Spark性能优化 -- > Joins (SQL and Core)
博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!

本博文将总结和讨论下spark core和spark sql 中join的优化操作。
简介
Join操作是spark中比较重要和常用的操作,无论是Spark Core还是Spark SQL都支持一些基础的join操作。但是join操作需要特殊的性能考虑(因为该操作要求RDD根据其key值,将相同key值的RDD拉取到同一个分区中),因为他们需要较大的网络传输,甚至会创建出超过系统处理能力的Dataset;在core Spark中,考虑操作的顺序可能更为重要,因为DAG优化器与SQL优化器不同,不能重新排序或向下推过滤操作。对于提高spark运行性能,考虑如何优化join操作就显得尤为重要。
core spark join
RDD Join
一般来说,Join操作是昂贵的,因为该操作要求RDD根据其key值,拉取相同key值的RDD处在同一个分区中,这样便可以在各个就对其进行连接操作。
- 如果RDD没有已知的partitioners,则需要对它们进行shuffle操作,使其相同键的数据位于相同的分区中,如下图所示。

- 如果它们具有相同的partitioners,则可以将数据放在同一个分区中,以避免网络传输,如下图所示。

- 不管partitioners 是否相同,如果一个(或两个)RDD有一个已知的partitioners,那么只会产生一个窄依赖,如下图所示。与大多数键/值操作一样,join的成本随着key的数量和其到达正确分区所需的移动距离成正比。
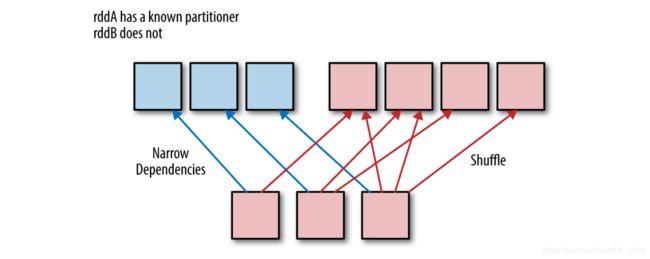
join中的key值问题
如果其中一个或两个RDD中存在重复的key值时,进行join操作,数据的大小可能会急剧扩展,从而导致性能问题,下面提几个经验建议:
-
当两个RDD都存在重复的key值时,最好先进行distinct或combineByKey操作,或者使用cogroup 处理重复key值问题,在执行join操作时可以防止二次的shuffle。
-
如果两个RDD中都不存在key时,则可能会意外丢失数据。使用外部连接(left,right)outer join时 会更安全,这样就可以保证将所有数据保存在左边或右边的RDD中,然后连接之后再过滤数据。
-
在join之前检查RDD中的key值,在此之前先过滤掉一些特殊的key值,例如空值。
注:join操作是spark里常用到的比较耗费性能的操作,有必要在join操作之前对数据集进行预处理。
举例:scoreRDD (Panda id, score) ,addressRDD (Panda id, address),现在想找到每个Panda id下面的address和bestScore,可用join操作达到目标。
方法一:
def joinScoresWithAddress1( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, String))]= {
val joinedRDD = scoreRDD.join(addressRDD)
joinedRDD.reduceByKey( (x, y) => if(x._1 > y._1) x else y )
}
方法二:
def joinScoresWithAddress2(scoreRDD : RDD[(Long, Double)], addressRDD: RDD[(Long, String)]) :
RDD[(Long, (Double, String))]= {
val bestScoreData = scoreRDD.reduceByKey((x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}
显然方法二更优,方法二在join之前就过滤掉了一些不必要的数据。
加速join过程的几种方法
为了join 数据,Spark需要将要join的数据(即基于每个key的数据)放入到同一个分区上。Spark中join的默认实现是 shuffled hash join。shuffled hash join 通过使用与第一个相同的默认partitioners 对第二个数据集进行分区,确保每个分区上的数据包含相同的key,从而使来自两个数据集的具有相同hash value的键位于同一分区中。虽然这种方法是有效的,但是它通常可能需要进行一次shuffle操作,代价比较昂贵。有以下两点可以用来避免shuffle过程:
- 需要join的两个RDD具有相同的partitioners
- 需要join的其中一个RDD很小,可以直接将其存入到内存中,使用broadcast hash join。
通过分配已知的partitioners来加速join过程
在对两个RDD进行join操作之前,可以对第二个RDD添加与第一个RDD相同的partitioners,使其两个RDD使用同一个partitioners,缓解join操作时的shuffle。
def joinScoresWithAddress3(scoreRDD: RDD[(Long, Double)], addressRDD: RDD[(Long, String)]) : RDD[(Long, (Double, String))]=
{
// If addressRDD has a known partitioner we should use that,
// otherwise it has a default hash parttioner, which we can reconstruct by
// getting the number of partitions.
val addressDataPartitioner = addressRDD.partitioner match {
case (Some(p)) => p
case (None) => new HashPartitioner(addressRDD.partitions.length)
}
// 通过使用addressRDD的Partitioner作为reduceByKey步骤的参数
val bestScoreData = scoreRDD.reduceByKey(addressDataPartitioner, (x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}

如上这种操作可以有效避免join操作中的shuffle过程。
注:在repartitioning后最好对RDD进行持久化
使用 broadcast hash join 加速join过程
broadcast hash join 会将较小的RDD复制副本到每个工作节点上,然后再和较大RDD的每个分区数据做map-side combine。如果较小的RDD可以存入到内存中,那么broadcast hash join效果更好。在Spark SQL中,可以配置spark.sql.autoBroadcastJoinThreshold (若dataset大小低于该阈值就会自动进行broadcast)和spark.sql.broadcastTimeout,使得spark sql足够聪明的配置broadcast hash join,例如将较小的RDD加载到内存。
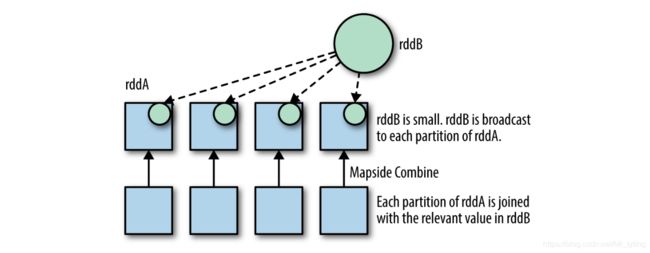
Spark Core 中没有实现broadcast hash join,需要自己实现,可以通过将较小RDD collect到驱动器,作为一个map,然后对其进行广播操作,然后再使用mapPartition。
def manualBroadCastHashJoin[K : Ordering : ClassTag, V1 : ClassTag, V2 : ClassTag](bigRDD : RDD[(K, V1)], smallRDD : RDD[(K, V2)])=
{
// 将较小的RDD进行collect,并进行广播操作
val smallRDDLocal: Map[K, V2] = smallRDD.collectAsMap()
bigRDD.sparkContext.broadcast(smallRDDLocal)
// 对较大RDD的每个分区进行map操作
bigRDD.mapPartitions(iter =>
{
iter.flatMap{
case (k,v1 ) => smallRDDLocal.get(k) match
{
case None => Seq.empty[(K, (V1, V2))]
case Some(v2) => Seq((k, (v1, v2)))
}
}
},
//preservesPartitioning表示是否保留父RDD的partitioner分区信息。
preservesPartitioning = true)
}
//end:coreBroadCast[]}
手动的进行Partial broadcast hash join
不是所有的较小RDD都能存入到内存中进行broadcast hash join,这时如果较大的RDD中,存在某些key值占比较大,特别是当某个key值占比太大,大到单个分区已经无法处理,而你又仅仅想对这些占比较大key值进行join,这时你可以对较小的RDD按照这些key值进行过滤,这时就可以对较小的RDD进行broadcast hash join得到Partial result。甚至可以对较大RDD剩下的key记录再次进行上述操作,将得到所有Partial result进行union,即可得到整个join结果。
上述这种方法虽然复杂,但可以有效的处理高度倾斜的数据。
Spark SQL Join
相对于spark core,spark sql可以利用其特有的优化器做一些繁重的工作,使得join操作更有效率,但同时你会失去部分控制权,例如不能控制分区细节,不能像core spark 那样手动的避免shuffle过程。
注:基表不能被广播,比如left outer join时,只能广播右表。
DataFrame Joins
spark join type
- inner
- left_outer
- right_outer
- full_outer
- left_semi
上述的join type太简单了,这里就不举例说明了,需要注意的是,这样的join和pandas 中的DataFrame的join不一样之处在于,这里的join结果会同时出现df1和df2的key列,即在join结果中key列会出现两次。
DataFrame Broadcast hash joins
配置spark.sql.autoBroadcastJoinThreshold (若dataset大小低于该阈值就会自动进行broadcast)和spark.sql.broadcastTimeout参数
import org.apache.spark.sql.functions.broadcast
val smallDF: DataFrame = ???
val largeDF: DataFrame = ???
largeDF.join(broadcast(smallDF), Seq("foo"))
// or broadcast hint (Spark >= 2.2):
largeDF.join(smallDF.hint("broadcast"), Seq("foo"))
总结
本文主要总结了如下几种join中的优化操作
- 在join之前过滤掉特殊和不必要的key
- 在join之前,尽量将存在重复key的数据集通过各种操作 转成distinct key的数据集
- 在join之前,将参与join操作的两个RDD使用同一个partitioners,对应key的分区上存储着相应的将要连接的数据。
- broadcast hash join(只适用于存在小的数据集)
- Partial manual broadcast hash join(只适用于存在小的数据集,对于解决数据倾斜,非常有效)
参考
- High Performance Spark