【Python库】05—RE正则表达式
有些人面临一个问题时会想:“我知道,可以用正则表达式来解决这个问题。”于是,现在他们就有两个问题了。
Jamie Zawinski
使用Python正则表达式,可以帮助我们批量处理一些文件内容,大幅提高效率,减小重复性工作。
RE模块中常用的函数:
1.re.compile(pattem,flags=0)
Compile a regular expression pattern into a regular expression object, which can be used for matching using its match(), search() and other methods, described below.
编译正则表达式,使其转化为一个正则表达式对象,以便其他方法,如:match()、search()等的使用。那么,为什么要这样做呢?
因为当我们在Python中使用正则表达式时,RE模块内部会做两件事:
(1)编译正则表达式,如果正则表达式不合法,则报错;
(2)用编译后的正则表达去匹配字符串。
所以,当我们要多次使用同一个正则表达式时,为了实现更有效率的匹配,先将正则表达式编译为正则表达式对象,这样在下一次使用时,就不用再转化一次。
函数详解:
- pattem:正则表达式
- flags:用于修改正则表达式的匹配方式,常用的有:
| 标志 |
含义 |
| re.S(DOTALL) |
匹配包括换行在内的所有字符 |
| re.I(IGNORECASE) |
匹配时大小写不敏感 |
| re.L(LOCALE) |
做本地化识别匹配??? |
| re.M(MULTILINE) |
多行匹配 |
| re.X(VERBOSE) |
给与更灵活的方式 |
| re.U |
根据Unicode字符集解析,会影响到\w,\W,\b,\B |
代码示例:
import re
tt = "Tina is a good girl, she is cool, clever, and so on..."
rr = re.compile(r'\w*oo\w*',re.I)
2.re.search(pattern,string,flags=0)
Scan through string looking for the first location where the regular expression pattern produces a match, and return a corresponding match object. Return None if no position in the string matches the pattern; note that this is different from finding a zero-length match at some point in the string.
查找给定字符串中第一个匹配项,并换回。如果没有字符串匹配,则返回NONE。
匹配成功后,将返回一个match object,并有以下方法:
| 方法 |
作用 |
| group() |
返回匹配的字符串 |
| start() |
返回匹配开始的位置 |
| end() |
返回匹配结束的位置 |
| span() |
返回一个元组,包括匹配的开始和结束的位置 |
| group( n ) |
返回对应子表达式的内容 |
| groups( ) |
返回一个列表,包括全部的子表达式 |
代码示例:
import re
text = "Tina is a good girl, she is cool, clever, and so on..."
S1 = re.search('[A-Z]?[a-z]*',text).group()
S2 = re.search('[A-Z]?[a-z]*',text).start()
S3 = re.search('[A-Z]?[a-z]*',text).end()
S4 = re.search('[A-Z]?[a-z]*',text).span()
print(S1)
print(S2)
print(S3)
print(S4)结果如下:

group()的用法详解:
可按子表达式进行返回对应的匹配字符串。“0”为返回全部,与不填是一样的。
示例代码:
import re
text = "123abc456"
S1 = re.search("([0-9]*)([a-z]*)([0-9]*)",text).group()
S2 = re.search("([0-9]*)([a-z]*)([0-9]*)",text).group(0)
S3 = re.search("([0-9]*)([a-z]*)([0-9]*)",text).group(1)
S4 = re.search("([0-9]*)([a-z]*)([0-9]*)",text).group(2)
S5 = re.search("([0-9]*)([a-z]*)([0-9]*)",text).group(1,3)
S6 = re.search("([0-9]*)([a-z]*)([0-9]*)",text).groups()
print(S1)
print(S2)
print(S3)
print(S4)
print(S5)
print(S6)结果为

3.re.match(pattern, string, flags=0)
If zero or more characters at the beginning of string match the regular expression pattern, return a corresponding match object. Return None if the string does not match the pattern; note that this is different from a zero-length match.
Note that even in MULTILINE mode, re.match() will only match at the beginning of the string and not at the beginning of each line.
If you want to locate a match anywhere in string, use search() instead (see also search() vs. match()).
re.match()在字符串的开头匹配正则表达式,并返回匹配项,否则返回NONE。
示例代码:
import re
text = "123abc456"
S1 = re.match("([0-9]*)",text)
S2 = re.match("([a-z]*)",text)
S3 = re.match("([0-9]*)",text).group()
S4 = re.match("([a-z]*)",text).group()
print(S1)
print(S2)
print(S3)
print(S4)返回结果:
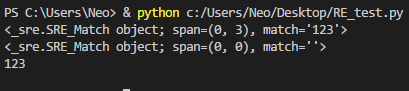
此处,可以更好的理解match object的概念。
4.re.findall(pattern, string, flags=0)
Return all non-overlapping matches of pattern in string, as a list of strings. The string is scanned left-to-right, and matches are returned in the order found. If one or more groups are present in the pattern, return a list of groups; this will be a list of tuples if the pattern has more than one group. Empty matches are included in the result.
以列表的形式,返回所有的匹配项。
示例代码:
import re
p = re.compile(r'\d+')
S1 =p.findall('o1n2m3k4')
print(S1)返回结果为
![]()
5.re.finditer(pattern, string, flags=0)
Return an iterator yielding match objects over all non-overlapping matches for the RE pattern in string. The string is scanned left-to-right, and matches are returned in the order found. Empty matches are included in the result.
返回一个顺序访问每一个匹配结果的迭代器。
示例代码:
import re
S1 = re.finditer(r'\d+','12 drumm44ers drumming, 11 ... 10 ...')
for i in S1:
print(i.group())返回结果:

6.re.split(pattern, string, maxsplit=0, flags=0)
Split string by the occurrences of pattern. If capturing parentheses are used in pattern, then the text of all groups in the pattern are also returned as part of the resulting list. If maxsplit is nonzero, at most maxsplit splits occur, and the remainder of the string is returned as the final element of the list.
根据匹配项来分割字符串。
示例代码:
import re
S1 = re.split(r',', 'Words, SKY, Space.')
print(S1)返回结果为
![]()
7.re.sub(pattern, repl, string, count=0, flags=0)
用repl替换string中每一个匹配项后,返回替换后的字符串。
示例代码:
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
print(re.sub(r'\s+', '-', text))返回结果:
![]()
repl还可以是一个函数,允许其对匹配项做处理后再进行替换。
If repl is a function, it is called for every non-overlapping occurrence of pattern. The function takes a single match object argument, and returns the replacement string.
示例代码:
import re
def repl_handle(matchobj):
repl2 = str(int(matchobj.group()) + 1)
return repl2
text = "one1two2three3four4five5six"
S1 = re.sub(r'\d+',repl_handle,text)
print(S1)返回结果为:
![]()
8.re.subn(pattern, repl, string, count=0, flags=0)
Perform the same operation as sub(), but return a tuple (new_string, number_of_subs_made).
执行和sub()一样的操作,但同时返回替换的次数。
示例代码:
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
S1 = re.sub(r'\s+', '-', text)
S2 = re.subn(r'\s+', '-', text)
print(S1)
print(S2)返回结果:

9.re.escape(pattern)
将字符串中所有的特殊正则表达式字符转义。
示例代码:
import re
S1 = re.escape('www.python.org')
print(S1)返回结果:
![]()
注:
在字符串前面加上“r”前缀,就不用考虑转义了。
Ref:
1.MagnusLieHetland. Python基础教程.第2版[M]. 人民邮电出版社, 2014.
2.Python官网说明:https://docs.python.org/3.7/library/re.html
3.廖雪峰Python教程:https://www.liaoxuefeng.com/wiki/
4.Python(RE模块):https://www.cnblogs.com/tina-python/p/5508402.html