官方文档地址: https://docs.signal18.io/
搭建主从复制环境
我这里用的是dbdeployer部署的mysql 5.7单机多实例的主从架构。
宿主机地址: 192.168.2.4
复制用的账号和密码: rsandbox rsandbox
准备给replication-manager用的账号密码: rep-manager rep-manager
稍微修改了些配置,改动的地方大致如下:
default-time-zone = '+08:00'
log_timestamps = SYSTEM
log_error_verbosity = 2
skip_name_resolve=on
slave_parallel_type = 'LOGICAL_CLOCK'
slave_parallel_workers = 4
show_compatibility_56 = ON
innodb_buffer_pool_instances = 4
log_slave_updates = ON
gtid_mode= ON
enforce_gtid_consistency = ON
binlog_gtid_simple_recovery = TRUE
character_set_server = utf8
relay_log_info_repository = 'TABLE'
master_info_repository = 'TABLE'
relay_log_recovery = ON
relay-log-index=mysql-relay
relay-log=mysql-relay
log-bin=mysql-bin
server-id=200 # 这里每个实例必须保持不一致
bind-address = 0.0.0.0
# replication-manager不具备补数据的功能,因此建议开启半同步复制(需要安装semi-sync插件)
loose-rpl_semi_sync_master_enabled = ON
loose-rpl_semi_sync_master_timeout = 1000
loose-rpl_semi_sync_master_wait_no_slave = ON
loose-rpl_semi_sync_slave_enabled = ONreplication-manager初步尝试
添加repo源
$ cat /etc/yum.repos.d/signal18.repo
[signal18]
name=Signal18 repositories
baseurl=http://repo.signal18.io/centos/$releasever/$basearch/
gpgcheck=0
enabled=1安装replication-manager
$ yum install replication-manager-osc -y注意:下面我们先简单演示下功能,这里用的haproxy的做负载均衡和读写分离。
生产环境的用法:使用proxysql来做读写分离,replication-manager单纯只做HA切换作用。
编译安装haproxy
默认centos7带的是1.5版本,较低。需要自行编译haproxy,到haproxy官网下载源码包即可, 我这里用的是2.0.15版的。
tar xf haproxy-2.0.15.tar.gz
cd haproxy-2.0.15/
make TARGET=generic -j 8
make install
ln -s /usr/local/sbin/haproxy /usr/sbin/haproxy编辑replication-manager的配置文件
cd /etc/replication-manager
cp config.toml.sample.tst.masterslave-haproxy config.toml
下面是我修改后的全部配置内容:
$ cat /etc/replication-manager/config.toml | egrep -v '^$'
[Cluster_Haproxy_MasterSlave]
title = "DBA-TEST57"
db-servers-hosts = "192.168.2.4:19226,192.168.2.4:19227,192.168.2.4:19228"
db-servers-prefered-master = "192.168.2.4:19226"
db-servers-ignored-hosts = "192.168.2.4:19228"
db-servers-credential = "rep-manager:rep-manager"
db-servers-connect-timeout = 2
db-servers-read-timeout = 5
replication-credential = "rsandbox:rsandbox" # 复制用的账号密码
replication-master-connect-retry = 10 # Replication is created using this connection retry timeout in second.
# 使用haproxy 在前面做代理, haproxy需要在1.7版本及以上
haproxy = true
haproxy-binary-path = "/usr/sbin/haproxy" # 用的本地模式的haproxy
haproxy-servers = "127.0.0.1"
haproxy-ip-write-bind = "0.0.0.0"
haproxy-stat-port = 1988
haproxy-write-port = 3303
haproxy-read-port = 3302
# 此外replication-manager还支持使用远程的haproxy(比本地模式稍微复杂点,简单点的话就用本地模式即可)
# 可以参考这个 https://docs.signal18.io/configuration/routing-traffic/haproxy
[Default]
monitoring-datadir = "/var/lib/replication-manager"
monitoring-sharedir = "/usr/share/replication-manager"
# replication-manager 还支持 proxysql maxscale 等其他工具,具体参考官网即可
## Timeout in seconds between consecutive monitoring
# monitoring-ticker = 2
#########
## LOG ##
#########
log-file = "/var/log/replication-manager.log"
verbose = true
log-rotate-max-age = 1
log-rotate-max-backup = 7
log-rotate-max-size = 10
log-sql-in-monitoring = true # Log all SQL queries send to backend for monitoring servers (filename:sql_general.log)
##############
## TOPOLOGY ##
##############
replication-multi-master = false
# replication-multi-tier-slave = false
# 脚本写法可以参考 http://docs.signal18.io/configuration/failover
## Slaves will re enter with read-only
failover-readonly-state = true
failover-event-scheduler = false
failover-event-status = false
## Failover after N failures detection
failover-falsepositive-ping-counter = 5 # 5次ping探活失败后进行failover
failover-limit = 100 # 如果failover累积达到100次,就不再进行。可以再web界面reset这个值
failover-time-limit = 30 # 如果30秒前发生过一次故障转移,就不再进行本次failover
failover-at-sync = false
failover-max-slave-delay = 5
failover-restart-unsafe = false # 当整个群集关闭时,故障转移到第一个重新启动的节点(注意:这个节点可以是之前的一个从节点)
failover-falsepositive-heartbeat = true # 如果一个从站仍可以从主站获取事件,则取消故障转移
failover-falsepositive-heartbeat-timeout = 3 # 故障转移等待此计时器的秒数,以便复制检测到故障的主服务器以进行故障转移 falsepositive-heartbeat
# failover-falsepositive-maxscale = false
# failover-falsepositive-maxscale-timeout = 14
# failover-falsepositive-external = false
# failover-falsepositive-external-port = 80
# 人工切主时候涉及到的相关参数
switchover-wait-kill = 5000 #切换要等待这么多毫秒,然后才能杀死降级的主服务器上的线程
switchover-wait-trx = 10 # 如果FTWL 10秒也没返回,则切换取消
switchover-wait-write-query = 10 # 如果有个write query 10秒还没结束,则切换取消
# switchover-at-equal-gtid = false
# switchover-at-sync = false
# switchover-max-slave-delay = 30
switchover-slave-wait-catch = true # Switchover wait for replication to catch up before switching extra slaves, when using GTID don't wait can speed up switchover but may hide issues liek writing on the old master with super user
############
## REJOIN ##
############
autorejoin = true
# autorejoin-script = ""
autorejoin-semisync = true
autorejoin-backup-binlog = true
autorejoin-flashback = false
autorejoin-mysqldump = false
autorejoin-flashback-on-sync = false
autorejoin-slave-positional-hearbeat = false
####################
## CHECKS & FORCE ##
####################
# check-replication-filters = true
# check-binlog-filters = true
check-replication-state = true
force-slave-heartbeat= false
force-slave-heartbeat-retry = 5
force-slave-heartbeat-time = 3
force-slave-gtid-mode = false
force-slave-semisync = false
force-slave-failover-readonly-state = false
force-binlog-row = false
force-binlog-annotate = false
force-binlog-slowqueries = false
force-binlog-compress = false
force-binlog-checksum = false
force-inmemory-binlog-cache-size = false
force-disk-relaylog-size-limit = false
force-disk-relaylog-size-limit-size = 1000000000
force-sync-binlog = false
force-sync-innodb = false
http-server = true
http-bind-address = "0.0.0.0"
# http-port = "10001"
# http-auth = false
# http-session-lifetime = 3600
# http-bootstrap-button = false
#########
## API ##
#########
# api-credential = "admin:repman"
# api-port = "3000"
graphite-metrics = true
graphite-carbon-host = "127.0.0.1"
graphite-carbon-port = 2003
graphite-embedded = true
graphite-carbon-api-port = 10002
graphite-carbon-server-port = 10003
graphite-carbon-link-port = 7002
graphite-carbon-pickle-port = 2004
graphite-carbon-pprof-port = 7007启动replication-manager
systemctl start replication-manager 查看replication-manager运行状态**
$ ss -lntp | grep replication
LISTEN 0 4096 127.0.0.1:10003 *:* users:(("replication-man",pid=3707764,fd=9))
LISTEN 0 4096 :::10001 :::* users:(("replication-man",pid=3707764,fd=32))
LISTEN 0 4096 :::10002 :::* users:(("replication-man",pid=3707764,fd=14))
LISTEN 0 4096 :::2003 :::* users:(("replication-man",pid=3707764,fd=7))
LISTEN 0 4096 :::2004 :::* users:(("replication-man",pid=3707764,fd=8))
LISTEN 0 4096 :::10005 :::* users:(("replication-man",pid=3707764,fd=11))
LISTEN 0 4096 :::7002 :::* users:(("replication-man",pid=3707764,fd=10))
端口说明:
10001 admin-web管理界面端口
其余大部分都是graphite-carbon使用的端口
$ ps auxf | grep replication
root 3707764 5.1 0.0 121748 49096 ? Ssl 17:56 10:51 /usr/bin/replication-manager-osc monitor
root 3780230 0.1 0.0 7012 2332 ? Ss 21:02 0:01 /usr/sbin/haproxy -f /var/lib/replication-manager/cluster_haproxy_masterslave-haproxy.cfg -p /var/lib/replication-manager/cluster_haproxy_masterslave-haproxy-private.pid -D -sf 3773274
进程说明:
启动replication-manager后,它会生成haproxy的配置文件,并帮我们自动拉起haproxy进程对外提供服务。
haproxy的端口情况:
$ ss -lntp| grep haproxy
LISTEN 0 4096 *:1988 *:* users:(("haproxy",pid=3780230,fd=4))
LISTEN 0 4096 *:3302 *:* users:(("haproxy",pid=3780230,fd=8)) ### haproxy-read-port
LISTEN 0 4096 *:3303 *:* users:(("haproxy",pid=3780230,fd=7)) ### haproxy-write-port
访问replication-manager管理界面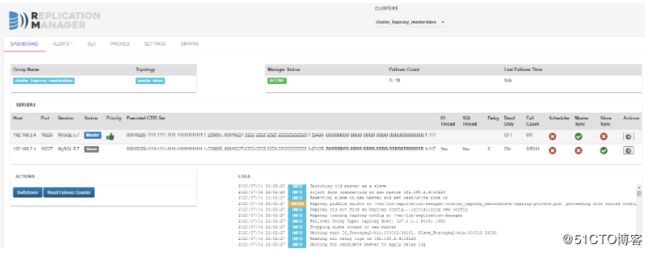
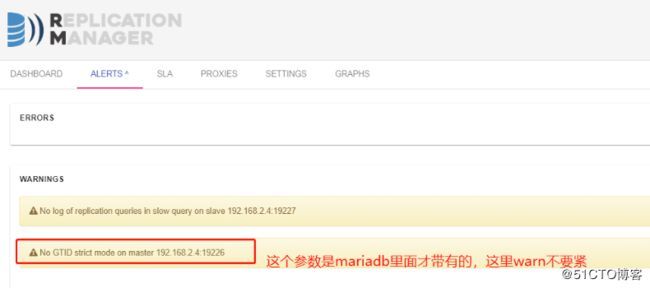
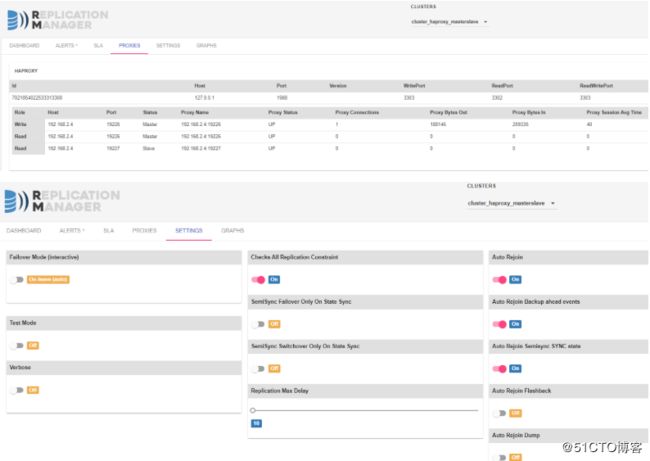
访问haproxy管理界面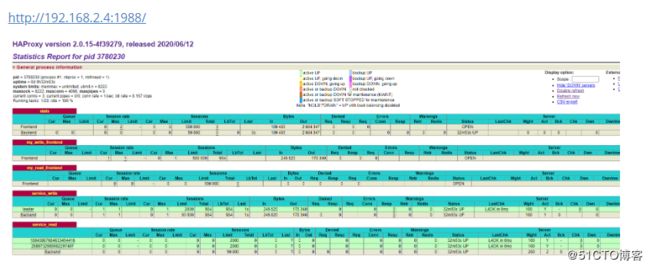
人工切换时,MySQL的日志
tion-manager的web界面,很方便的做人工切换。
下面是我在web界面执行 人工failover后,到2个实例上 抓取的general_log。如下:
原拓扑:
主: 192.168.2.4:19226
从: 192.168.2.4:19227
人工切换后拓扑:
主: 192.168.2.4:19227
从: 192.168.2.4:19226
我们看下 192.168.2.4:19226 上面的日志(只摘录了最核心的几行):
2020-07-04T21:47:36.100973+08:00 10 Query FLUSH NO_WRITE_TO_BINLOG TABLES # 关闭打开的表
2020-07-04T21:47:36.118698+08:00 10 Query SET GLOBAL read_only=1 # 锁写
2020-07-04T21:47:36.118881+08:00 10 Query SET GLOBAL super_read_only=1 # 锁写
2020-07-04T21:47:36.122252+08:00 10 Query SET sql_mode='STRICT_TRANS_TABLES'
2020-07-04T21:47:36.122402+08:00 10 Query SET GLOBAL max_connections=10 # 将连接数临时调小
2020-07-04T21:47:36.123304+08:00 10 Execute KILL 43 # 杀掉长连接
2020-07-04T21:47:36.123626+08:00 10 Query FLUSH TABLES WITH READ LOCK # 锁写全部的表
2020-07-04T21:47:36.123999+08:00 4015 Query SET NAMES utf8
2020-07-04T21:47:36.125417+08:00 4015 Query SET @slave_uuid= '00019227-2222-2222-2222-222222222222'
2020-07-04T21:47:36.125615+08:00 4015 Query SELECT @@global.rpl_semi_sync_master_enabled
2020-07-04T21:47:36.125748+08:00 4015 Query SET @rpl_semi_sync_slave= 1
2020-07-04T21:47:36.125911+08:00 4015 Binlog Dump GTID Log: '' Pos: 4 GTIDs: '00019226-1111-1111-1111-111111111111:1-229138,
00019227-2222-2222-2222-222222222222:1-22425,
bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb:1-117' # 显示当前实例的GTID情况
2020-07-04T21:47:36.392927+08:00 10 Query UNLOCK TABLES
2020-07-04T21:47:36.402293+08:00 10 Query STOP SLAVE
2020-07-04T21:47:36.408238+08:00 10 Query CHANGE MASTER TO MASTER_HOST = '192.168.2.4' MASTER_USER = 'rsandbox' MASTER_PASSWORD = MASTER_PORT = 19227 MASTER_CONNECT_RETRY = 5 MASTER_HEARTBEAT_PERIOD = 3.000000 # 切为从库
2020-07-04T21:47:36.633585+08:00 10 Query START SLAVE # 开启复制
2020-07-04T21:47:36.718644+08:00 10 Query SET GLOBAL read_only=1 # 开始打开写功能
2020-07-04T21:47:36.718806+08:00 10 Query SET GLOBAL max_connections=151 # 将连接数改回原先的值
我们看下 192.168.2.4:19227 上面的日志(只摘录了最核心的几行):
2020-07-04T21:47:36.105982+08:00 5 Query SHOW MASTER STATUS
2020-07-04T21:47:36.106755+08:00 5 Query SHOW ENGINE INNODB STATUS
2020-07-04T21:47:36.109851+08:00 5 Query SHOW SLAVE STATUS
2020-07-04T21:47:36.131030+08:00 5 Query STOP SLAVE
2020-07-04T21:47:36.243862+08:00 5 Query RESET SLAVE ALL ## 开始提升为主库
2020-07-04T21:47:36.362719+08:00 5 Query SET GLOBAL read_only=0 # 开始打开写功能
2020-07-04T21:47:36.366015+08:00 5 Query SET GLOBAL super_read_only=0 # 开始打开写功能
2020-07-04T21:47:36.366318+08:00 5 Query FLUSH TABLES 模拟Master宕机,replication-manager自动切换的日志
注意:这是replication-manager web控制台上截取的日志。
里面反映的情况是:
1、检测到master宕机了
2、replication-manager在5次master探活都失败后,开始执行failover动作
3、将192.168.2.4:19226提升为新的主库
4、通知haproxy调整后端挂载的实例
5、2020/07/04 22:19:50 原先宕机的master已经启动完成,replication-manager尝试将其重新加回集群内
6、replication-manager 对原先的master做gtid对比
2020/07/04 22:22:37 STATE OPENED WARN0007 : At least one server is not ACID-compliant. Please make sure that sync_binlog and innodb_flush_log_at_trx_commit are set to 1
2020/07/04 22:21:54 STATE OPENED ERR00041 : Skip slave in election 192.168.2.4:19227 has more than 10 seconds of replication delay (119)
2020/07/04 22:21:54 STATE RESOLV ERR00042 : Skip slave in election 192.168.2.4:19227 SQL Thread is stopped
2020/07/04 22:21:44 STATE OPENED ERR00042 : Skip slave in election 192.168.2.4:19227 SQL Thread is stopped
2020/07/04 22:21:44 STATE RESOLV ERR00041 : Skip slave in election 192.168.2.4:19227 has more than 10 seconds of replication delay (107)
2020/07/04 22:19:52 STATE OPENED ERR00041 : Skip slave in election 192.168.2.4:19227 has more than 10 seconds of replication delay (8994)
2020/07/04 22:19:52 STATE OPENED WARN0054 : No log of replication queries in slow query on slave 192.168.2.4:19227
2020/07/04 22:19:52 STATE RESOLV ERR00010 : Could not find a slave in topology
2020/07/04 22:19:50 INFO New Master 192.168.2.4:19227 was not synced before failover, unsafe flashback, lost events backing up event to /var/lib/replication-manager/cluster_haproxy_masterslave/crash-bin-20200704221950
2020/07/04 22:19:50 INFO Doing MySQL GTID switch of the old master
2020/07/04 22:19:50 INFO Found same or lower GTID 0-14208664504865218624-229138,0-12250091203236490887-51881,0-8802070338800431574-117 and new elected master was 0-14208664504865218624-229138,0-12250091203236490887-51881,0-9120374598754219016-117
2020/07/04 22:19:50 INFO Crash Saved GTID sequence 0 for master id 200
2020/07/04 22:19:50 INFO Rejoined GTID sequence 0
2020/07/04 22:19:50 INFO Setting Read Only on rejoin incremental on server 192.168.2.4:19227
2020/07/04 22:19:50 INFO Crash info &{192.168.2.4:19227 mysql-bin.000012 48999006 mysql-bin.000004 48671539 %!s(bool=true) %!s(*gtid.List=&[{0 14208664504865218624 229138} {0 12250091203236490887 51881} {0 9120374598754219016 117}]) 192.168.2.4:19226}
2020/07/04 22:19:50 INFO Rejoin master incremental 192.168.2.4:19227
2020/07/04 22:19:50 INFO Backup /usr/share/replication-manager/amd64/linux/mysqlbinlog [/usr/share/replication-manager/amd64/linux/mysqlbinlog --read-from-remote-server --raw --stop-never-slave-server-id=10000 --user=rsandbox --password=rsandbox --host=192.168.2.4 --port=19227 --result-file=/var/lib/replication-manager/cluster_haproxy_masterslave-server200- --start-position=48999006 mysql-bin.000012]
2020/07/04 22:19:50 INFO Backup ahead binlog events of previously failed server 192.168.2.4:19227
2020/07/04 22:19:50 INFO Rejoining server 192.168.2.4:19227 to master 192.168.2.4:19226
2020/07/04 22:19:50 INFO Trying to rejoin restarted server 192.168.2.4:19227
2020/07/04 22:19:50 INFO Setting Read Only on unconnected server 192.168.2.4:19227 as actif monitor and other master dicovereds
2020/07/04 22:19:12 STATE OPENED ERR00010 : Could not find a slave in topology
2020/07/04 22:19:12 STATE OPENED ERR00032 : No candidates found in slaves list
2020/07/04 22:19:12 STATE OPENED WARN0070 : No GTID strict mode on master 192.168.2.4:19226
2020/07/04 22:19:12 STATE RESOLV WARN0023 : Failover number of master pings failure has been reached
2020/07/04 22:19:12 STATE RESOLV ERR00050 : Can't connect to proxy driver: bad connection
2020/07/04 22:19:12 STATE RESOLV WARN0054 : No log of replication queries in slow query on slave 192.168.2.4:19226
2020/07/04 22:19:10 STATE OPENED WARN0023 : Failover number of master pings failure has been reached
2020/07/04 22:19:10 STATE RESOLV ERR00016 : Master is unreachable but slaves are replicating
2020/07/04 22:19:10 INFO Master switch on 192.168.2.4:19226 complete
2020/07/04 22:19:10 INFO Switching other slaves to the new master
2020/07/04 22:19:10 INFO Inject fake transaction on new master 192.168.2.4:19226
2020/07/04 22:19:10 INFO Resetting slave on new master and set read/write mode on
2020/07/04 22:19:10 WARN Haproxy pidfile exists at /var/lib/replication-manager/cluster_haproxy_masterslave-haproxy-private.pid, proceeding with reload config...
2020/07/04 22:19:10 INFO Haproxy did not find an haproxy config...initializing new config
2020/07/04 22:19:10 INFO Haproxy loading haproxy config at /var/lib/replication-manager
2020/07/04 22:19:10 INFO Failover Proxy Type: haproxy Host: 127.0.0.1 Port: 1988
2020/07/04 22:19:10 INFO Stopping slave thread on new master
2020/07/04 22:19:10 INFO Waiting sync IO_Pos:mysql-bin.000012/48999006, Slave_Pos:mysql-bin.000012 48999006
2020/07/04 22:19:10 INFO Reading all relay logs on 192.168.2.4:19226
2020/07/04 22:19:10 INFO Waiting for candidate master to apply relay log
2020/07/04 22:19:10 INFO Slave 192.168.2.4:19226 has been elected as a new master
2020/07/04 22:19:10 INFO Election matrice: [ { "URL": "192.168.2.4:19226", "Indice": 0, "Pos": 1248999006, "Seq": 0, "Prefered": true, "Ignoredconf": false, "Ignoredrelay": false, "Ignoredmultimaster": false, "Ignoredreplication": false, "Weight": 0 } ]
2020/07/04 22:19:10 INFO Electing a new master
2020/07/04 22:19:10 INFO ------------------------
2020/07/04 22:19:10 INFO Starting master failover
2020/07/04 22:19:10 INFO ------------------------
2020/07/04 22:19:07 ALERT Server 192.168.2.4:19227 state changed from Suspect to Failed
2020/07/04 22:19:07 INFO Declaring master as failed
2020/07/04 22:19:07 INFO Master Failure detected! Retry 5/5
2020/07/04 22:19:05 INFO Master Failure detected! Retry 4/5
2020/07/04 22:19:03 INFO Master Failure detected! Retry 3/5
2020/07/04 22:19:01 STATE OPENED ERR00050 : Can't connect to proxy driver: bad connection
2020/07/04 22:19:01 INFO Master Failure detected! Retry 2/5
2020/07/04 22:18:59 STATE OPENED ERR00016 : Master is unreachable but slaves are replicating
2020/07/04 22:18:59 STATE RESOLV WARN0070 : No GTID strict mode on master 192.168.2.4:19227
2020/07/04 22:18:59 ALERT Server 192.168.2.4:19227 state changed from Master to Suspect
2020/07/04 22:18:59 INFO Master Failure detected! Retry 1/5看起来是不是很诱人??
replication-manager还能自动拉起haproxy自动做读写分离。有种真香的感觉了吧
但是haproxy这种局限性比较大(重启replication-manager也会造成haproxy的重启,这也就造成了服务中断。不信的同学可以自己试验下看)。
因此,我们生产环境更常用的是replication-manager+proxysql 或者 replication-manager+maxscale来做。
但是又因为maxscale的授权协议稍微严格些问题,我们一般生产用replication-manager+proxysql这种方案。
官方文档:https://docs.signal18.io/configuration/routing-traffic/proxysql
部署文档,proxysql的部署可以参考大师兄的博客 https://www.cnblogs.com/gomysql/p/7018797.html
ProxySQL+replication-manager解决方案
在mysql上创建几个账号,后面会用到:
GRANT select on *.* to ro@'%' identified by 'ro'; -- 业务的只读账号
GRANT select,update,delete,insert,create on sbtest.* to sbuser@'%' identified by 'sbuser'; -- 业务的读写账号
GRANT PROCESS, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'proxysql'@'%' identified by 'proxysql'; -- proxysql使用
GRANT ALL PRIVILEGES ON *.* TO 'rep-manager'@'%' identified by 'rep-manager'; -- replication-manager使用这次用3节点主从结构,目前如下:
192.168.2.4:19226 主
192.168.2.4:19227 从
192.168.2.4:19228 从replication-manager的配置如下:
$ egrep -v '^$|^#' /etc/replication-manager/config.toml
[Cluster_Haproxy_MasterSlave]
title = "DBA-TEST57"
db-servers-hosts = "192.168.2.4:19226,192.168.2.4:19227,192.168.2.4:19228"
db-servers-credential = "rep-manager:rep-manager"
db-servers-connect-timeout = 2
db-servers-read-timeout = 5
replication-credential = "rsandbox:rsandbox" # 复制用的账号密码
replication-master-connect-retry = 10 # Replication is created using this connection retry timeout in second.
proxysql = true
proxysql-servers = "127.0.0.1"
proxysql-port = "6033"
proxysql-admin-port = "6032"
proxysql-writer-hostgroup = 100
proxysql-reader-hostgroup = 1000
proxysql-user = "admin"
proxysql-password = "admin"
proxysql-bootstrap = false # 这里设置为false,由我们自行到proxysql后端去配置servers等信息,不要replication-manager去自行生成
proxysql-copy-grants = true
[Default]
monitoring-datadir = "/var/lib/replication-manager"
monitoring-sharedir = "/usr/share/replication-manager"
log-file = "/var/log/replication-manager.log"
verbose = true
log-rotate-max-age = 1
log-rotate-max-backup = 7
log-rotate-max-size = 10
log-sql-in-monitoring = true # Log all SQL queries send to backend for monitoring servers (filename:sql_general.log)
replication-multi-master = false
failover-mode = "automatic" # 可选值 "manual" , "automatic"
failover-readonly-state = true
failover-event-scheduler = false
failover-event-status = false
failover-falsepositive-ping-counter = 5 # 5次ping探活失败后进行failover
failover-limit = 1000 # 如果failover累积达到100次,就不再进行。可以再web界面reset这个值
failover-time-limit = 30 # 如果30秒前发生过一次故障转移,就不再进行本次failover
failover-at-sync = false
failover-max-slave-delay = 5
failover-restart-unsafe = false # 当整个群集关闭时,故障转移到第一个重新启动的节点(注意:这个节点可以是之前的一个从节点)
failover-falsepositive-heartbeat = true # 如果一个从站仍可以从主站获取事件,则取消故障转移
failover-falsepositive-heartbeat-timeout = 3 # 故障转移等待此计时器的秒数,以便复制检测到故障的主服务器以进行故障转移 falsepositive-heartbeat
switchover-wait-kill = 5000 #切换要等待这么多毫秒,然后才能杀死降级的主服务器上的线程
switchover-wait-trx = 10 # 如果FTWL 10秒也没返回,则切换取消
switchover-wait-write-query = 10 # 如果有个write query 10秒还没结束,则切换取消
switchover-slave-wait-catch = true # Switchover wait for replication to catch up before switching extra slaves, when using GTID # don't wait can speed up switchover but may hide issues liek writing on the old master with super user
autorejoin = true
autorejoin-semisync = true
autorejoin-backup-binlog = true
autorejoin-flashback = false
autorejoin-mysqldump = false
autorejoin-flashback-on-sync = false
autorejoin-slave-positional-hearbeat = false
check-replication-filters = true
check-binlog-filters = true
check-replication-state = true
force-slave-heartbeat= true # Automatically activate replication heartbeat on slave.
force-slave-heartbeat-retry = 5 # Replication heartbeat retry on slave.
force-slave-heartbeat-time = 3 # Replication heartbeat time.
force-slave-gtid-mode = false
force-slave-semisync = false
force-slave-failover-readonly-state = false
force-binlog-row = false
force-binlog-annotate = false
force-binlog-slowqueries = false
force-binlog-compress = false
force-binlog-checksum = false
force-inmemory-binlog-cache-size = false
force-disk-relaylog-size-limit = false
force-disk-relaylog-size-limit-size = 1000000000
force-sync-binlog = false
force-sync-innodb = false
http-server = true
http-bind-address = "0.0.0.0"
graphite-metrics = true
graphite-carbon-host = "127.0.0.1"
graphite-carbon-port = 2003
graphite-embedded = true
graphite-carbon-api-port = 10002
graphite-carbon-server-port = 10003
graphite-carbon-link-port = 7002
graphite-carbon-pickle-port = 2004
graphite-carbon-pprof-port = 7007proyxsql配置文件如下(这里以单节点proxysql的配置为例):
[root@localhost /var/lib/proxysql ] # cat /etc/proxysql.cnf | egrep -v '^$|^#'
datadir="/var/lib/proxysql"
errorlog="/var/lib/proxysql/proxysql.log"
admin_variables=
{
admin_credentials="admin:admin"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
debug=true
}
mysql_variables=
{
threads=4
max_connections=1000
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033"
default_schema="information_schema"
stacksize=1048576
server_version="5.7.25"
connect_timeout_server=3000
monitor_username="proxysql"
monitor_password="proxysql"
monitor_history=600000
monitor_connect_interval=60000
monitor_ping_interval=10000
monitor_read_only_interval=1500
monitor_read_only_timeout=500
ping_interval_server_msec=120000
ping_timeout_server=500
commands_stats=true
sessions_sort=true
connect_retries_on_failure=10
}
mysql_servers =
(
)
mysql_users:
(
)
mysql_query_rules:
(
)
scheduler=
(
)
mysql_replication_hostgroups=
(
)登录proxysql admin管理控制端:
mysql -u admin -padmin -h 127.0.0.1 -P6032 --prompt='Admin> '
Admin> show databases;
+-----+---------------+-------------------------------------+
| seq | name | file |
+-----+---------------+-------------------------------------+
| 0 | main | |
| 2 | disk | /var/lib/proxysql/proxysql.db |
| 3 | stats | |
| 4 | monitor | |
| 5 | stats_history | /var/lib/proxysql/proxysql_stats.db |
+-----+---------------+-------------------------------------+
5 rows in set (0.00 sec)配置后端的mysql后端节点信息:
insert into mysql_servers
(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)
values
(100,'192.168.2.4',19226,1,1000,10,'');
insert into mysql_servers
(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)
values
(1000,'192.168.2.4',19226,1,1000,10,'');
insert into mysql_servers
(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)
values
(1000,'192.168.2.4',19227,1,1000,10,'');
insert into mysql_servers
(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)
values
(1000,'192.168.2.4',19228,1,1000,10,'');
load mysql servers to runtime;
save mysql servers to disk;
Admin> select * from mysql_servers;
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
| hostgroup_id | hostname | port | gtid_port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
| 100 | 192.168.2.4 | 19226 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19226 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19227 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19228 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
4 rows in set (0.00 sec)
Admin> select * from runtime_mysql_servers;
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
| hostgroup_id | hostname | port | gtid_port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
| 100 | 192.168.2.4 | 19226 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19226 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19228 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19227 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
4 rows in set (0.01 sec)配置proxysql上用于对外提供服务的账号密码
insert into mysql_users
(username,password,active,default_hostgroup,transaction_persistent)
values('sbuser','sbuser',1,100,1);
insert into mysql_users
(username,password,active,default_hostgroup,transaction_persistent)
values('ro','ro',1,1000,1);
load mysql users to runtime;
save mysql users to disk;
Admin> select * from mysql_users \G
*************************** 1. row ***************************
username: sbuser
password: sbuser
active: 1
use_ssl: 0
default_hostgroup: 100
default_schema: NULL
schema_locked: 0
transaction_persistent: 1
fast_forward: 0
backend: 1
frontend: 1
max_connections: 10000
comment:
*************************** 2. row ***************************
username: ro
password: ro
active: 1
use_ssl: 0
default_hostgroup: 1000
default_schema: NULL
schema_locked: 0
transaction_persistent: 1
fast_forward: 0
backend: 1
frontend: 1
max_connections: 10000
comment:
2 rows in set (0.00 sec)下面这个配置是核心部分,需要配置下复制组关系。
我这里的配置如下:
insert into mysql_replication_hostgroups
(writer_hostgroup,reader_hostgroup,check_type,comment)
values
(100,1000,'read_only','读写分离高可用');
load mysql servers to runtime;
save mysql servers to disk;
Admin> select * from mysql_replication_hostgroups ;
+------------------+------------------+------------+-----------------------------------+
| writer_hostgroup | reader_hostgroup | check_type | comment |
+------------------+------------------+------------+-----------------------------------+
| 100 | 1000 | read_only | 读写分离高可用 |
+------------------+------------------+------------+-----------------------------------+
1 row in set (0.01 sec)配置完上面的mysql_replication_hostgroups 信息后,我们可以去各个实例上用vc-mysql-sniffer抓包,可以看到 有很多SHOW GLOBAL VARIABLES LIKE 'read_only'; 命令在执行,
这时候,我们再到proxysql admin界面查看下 mysql servers信息,可以看到多了一个server。如下:
Admin> select * from runtime_mysql_servers;
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
| hostgroup_id | hostname | port | gtid_port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
| 100 | 192.168.2.4 | 19226 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19226 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19228 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
| 1000 | 192.168.2.4 | 19227 | 0 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | |
+--------------+-------------+-------+-----------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+
4 rows in set (0.00 sec)我实际用账号连接proxysql进行读写的时候,遇到的问题和 https://github.com/sysown/proxysql/issues/2234 情况一样,需要再设置下面3行命令:
set mysql-set_query_lock_on_hostgroup=0;
load mysql variables to runtime;
save mysql variables to disk;下面开始连接测试
-- 测试只读账号
for i in {1..100}; do mysql -uro -pro -h 192.168.2.4 -P6033 -e 'select * from sbtest.sbtest1 LIMIT 2;' ; sleep 0.5; done
-- 测试读写账号
for i in {1..100}; do mysql -usbuser -psbuser -h 192.168.2.4 -P6033 -e 'insert into sbtest.tb1 select 22,33;'; sleep 0.5; done
然后,可以在proxysql admin控制台查看如下:
Admin> select * from stats_mysql_query_digest LIMIT 3 ;
+-----------+--------------------+----------+----------------+--------------------+--------------------------------------------------------------------+------------+------------+------------+----------+----------+----------+-------------------+---------------+
| hostgroup | schemaname | username | client_address | digest | digest_text | count_star | first_seen | last_seen | sum_time | min_time | max_time | sum_rows_affected | sum_rows_sent |
+-----------+--------------------+----------+----------------+--------------------+--------------------------------------------------------------------+------------+------------+------------+----------+----------+----------+-------------------+---------------+
| 100 | information_schema | sbuser | | 0x226CD90D52A2BA0B | select @@version_comment limit ? | 500 | 1593950681 | 1593950964 | 0 | 0 | 0 | 0 | 0 |
| 1000 | information_schema | ro | | 0x80A87C003F3EDB3A | select * from sbtest.sbtest1 limit ? ,? | 102 | 1593950675 | 1593950887 | 46902 | 300 | 1513 | 0 | 204 |
| 1000 | sbtest | ro | | 0x283AA9863F85EFC8 | SELECT DISTINCT c FROM sbtest4 WHERE id BETWEEN ? AND ? ORDER BY c | 32759 | 1593944506 | 1593944967 | 71107083 | 179 | 121122 | 0 | 3256989 |
+-----------+--------------------+----------+----------------+--------------------+--------------------------------------------------------------------+------------+------------+------------+----------+----------+----------+-------------------+---------------+
3 rows in set (0.01 sec)
-- 可以使用下面命令清空
Admin> select * from stats_mysql_query_digest_reset;
sysbench测试(可选)
export MYSQL_HOST='192.168.2.4'
sysbench /usr/share/sysbench/oltp_read_only.lua --mysql-host=${MYSQL_HOST} --mysql-port=6033 --mysql-user=ro --mysql-password=ro --mysql-db=sbtest --tables=5 --table-size=10000 --mysql_storage_engine=Innodb --threads=16 --time=900 --report-interval=10 --rand-type=uniform run --mysql-ssl=off
sysbench /usr/share/sysbench/oltp_read_write.lua --mysql-host=${MYSQL_HOST} --mysql-port=6033 --mysql-user=sbuser --mysql-password=sbuser --mysql-db=sbtest --tables=5 --table-size=10000 --mysql_storage_engine=Innodb --threads=16 --time=900 --report-interval=10 --rand-type=uniform run --mysql-ssl=off其它
1、replication-manager的参数相关文档 https://docs.signal18.io/configuration/
2、web界面上,将一台主机 设置为维护模式,会自动在proxysql里面设置为OFFLINE_SOFT 下线状态。
*3、如果我们将任意节点关闭掉,可以在proxysql admin界面 执行 select from runtime_mysql_servers; 看到是一个 SHUNNED 状态
4、我们可以在 replication-manager 的web界面上,执行 switchover ,可以看到5秒左右即可完成切换。 另外,如果主从延迟过大,则人工切换是会失败的。
5、上面是1主2从,如果是1主1从,那么从挂了怎么办呢?需要额外一条规则,那就是在mysql_servers的hostgroup 1000 里面要插一条主库的记录,然后把weight设小,当读不到从库,回去主库查询。**