JavaEE学习日志(一百一十二): lucene详解,ik中文分词器
lucene
- lucene概述
- lucene原理
- lucene使用
- 从数据库中获取数据
- 创建索引库
- 图形化界面查询索引库
- 查询索引
- 删除索引
- 更新索引
- ik中文分词器
- 域对象的选择
lucene概述
- lucene就是apache下的一个全文检索工具,一堆的jar包,我们可以使用lucene做一个谷歌和百度一样的搜索引擎系统。
- Lucene是有Doug Cutting 2000年时开发出的第一个版本,后捐献给apache基金会,doug cutting是Lucene、Hadoop(大数据领域的)等项目的发起人。
- lucene 原理 — solr 和 elasticSearch
lucene原理
- 顺序扫描法
描述:带着关键字,一条一条的比较,逐字匹配,直到找到为止
缺点:查询效率低(慢), 随着数据量的大量增长效率会明显降低
优点: 准确率高
举例:数据库中like查询 - 全文检索算法(倒排索引算法)
描述:把数据库中的所有内容都查询出来,然后进行切分词, 把切开分词组成索引(目录),把内容放到文档对象中,
索引与文档组成索引库; 检索时,先查询到索引,索引与文档之间有联系,通过联系可以快速确定文档的位 置,返回文档,这就是倒排索引算法.
缺点:空间换时间
优点:查询效率高,不会随着数据的大量增长而效率明显降低
举例:字典:把所有的字偏旁部首都取出来,组成目录,目录与后面的内容有联系, 通过目录能快速的找到字的详细

lucene使用
从数据库中获取数据
首先创建表

创建pojo和一个dao
public class Book {
private Integer id;
private String name;
private String pic;
private Double price;
private String description;
//....省略
}
public class BookDao {
/**
* 查询全部
* @return
*/
public List<Book> findAll(){
List<Book> bookList = new ArrayList<>();
//注册驱动
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
String url = "jdbc:mysql://localhost:3306/lucene_331";
String username = "root";
String password = "root";
Connection conn = null;
PreparedStatement pst = null;
ResultSet rs = null;
try {
//获取连接
conn = DriverManager.getConnection(url,username,password);
//sql语句
String sql = "select * from book";
//创建statement对象
pst = conn.prepareStatement(sql);
//执行sql语句返回结果集
rs = pst.executeQuery();
//处理结果集
while (rs.next()){
Book book = new Book();
//封装book对象
book.setId(rs.getInt("id"));
book.setName(rs.getString("name"));
book.setPic(rs.getString("pic"));
book.setPrice(rs.getDouble("price"));
book.setDescription(rs.getString("description"));
bookList.add(book);
}
//返回结果
return bookList;
} catch (SQLException e) {
e.printStackTrace();
} finally {
//释放资源
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (pst!=null){
try {
pst.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
return null;
}
}
创建索引库
引入新的依赖
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-analyzers-commonartifactId>
<version>4.10.3version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>4.10.3version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>4.10.3version>
dependency>
<dependency>
<groupId>com.janeluogroupId>
<artifactId>ikanalyzerartifactId>
<version>2012_u6version>
dependency>
步骤
- 创建分词器对象
- 指定索引库位置
- 查询所有内容
- 把内容放入文档对象中
- 获得索引输出流对象
- 把文档对象写入到索引库
- 提交数据
- 关闭流
/**
* 创建索引
*/
public class CreateIndex {
@Test
public void test() throws IOException {
//1.创建分词器对象
Analyzer analyzer = new StandardAnalyzer();
//2.指定索引库位置
FSDirectory fsDirectory = FSDirectory.open(new File("f:/dic"));
//3.查询所有内容
BookDao bookDao = new BookDao();
List<Book> bookList = bookDao.findAll();
//4.把内容放入文档对象中
//创建文档集合对象
List<Document> docList = new ArrayList<>();
//一条记录对应一个文档,一条记录对应一个book对象
for (Book book : bookList) {
//创建一个文档对象
Document doc = new Document();
//一列对应一个域
//创建域对象
/**
* 参数1:域的名称
* 参数2:域中存储的值
* 参数3:是否存储
*/
TextField idField = new TextField("id",String.valueOf(book.getId()), Field.Store.YES);
TextField nameField = new TextField("name",book.getName(), Field.Store.YES);
TextField picField = new TextField("pic",book.getPic(), Field.Store.YES);
TextField priceField = new TextField("price",String.valueOf(book.getPrice()), Field.Store.YES);
TextField descriptionField = new TextField("description",book.getDescription(), Field.Store.YES);
//把所有的域对象添加到文档中
doc.add(idField);
doc.add(nameField);
doc.add(picField);
doc.add(priceField);
doc.add(descriptionField);
//把文档对象添加到集合中
docList.add(doc);
}
//5.获得索引输出流对象
/**
* 参数1:版本号
* 参数2:分词器
*/
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3,analyzer);
/**
* 参数1:索引库的位置对象
* 参数2:索引输出流的配置对象
*
*/
IndexWriter indexWriter = new IndexWriter(fsDirectory, config);
//6.把文档对象写入到索引库
//遍历文档对象,添加到索引库
for (Document document : docList) {
indexWriter.addDocument(document);
}
//7.提交数据
indexWriter.commit();
//8.关闭流
indexWriter.close();
}
}
图形化界面查询索引库
运行jar包
![]()

浏览仓库

左下角:显示所有的索引
Term count:分词的数量
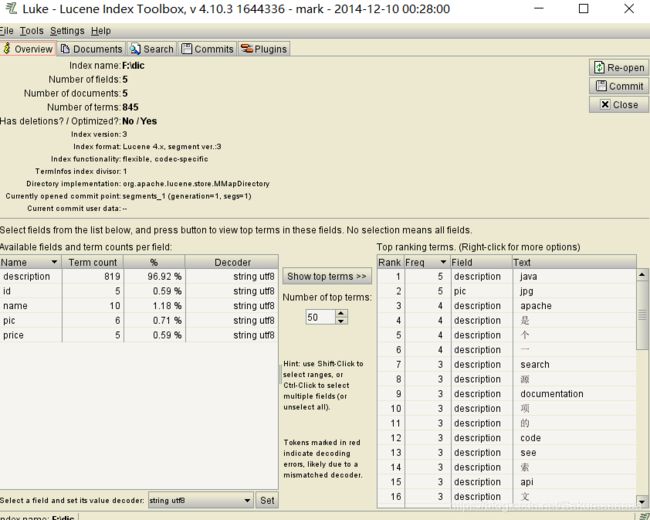
查看name的分词,会发现他把每一个字都给拆分了
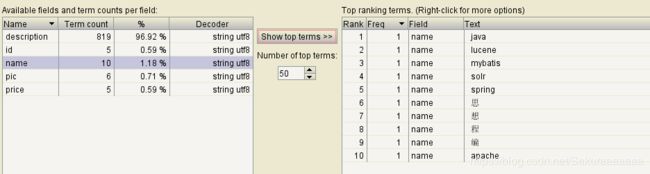
点击上方的Documents,可以查看文档对象,编号从0开始
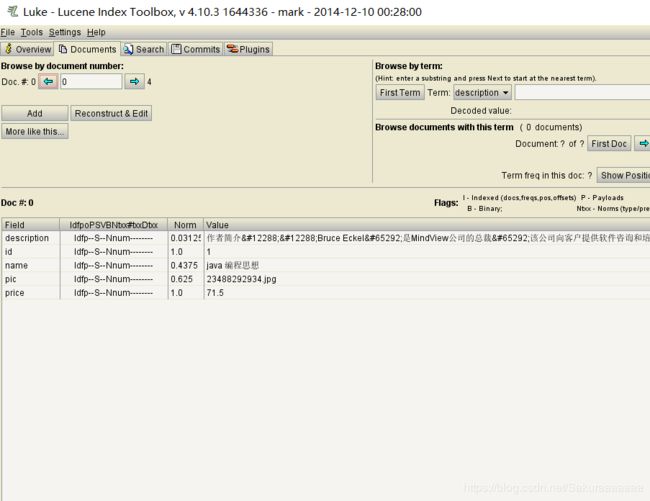
点击search选项卡,可以进行搜索
score:搜索之后会对搜索的结果进行打分

查询索引
- 创建索引库的位置对象
- 创建分词器对象 – 创建索引库与查询索引使用的分词器对象必须同一个
- 查询索引对象
- 查询的关键字对象
public class SearchIndex {
@Test
public void test() throws IOException, ParseException {
//1.创建索引库的位置对象
FSDirectory directory = FSDirectory.open(new File("f:/dic"));
//2.创建分词器对象 -- 创建索引库与查询索引使用的分词器对象必须同一个
Analyzer analyzer = new StandardAnalyzer();
//3.查询索引对象
//创建索引输入流对象:索引库的位置对象
IndexReader indexReader = IndexReader.open(directory);
/**
* 参数:索引输入流对象
*/
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//4.查询的关键字对象
//查询分析对象
/**
*参数1:默认域,如果查询时没有使用域,使用默认域;如果指定,使用指定域
*参数2:分词器
*
*/
QueryParser queryParser = new QueryParser("name",analyzer);
//通过查询解析对象获取查询关键字对象
Query query = queryParser.parse("id:1");
/**
* 参数1:查询的关键字对象
* 参数2:查询的记录数
* 返回值:顶部的文档对象
*/
TopDocs topDocs = indexSearcher.search(query, 2);
//显示结果
//得到分数文档对象数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历数组
for (ScoreDoc scoreDoc : scoreDocs) {
//获取的分数文档对象的编号
int docId = scoreDoc.doc;
//根据文档id获取真正的文档对象
Document doc = indexSearcher.doc(docId);
//获取域中的值
System.out.println("id域的值:"+doc.get("id"));
System.out.println("name域的值:"+doc.get("name"));
System.out.println("pic域的值:"+doc.get("pic"));
System.out.println("price域的值:"+doc.get("price"));
System.out.println("description域的值:"+doc.get("description"));
}
}
}
删除索引
删除操作只删除文档,不删除索引
public class DeleteIndex {
@Test
public void test() throws IOException {
//1、索引库的位置
FSDirectory directory = FSDirectory.open(new File("f:/dic"));
//2、分词器对象
Analyzer analyzer = new StandardAnalyzer();
//3、删除的关键字对象 --term 分词对象
Term term = new Term("id","1");
//4、输出流对象
//索引输出流配置对象
IndexWriterConfig writerConfig = new IndexWriterConfig(Version.LUCENE_4_10_3,analyzer);
//创建输出流对象
IndexWriter indexWriter = new IndexWriter(directory,writerConfig);
//5、执行删除操作
indexWriter.deleteDocuments(term);
//6、提交
indexWriter.commit();
//7、释放资源
indexWriter.close();
}
}
如果执行indexWriter.deleteAll();,则会将索引和文档对象全部删除
更新索引
更新之后,原索引保留,原文档删除,添加一个新的文档,更新索引
/**
* 更新索引
*/
public class UpdateIndex {
@Test
public void test() throws IOException {
//1.索引库位置
FSDirectory directory = FSDirectory.open(new File("f:/dic"));
//2.分词器对象
Analyzer analyzer = new StandardAnalyzer();
//3.关键字
Term term = new Term("id","2");
//4.输出流对象
//创建输出流配置对象
IndexWriterConfig writerConfig = new IndexWriterConfig(Version.LUCENE_4_10_3,analyzer);
//创建输出流对象
IndexWriter indexWriter = new IndexWriter(directory,writerConfig);
//5.更新操作
//创建更新后的文档对象
Document doc = new Document();
//创建域对象
TextField idField = new TextField("id",String.valueOf(6), Field.Store.YES);
TextField nameField = new TextField("name","水浒传", Field.Store.YES);
TextField picField = new TextField("pic","123.jpg", Field.Store.YES);
TextField priceField = new TextField("price",String.valueOf(18.0), Field.Store.YES);
TextField descriptionField = new TextField("description","非常好看,水浒英雄传,替天行道", Field.Store.YES);
//将域添加到文档
doc.add(idField);
doc.add(nameField);
doc.add(picField);
doc.add(priceField);
doc.add(descriptionField);
indexWriter.updateDocument(term,doc);
//6.提交
indexWriter.commit();
//7.释放资源
indexWriter.close();
}
}
ik中文分词器
可以解析中文语法
引入依赖
<dependency>
<groupId>com.janeluogroupId>
<artifactId>ikanalyzerartifactId>
<version>2012_u6version>
dependency>
在IKAnalyzer.cfg.xml中可以配置扩展配置
如下:
- 可在
ext.dic文件中配置扩展词汇 - 可在
stopword.dic文件中配置停止词汇
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">ext.dic;entry>
<entry key="ext_stopwords">stopword.dic;entry>
properties>
将这三个文件加入到resources文件夹下

只需要在代码中更改
Analyzer analyzer = new IKAnalyzer();
/**
* 创建索引
*/
public class CreateIndex {
@Test
public void test() throws IOException {
//1.创建分词器对象
//Analyzer analyzer = new StandardAnalyzer();
//1.1创建中文分词器
Analyzer analyzer = new IKAnalyzer();
//2.指定索引库位置
FSDirectory fsDirectory = FSDirectory.open(new File("f:/dic"));
//3.查询所有内容
BookDao bookDao = new BookDao();
List<Book> bookList = bookDao.findAll();
//4.把内容放入文档对象中
//创建文档集合对象
List<Document> docList = new ArrayList<>();
//一条记录对应一个文档,一条记录对应一个book对象
for (Book book : bookList) {
//创建一个文档对象
Document doc = new Document();
//一列对应一个域
//创建域对象
/**
* 参数1:域的名称
* 参数2:域中存储的值
* 参数3:是否存储
*/
TextField idField = new TextField("id",String.valueOf(book.getId()), Field.Store.YES);
TextField nameField = new TextField("name",book.getName(), Field.Store.YES);
TextField picField = new TextField("pic",book.getPic(), Field.Store.YES);
TextField priceField = new TextField("price",String.valueOf(book.getPrice()), Field.Store.YES);
TextField descriptionField = new TextField("description",book.getDescription(), Field.Store.YES);
//把所有的域对象添加到文档中
doc.add(idField);
doc.add(nameField);
doc.add(picField);
doc.add(priceField);
doc.add(descriptionField);
//把文档对象添加到集合中
docList.add(doc);
}
//5.获得索引输出流对象
/**
* 参数1:版本号
* 参数2:分词器
*/
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3,analyzer);
/**
* 参数1:索引库的位置对象
* 参数2:索引输出流的配置对象
*
*/
IndexWriter indexWriter = new IndexWriter(fsDirectory, config);
//6.把文档对象写入到索引库
//遍历文档对象,添加到索引库
for (Document document : docList) {
indexWriter.addDocument(document);
}
//7.提交数据
indexWriter.commit();
//8.关闭流
indexWriter.close();
}
}
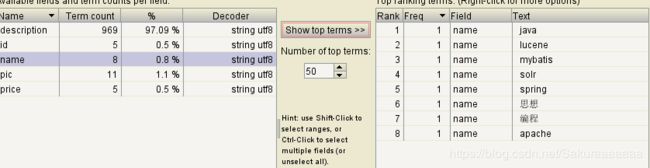
结果:思想成为一个词,编程也成为一个词
域对象的选择
Field域的类型

域的选择
一、是否分词:分词的目的就是索引,分词后是否有意义,如果有意义则分词,无意义则不分词。
- 是:需要分词
例如:name,description,price(区间检索) - 否:不需要分词
举例:id,pic
二、是否索引:查询时,是否需要用到索引(查询时是否需要用到该字段)
- 是:查询时需要索引
例如:name,price,description,id - 否:查询时不需要索引
例如:pic
三、是否存储:是否存储到索引库中,在查询页面需要展示就需要存储,不需要展示就不需要存储
- 是:需要展示
举例:name,pic,price,id - 否:不需要展示
举例:description
注意:
- 如果在检索时,需要区间(范围)检索,则必须分词,必须索引,必须存储。(lucene底层规则)
- 描述信息一般不存储,数据量太大。如果需要描述信息,通过隐藏域中的id值,通过jdbc快速来查询描述信息并返回。