Linux 多线程服务器端编程:使用 muduo C++ 网络库
目录
一、线程同步精要
互斥器 mutex
条件变量
封装 MutexLock、MutexLockGuard 和 Condition
线程安全的 Singleton 实现
一、线程同步精要
并发编程的两种基本模型:message passing 和 shared memory。
线程同步的四项原则:
- 尽量最低限度的共享对象,减少需要同步的场合。尽量避免对象暴露给其他线程,如果要暴露,优先考虑 immutable 对象;无可避免时才暴露可修改的对象,并用同步措施充分保护它。
- 使用高级的并发编程构件,如 TaskQueue、CountDownLaunch 等等。
- 不得已使用底层同步原语时,只使用非递归的互斥器和条件变量,慎用读写锁,不使用信号量。
- 除了使用 atomic 整数之外,不自己编写 lock-free 代码。
互斥器 mutex
保护了临界区,任何一个时刻最多只能有一个线程在此 mutex 划出的临界区内活动。
主要原则:
- 只用非递归的 mutex(即不可重入的 mutex)。
- 不手动调用 lock() 和 unlock() 函数,一切交给栈上的 guard 对象的构造和析构函数负责,保证始终在同一个函数同一个 scope 里对某个 mutex 加锁和解锁,其生命周期正好等于临界区。
- 每次构造 guard 对象的时候,思考一路上(调用栈上)已经持有的锁,防止因加锁顺序不同而导致死锁。由于 guard 对象是栈上对象,看函数调用栈就能分析用锁的情况。
次要原则:
- 不使用跨进程的 mutex ,进程间通信只用 TCP sockets
- 加锁解锁在同一个线程
只使用非递归的 mutex
非递归的 mutex 即非可重入的 mutex。同一个线程不能重复对 非递归的 mutex 进行加锁。
死锁
情景一:线程自己与自己死锁
class Request{
public:
void process(){
muduo::MutexLockGuard lock(mulex_);
//...
print(); //lead to deadlock
}
void print() const{
muduo::MutexLockGuard lock(mulex_);
//...
}
private:
mutable muduo::MulexLock mutex_;
}
int main(){
Request req;
req.process();
}要定位这种死锁,只要把函数调用栈打印出来,结合源码一看,就能发现第6帧 Request::process() 和第5帧 Request::print() 先后对同一个 mutex 上锁,引发了死锁。
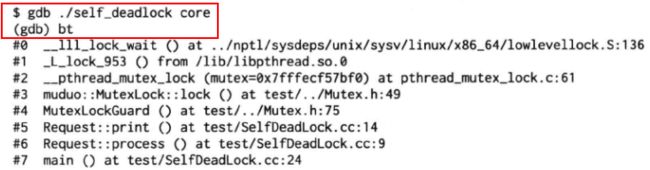
修复方法:从 Request::print() 抽取出 Request::printWithLockHold(),并让 Request::print() 和 Request::process() 都调用它即可。
class Request{
public:
void process(){
muduo::MutexLockGuard lock(mulex_);
//...
printWithLockHold(); //lead to deadlock
}
void print() const{
muduo::MutexLockGuard lock(mulex_);
printWithLockHold();
}
void printWithLockHold() const{
doprint;
//...
}
private:
mutable muduo::MulexLock mutex_;
}
int main(){
Request req;
req.process();
}情景二:两个线程死锁
有一个 Inventory (清单) class,记录当前的 Request 对象,容易看出,下面这个 Inventory class 的 add() 和 remove() 成员函数都是线程安全的,使用了 mutex 来保护共享数据 request_。

Request class 在处理(process)时,往 g_inventory 中添加自己。析构的时候,从 g_inventory 中移除自己。


Inventory class 的 printall 函数功能是打印全部一致的 Request 对象,单独看逻辑是没有问题的,但是它有可能应发典型的两个进程的死锁。
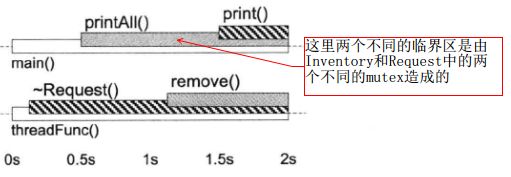
修复方法:1.将 print() 移出 printAll() 的临界区,2.把 remove() 移出 ~Request() 的临界区 借助 shared_ptr 实现 copy_on_write(下文)
条件变量
互斥锁是加锁原语,用来排他性的访问共享数据,他不是等待原语。使用 mutex 的时候,一般都希望加锁不要阻塞,能立刻拿到锁,然后尽快访问数据,用完之后尽快解锁,这样才能不影响并发性和性能。
如果需要等待某个条件成立,我们应该使用条件变量。条件变量顾名思义就是一个或者多个线程等待某个布尔表达式为真,即等待别的线程 唤醒 它。条件变量的学名叫做 管程。
- 条件变量的使用过程如下:
- 拥有条件变量的线程获取互斥锁
- 循环检查某个条件,如果条件不满足,则阻塞直到条件满足,如果条件满足,则向下执行
- 某个线程满足条件执行完之后,调用notify_one或notify_all唤醒一个或者所有的等待线程
- 条件变量只有一种正确的使用方式。对于 wait 端:
- 必须和 mutex 一起使用,该布尔表达式的读写需受到此 mutex 保护
- 在 mutex 上锁的时候才能调用 wait()
- 把判断布尔条件和 wait() 放入 while 循环中

spurious wakeups:虚假唤醒
查阅了很多资料,发现网上说的很多关于spurious wakeups 的描述都是错误的。
第一次遇到 spurious wakeups 是在使用条件变量时,一个典型的条件变量使用样例如:
// wait 端
pthread_mutex_lock(mtx);
while(deque.empty())
pthread_cond_wait(...);
deque.pop_front();
pthread_mutex_unlock(mtx);
// signal 端
pthread_mutex_lock(mtx);
deque.push_back(x);
pthread_cond_signal(...);
pthread_mutex_unlock(mtx);
在 wait 端必须使用 while 来等待条件变量而不能使用 if 语句,原因在于 spurious wakeups,即虚假唤醒。虚假唤醒很容易被人误解为:如果有多个消费者,这些消费者可能阻塞在同一位置。当生产者通知 not empty 时,deque立即被第一个被唤醒的消费者清空,则后面的消费者相当于时被虚假唤醒了。
这种情况完全可以通过使用 signal 而非 broadcast 解决。signal 只会唤醒某个线程,唤醒的依据为等待线程的优先级,若优先级相同,则依据线程的等待时长。
上述现象类似于惊群现象:
惊群效应就是当一个 fd 的事件被触发时,所有等待这个 fd 的线程或进程都被唤醒。一般都是 socket 的 accept() 会导致惊群(当然也可以弄成一堆线程/进程阻塞 read 一个 fd,但这样写应该没什么意义吧),很多个进程都 block 在 server socket 的 accept(),一但有客户端进来,所有进程的 accept() 都会返回,但是只有一个进程会读到数据,就是惊群。实际上现在的 Linux 内核实现中不会出现惊群了,只会有一个进程被唤醒(Linux2.6内核)。
虚假唤醒的正解是:
wikipedia 中有关于 spurious wakeups 的大致描述:
According to David R. Butenhof's Programming with POSIX Threads ISBN 0-201-63392-2:"This means that when you wait on a condition variable,the wait may (occasionally) return when no thread specifically broadcast or signaled that condition variable.Spurious wakeups may sound strange, but on some multiprocessor systems, making condition wakeup completely predictable might substantially slow all condition variable operations. The race conditions that cause spurious wakeups should be considered rare."
其中提到,即使没有线程 broadcast 或者 signal 条件变量,wait 也可能偶尔返回,即处理机制导致的逻辑错误唤醒,只能通过这样的无理由的操作来避免。
对于 signal / broadcast 端:
- 不一定要在 mutex 已上锁的情况下调用 signal
- 在 signal 之前一般要修改布尔表达式
- 修改布尔表达式通常要用 mutex 保护
- 区分 signal 和 broadcast:broadcast 通常用于表明状态变化,signal 通常用于表示资源可用

条件变量是非常底层的同步原语,很少直接使用,一般都是用它来实现高层的同步措施,如 BlockingQueue 或 CountDownLatch。
倒计时(CountDownLatch)是一种常见且易用的同步手段。主要的两种用途有:
-
主线程发起多个子线程,等这些子线程各自都完成一定的任务之后,主线程才继续执行。通常用于主线程等待多个子线程完成初始化。
-
主线程发起多个子线程,子线程都等待主线程完成一些其他任务之后才开始执行。通常用于多个子线程等待主线程发出“起跑”命令。

互斥器和条件变量构成了多线程编程的全部必备同步原语,用它们即可完成任何多线程的同步任务,二者不能相互替代。
封装 MutexLock、MutexLockGuard 和 Condition
MutexLock 封装临界区,一般是别的 class 的数据成员。
MutexLockGuard 封装临界区的进入和退出,即加锁和解锁。MutexLockGuard 一般是一个栈上对象,作用域刚好等于临界区域。


Condition class 的实现,原来的库中对 condition_variable 提供了许多的灵活性,但实际使用是时只需要将 condition_variable 与 mutex 一对一使用,用起来也容易。
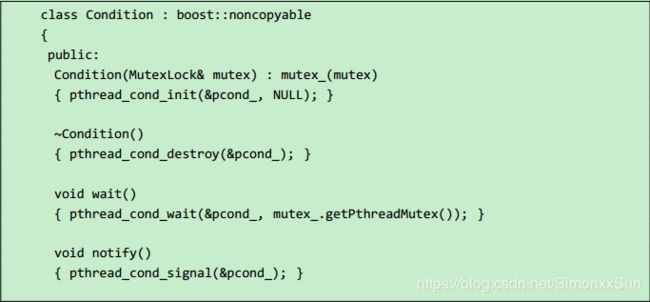
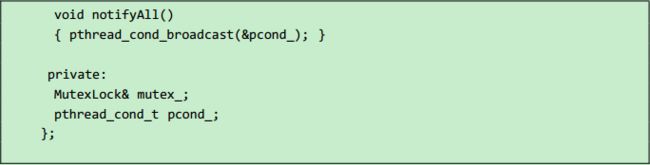
如果一个 class 要包含 MutexLock 和 Condition,请注意它们的声明顺序和初始化顺序,mutex_ 应先于 condition_ 构造,并作为后者的参数:

Mutex 和 条件变量都是非诚底层的同步原语,虽然花费了一些篇幅来介绍它们,但其实很少直接使用,一般都是用它们来实现高层的同步措施,如 BlockingQueue 或 CountDownLatch。
线程安全的 Singleton 实现
单例模式
单例模式,是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例的特殊类。通过单例模式可以保证系统中,应用该模式的一个类只有一个实例。即一个类只有一个对象实例。
两种构建方式:
- 懒汉方式。指全局的单例实例在第一次被使用时构建。
- 饿汉方式。指全局的单例实例在类装载时构建。
如何保证一个类只有一个实例并且这个实例易于被访问呢?定义一个全局变量可以确保对象随时都可以被访问,但不能防止我们实例化多个对象。一个更好的解决办法是让类自身负责保存它的唯一实例。这个类可以保证没有其他实例被创建,并且它可以提供一个访问该实例的方法(静态方法)。这就是单例模式的模式动机。
要点有三个:
某个类只能有一个实例;
它必须自行创建这个实例;
三是它必须自行向整个系统提供这个实例。
实现角度来说,就是以下三点:一是单例模式的类只提供私有的构造函数,二是类定义中含有一个该类的静态私有对象,三是该类提供了一个静态的公有的函数用于创建或获取它本身的静态私有对象。
//饿汉模式
template
class singleton
{
protected:
singleton(){};
private:
singleton(const singleton&) = delete;//禁止拷贝
singleton& operator=(const singleton&) = delete;//禁止赋值
static T* m_instance;
public:
static T* GetInstance();
};
template
T* singleton::GetInstance()
{
return m_instance;
}
template
T* singleton::m_instance = new T(); 这种写法就是所谓的饥饿模式,每个对象在没有使用之前就已经初始化了。在实例化m_instance 变量时,直接调用类的构造函数。顾名思义,在还未使用变量时,已经对m_instance进行赋值,就像很饥饿的感觉。这种模式,在多线程环境下肯定是线程安全的,因为不存在多线程实例化的问题。 这就可能带来潜在的性能问题:如果这个对象很大呢?没有使用这个对象之前,就把它加载到了内存中去是一种巨大的浪费。
针对这种情况,我们可以对以上的代码进行改进,使用一种新的设计思想——延迟加载(Lazy-load Singleton)。
//懒汉模式
template
class singleton
{
protected:
singleton(){};
private:
singleton(const singleton&) = delete;
singleton& operator=(const singleton&) = delete;
static T* m_instance;
public:
static T* GetInstance();
};
template
T* singleton::GetInstance()
{
if( m_instance == NULL)
{
m_instance = new T();
}
return m_instance;
}
template
T* singleton::m_instance = NULL; 这种写法就是所谓的懒汉模式。它使用了延迟加载来保证对象在没有使用之前,是不会进行初始化的。
但是,通常这个时候面试官又会提问新的问题来刁难一下。他会问:这种写法线程安全吗?回答必然是:不安全。这是因为在多个线程可能同时运行到 GetInstance(),判断 m_instance 为 null,于是同时进行了初始化。所以,这是面临的问题是如何使得这个代码线程安全?要实现线程安全,就必须加锁。
//Lazy Singleton with mutex
template
class singleton
{
protected:
singleton(){};
private:
singleton(const singleton&) = delete;
singleton& operator=(const singleton&) = delete;
static T* m_instance;
static pthread_mutex_t mutex;
public:
static T* GetInstance();
};
template
T* singleton::GetInstance()
{
pthread_mutex_lock(&mutex);
if( m_instance == NULL)
{
m_instance = new T();
}
pthread_mutex_unlock(&mutex);
return m_instance;
}
template
pthread_mutex_t singleton::mutex = PTHREAD_MUTEX_INITIALIZER;
template
T* singleton::m_instance = NULL; 写到这里,面试官可能仍然会狡猾的看了你一眼,继续刁难到:这个写法有没有什么性能问题呢?答案肯定是有的!同步的代价必然会一定程度的使程序的并发度降低。 GetInstance()方法,每次进来都要加锁,会影响效率。然而这并不是必须的,于是又对GetInstance()方法进行改进。那么有没有什么方法,一方面是线程安全的,有可以有很高的并发度呢?我们观察到,线程不安全的原因其实是在初始化对象的时候,所以,可以想办法把同步的粒度降低,只在初始化对象的时候进行同步。这里有必要提出一种新的设计思想——双重检查锁(Double-Checked Lock)。
template
T* singleton::GetInstance()
{
if( m_instance == NULL)
{
pthread_mutex_lock(&mutex);
if( m_instance == NULL) //双检锁机制
{
m_instance = new T();
}
pthread_mutex_unlock(&mutex);
}
return m_instance;
} 这也就是所谓的“双检锁”机制。但是有人质疑这种实现还是有问题,在执行 m_instance = new T()时,可能 类T还没有初始化完成,m_instance 就已经有值了。这样会导致另外一个调用GetInstance()方法的线程,获取到还未初始化完成的m_instance 指针,如果去使用它,会有意料不到的后果。其实,解决方法也很简单,用一个局部变量过渡下即可:
template
T* singleton::GetInstance()
{
if( m_instance == NULL)
{
pthread_mutex_lock(&mutex);
if( m_instance == NULL)
{
T* ptmp = new T();
m_instance = ptmp;
}
pthread_mutex_unlock(&mutex);
}
return m_instance;
} 到这里在懒汉模式下,也就可以保证线程安全了。
陈硕所建议的做法:在 Linux 下利用POSIX标准 pthread.h 中的 pthread_once(),可以实现 once_run()函数仅执行一次,且究竟在哪个线程中执行是不定的,尽管pthread_once(&once,once_run)出现在两个线程中。、

LinuxThreads使用互斥锁和条件变量保证由 pthread_once() 指定的函数执行且仅执行一次,而 once_t 则表征是否执行过。注意 once_t 的初值必须设置为 PTHREAD_ONCE_INIT(LinuxThreads定义为0),否则pthread_once() 的行为就会不正常。
mutex 与 shared_ptr 的应用实例
- 用普通的 mutex 与 shared_ptr 替换读写锁 copy-on-other-reading
- 使用 shared_ptr 实现 copy_on_write
- 使用 shared_ptr 解决析构的 race condition
1.mutex 与 shared_ptr 替换读写锁 copy-on-other-reading
读写锁的开销比普通的 mutex 要大,而且是写锁优先,会阻塞后面的写锁。
场景:一个多线程的 C++ 程序,有几个工作线程 Worker{0,1,2,3},处理用户发过来的交易请求;另外有一个背景线程ground,不定期更新程序内部的参考数据。这些线程都跟一个 hash(map) 表打交道,工作线程只读,背景线程读写,必然用到一些同步机制,防止数据损坏。
Map 的 Key 是用户名,value 是一个 vector,里面存的是不同的 stock 的最小交易间隔,vector 已经排好序,可以用二分查找。
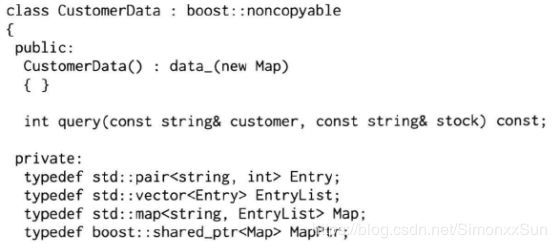

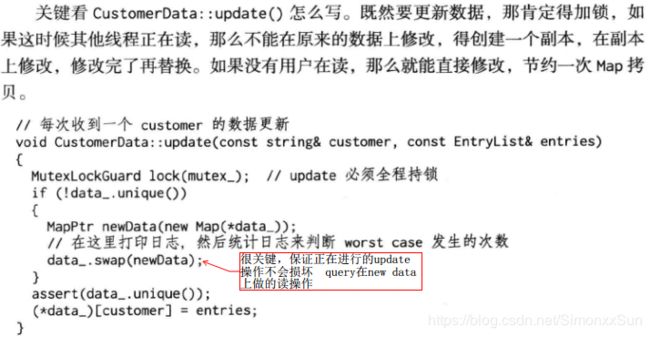
此处 swap 函数是改变了两个 shared_ptr 的指向,使 query 操作读到的是交换到 newdata 上的旧数据,update 更新的是在 data_ 上复制出来的新数据。
2.使用 shared_ptr 实现 copy_on_write
- 利用 shared_ptr 的智能指针特性,如果当前只有一个观察者,那么引用计数的值为1。
- 对于 write 端,如果发现引用计数为1(shared_ptr.unique()方法),这时可以安全的修改共享对象,不必担心有人正在读它。
- 对于 read 端,在读之前把引用计数加1,读完之后减1,这样保证在读的期间其引用计数大于1,可以防止并发写。
- 需要考虑的是,对于 write 端,如果发现引用计数大于1,该如何处理,sleep() 一小段时间肯定是错的。

- 要考虑的是,对于 write 端,如果发现引用计数大于1,该如何处理?如果使用 shared_ptr.unique() 方法返回的值为false,说明这时别的线程正在读取 FooList ,我们不能原地修改,而是复制一份,在副本上做修改,这样就避免了死锁。

使用原 g_foos 所指向的对象的数据 new 一个新的对象,并将其指针管理赋值给新的 g_foos 并在其之上完成修改操作,已指向原有的 g_foos 的指针位置不受影响,可以继续读。
3.使用 shared_ptr 解决析构的 race condition
一个线程的 observer 对象正在析构,但是另一个线程正在调用这个 observer 对象的方法,就会造成析构的 race condition。
- 使用shared_ptr 可以控制对象的生命期。shared_ptr 是强引用,只要有一个指向 x 对象的 shared_ptr 存在,该 x 对象就不会析构。当指向对象 x 的最后一个 shared_ptr 析构或 reset() 的时候,x 保证会被销毁。
- weak_ptr 不能控制对象的生命期,但是它知道对象是否还“活着”。如果对象还活着,那么它可以提升(promote)为有效的 shared_ptr;如果对象已经析构了,提升会失败,返回一个空的 shared_ptr。“提升 - weak_ptr.lock()”行为是线程安全的。weak_ptr设计之初就是为了服务于shared_ptr的,所以不增加引用计数就是它的核心功能。

万一 L62 的 update() 虚函数中调用了 (un)register 呢?如果 mutex_ 是不可重入的,那么会死锁;如果 mutex_ 是可重入的,程序会面临迭代器失效(core dump 是最好的结果),因为 vector observers_ 在遍历期间被意外地修改了。
提升成功,则将有 obj 与 it(由 weak_ptr 提升为 shared_ptr)两个 shared_ptr 指向原数据,所以引用计数至少为2。