HBase命令行客户端+架构 笔记
文章目录
- 数据类型
- 安装集群
- 配置文件
- 配置环境变量
- HBase远程发送到其他集群
- 启动
- 查看HBase页面
- 命令行客户端
- DDL
- 建表
- 查看表详情
- 修改列族
- 删除表
- DML
- put
- scan
- get
- 删除
- 清空表
- 命名空间操作
- 查看底层数据
- 查看删除的版本信息
- 删除策略(3种)
- 查看hbase:meta
- RegionServer架构
- 写流程
- MemStore Flush
- 刷写时机
- 手动flush
- 读流程
- StoreFile Compaction
- Region Split
- Region Split时机
数据类型
传统:数据库->表->行->
hbase:命名空间(namespce)->table ->列族 ->行 ->列
逻辑结构
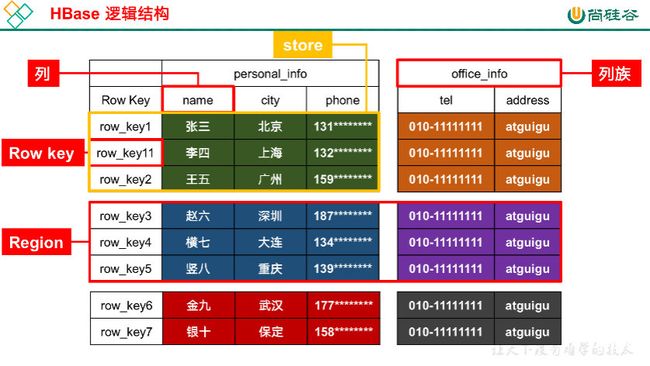
官方不建议列族超过2个
列族里可以创建无限个列
列族:列名
安装集群
准备工作
zookeeper ,hdfs
配置文件
hbase-env.sh
125行
:set num
export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://hadoop130:9820/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>hadoop130,hadoop133,hadoop134value>
property>
<property>
<name>hbase.unsafe.stream.capability.enforcename>
<value>falsevalue>
property>
<property>
<name>hbase.wal.providername> //预写日志
<value>filesystemvalue>
property>
configuration>
regionservers
hadoop130
hadoop133
hadoop134
配置环境变量
/etc/profile.d/my_env.sh
export HBASE_HOME=/opt/module/hbase-2.0.5
export PATH=$PATH:$HBASE_HOME/bin
HBase远程发送到其他集群
xsync hbase/
启动
1.先启动hdfs
2.启动zookeeper
3.hbase集群有两种角色
master,rigonsever
单启
群起
start-hbase.sh
1.在当前节点起一个master
2.在所有节点(reginservers)起regionserver
查看HBase页面
master: http://hadoop130:16010
Region:16030

系统表里有2个表
Zk->meta->region
meta:原数据 确定在哪个region
namespace
命令行客户端
DDL
进入客户端
[vanas@hadoop130 conf]$ hbase shell
hbase(main):001:0> help
hbase(main):002:0> list //列出所有用户表
建表
help ‘create’
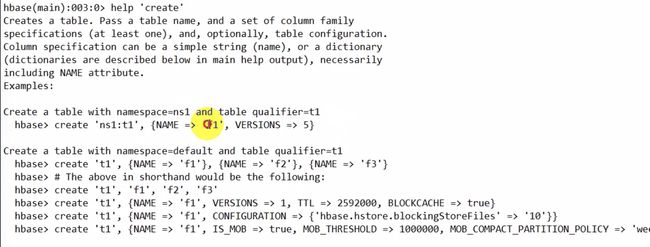
create 'student','info'
查看表详情
desc 'student'

hbase(main):002:0> desc 'user'
Table user is ENABLED
user
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE',
CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BL
OOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPE
N => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
1 row(s)

修改列族
修改版本
alter 'student',{NAME=>'info',VSRSIONS=>3}
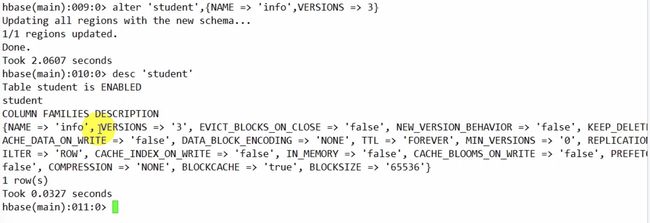
添加列族
alter 'student',{NAME=>'msg'}

删除列族
alter 'student','delete'=>'msg'
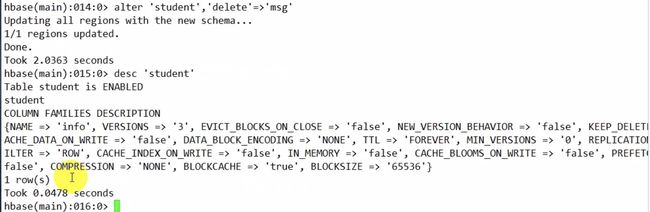
删除表
enable表示可以往里写也可以读
disable表示不可写不可读 表还在
disable 'student'
enable 'student'
disable 后再drop
hbase(main):004:0> drop 'user' //表里有内容需要disable
ERROR: Table user is enabled. Disable it first.
Drop the named table. Table must first be disabled:
hbase> drop 't1'
hbase> drop 'ns1:t1'
Took 0.0195 seconds
hbase(main):005:0> disable 'user'
Took 0.4406 seconds
hbase(main):019:0> drop 'user'
Took 0.2415 seconds
hbase(main):020:0> list
TABLE
0 row(s)
Took 0.0078 seconds
=> []
DML
put
加和修改都用put
put 'student','1001','info:name','zhangsan'
put 'student','1001','info:name','lisi'
scan
全表扫描,使用慎重
最好加一些范围
hbase(main):003:0> create 'user','cf1','cf2'
hbase(main):005:0> scan 'user' //全表扫描
ROW COLUMN+CELL
0 row(s)
hbase(main):006:0> put 'user','1001','cf1:name','zs'
hbase(main):007:0> scan 'user'
ROW COLUMN+CELL
1001 column=cf1:name, timestamp=1592882972801, value=zs
1 row(s)
hbase(main):008:0> put 'user','1001','cf1:age',10 //都是字节 ‘10’
hbase(main):009:0> scan 'user' //字母序升序
ROW COLUMN+CELL
1001 column=cf1:age, timestamp=1592883069488, value=10
1001 column=cf1:name, timestamp=1592882972801, value=zs
1 row(s)
hbase(main):010:0> put 'user','1002','cf1:name','lisi'
Took 0.0136 seconds
hbase(main):011:0> scan 'user'
ROW COLUMN+CELL
1001 column=cf1:age, timestamp=1592883069488, value=10
1001 column=cf1:name, timestamp=1592882972801, value=zs
1002 column=cf1:name, timestamp=1592883223340, value=lisi
2 row(s)
hbase(main):012:0> put 'user','1002','cf2:sex','male'
Took 0.0107 seconds
hbase(main):013:0> scan 'user'
ROW COLUMN+CELL
1001 column=cf1:age, timestamp=1592883069488, value=10
1001 column=cf1:name, timestamp=1592882972801, value=zs
1002 column=cf1:name, timestamp=1592883223340, value=lisi
1002 column=cf2:sex, timestamp=1592883280626, value=male
2 row(s)
带范围
scan 'student',{STARTROW=>'1002',STOPROW=>'1004'}

hbase(main):002:0> scan 'user',{ STARTROW => '1001',STOPROW => '1002_'}
ROW COLUMN+CELL
1001 column=cf1:age, timestamp=1592883069488, value=10
1001 column=cf1:name, timestamp=1592882972801, value=zs
1002 column=cf1:name, timestamp=1592883223340, value=lisi
1002 column=cf2:sex, timestamp=1592883280626, value=male
2 row(s)
Took 0.0265 seconds
hbase(main):003:0> count 'user'
2 row(s)
Took 0.0309 seconds
=> 2
要考虑字典序的问题
取范围后面加个!(!靠前的字符)
scan 'student',{STARTROW=>'1002',STOPROW=>'1003!'}
get
查找一行
hbase(main):014:0> get 'user','1001'
COLUMN CELL
cf1:age timestamp=1592883069488, value=10
cf1:name timestamp=1592882972801, value=zs
hbase(main):001:0> get 'user','1001','cf1:name'
COLUMN CELL
cf1:name timestamp=1592882972801, value=zs
1 row(s)
Took 0.4030 seconds
删除
delete
deleteall
hbase(main):005:0> delete 'user','1000','cf1:name'
Took 0.0431 seconds
hbase(main):006:0> scan 'user'
ROW COLUMN+CELL
1001 column=cf1:age, timestamp=1592883069488, value=10
1001 column=cf1:name, timestamp=1592882972801, value=zs
1002 column=cf1:name, timestamp=1592883223340, value=lisi
1002 column=cf2:sex, timestamp=1592883280626, value=male
2 row(s)
hbase(main):001:0> deleteall 'user','1001'
Took 0.3408 seconds
清空表
truncate 没法挽救的
hbase(main):002:0> truncate 'user'
Truncating 'user' table (it may take a while):
Disabling table...
Truncating table...
Took 2.1492 seconds
hbase(main):003:0> scan 'user'
ROW COLUMN+CELL
0 row(s)
Took 0.5192 seconds
命名空间操作
hbase(main):003:0> create_namespace 'test'
Took 0.3113 seconds
hbase(main):004:0> create 'test:user','info'
Created table test:user
Took 0.7611 seconds
=> Hbase::Table - test:user
Took 0.1234 seconds
hbase(main):010:0> list
TABLE
test:user
user
2 row(s)
Took 0.0123 seconds
=> ["test:user", "user"]
hbase(main):012:0> disable 'test:user'
Took 0.4602 seconds
hbase(main):013:0> drop 'test:user'
Took 0.2643 seconds
hbase(main):014:0> drop_namespace 'test'
Took 0.2292 seconds
hbase(main):016:0> list_namespace
NAMESPACE
default
hbase
2 row(s)
Took 0.0187 seconds
查看底层数据
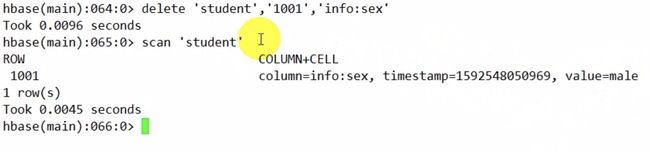
查看删除的版本信息
create 'user1',{NAME=> 'f1',VERSIONS => 2}
scan 'user1',{RAW =>TRUE,VERSIONS=>10}

删除最新的版本 话返回老版本
删除策略(3种)
hbase(main):001:0> help 'delete'
Put a delete cell value at specified table/row/column and optionally
timestamp coordinates. Deletes must match the deleted cell's
coordinates exactly. When scanning, a delete cell suppresses older
versions. To delete a cell from 't1' at row 'r1' under column 'c1'
marked with the time 'ts1', do:
hbase> delete 'ns1:t1', 'r1', 'c1', ts1
hbase> delete 't1', 'r1', 'c1', ts1
hbase> delete 't1', 'r1', 'c1', ts1, {VISIBILITY=>'PRIVATE|SECRET'}
The same command can also be run on a table reference. Suppose you had a reference
t to table 't1', the corresponding command would be:
hbase> t.delete 'r1', 'c1', ts1
hbase> t.delete 'r1', 'c1', ts1, {VISIBILITY=>'PRIVATE|SECRET'}
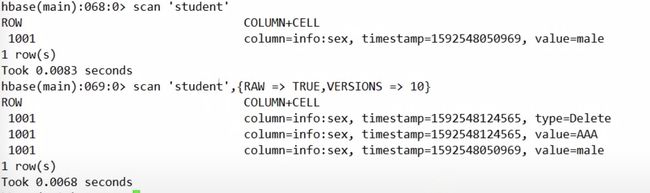
**删除最新版本:**delete
标记为:delete
**删除列的所有版本:**deleteall
标记type 变为deleteColumn
deleteall 'student','1001','info:sex'
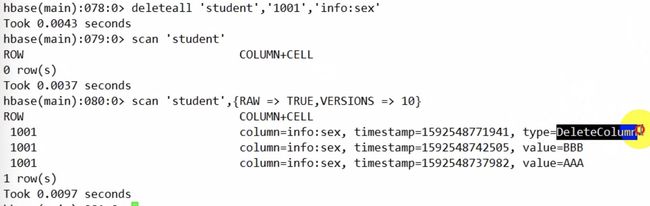
删除整个列族的所有版本:deleteall
未标明列族
type变为DeleteFamily
deleteall 'student','1001'
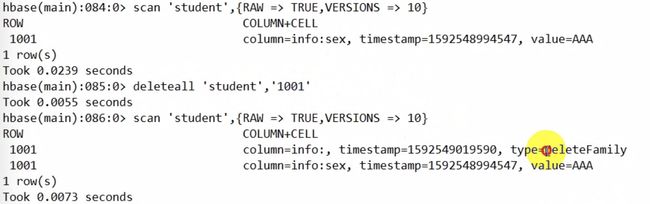
查看hbase:meta
可以看到原数据信息
hbase(main):021:0> create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
Created table staff1
Took 1.3110 seconds
=> Hbase::Table - staff1
hbase(main):022:0> scan 'hbase:meta'
ROW COLUMN+CELL
hbase:namespace column=table:state, timestamp=1592879043543, value=\x08\x00
hbase:namespace,,1592879042424.8 column=info:regioninfo, timestamp=1592882943466, value={ENCODED => 8cf40d6315c5a0717e8dd66d08916f
cf40d6315c5a0717e8dd66d08916f51. 51, NAME => 'hbase:namespace,,1592879042424.8cf40d6315c5a0717e8dd66d08916f51.', STARTKEY => '', E
NDKEY => ''}
hbase:namespace,,1592879042424.8 column=info:seqnumDuringOpen, timestamp=1592882943466, value=\x00\x00\x00\x00\x00\x00\x00\x0A
cf40d6315c5a0717e8dd66d08916f51.
hbase:namespace,,1592879042424.8 column=info:server, timestamp=1592882943466, value=hadoop133:16020
cf40d6315c5a0717e8dd66d08916f51.
hbase:namespace,,1592879042424.8 column=info:serverstartcode, timestamp=1592882943466, value=1592879017171
cf40d6315c5a0717e8dd66d08916f51.
hbase:namespace,,1592879042424.8 column=info:sn, timestamp=1592882942925, value=hadoop133,16020,1592879017171
cf40d6315c5a0717e8dd66d08916f51.
hbase:namespace,,1592879042424.8 column=info:state, timestamp=1592882943466, value=OPEN
cf40d6315c5a0717e8dd66d08916f51.
staff1 column=table:state, timestamp=1592897196760, value=\x08\x00
staff1,,1592897195898.820d19df08 column=info:regioninfo, timestamp=1592897196684, value={ENCODED => 820d19df08d143327dd824397590fa
d143327dd824397590fa57. 57, NAME => 'staff1,,1592897195898.820d19df08d143327dd824397590fa57.', STARTKEY => '', ENDKEY =>
'1000'}
staff1,,1592897195898.820d19df08 column=info:seqnumDuringOpen, timestamp=1592897196684, value=\x00\x00\x00\x00\x00\x00\x00\x02
d143327dd824397590fa57.
staff1,,1592897195898.820d19df08 column=info:server, timestamp=1592897196684, value=hadoop133:16020
d143327dd824397590fa57.
staff1,,1592897195898.820d19df08 column=info:serverstartcode, timestamp=1592897196684, value=1592879017171
d143327dd824397590fa57.
staff1,,1592897195898.820d19df08 column=info:sn, timestamp=1592897196403, value=hadoop133,16020,1592879017171
d143327dd824397590fa57.
staff1,,1592897195898.820d19df08 column=info:state, timestamp=1592897196684, value=OPEN
d143327dd824397590fa57.
staff1,1000,1592897195898.fa98b7 column=info:regioninfo, timestamp=1592897196735, value={ENCODED => fa98b703cadb3c14560d016d6c05ea
03cadb3c14560d016d6c05eafa. fa, NAME => 'staff1,1000,1592897195898.fa98b703cadb3c14560d016d6c05eafa.', STARTKEY => '1000', EN
DKEY => '2000'}
staff1,1000,1592897195898.fa98b7 column=info:seqnumDuringOpen, timestamp=1592897196735, value=\x00\x00\x00\x00\x00\x00\x00\x02
03cadb3c14560d016d6c05eafa.
staff1,1000,1592897195898.fa98b7 column=info:server, timestamp=1592897196735, value=hadoop134:16020
03cadb3c14560d016d6c05eafa.
staff1,1000,1592897195898.fa98b7 column=info:serverstartcode, timestamp=1592897196735, value=1592879017250
03cadb3c14560d016d6c05eafa.
staff1,1000,1592897195898.fa98b7 column=info:sn, timestamp=1592897196403, value=hadoop134,16020,1592879017250
03cadb3c14560d016d6c05eafa.
staff1,1000,1592897195898.fa98b7 column=info:state, timestamp=1592897196735, value=OPEN
03cadb3c14560d016d6c05eafa.
staff1,2000,1592897195898.7073fc column=info:regioninfo, timestamp=1592897196677, value={ENCODED => 7073fcf3b2d6c16a92ae70aff275c3
f3b2d6c16a92ae70aff275c329. 29, NAME => 'staff1,2000,1592897195898.7073fcf3b2d6c16a92ae70aff275c329.', STARTKEY => '2000', EN
DKEY => '3000'}
staff1,2000,1592897195898.7073fc column=info:seqnumDuringOpen, timestamp=1592897196677, value=\x00\x00\x00\x00\x00\x00\x00\x02
f3b2d6c16a92ae70aff275c329.
staff1,2000,1592897195898.7073fc column=info:server, timestamp=1592897196677, value=hadoop130:16020
f3b2d6c16a92ae70aff275c329.
staff1,2000,1592897195898.7073fc column=info:serverstartcode, timestamp=1592897196677, value=1592879017365
f3b2d6c16a92ae70aff275c329.
staff1,2000,1592897195898.7073fc column=info:sn, timestamp=1592897196404, value=hadoop130,16020,1592879017365
f3b2d6c16a92ae70aff275c329.
staff1,2000,1592897195898.7073fc column=info:state, timestamp=1592897196677, value=OPEN
f3b2d6c16a92ae70aff275c329.
staff1,3000,1592897195898.e8249c column=info:regioninfo, timestamp=1592897196734, value={ENCODED => e8249c723dc95217610046edf5184d
723dc95217610046edf5184dd6. d6, NAME => 'staff1,3000,1592897195898.e8249c723dc95217610046edf5184dd6.', STARTKEY => '3000', EN
DKEY => '4000'}
staff1,3000,1592897195898.e8249c column=info:seqnumDuringOpen, timestamp=1592897196734, value=\x00\x00\x00\x00\x00\x00\x00\x02
723dc95217610046edf5184dd6.
staff1,3000,1592897195898.e8249c column=info:server, timestamp=1592897196734, value=hadoop134:16020
723dc95217610046edf5184dd6.
staff1,3000,1592897195898.e8249c column=info:serverstartcode, timestamp=1592897196734, value=1592879017250
723dc95217610046edf5184dd6.
staff1,3000,1592897195898.e8249c column=info:sn, timestamp=1592897196403, value=hadoop134,16020,1592879017250
723dc95217610046edf5184dd6.
staff1,3000,1592897195898.e8249c column=info:state, timestamp=1592897196734, value=OPEN
723dc95217610046edf5184dd6.
staff1,4000,1592897195898.439111 column=info:regioninfo, timestamp=1592897196678, value={ENCODED => 439111241cca898505c24f241c6d93
241cca898505c24f241c6d93e7. e7, NAME => 'staff1,4000,1592897195898.439111241cca898505c24f241c6d93e7.', STARTKEY => '4000', EN
DKEY => ''}
staff1,4000,1592897195898.439111 column=info:seqnumDuringOpen, timestamp=1592897196678, value=\x00\x00\x00\x00\x00\x00\x00\x02
241cca898505c24f241c6d93e7.
staff1,4000,1592897195898.439111 column=info:server, timestamp=1592897196678, value=hadoop130:16020
241cca898505c24f241c6d93e7.
staff1,4000,1592897195898.439111 column=info:serverstartcode, timestamp=1592897196678, value=1592879017365
241cca898505c24f241c6d93e7.
staff1,4000,1592897195898.439111 column=info:sn, timestamp=1592897196404, value=hadoop130,16020,1592879017365
241cca898505c24f241c6d93e7.
staff1,4000,1592897195898.439111 column=info:state, timestamp=1592897196678, value=OPEN
241cca898505c24f241c6d93e7.
8 row(s)
RegionServer架构
Memstore 写缓存
操作记录写到WAL中,追加写 (wal一般在hdfs上)
然后再往memstore写 当memestore到达一定时机 再刷写到hdfs
每次刷写会生成新的StoreFile
block Cache 读缓存
LRU(Least Resent use)策略会把最早的访问最少的清除掉

写流程

MemStore Flush

以Region为单位刷写
尽可能减少列族 ,最好不要超过3个,不然小文件过多
刷写时机
1.当某个memstroe的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。
当memstore的大小达到了
hbase.hregion.memstore.flush.size(默认值128M)* hbase.hregion.memstore.block.multiplier(默认值4)时,会阻止继续往该memstore写数据。
2.当region server中memstore的总大小达到
java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)
*hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),
region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。
当region server中memstore的总大小达到
java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)
时,会阻止继续往所有的memstore写数据。
3. 到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时)。
4.当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。
wal工作的文件就一个 当memstore flush到storeFile中 wal 才会删除预写日志
手动flush
第5种
flush 可以以region、表为单位
读流程
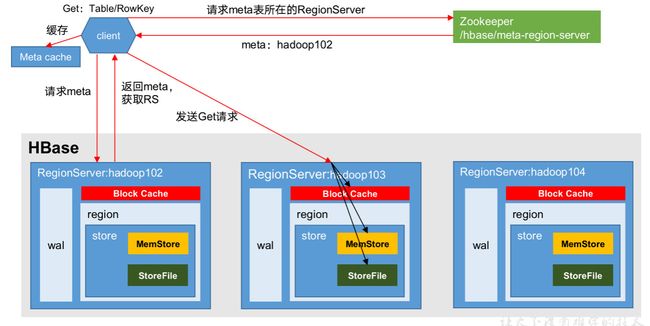
细节
过滤的作用:减少一部分HFile,扫描的范围变小
Block Cache作用:加快读的流程
每一个HFile都有索引,在flush时生成的索引,位于HFile中
每个HFile都有 自己的 布隆过滤器
第一次读HFile加载到block cache后也会存HFile的索引和布隆过滤器
第二次读从block cache 读索引 根据索引定位block,Block cache有直接读取,没有再去读HFile
布隆过滤器:
存在每个HFile中,刷写的过程中索引和布隆过滤器同时生成,也换缓存在BlockCache中
数据结构 数组 存放0/1 rowkey根据不同的hash判断放入数组中
布隆过滤器可以100%否定 这个文件没有rowkey的 ,不能100%肯定某个文件有rowkey
有无一定误差 数组越长误差越小
布隆过滤器数组长度可以设定
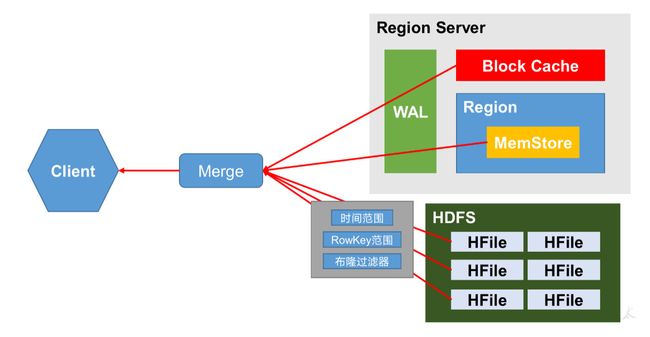
StoreFile Compaction
1.归并排序
2.删除过期数据
Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。

Minor Compaction (自动执行)
归并排序,部分物理删除,删除标记不能删
Major Compaction (周期进行,7天一次大合并)
可以把该删的都删了
合并是比较耗费性能,通常自动大合并需要关闭,手动进行
Region Split
细节:
region对应一个hdfs一个路径
分裂过程中会产生新路径,引用文件 引用老文件中的rowkey范围,写的时候会写在新路径下
当新region进行Major Compaction 时会把老region的文件拿过来合并在一起,排序清理过期数据
当2个新region都进行完Major Compaction 后,老region才会删除掉
Region Split时机
分裂策略

1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize (默认10G),该Region就会进行拆分(0.94版本之前)。
2.当1个region中的某个Store下所有StoreFile的总大小超过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该Region就会进行拆分。其中initialSize的默认值为2*hbase.hregion.memstore.flush.size,R为当前Region Server中属于该Table的Region个数(0.94版本之后)。
具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了。
3.Hbase 2.0引入了新的split策略:如果当前RegionServer上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size分裂,否则按照hbase.hregion.max.filesize分裂。

在建表的时候指明分裂策略hbase.regionserver.region.split.policy