要在前端实现语音合成,即将文字讲述出来,一开始考虑用百度tts语音合成的方法,后来发现html5 本身就支持语音合成。就直接用html5的咯,百度的那个还有调用次数限制,配置还麻烦
一、关于HTML5语音Web Speech API
HTML5中和Web Speech相关的API实际上有两类,一类是“语音识别(Speech Recognition)”,另外一个就是“语音合成(Speech Synthesis)”,这两个名词听上去很高大上,实际上指的分别是“语音转文字”,和“文字变语音”。
而本文要介绍的就是这里的“语音合成-文字变语音”。为什么称为“合成”呢?比方说你Siri发音“你好,世界!” 实际上是把“你”、“好”、“世”、“界”这4个字的读音给合并在一起,因此,称为“语音合成”。
“语音识别”和“语音合成”看上去像是正反两方面,应该带有镜面气质,实际上,至少从兼容性来看,两者并无法直接对等。
“语音识别(Speech Recognition)”目前的就Chrome浏览器和死忠小弟Opera浏览器默认支持,并且需要webkit私有前缀:
但是,“语音合成(Speech Synthesis)”的兼容性要好上太多了,如下图: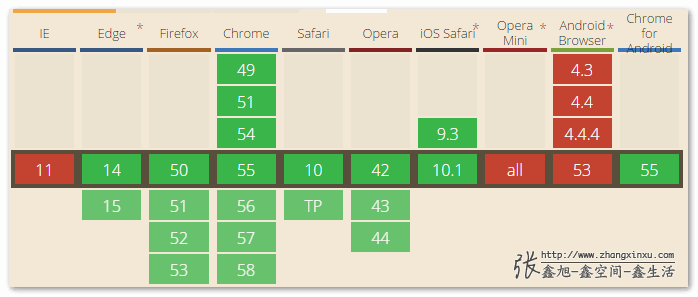
所以,本文主要介绍下理论上更为适用的HTML5 Speech Synthesis API。不过在此之前,Speech Recognition API还是简单提一下。
Speech Recognition API也就是语音识别功能,需要麦克风等音频输入设备的支持,在Chrome浏览器下,实际上可以添加简单的属性就可以让部分控件有语音识别功能,一行JS都不需要写,这个我之前有专门写文章介绍过:“渐进使用HTML5语言识别, so easy!”
就是在输入框上加一个x-webkit-speech属性即可,例如:
然而,我刚刚打开demo页面一测试,发现原来有的麦克风(下图为以前截图)居然不见了。。。。看来已经被chrome无情抛弃了!

好吧,就当我上面的内容,什么都没说过。不过有一点是可以肯定的,就是原来输入框上的那个语音识别底层就是使用的Speech Recognition API,因此存在一定的共性,比方说文字内容识别需要google服务器返回,因此功能就与网络环境有很大关系,比方说google被墙了,或者网速很慢了,都有可能导致识别出现异常。
使用的基本套路如下:
- 创建SpeechRecognition的新实例。由于到目前为止,浏览器还没有广泛支持,所以需要
webKit的前缀:var newRecognition = webkitSpeechRecognition();
- 设置是持续听还是听到声音之后就关闭接收。通过设置
continuous属性值实现。一般聊天沟通使用false属性值,如果是写文章写公众号之类的则可以设置为true,如下示意:newRecognition.continuous = true;
- 控制语音识别的开启和停止,可以使用start()和stop()方法:
// 开启 newRecognition.start(); // 停止 newRecognition.stop();
- 对识别到的结果进行处理,可以使用一些事件方法,比方说
onresult:newRecognition.onresult = function(event) { console.log(event); }event是个对象,我家里电脑不知道什么原因,无法成功返回识别内容,显示网络错误,可能因为墙的缘故: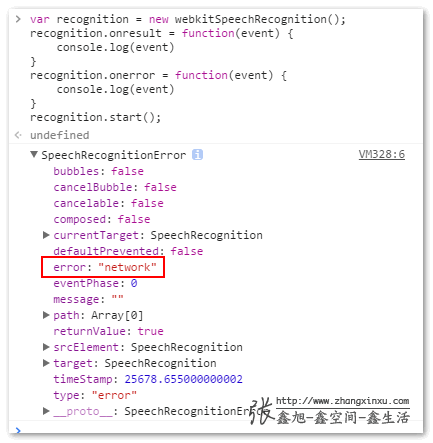
所以,我从网上找了下大致数据结构:
{ .. results: { 0: { 0: { confidence: 0.695017397403717, transcript: "你好,世界" }, isFinal:true, length:1 }, length:1 }, .. }
除了result事件外,还有其他一些事件,例如,soundstart、speechstart、error等。
二、关于语音合成Speech Synthesis API
先从最简单的例子说起,如果想让浏览器读出“你好,世界!”的声音,可以下面的JS代码:
var utterThis = new window.SpeechSynthesisUtterance('你好,世界!');
window.speechSynthesis.speak(utterThis);
没错,只需要这么一点代码就足够了,大家可以在自己浏览器的控制台里面运行上面两行代码,看看有没有读出声音。
上面代码出现了两个长长的对象,SpeechSynthesisUtterance和speechSynthesis,就是语音合成Speech Synthesis API的核心。
首先是SpeechSynthesisUtterance对象,主要用来构建语音合成实例,例如上面代码中的实例对象utterThis。我们可以直接在构建的时候就把要读的文字内容写进去:
var utterThis = new window.SpeechSynthesisUtterance('你好,世界!');
又或者是使用实例对象的一些属性,包括:
text– 要合成的文字内容,字符串。lang– 使用的语言,字符串, 例如:"zh-cn"voiceURI– 指定希望使用的声音和服务,字符串。volume– 声音的音量,区间范围是0到1,默认是1。rate– 语速,数值,默认值是1,范围是0.1到10,表示语速的倍数,例如2表示正常语速的两倍。pitch– 表示说话的音高,数值,范围从0(最小)到2(最大)。默认值为1。
因此上面的代码也可以写作:
var utterThis = new window.SpeechSynthesisUtterance(); utterThis.text = '你好,世界!';
不仅如此,该实例对象还暴露了一些方法:
onstart– 语音合成开始时候的回调。onpause– 语音合成暂停时候的回调。onresume– 语音合成重新开始时候的回调。onend– 语音合成结束时候的回调。
接下来是speechSynthesis对象,主要作用是触发行为,例如读,停,还原等:
speak()– 只能接收SpeechSynthesisUtterance作为唯一的参数,作用是读合成的话语。stop()– 立即终止合成过程。pause()– 暂停合成过程。resume()– 重新开始合成过程。getVoices– 此方法不接受任何参数,用来返回浏览器支持的语音包列表,是个数组,例如,在我的电脑下,Firefox浏览器返回的语言包是两个:

而在chrome浏览器下,数量就很惊人了:

虽然数量很多,是有种给人中看不中用的感觉,为什么这么说呢!在我的chrome浏览器下,不知道为什么,不会读任何声音,但是同样的demo见面,公司的电脑就可以,我后来仔细查了一下,有可能(20%可能性)是我家里的电脑win7版本是阉割版,没有安装或配置TTS引擎。
手机Safari浏览器也不会读。
其中,17是普通话大陆:

另外,
getVoices的获取是个异步的过程,因此,你可以直接在控制台输入,speechSynthesis.getVoices()返回的是一个空数组,没关系,多试几次,或者搞个定时器之类的。
三、语音合成Speech Synthesis API有什么用
对于盲人或弱视用户,往往会借助一些辅助设备或者软件访问我们的网页,其原理是通过触摸或定位某些元素发出声音,来让用户感知内容。
有了语音合成Speech Synthesis API,对于这类用户,以及开发人员自己,都会带来一定的便利性。首先对于视觉有障碍的用户,他们就不需要再安装其他软件或购买其他设备,就可以无障碍地访问我们的产品。对于开发人员自己,我们的无障碍建设可以变得更加灵活,不一定要百分百契合ARIA无障碍规范(可参见我之前文章“WAI-ARIA无障碍网页应用属性完全展示”),因为我们可以直接让浏览器合成我想要的语音内容,例如,VoiceOver在对一些标签读取的时候,总会附带一句“标志性内容”,就算对于我这样专业从业者,这个词也是有点生涩难懂的,我们其实可以把这个语音合成交给自己,使用更通俗易懂的词反馈给用户,我想体验上应该是更好的。
至少我会在17年,尝试在一些产品上推动这方面工作的建设。
另外一个就是二维码识别,有时候肉眼看得眼睛疼,加个按钮让用户听。
等等~