【Java】Dom解析XML(读取,增删改查,保存),Dom树转Map集合,Map集合结构化层次输出——三个示例的整合
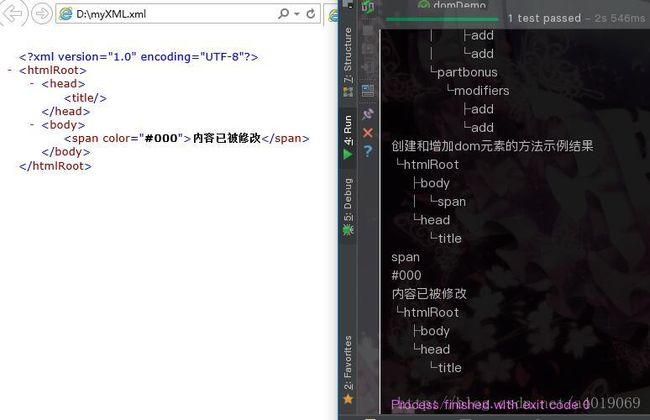
效果图
XML文件片段
(永恒之塔服务端:\gameserver\data\static_data\item_sets\item_sets.xml)589KB
……
主方法源码
@Test
public void domDemo() {
try {
//构造输出方法的lambda表达式,传入根节点
Consumer printDomTree = root -> {
HashMap map = new HashMap<>();
getNodeMap(root, map);//Dom树转Map集合
printMap(map, "", true);//输出Map集合结构
};
//构造保存方法的lambda表达式,传入根节点、路径文件
BiConsumer saveDomTree = (root, strPath) -> {
try {
//【保存】1、创建转换工厂
TransformerFactory tff = TransformerFactory.newInstance();
//【保存】2、创建转换器
Transformer tf = tff.newTransformer();
//【保存】3、设置转换器,会根据标签自动添加不同的声明,XML,HTML
tf.setOutputProperty(OutputKeys.VERSION, "1.0");
tf.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//【保存】4、获取数据源
DOMSource doms = new DOMSource(root);
//【保存】5、设置保存位置,已经存在的文件被覆盖,不存在自动创建
StreamResult sr = new StreamResult(strPath);
//【保存】6、执行
tf.transform(doms, sr);
} catch (TransformerException e) {
e.printStackTrace();
}
};
//=========================================================
//【加载】1、创建解析器工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//【加载】2、创建解析器
DocumentBuilder builder = factory.newDocumentBuilder();
//【加载】3、读取xml,生成dom树
File file = new File("D:\\item_sets.xml");
System.out.println(file.getName());
Document doc = builder.parse(file);
//=========================================================
//【读取】1、获取根节点
NodeList rootList = doc.getChildNodes();//获取所有最外层标签
Node root = null;
for (int n = 0; n < rootList.getLength(); n++) {
root = rootList.item(n);
if (root.getNodeType() == Node.ELEMENT_NODE) {
break;//找到根节点(唯一)
}
}
if (root == null) {
return;//没有找到dom可用的节点
}
//【读取】2、遍历子节点到map集合并输出
printDomTree.accept(root);
//=========================================================
//【加载】1、创建解析器工厂
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//【操作】2、创建解析器
DocumentBuilder db = dbf.newDocumentBuilder();
//【操作】3、创建新的dom树
Document docNew = db.newDocument();
//增加,以html网页的基本骨架为例
System.out.println("创建和增加dom元素的方法示例结果");
Element eRoot = docNew.createElement("htmlRoot");//创建根节点
Element eFather1 = docNew.createElement("head");//创建父节点
Element eFather2 = docNew.createElement("body");//创建父节点
Element eChild1 = docNew.createElement("title");//创建子节点
Element eChild2 = docNew.createElement("span");//创建子节点
eChild2.setAttribute("color", "#f00");//添加属性(不从在会创建)
eChild2.setTextContent("span标签");//添加内容(不推荐)如果有子节点会被覆盖
eFather1.appendChild(eChild1);//title标签属于head的子标签
eFather2.appendChild(eChild2);//span标签属于body的子标签
eRoot.appendChild(eFather1);//head标签属于body的子标签
eRoot.appendChild(eFather2);//body标签属于html的子标签
printDomTree.accept(eRoot);//输出
saveDomTree.accept(eRoot, "D:\\myXML.xml");//保存
//=========================================================
//修改,在增加的基础上进行修改
//修改span标签的内容,需要遍历子节点,找到目标节点
Node bNode = null;
NodeList nl = eRoot.getElementsByTagName("body");
Node node = nl.item(0);
Element ef = (Element) node;
NodeList es = ef.getElementsByTagName("span");
Node ns = es.item(0);
Element e = (Element) ns;
e.setAttribute("color", "#000");//修改为黑色,属性名已存在会覆盖原属性值
e.setTextContent("内容已被修改");//修改内容
saveDomTree.accept(eRoot, "D:\\myXML.xml");//保存
//=========================================================
//查询
System.out.println(e.getTagName());//标签名
System.out.println(e.getAttribute("color"));//属性
System.out.println(e.getTextContent());//标签中间包含的内容
//=========================================================
//删除,删除span标签
Node f = e.getParentNode();//节点无法自杀,获取父节点
f.removeChild(e);//删除操作必须在父节点中执行
printDomTree.accept(eRoot);//输出
saveDomTree.accept(eRoot, "D:\\myXML.xml");//保存
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
} Dom树转Map集合源码
/**
* 迭代遍历所有节点
*
* @param node 父节点
* @param map 父节点--键,子节点集合--值,没有子节点值为null
*/
public void getNodeMap(Node node, HashMap map) {
//1、获取子节点
NodeList childL = node.getChildNodes();
int childLen = childL.getLength();
if (childLen == 0) {
//没有子节点,结束遍历
map.put(node, null);
} else {
Node childN;
boolean flag = false;
HashMap childM = new HashMap<>();
//2、遍历子节点
for (int n = 0; n < childLen; n++) {
childN = childL.item(n);
if (childN.getNodeType() == Node.ELEMENT_NODE) {
flag = true;//标记是否已经遍历到指定类型的节点
getNodeMap(childN, childM);//迭代
map.put(node, childM);//迭代到的子节点添加到集合中
}
}
//3、没有指定类型的节点
if (!flag) {
map.put(node, null);
}
}
} 结构层次化输出map集合源码
/**
* 按照层次结构,输出map集合
*
* @param map 待输出集合
* @param leftStr 层次
* @param isLast 元素遍历到当前层次的最后一个判断
*/
public void printMap(HashMap map, String leftStr, boolean isLast) {
Set key = map.keySet();//输出时会无序,xml无影响,键值关系(父子节点关系)正确即可
List list = new ArrayList<>(key);
int len = list.size();
while (len-- > 0) {
//输出层次
System.out.print(leftStr);
//1、输出元素
Node node = list.get(len);
Element child = (Element) node;
if (len == 0) {
System.out.print("└");
} else {
System.out.print("├");
}
System.out.println(child.getNodeName());
//2、迭代遍历
HashMap childM = map.get(node);
if (childM != null) {
String nextLeftStr = leftStr;//创建新的字符串
if (len == 0) {
nextLeftStr += "\t";//当前层次最后一个节点,闭合
printMap(childM, nextLeftStr, true);
} else {
nextLeftStr += "│\t";//当前层次没有遍历完成,不闭合
printMap(childM, nextLeftStr, false);
}
}
}
}