词向量: https://blog.csdn.net/class_brick/article/details/78908984
word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。

比如上面的这个例子,在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。但是使用One-Hot Encoder有以下问题。一方面,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难。
使用Vector Representations可以有效解决这个问题。Word2Vec可以将One-Hot Encoder转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词将被映射到向量空间中相近的位置。
如果将embed后的城市向量通过PCA降维后可视化展示出来,那就是这个样子。
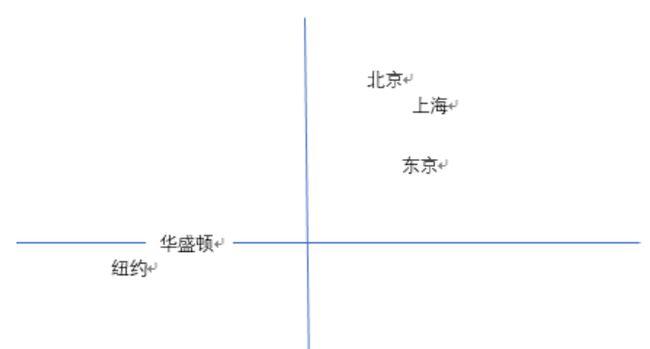
我们可以发现,华盛顿和纽约聚集在一起,北京上海聚集在一起,且北京到上海的距离与华盛顿到纽约的距离相近。也就是说模型学习到了城市的地理位置,也学习到了城市地位的关系。
模型拆解
word2vec模型其实就是简单化的神经网络。

输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。我们要获取的dense vector其实就是Hidden Layer的输出单元。有的地方定为Input Layer和Hidden Layer之间的权重,其实说的是一回事。

Word2Vec
问题设定
对于One-hot的词向量:
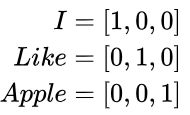
无法通过两向量夹角余弦值计算其相似度,word2vec提供了Skip-Gram(跳字模型)与CBOW(连续词袋模型)两个词嵌入模型,通过这种模型训练出的词向量可以较好的表示出词之间的相似度。
Skip-Gram
即跳字模型,其核心思想是对于一个上下文,设定一个大小为m的滑窗,在滑窗内选择1个中心词,预测滑窗内m-1个背景词。即如果上下文是:
对每一个词进行One-hot编码:
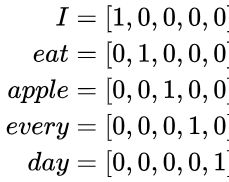
设定滑窗大小为2,如果选择中心词apple,那么将会有以下训练数据:

设计一个只有1个输入层、1个隐藏层、1个输出层的神经网络,其中输出层的神经元个数等于输入层即等于One-hot编码的维度,而隐含层的神经元个数通常远小于输出层,比如One-hot维度如果是10000,隐含层可以只有300个神经元
CBOW
即Continuous Bag of Words,连续词袋模型,其核心思想是对于一个上下文,设定一个大小为m的滑窗,在滑窗内选择1个背景词,m - 1个中心词,与Skip-Gram相反,设定滑窗大小为2,如果选择中心词 I, eat, every, day ,那么将会有以下训练数据:
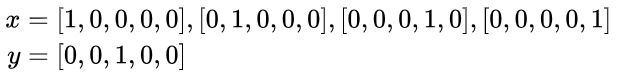
--------------------------------------------------------------------------------------------------------------------
【其他】
『TensorFlow』读书笔记_Word2Vec:https://www.cnblogs.com/hellcat/p/8068198.html
Word2Vec又称Word Embeddings,中文称为"词向量"、"词嵌入"等。
One_Hot_Encoder
图像和语音天然可以表示为稠密向量,自然语言处理领域在Word2Vec之前都是使用离散符号,如"中国"表示为5178,"北京"表示为3987这样,即One_Hot_Encoder,一个词对应一个向量(向量中一个值为1其余值为0),这使得整篇文章变为一个稀疏矩阵。而在文本分类领域,常使用Bag of Words模型,将文章对应的稀疏矩阵进行合并,比如"中国"出现23次,则5178位置特征值为23这样。
由于One_Hot_Encoder的特征编码是随机的,完全忽视了字词之间可能的关联。而且稀疏向量作为存储格式时,其效率比较低,即我们需要更多的训练数据,另外,稀疏矩阵计算也非常麻烦。
向量空间模型
向量表达可以有效的解决这些问题,向量空间模型会将意思相近的词映射到邻近的位置。向量空间模型在NLP中依赖的假设是Distributional Hypothesis,即相同语境中出现的词其意义也相近。
向量空间模型有两个子类,
其一是计数模型,计数模型会统计相邻词出现的频率,然后将之处理为小而稠密的矩阵
其二是预测模型,预测模型则是根据一个词相邻的词去推测出这个词,以及其空间向量
Word2Vec就属于一种预测模型,其分为两个模式,
CBOW模式从缺词的原始语句推测目标词,适用于小型数据
Skip-Gram利用目标词逆推原始语句,对大型语料库效果很好
预测模型一般是给定前h个词的情况下去最大化目标词的概率,CBOW模型并不需要计算全部词汇表中的可能性,随机选择k个词汇和目标词汇进行计算loss,这个方法由tf.nn.nce_loss()已经实现了。
以一句话为例;“the quick brown fox jumped over the lazy dog”为例,滑窗尺寸为一时映射关系有:CBOW中,【the、brown】->【quick】这样的,而Skip-Gram中相反,我们希望得到的是(quick,the)、(quick,brown)这样的关系。面对随机生成的负样本时,我们希望概率分布在the的位置尽可能的大。
再举个例子:对同样一个句子:Hangzhou is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。
这里假设滑窗尺寸为1(滑窗尺寸……这个……不懂自己google吧-_-|||)
CBOW可以制造的映射关系为:[Hangzhou,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram可以制造的映射关系为(is,Hangzhou),(is,a),(a,is), (a,nice),(nice,a),(nice,city)