Oracle数据库结构
数据库结构

文章目录
- 数据库结构
- 物理结构
- 数据库物理文件
- 控制文件(controlFile)
- 数据文件(dataFile)
- 重做/恢复日志文件(logFile)
- 参数文件(InitSID.ora)
- SCN号
- 系统检查点SCN
- 数据文件SCN
- 数据文件尾SCN(结束SCN)
- 数据文件头SCN
- Redo log中的high scn和low scn
- 逻辑结构
- 表空间
- 表空间类型
- 创建表空间
- 变动表空间大小
- 查看表空间的大小
- 删除表空间
- 创建回滚段(undo表空间)
- 模式和模式对象
- 表空间与模式对象的关系
- 数据块-数据区段-段
- 段类型
- 控制区的大小
- 内存结构
- 内存结构示意图
- 系统全局区SGA
- 影响SGA的参数
- 程序全局区PGA
- 进程结构
- SGA和oracle进程间的关系
- oracle系统进程
- oracle后台进程
- 数据库写入进程 DBWR
- 日志写入进程 LGWR
- 系统监控进程 SMON
- 程序监控进程 PMON
- 检查点进程 CKPT
- 归档日志进程 ARCH
- 服务进程Server Process
- 专用服务器架构
- 多线程服务器架构
- 并行服务器架构
- 分布式服务器架构
物理结构
数据库物理文件
数据库物理结构主要由控制文件,数据文件,日志文件和参数文件构成。
控制文件(controlFile)
控制文件是用来保存数据库的物理结构—数据文件和重作日志文件,保存数据库的名称、数据文件和恢复日志文件的名称及位置、时间戳等与数据库相关的所有文件信息 。
- 控制文件所属的数据库名,一个控制文件只能属于一个数据库
- 数据库生成的时间
- 数据文件的名称、位置、在线/离线状态
- 重做日志文件的名称和位置
- 表空间的名称
- 当前日志文件的序列号
- 最近检查点信息
- 一般都镜像控制文件
- 与控制文件相关的表和视图:v$controlFile、v$controlFile_record_section
数据文件(dataFile)
是操作系统文件,包括所有数据库数据,逻辑数据库结构的数据存储在这些文件中
数据文件有如下特性:
- 一个数据库由一个或多个数据文件构成
- 一个数据文件只能归属于一个数据库
- 一个表空间由一个或者多个数据文件组成
- 与数据文件相关的表和视图:v$dataFile、dba_data_files
重做/恢复日志文件(logFile)
保存每个事务处理的操作系统文件集,这些文件叫事务日志。(创建后大小一般不再变),LGWR日志写入进程周期性写入重做日志缓冲区,如有3个重做日志文件,LGWR首先写第一个,当第一个满时,开始写第二个,然后是第三个,最后返回第一个。一个数据库最少有两个重做日志文件,也被称作redoLog
- 分为两种工作模式:归档日志模式和非归档日志模式(循环方式)
- 与redoLog相关的表和视图:v$log、v$logFile、v$archived_log、v$log_history
参数文件(InitSID.ora)
是在ORACLE实例启动时候,需要读入的一个参数文件。该参数文件是一个文本文件,包含有实例配置参数。这些参数置成特殊值,用于初始ORACLE实例的许多内存和进程设置
SCN号
SCN是当Oracle数据库更新后(结构发生变化),由 DBMS自动维护去累积递增的一个数字。oracle中有四种SCN号:系统检查点SCN、数据文件SCN、结束SCN、数据文件头SCN
oracle 10g提供了两个新的函数对于scn和时间戳进行相互转换。这两个函数是scn_to_timestamp,timestamp_to_scn,这两者的相互转换,给管理者带来极大的便利。在10g之前oracle是没有办法通过函数得到时间和scn的相应关系(一般通过logmnr分析日志获得。可是这样的转换是依赖于数据库内部的数据记录。对于久远的scn不能转换。
- 获取当前SCN号
SQL> select CURRENT_SCN from v$database;
SQL> select dbms_flashback.get_system_change_number from dual; - SCN与时间的相互转化
SQL> select scn_to_timestamp( 9501954) from dual;
SQL> select timestamp_to_scn(scn_to_timestamp( 9501954)) from dual;
系统检查点SCN
系统检查点SCN位于控制文件中,当检查点进程启动时(ckpt),Oracle就把系统检查点的SCN存储到控制文件中。该SCN是全局范围的,当发生文件级别的SCN时,例如将表空间置于只读状态,则不会更新系统检查点SCN。
- 查询系统检查点SCN号命令
SQL> select checkpoint_change# from v$database;
数据文件SCN
当ckpt进程启动时,包括全局范围的(比如日志切换)以及文件级别的检查点(将表空间置为只读、begin backup或将某个数据文件设置为offline等),这时会在控制文件中记录SCN。
- 查询数据文件SCN号命令
select file#,checkpoint_change# from v$datafile;
数据文件尾SCN(结束SCN)
每个数据文件都有一个结束scn,在数据库的正常运行中,只要数据文件在线且是可读写的,结束scn为null。否则则存在具体的scn值。结束scn也记录在控制文件中
- 查询结束SCN号命令
select file#,LAST_CHANGE# from v$datafile;
数据文件头SCN
不同于上述的SCN,数据文件开始scn记录在每个数据文件中。当发生系统及文件级别的检查点后,不仅将这时的SCN号记录在控制文件中,同样也记录在数据文件中
- 查询数据文件头SCN号命令
select file#,CHECKPOINT_CHANGE# from v$datafile_header;
在安全关闭数据库的过程中,系统会执行一个检查点动作,这时所有数据文件的终止scn都会设置成数据文件头中的那个启动scn的值。在数据库重新启动的时候,Oracle将文件头中的那个启动scn与数据库文件检查点scn进行比较,假如这两个值相互匹配,oracle接下来还要比较数据文件头中的启动 scn和控制文件中数据文件的终止scn。假如这两个值也一致,就意味着所有数据块多已经提交,所有对数据库的修改都没有在关闭数据库的过程中丢失,因此这次启动数据库的过程也不需要任何恢复操作,此时数据库就可以打开了。当所有的数据库都打开之后,存储在控制文件中的数据文件终止scn的值再次被更改为 null,这表示数据文件已经打开并能够正常使用了。
Redo log中的high scn和low scn
Oracle的Redo log会顺序纪录数据库的各个变化。一组redo log文件写满后,会自动切换到下一组redo log文件。则上一组redo log的high scn就是下一组redo log的low scn。在current log中high scn为无穷大。
可通过查询v$log_history查看 low scn和 high scn。
SQL> select recid,sequence#,first_change#,next_change# from v$log_history ;
RECID SEQUENCE# FIRST_CHANGE# NEXT_CHANGE#
---------- ---------- ------------- ------------
1 1 446075 474154
2 2 474154 497385
3 3 497385 516087
4 4 516087 540659
5 5 540659 564897
6 6 564897 564903
7 7 564903 565320
8 8 565320 565704
9 9 565704 565715
10 10 565715 567343
11 11 567343 587705
查看currnet redolog中的high scn
SQL>select vf.member,v.status,v.first_change# from v$logfile vf,v$log v
where vf.group#=v.group#
and v.status='CURRENT'
MEMBER STATUS FIRST_CHANGE#
------------------------------------------------------------ -------------- -------------
/u01/app/oradata/orcl/redo02.log CURRENT 587705
SQL>alter system dump logfile ' /u01/app/oradata/orcl/redo02.log';
SQL> show parameter user_dump
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
user_dump_dest string /home/oracle/admin/c001/udump
打开转储出来的文件,可以看到
DUMP OF REDO FROM FILE ‘/u01/app/oradata/orcl/redo02.log’
Opcodes .
RBAs: 0x000000.00000000.0000 thru 0xffffffff.ffffffff.ffff
SCNs: scn: 0x0000.00000000 thru scn: 0xffff.ffffffff
Times: creation thru eternity
FILE HEADER:
Compatibility Vsn = 169869568=0xa200100
Db ID=1269936864=0x4bb1b2e0, Db Name=‘ORCL’
Activation ID=1269912032=0x4bb151e0
Control Seq=696=0x2b8, File size=102400=0x19000
File Number=2, Blksiz=512, File Type=2 LOG
descrip:“Thread 0001, Seq# 0000000012, SCN 0x00000008f7b9-0xffffffffffff”
thread: 1 nab: 0x34f6 seq: 0x0000000c hws: 0x9 eot: 1 dis: 0
resetlogs count: 0x2c3c676f scn: 0x0000.0006ce7b (446075)
resetlogs terminal rcv count: 0x0 scn: 0x0000.00000000
prev resetlogs count: 0x2184ef74 scn: 0x0000.00000001 (1)
prev resetlogs terminal rcv count: 0x0 scn: 0x0000.00000000
Low scn: 0x0000.0008f7b9 (587705) 04/20/2011 09:35:56
Next scn: 0xffff.ffffffff 01/01/1988 00:00:00
Enabled scn: 0x0000.0006ce7b (446075) 02/03/2011 18:29:03
Thread closed scn: 0x0000.00090ae0 (592608) 04/20/2011 15:29:05
Disk cksum: 0x30ee Calc cksum: 0x30ee
Terminal recovery stop scn: 0x0000.00000000
Terminal recovery 01/01/1988 00:00:00
Most recent redo scn: 0x0000.00000000
Largest LWN: 1920 blocks
End-of-redo stream : No
Unprotected mode
Miscellaneous flags: 0x0
Thread internal enable indicator: thr: 0, seq: 0 scn: 0x0000.00000000
redo log中当前系统的SCN记录当前最新的数据库scn值可通过如下命令查看
SQL> select dbms_flashback.get_system_change_number from dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
594373
如果需要进行实例恢复,则需要恢复的记录为587705至594373中redo log中的记录。
逻辑结构
表空间
表空间tableSpace是oracle数据库内部的数据库的主要逻辑结构,是存储数据库对象的容器,它与磁盘上的一个或多个物理数据文件(dataFile)相对应,但是一个数据文件只能与一个表空间相关联,数据库的默认表空间如下
- SYSTEM
用于存储整个数据库的数据字典等 - UNDOTBS1
用来存储回滚段的内容 - SYSAUX
system表空间的辅助表空间,如OEM、streams等会默认存放在SYSAUX表空间里 - TEMP
数据库的临时表空间,用来管理数据库排序操作以及用于存储临时表、中间排序结果等的临时对象 - USERS
在创建一个用户但是没有指定此用户使用表空间时,此用户所有信息都会放入USERS表空间
表空间类型
- 联机表空间(Online TableSpace)
Oracle可以在逐个表空间的基础上控制数据库的数据可用性,当表空间保证用户可以访问数据库中的信息表空间的数据可用于应用程序和数据库,此种表空间叫联机表空间。
System表空间必须始终保持联机,因为数据字典中的信息必须在整个运行中是可用的。 - 脱机表空间(Offline TableSpace)
此种表空间中的数据不可用于数据库用户,就算该数据库是可用的也不行。管理员可能会令表空间脱机来防止对换应用程序数据的访问,这可能是因为该表空间可能碰到了问题,或是因为表空间中包含了任何人都不需要的历史数据。 - 临时表空间(Temporary TableSpace)
是一个大的临时工作空间,事务处理可用它来处理复杂的SQL 操作的地方。如:存储查询、连接查询、索引构造等。
创建表空间
- 语法格式
CREATE TABLESPACE tablespace
DATAFILE ‘filename’ [SIZE integer [K|M][REUSE]
[AUTOEXTEND OFF|ON [NEXT integer [K|M]] [MAXSIZE
{UNLIMITED|integer [K|M]}]]
[,… other datafile specifications …]
[ONLINE|OFFLINE]
[PERMANENT|TEMPORARY]
- 说明
要创建表空间必须有CREATE TABLESPCE系统权限。在创建时,可以为表
空间指定一个或多个数据文件,创建永久或临时表空间,将新的表空间
设置为联机或脱机状态。
变动表空间大小
- 增加一个或多个新的数据文件到表空间
ALTER TABLESPACE tablespace_name ADD DATAFILE filename SIZE size_of_file
- 手工重新定义表空间中的数据文件的大小
ALTER DATABASE dbname DATAFILE filename RESIZE size_of_file [AUTOEXTEND]
- 表空间的文件的重命名或者路径改动
ALTER TABLESPACE tablespace_name RENAME DATAFILE filename TO newfilename
- 在配置表空间的数据文件时,指定自动增长的方式
alter tablespace tablespace_name add datafile 'c:\oradata\userdata_002.ora' size 50m Autoextend on next 100m maxsize 1000M
查看表空间的大小
select
substr(a.TABLESPACE_NAME,1,10) TablespaceName,
sum(a.bytes/1024/1024) totle_size,
sum(nvl(b.free_space1/1024/1024,0)) free_space,
sum(a.bytes/1024/1024)-sum(nvl(b.free_space1/1024/1024,0)) used_space,round((sum(a.bytes/1024/1024)- sum(nvl(b.free_space1/1024/1024,0)))*100/sum(a.bytes/1024/1024),2) used_percent
from dba_data_files a,
(select sum(nvl(bytes,0)) free_space1,file_id
from dba_free_space
group by file_id) b
where a.file_id = b.file_id(+)
group by a.TABLESPACE_NAME
删除表空间
DROP TABLESPACE tablespace_name [INCLUDING CONTENTS [CASCADE CONSTRAINTS]]
- 说明:
including contents子句表明如果表空间上有建立了任何的数据库对象,则返回错误或异常;
cascade constraints子句表示如果表空间上的数据库对象存在与表空间外的约束,则返回错误;
创建回滚段(undo表空间)
CREATE [PUBLIC|PRIVATE] ROLLBACK SEGMENTsegmentname
TABLESPACE tablespacename
STORAGE{…
OPTIMAL integer [K|M]
}
- 回滚段联机或脱机
ALTER ROLLBACK SEGMENT segname ONLINE|OFFLINE - 收缩回滚段
ALTER ROLLBACK SEGMENT segname SHRINK - 规则
- 原则:系统回滚段应放在SYSTEM表空间中, 并且应该永远保持ONLINE状态
建议1:在单实例系统中,建议将所有回滚段设为PUBLIC
建议2:在多实例系统中(如OPS), 建议将每个实例的PRIVATE回滚段放置到访问比较快的本地设备上 - 原则:OLTP系统应使用小但较多的回滚段, OLAP系统/批处理系统应使用少量的大回滚段
建议3:OLTP/OLAP混合型系统中, 应专门设置一个或几个大的回滚段, 平时设置为OFFLINE, 使用时通过使用SET TRANSACTION USE ROLLBACK SEGMENT XXX来使用它. 这些回滚段应使用OPTIMAL参数,以便在不使用时,可以SHRINK到一个较小的尺寸
建议4:在很难计算准确的数量、大小时,可用"偏大不偏小"的原则 - 原则:所有的回滚段的INITIAL/NEXT参数应设为相同, 只有建议3中提到的大回滚段例外
- 原则:不要将回滚段的MAXEXTENTS设为UNLIMITED, 回滚段所在表空间也不要设为AUTOEXTEND
模式和模式对象
每一个数据库用户对应一个模式,每个模式由模式对象的集合构成,模式对象是由用户创建的逻辑结构,用以包含或引用他们的数据,其中模式对象包含如下:
- 系统表和用户表(Table)
- 聚集(Cluster)
- 视图(View)
- 索引(Index)
- 序列生成器(Sequence)
- 同义词(Synonym)
- 程序单元(存储过程、函数、包)
- 数据库链(Database Link)
- 触发器(Trigger)
- …
表空间与模式对象的关系

数据块-数据区段-段
- 数据块
ORACLE管理数据文件存储空间的单位,是数据I/O最小单位,它的大小为操作系统块大小的倍数,一般为2K或者4K、8K、16K - 数据区间(extent) DBA/ALL/USER_EXTENTS
是数据库存储空间分配的一个逻辑单位,由一定数目连续存放的数据块构成数据区间;当段中所有数据区间被用完后,数据就新分配一个数据区间; 一个区只能存在于一个数据文件中。 - 段
由存储某一个数据库模式对象数据的所有数据区间共同构成一个段
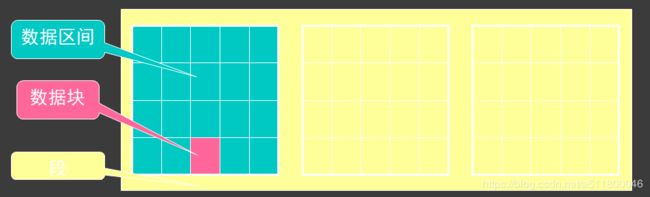
段类型
- 数据段:存储实际数据的段
- 索引段:存储索引信息的段
- 回滚段:由DBA建立,存储事务处理回退信息的段
- 临时段:当一个SQL语句需要临时工作区时,由ORACLE建立
控制区的大小
- 一般语法
STORAGE(
[INITIAL integer [K|M]
[NEXT [K|m]}
[MINEXTENTS integer]
[MAXEXTENTS {integer|UNLIMITED}]
[PCTINCREASE integer]
- 说明
使用STORAGE子句的MINEXTENTS参数确定在创建该段时分配的
区数。Oracle在创建新段时至少分配一个区。
使用MAXEXTENTS参数限定Oracle给该段分配区的最大数量。
INITIAL参数设置改段初始区的大小,使用NEXT参数控制后续
区的大小,使用PCTINCREASE参数指定在分配该段后续区之前
使用的增长因子。
内存结构
服务端进程和内存区两者构建了oracle系统内存组成结构;oracle服务端=服务端进程+内存区+数据库;oracle实例是oracle用来管理数据库访问的服务器端进程及内存区域的集合。
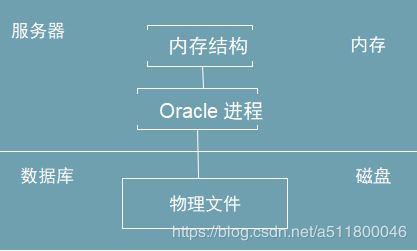
内存结构示意图

系统全局区SGA
为一组由ORACLE分配的共享的内存结构,可包含一个数据库实例的数据或控制信息,可划分为如下内存区:
- 数据库数据缓存
用来存放那些已经修改但还没有写到磁盘的数据,采用LRU(最近最少使用)机制管理。 - 重做日志缓存
- 用来在内存中存储已经被修改的数据库信息。采用循环使用机制,
从头到尾的顺序写,直到写满则由LGWR将该区内的所有数据写入
重做日志文件,然后回到缓存开头重新写 - 共享池
用来存放SQL、PL/SQL、过程、包、数据字典锁、字符设置信息、
安全属性等 ,主要包括数据字典区和共享SQL区
影响SGA的参数
影响SGA的参数有db_block_buffers、db_block_size、log_buffer、shared_pool_size
db_block_buffers的值越高,用户需要的数据在内存的可能性越大,从而减少了Oracle到硬盘访问数据的次数(物理I/O)
然而, db_block_buffers的值太高, Oracle不得不在内存中寻找更多的块来定位你需要的那一块,反而降低了系统性能。
更多的log_buffer减少了数据被填充到日志文件中的次数。
shared_pool_size的值越大,可使经常使用的包和过程长驻内存,可以提高数据库的性能。
SGA不得超过内存的50%
- SGA大小的计算
$(DB_BLOCK_BUFFERS * DB_BLOCK_SIZE) + SORT_AREA_SIZE + SHARED_POOL_SIZE + LOG_BUFFER + JAVA_POOL_SIZE + LARGE_POOL_SIZE $
程序全局区PGA
是一个内存区,包含单个进程的数据和控制信息,所以又叫进程全局区(Process Global Area)

进程结构
数据库进程分为用户进程和oracle系统进程(服务器进程和后台进程)
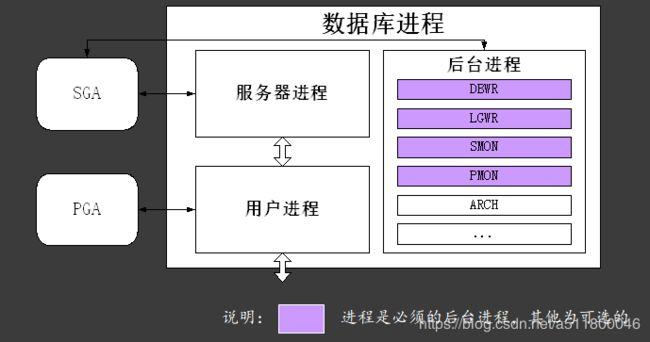
SGA和oracle进程间的关系
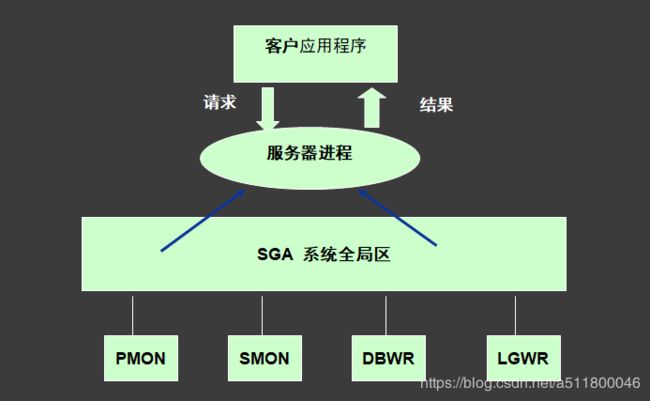
oracle系统进程
oracle系统进程分为分为服务器进程和后台进程,服务器进程专门用来处理连接oracle实例的请求,后台进程包括:
- DBWR 数据库写入进程
- LGWR 日志写入进程
- PMON 程序监控进程
- SMON 系统监控进程
- CKPT 检查点进程
- ARCH 归档日志进程
- …
oracle后台进程
数据库写入进程 DBWR
- 工作内容
将修改过的数据缓冲区的数据写入对应数据文件,维护系统内的空缓冲区 - DBWR工作的主要条件如下
- 系统中没有多的空缓冲区用来存放数据
- CKPT 进程触发DBWR 等
日志写入进程 LGWR
- 工作内容
将重做日志缓冲区的数据写入重做日志文件 - LGWR 工作的主要条件如下
- 用户提交
- 有1/3 重做日志缓冲区未被写入磁盘
- 有大于1M 重做日志缓冲区未被写入磁盘
- 3s一次
系统监控进程 SMON
- 工作内容
- 清除临时空间
- 在系统启动时,完成系统实例恢复
程序监控进程 PMON
- 工作内容
主要用于清除失效的用户进程,释放用户进程所用的资源
检查点进程 CKPT
- CKPT工作的主要条件如下
- 在日志切换的时候
- 数据库用immediate ,transaction , normal 选项shutdown数据库的时候
- 根据初始化文件LOG_CHECKPOINT_INTERVAL、LOG_CHECKPOINT_TIMEOUT、FAST_START_IO_TARGET 的设置的数值来确定
用户触发checkpoint是一个数据库事件,它将已修改的数据从高速缓存刷新到磁盘,并更新控制文件和数据文件。
- 以下几种情况会触发checkpoint。
- 当发生日志组切换的时候。
- 当符合
LOG_CHECKPOINT_TIMEOUT,LOG_CHECKPOINT_INTERVAL,FAST_START_IO_TARGET,FAST_START_MTTR_TARGET参数设置的时候。 - 当运行ALTER SYSTEM SWITCH LOGFILE的时候。
- 当运行ALTER SYSTEM CHECKPOINT的时候。
- 当运行alter tablespace XXX begin backup,end backup的时候。
- 当运行alter tablespace ,datafile offline的时候。
归档日志进程 ARCH
- 工作内容
当数据库以归档方式运行的时候,Oracle会启动ARCH进程,当
重做日志文件被写满时,日志文件进行切换,旧的重做日志文
件就被ARCH进程复制到一个/多个特定的目录/远程机器。这些
被复制的重做日志文件被叫做归档日志文件。
服务进程Server Process
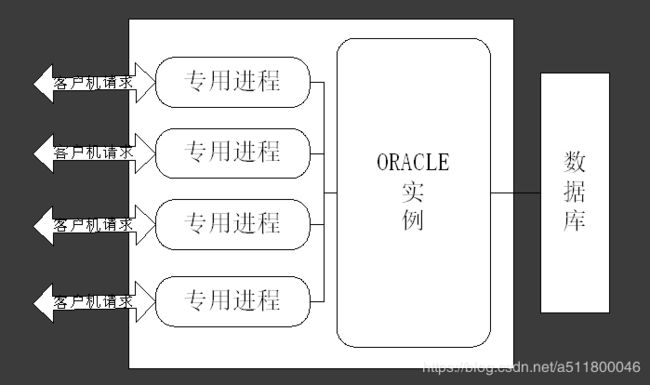
服务器进程分为专用服务进程和共享服务进程
- 专用服务进程(Dedicated Server Process)
一个服务进程对应一个用户进程 - 共享服务进程(MultiTreaded Server Process)
一个服务进程对应多个用户进程,轮流为用户进程服务
专用服务器架构
- 特点:为每个用户/连接分配一个专用的进程来处理请求
- 适合场景:用于大数据量处理的连接
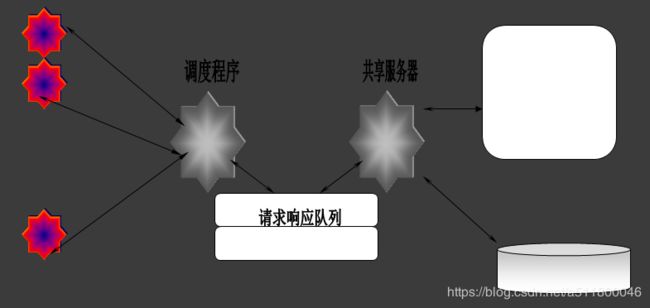
多线程服务器架构
- 特点:在一个进程中启动不同多线程来处理用户请求
- 组成:调度请求、共享服务器、队列(请求和响应)
- 适合场景:适合大量连接并发,请求频繁的环境
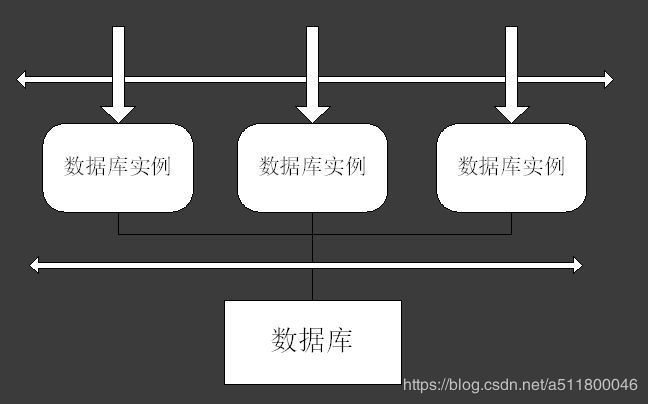
并行服务器架构
Oracle并行或集群数据库由两台或更多台物理服务器(节点)组成,它们管理着自己的Oracle实例,并共享一个磁盘阵列。每个节点的Oracle实例有自己的"系统全局区"(SGA)和自己的重做日志文件,但数据文件和控制文件由所有实例共用。数据文件和控制文件由所有实例同时读写;但是,重做日志文件可以由任意实例读取,但只能由拥有它的实例写入。一些参数,如db_block_buffers和log_buffer,可以在每个实例中进行不同配置,但其他一些参数必须在所有实例中均保持一致。每个集群节点有其自己的后台进程集合,就像单个实例一样。另外,还会在每个实例上启动OPS特有的进程,以处理跨实例通信、锁定管理和数据块传送。
分布式服务器架构