本文阿宝哥将按照以下的流程来介绍前端如何进行图片处理,然后穿插介绍二进制、Blob、Blob URL、Base64、Data URL、ArrayBuffer、TypedArray、DataView 和图片压缩相关的知识点。
![[1.3万字] 玩转前端二进制_第1张图片](http://img.e-com-net.com/image/info9/0b73f7c1d0f540d9b276f8e87a0505b5.jpg "image-process-flow-1.jpeg")
阅读完本文,小伙伴们将能轻松看懂以下转换关系图:
![[1.3万字] 玩转前端二进制_第2张图片](http://img.e-com-net.com/image/info9/f55024110dc74933b00f7d3a289eecd0.jpg "binary-object-transfer-flow.jpeg")
还在犹豫什么?跟上阿宝哥的脚步,让我们一起来玩转前端二进制。请小伙伴们原谅阿宝哥的 “自恋”,在后面的示例中,我们将使用阿宝哥的个人头像作为演示素材。
![[1.3万字] 玩转前端二进制_第3张图片](http://img.e-com-net.com/image/info9/91148b3bf425425f8614042326d83ca7.jpg "abao.png")
好的,现在我们开始来进入第一个环节:选择本地图片 -> 图片预览。
一、选择本地图片 -> 图片预览
1.1 FileReader API
在支持 FileReader API 的浏览器中,我们也可以利用该 API 方便实现图片本地预览功能。
![[1.3万字] 玩转前端二进制_第4张图片](http://img.e-com-net.com/image/info9/5c24eb7b9c284947abc407d841a554b1.jpg "caniuse-file-reader.jpg")
(图片来源:https://caniuse.com/#search=f...)
由上图可知,该 API 兼容性较好,我们可以放心使用。这里阿宝哥就不展开详细介绍 FileReader API,我们直接来看一下利用它如何实现本地图片预览,具体代码如下:
图片本地预览示例
阿宝哥:图片本地预览示例
![]()
在以上示例中,我们为 file 类型的输入框绑定 onchange 事件处理函数 loadFile,在该函数中,我们创建了一个 FileReader 对象并为该对象绑定 onload 相应的事件处理函数,然后调用 FileReader 对象的 readAsDataURL() 方法,把本地图片对应的 File 对象转换为 Data URL。
其实对于 FileReader 对象来说,除了支持把 File/Blob 对象转换为 Data URL 之外,它还提供了readAsArrayBuffer()和readAsText()方法,用于把 File/Blob 对象转换为其它的数据格式。
当文件读取完成后,会触发绑定的 onload 事件处理函数,在该处理函数内部会把获取 Data URL 数据赋给 img 元素的 src 属性,从而实现图片本地预览。
通过使用 Chrome 开发者工具,我们可以在 Elements 面板中看到 Data URL 的 “芳容”:
![[1.3万字] 玩转前端二进制_第5张图片](http://img.e-com-net.com/image/info9/f3b6cb38533f4f4ca3ef6c6e2f859963.jpg)
在图中右侧的绿色框中,我们可以清楚的看到 img 元素 src 属性值是一串非常 奇怪 的字符串:
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAhAAAAIwCAYAAADXrFK...其实,这串奇怪的字符串被称为 Data URL,它由四个部分组成:前缀(data:)、指示数据类型的 MIME 类型、如果非文本则为可选的 base64 标记、数据本身:
data:[][;base64], mediatype 是个 MIME 类型的字符串,比如 "image/png" 表示 PNG 图像文件。如果被省略,则默认值为 text/plain;charset=US-ASCII。如果数据是文本类型,你可以直接将文本嵌入(根据文档类型,使用合适的实体字符或转义字符)。如果是二进制数据,你可以将数据进行 base64 编码之后再进行嵌入。
MIME(Multipurpose Internet Mail Extensions)多用途互联网邮件扩展类型,是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。常见的 MIME 类型有:超文本标记语言文本 .html text/html、PNG 图像 .png image/png、普通文本 .txt text/plain 等。
在 Web 项目开发过程中,为了减少 HTTP 请求的数量,对应一些较小的图标,我们通常会考虑使用 Data URL 的形式内嵌到 HTML 或 CSS 文件中。 但需要注意的是:如果图片较大,图片的色彩层次比较丰富,则不适合使用这种方式,因为该图片经过 base64 编码后的字符串非常大,会明显增大 HTML 页面的大小,从而影响加载速度。
在 Data URL 中,数据是很重要的一部分,它使用 base64 编码的字符串来表示。因此要掌握 Data URL,我们还得了解一下 Base64。
1.2 Base64
Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法。由于 2⁶ = 64 ,所以每 6 个比特为一个单元,对应某个可打印字符。3 个字节有 24 个比特,对应于 4 个 base64 单元,即 3 个字节可由 4 个可打印字符来表示。相应的转换过程如下图所示:
![[1.3万字] 玩转前端二进制_第6张图片](http://img.e-com-net.com/image/info9/38b7cd7e053b4c699e9ba4150b23c5f3.png)
Base64 常用于在处理文本数据的场合,表示、传输、存储一些二进制数据,包括 MIME 的电子邮件及 XML 的一些复杂数据。 在 MIME 格式的电子邮件中,base64 可以用来将二进制的字节序列数据编码成 ASCII 字符序列构成的文本。使用时,在传输编码方式中指定 base64。使用的字符包括大小写拉丁字母各 26 个、数字 10 个、加号 + 和斜杠 /,共 64 个字符,等号 = 用来作为后缀用途。
Base64 相应的索引表如下:
![[1.3万字] 玩转前端二进制_第7张图片](http://img.e-com-net.com/image/info9/5fba17d111ac4b1a8b6f24b5c5bdb829.jpg)
了解完上述的知识,我们以编码 Man 为例,来直观的感受一下编码过程。Man 由 M、a 和 n 这 3 个字符组成,它们对应的 ASCII 码为 77、97 和 110。
![[1.3万字] 玩转前端二进制_第8张图片](http://img.e-com-net.com/image/info9/79b460ba3c3f4bad9f252ab16e4abc52.jpg)
接着我们以每 6 个比特为一个单元,进行 base64 编码操作,具体如下图所示:
![[1.3万字] 玩转前端二进制_第9张图片](http://img.e-com-net.com/image/info9/6f1a3cb8df0342eda3453b909a52f500.jpg)
由图可知,Man (3 字节)编码的结果为 TWFu(4 字节),很明显经过 base64 编码后体积会增加 1/3。Man 这个字符串的长度刚好是 3,我们可以用 4 个 base64 单元来表示。但如果待编码的字符串长度不是 3 的整数倍时,应该如何处理呢?
如果要编码的字节数不能被 3 整除,最后会多出 1 个或 2 个字节,那么可以使用下面的方法进行处理:先使用 0 字节值在末尾补足,使其能够被 3 整除,然后再进行 base64 的编码。
以编码字符 A 为例,其所占的字节数为 1,不能被 3 整除,需要补 2 个字节,具体如下图所示:
![[1.3万字] 玩转前端二进制_第10张图片](http://img.e-com-net.com/image/info9/d1ba5a3de8f84702a7992e097f042cc5.jpg)
由上图可知,字符 A 经过 base64 编码后的结果是 QQ==,该结果后面的两个 = 代表补足的字节数。而最后个 1 个 base64 字节块有 4 位是 0 值。
接着我们来看另一个示例,假设需编码的字符串为 BC,其所占字节数为 2,不能被 3 整除,需要补 1 个字节,具体如下图所示:
![[1.3万字] 玩转前端二进制_第11张图片](http://img.e-com-net.com/image/info9/beb2128218b745268779ccee59a97a5e.jpg)
由上图可知,字符串 BC 经过 base64 编码后的结果是 QkM=,该结果后面的 1 个 = 代表补足的字节数。而最后个 1 个 base64 字节块有 2 位是 0 值。
在 JavaScript 中,有两个函数被分别用来处理解码和编码 base64 字符串:
- btoa():该函数能够基于二进制数据 “字符串” 创建一个 base64 编码的 ASCII 字符串。
- atob(): 该函数能够解码通过 base64 编码的字符串数据。
1.2.1 btoa 使用示例
const name = 'Semlinker';
const encodedName = btoa(name);
console.log(encodedName); // U2VtbGlua2Vy1.2.2 atob 使用示例
const encodedName = 'U2VtbGlua2Vy';
const name = atob(encodedName);
console.log(name); // Semlinker对于 atob 和 btoa 这两个方法来说,其中的 a 代表 ASCII,而 b 代表 Blob,即二进制。因此 atob 表示 ASCII 到二进制,对应的是解码操作。而 btoa 表示二进制到 ASCII,对应的是编码操作。在了解方法中 a 和 b 分别代表的意义之后,在以后的工作中,我们就不会用错了。
相信看到这里,小伙伴们对 base64 已经有一定的了解。需要注意的是 base64 只是一种数据编码方式,目的是为了保障数据的安全传输。但标准的 base64 编码无需额外的信息,即可以进行解码,是完全可逆的。因此在涉及传输私密数据时,并不能直接使用 base64 编码,而是要使用专门的对称或非对称加密算法。
二、网络下载图片 -> 图片预览
除了可以从本地获取图片之外,我们也可以使用 fetch API 从网络上获取图片,然后在进行图片预览。当然对于网络上可正常访问的图片地址,我们可以直接把地址赋给 img 元素,并不需要通过 fetch API 绕一大圈。若在显示图片时,你需要对图片进行特殊处理,比如解密图片数据时,你就可以考虑在 Web Worker 中使用 fetch API 获取图片数据并进行解密操作。
简单起见,我们不考虑特殊的场景。首先我们先来看一下 fetch API 的兼容性:
![[1.3万字] 玩转前端二进制_第12张图片](http://img.e-com-net.com/image/info9/ba0053e9bfa44087aa0f5f4c18214691.jpg)
(图片来源:https://caniuse.com/#search=f...)
然后我们使用 fetch API 从 Github 上获取阿宝哥的头像,具体代码如下所示:
获取远程图片预览示例
阿宝哥:获取远程图片预览示例
![]()
在以上示例中,我们通过 fetch API 从 Github 上下载阿宝哥的头像,当请求成功后,把响应对象(Response)转换为 Blob 对象,然后使用 URL.createObjectURL 方法,创建 Object URL 并把它赋给 img 元素的 src 属性,从而实现图片的显示。
通过使用 Chrome 开发者工具,我们可以在 Elements 面板中看到 Object URL 的 “芳容”:
![[1.3万字] 玩转前端二进制_第13张图片](http://img.e-com-net.com/image/info9/c0d38cd1f54144ee833dbd6e58acd159.jpg)
在图中右侧的绿色框中,我们可以清楚的看到 img 元素 src 属性值是一串非常 特殊 的字符串:
blob:null/ab24c171-1c5f-4de1-a44e-568bc1f77d7b以上的特殊字符串,我们称之为 Object URL,相比前面介绍的 Data URL,它简洁很多。接下来我们来认识一下 Object URL 这种协议。
2.1 Object URL
Object URL 是一种伪协议,也被称为 Blob URL。它允许 Blob 或 File 对象用作图像,下载二进制数据链接等的 URL 源。在浏览器中,我们使用 URL.createObjectURL 方法来创建 Blob URL,该方法接收一个 Blob 对象,并为其创建一个唯一的 URL,其形式为 blob:,对应的示例如下:
blob:https://example.org/40a5fb5a-d56d-4a33-b4e2-0acf6a8e5f641浏览器内部为每个通过 URL.createObjectURL 生成的 URL 存储了一个 URL → Blob 映射。因此,此类 URL 较短,但可以访问 Blob。生成的 URL 仅在当前文档打开的状态下才有效。但如果你访问的 Blob URL 不再存在,则会从浏览器中收到 404 错误。
上述的 Blob URL 看似很不错,但实际上它也有副作用。虽然存储了 URL → Blob 的映射,但 Blob 本身仍驻留在内存中,浏览器无法释放它。映射在文档卸载时自动清除,因此 Blob 对象随后被释放。但是,如果应用程序寿命很长,那不会很快发生。因此,如果我们创建一个 Blob URL,即使不再需要该 Blob,它也会存在内存中。
针对这个问题,我们可以调用 URL.revokeObjectURL(url) 方法,从内部映射中删除引用,从而允许删除 Blob(如果没有其他引用),并释放内存。
既然讲到了 Blob URL,不得不提 Blob。那么什么是 Blob 呢?我们继续往下看。
2.2 Blob API
Blob(Binary Large Object)表示二进制类型的大对象。在数据库管理系统中,将二进制数据存储为一个单一个体的集合。Blob 通常是影像、声音或多媒体文件。在 JavaScript 中 Blob 类型的对象表示不可变的类似文件对象的原始数据。 为了更直观的感受 Blob 对象,我们先来使用 Blob 构造函数,创建一个 myBlob 对象,具体如下图所示:
![[1.3万字] 玩转前端二进制_第14张图片](http://img.e-com-net.com/image/info9/f74c0d3ea6874f1a9ae45a413dc78e37.jpg)
如你所见,myBlob 对象含有两个属性:size 和 type。其中 size 属性用于表示数据的大小(以字节为单位),type 是 MIME 类型的字符串。Blob 表示的不一定是 JavaScript 原生格式的数据。比如 File 接口基于 Blob,继承了 blob 的功能并将其扩展使其支持用户系统上的文件。
Blob 由一个可选的字符串 type(通常是 MIME 类型)和 blobParts 组成:
![[1.3万字] 玩转前端二进制_第15张图片](http://img.e-com-net.com/image/info9/7b75aa95de364292b287e21473092ed9.jpg)
MIME(Multipurpose Internet Mail Extensions)多用途互联网邮件扩展类型,是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。常见的 MIME 类型有:超文本标记语言文本 .html text/html、PNG图像 .png image/png、普通文本 .txt text/plain 等。
2.2.1 Blob 构造函数
Blob 构造函数的语法为:
var aBlob = new Blob(blobParts, options);相关的参数说明如下:
- blobParts:它是一个由 ArrayBuffer,ArrayBufferView,Blob,DOMString 等对象构成的数组。DOMStrings 会被编码为 UTF-8。
-
options:一个可选的对象,包含以下两个属性:
- type —— 默认值为
"",它代表了将会被放入到 blob 中的数组内容的 MIME 类型。 - endings —— 默认值为
"transparent",用于指定包含行结束符\n的字符串如何被写入。 它是以下两个值中的一个:"native",代表行结束符会被更改为适合宿主操作系统文件系统的换行符,或者"transparent",代表会保持 blob 中保存的结束符不变。
- type —— 默认值为
示例一:从字符串创建 Blob
let myBlobParts = ['Hello Semlinker
']; // an array consisting of a single DOMString
let myBlob = new Blob(myBlobParts, {type : 'text/html', endings: "transparent"}); // the blob
console.log(myBlob.size + " bytes size");
// Output: 37 bytes size
console.log(myBlob.type + " is the type");
// Output: text/html is the type示例二:从类型化数组和字符串创建 Blob
let hello = new Uint8Array([72, 101, 108, 108, 111]); // 二进制格式的 "hello"
let blob = new Blob([hello, ' ', 'semlinker'], {type: 'text/plain'});介绍完 Blob 构造函数,接下来我们来分别介绍 Blob 类的属性和方法:
![[1.3万字] 玩转前端二进制_第16张图片](http://img.e-com-net.com/image/info9/704ad5f834204341b60f6f50be0bd06a.jpg)
2.2.2 Blob 属性
前面我们已经知道 Blob 对象包含两个属性:
- size(只读):表示
Blob对象中所包含数据的大小(以字节为单位)。 - type(只读):一个字符串,表明该
Blob对象所包含数据的 MIME 类型。如果类型未知,则该值为空字符串。
2.2.3 Blob 方法
- slice([start[, end[, contentType]]]):返回一个新的 Blob 对象,包含了源 Blob 对象中指定范围内的数据。
- stream():返回一个能读取 blob 内容的
ReadableStream。 - text():返回一个 Promise 对象且包含 blob 所有内容的 UTF-8 格式的
USVString。 - arrayBuffer():返回一个 Promise 对象且包含 blob 所有内容的二进制格式的
ArrayBuffer。
这里我们需要注意的是,Blob 对象是不可改变的。我们不能直接在一个 Blob 中更改数据,但是我们可以对一个 Blob 进行分割,从其中创建新的 Blob 对象,将它们混合到一个新的 Blob 中。这种行为类似于 JavaScript 字符串:我们无法更改字符串中的字符,但可以创建新的更正后的字符串。
对于 fetch API 的 Response 对象来说,该对象除了提供 blob() 方法之外,还提供了 json()、 text() 、formData() 和 arrayBuffer() 等方法,用于把响应转换为不同的数据格式。
在前后端分离的项目中,大家用得比较多的应该就是 json() 方法,而其它方法可能用得相对比较少。对于前面的示例,我们把响应对象转换为 ArrayBuffer 对象,同样可以正常显示从网络下载的图像,具体的代码如下所示:
阿宝哥:获取远程图片预览示例
![]()
在以上代码中,我们先把响应对象转换为 ArrayBuffer 对象,然后通过调用 Blob 构造函数,把 ArrayBuffer 对象转换为 Blob 对象,再利用 createObjectURL() 方法创建 Object URL,最终实现图片预览。
相信有些小伙伴对 ArrayBuffer 还不太熟悉,下面阿宝哥就带大家一起来揭开它的神秘 “面纱”。
2.3 ArrayBuffer 与 TypedArray
2.3.1 ArrayBuffer
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。ArrayBuffer 不能直接操作,而是要通过类型数组对象 或 DataView 对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。
ArrayBuffer 简单说是一片内存,但是你不能直接用它。这就好比你在 C 里面,malloc 一片内存出来,你也会把它转换成 unsigned_int32 或者 int16 这些你需要的实际类型的数组/指针来用。这就是 JS 里的 TypedArray 的作用,那些 Uint32Array 也好,Int16Array 也好,都是给 ArrayBuffer 提供了一个 “View”,MDN 上的原话叫做 “Multiple views on the same data”,对它们进行下标读写,最终都会反应到它所建立在的 ArrayBuffer 之上。
语法
new ArrayBuffer(length)- 参数:length 表示要创建的 ArrayBuffer 的大小,单位为字节。
- 返回值:一个指定大小的 ArrayBuffer 对象,其内容被初始化为 0。
- 异常:如果 length 大于
Number.MAX_SAFE_INTEGER(>= 2 ** 53)或为负数,则抛出一个RangeError异常。
示例
下面的例子创建了一个 8 字节的缓冲区,并使用一个 Int32Array 来引用它:
let buffer = new ArrayBuffer(8);
let view = new Int32Array(buffer);从 ECMAScript 2015 开始,ArrayBuffer 对象需要用 new 运算符创建。如果调用构造函数时没有使用 new,将会抛出 TypeError 异常。比如执行该语句 let ab = ArrayBuffer(10) 将会抛出以下异常:
VM109:1 Uncaught TypeError: Constructor ArrayBuffer requires 'new'
at ArrayBuffer ()
at :1:10 对于一些常用的 Web API,如 FileReader API 和 Fetch API 底层也是支持 ArrayBuffer,这里我们以 FileReader API 为例,看一下如何把 File 对象读取为 ArrayBuffer 对象:
const reader = new FileReader();
reader.onload = function(e) {
let arrayBuffer = reader.result;
}
reader.readAsArrayBuffer(file);2.3.2 Unit8Array
Uint8Array 数组类型表示一个 8 位无符号整型数组,创建时内容被初始化为 0。创建完后,可以以对象的方式或使用数组下标索引的方式引用数组中的元素。
语法
new Uint8Array(); // ES2017 最新语法
new Uint8Array(length); // 创建初始化为0的,包含length个元素的无符号整型数组
new Uint8Array(typedArray);
new Uint8Array(object);
new Uint8Array(buffer [, byteOffset [, length]]);示例
// new Uint8Array(length);
var uint8 = new Uint8Array(2);
uint8[0] = 42;
console.log(uint8[0]); // 42
console.log(uint8.length); // 2
console.log(uint8.BYTES_PER_ELEMENT); // 1
// new TypedArray(object);
var arr = new Uint8Array([21,31]);
console.log(arr[1]); // 31
// new Uint8Array(typedArray);
var x = new Uint8Array([21, 31]);
var y = new Uint8Array(x);
console.log(y[0]); // 21
// new Uint8Array(buffer [, byteOffset [, length]]);
var buffer = new ArrayBuffer(8);
var z = new Uint8Array(buffer, 1, 4);2.3.3 ArrayBuffer 与 TypedArray 之间的关系
ArrayBuffer 本身只是一行 0 和 1 串。 ArrayBuffer 不知道该数组中第一个元素和第二个元素之间的分隔位置。
![[1.3万字] 玩转前端二进制_第17张图片](http://img.e-com-net.com/image/info9/a0d44a15139d49d19102440a157c54cf.png)
(图片来源 —— A cartoon intro to ArrayBuffers and SharedArrayBuffers)
为了提供上下文,实际上要将其分解为多个盒子,我们需要将其包装在所谓的视图中。可以使用类型数组添加这些数据视图,并且你可以使用许多不同类型的类型数组。
例如,你可以有一个 Int8 类型的数组,它将把这个数组分成 8-bit 的字节数组。
![[1.3万字] 玩转前端二进制_第18张图片](http://img.e-com-net.com/image/info9/090c7348601c490c8aac203509ffd410.jpg)
(图片来源 —— A cartoon intro to ArrayBuffers and SharedArrayBuffers)
或者你也可以有一个无符号 Int16 数组,它会把数组分成 16-bit 的字节数组,并且把它当作无符号整数来处理。
![[1.3万字] 玩转前端二进制_第19张图片](http://img.e-com-net.com/image/info9/c5c97868033c4d3dae85846981eaba3d.jpg)
(图片来源 —— A cartoon intro to ArrayBuffers and SharedArrayBuffers)
你甚至可以在同一基本缓冲区上拥有多个视图。对于相同的操作,不同的视图会给出不同的结果。
例如,如果我们从这个 ArrayBuffer 的 Int8 视图中获取 0 & 1 元素的值(-19 & 100),它将给我们与 Uint16 视图中元素 0 (25837)不同的值,即使它们包含完全相同的位。
![[1.3万字] 玩转前端二进制_第20张图片](http://img.e-com-net.com/image/info9/0a5afe45edc24a14a961cc4143089073.jpg)
(图片来源 —— A cartoon intro to ArrayBuffers and SharedArrayBuffers)
这样,ArrayBuffer 基本上就像原始内存一样。它模拟了使用 C 之类的语言进行的直接内存访问。你可能想知道为什么我们不让程序直接访问内存,而是添加了这种抽象层,因为直接访问内存将导致一些安全漏洞。
目前,我们已经了解 Blob 与 ArrayBuffer,那么它们之前有什么区别呢?
2.4 Blob vs ArrayBuffer
ArrayBuffer 对象用于表示通用的,固定长度的原始二进制数据缓冲区。你不能直接操纵 ArrayBuffer 的内容,而是需要创建一个类型化数组对象或 DataView 对象,该对象以特定格式表示缓冲区,并使用该对象读取和写入缓冲区的内容。
Blob 类型的对象表示不可变的类似文件对象的原始数据。Blob 表示的不一定是 JavaScript 原生格式的数据。File 接口基于 Blob,继承了Blob 功能并将其扩展为支持用户系统上的文件。
2.4.1 Blob 与 ArrayBuffer 的区别
- 除非你需要使用 ArrayBuffer 提供的写入/编辑的能力,否则 Blob 格式可能是最好的。
- Blob 对象是不可变的,而 ArrayBuffer 是可以通过 TypedArrays 或 DataView 来操作。
- ArrayBuffer 是存在内存中的,可以直接操作。而 Blob 可以位于磁盘、高速缓存内存和其他不可用的位置。
- 虽然 Blob 可以直接作为参数传递给其他函数,比如
window.URL.createObjectURL()。但是,你可能仍需要 FileReader 之类的 File API 才能与 Blob 一起使用。 -
Blob 与 ArrayBuffer 对象之间是可以相互转化的:
- 使用 FileReader 的
readAsArrayBuffer()方法,可以把 Blob 对象转换为 ArrayBuffer 对象; - 使用 Blob 构造函数,如
new Blob([new Uint8Array(data]);,可以把 ArrayBuffer 对象转换为 Blob 对象。
- 使用 FileReader 的
为了便于大家理解转换过程,阿宝哥简单举个相互转换的示例:
2.4.2 Blob 转换为 ArrayBuffer
var blob = new Blob(["\x01\x02\x03\x04"]),
fileReader = new FileReader(),
array;
fileReader.onload = function() {
array = this.result;
console.log("Array contains", array.byteLength, "bytes.");
};
fileReader.readAsArrayBuffer(blob);2.4.3 ArrayBuffer 转 Blob
var array = new Uint8Array([0x01, 0x02, 0x03, 0x04]);
var blob = new Blob([array]);2.5 DataView 与 ArrayBuffer
DataView 视图是一个可以从二进制 ArrayBuffer 对象中读写多种数值类型的底层接口,使用它时,不用考虑不同平台的字节序问题。
字节顺序,又称端序或尾序(英语:Endianness),在计算机科学领域中,指存储器中或在数字通信链路中,组成多字节的字的字节的排列顺序。字节的排列方式有两个通用规则。例如,一个多位的整数,按照存储地址从低到高排序的字节中,如果该整数的最低有效字节(类似于最低有效位)在最高有效字节的前面,则称小端序;反之则称大端序。在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化。
例如假设上述变量
x类型为int,位于地址0x100处,它的值为0x01234567,地址范围为0x100~0x103字节,其内部排列顺序依赖于机器的类型。大端法从首位开始将是:0x100: 01, 0x101: 23,..。而小端法将是:0x100: 67, 0x101: 45,..。
2.5.1 DataView 构造函数
new DataView(buffer [, byteOffset [, byteLength]])相关的参数说明如下:
- buffer:一个已经存在的 ArrayBuffer 或 SharedArrayBuffer 对象,DataView 对象的数据源。
- byteOffset(可选):此 DataView 对象的第一个字节在 buffer 中的字节偏移。如果未指定,则默认从第一个字节开始。
- byteLength:此 DataView 对象的字节长度。如果未指定,这个视图的长度将匹配 buffer 的长度。
DataView 返回值
使用 new 调用 DataView 构造函数后,会返回一个表示指定数据缓存区的新 DataView 对象。你可以把返回的对象想象成一个二进制字节缓存区 array buffer 的 “解释器” —— 它知道如何在读取或写入时正确地转换字节码。这意味着它能在二进制层面处理整数与浮点转化、字节顺序等其他有关的细节问题。
DataView 使用示例
const buffer = new ArrayBuffer(16);
// Create a couple of views
const view1 = new DataView(buffer);
const view2 = new DataView(buffer, 12, 4); //from byte 12 for the next 4 bytes
view1.setInt8(12, 42); // put 42 in slot 12
console.log(view2.getInt8(0)); // expected output: 422.5.2 DataView 属性
所有 DataView 实例都继承自 DataView.prototype,并且允许向 DataView 对象中添加额外属性。
- DataView.prototype.buffer(只读):指向创建 DataView 时设定的 ArrayBuffer 对象;
- DataView.prototype.byteLength(只读):表示 ArrayBuffer 或 SharedArrayBuffer 对象的字节长度;
- DataView.prototype.byteOffset(只读):表示从 ArrayBuffer 读取时的偏移字节长度。
2.5.3 DataView 方法
DataView 对象提供了 getInt8()、getUint8()、setInt8() 和 setUint8() 等方法来操作数据。具体每个方法的使用,我们就不详细介绍。这里我们来看个简单的例子:
const buffer = new ArrayBuffer(16);
const view = new DataView(buffer, 0);
view.setInt8(1, 68);
view.getInt8(1); // 68介绍完 ArrayBuffer、TypedArray 和 DataView 的相关知识,阿宝哥用一张图来总结一下它们之间的关系。
![[1.3万字] 玩转前端二进制_第21张图片](http://img.e-com-net.com/image/info9/0d876e51d6a34144a3a40b22dec2d3ff.jpg)
好的,下面我们马上进入下一个环节。
三、图片灰度化
要对图片进行灰度化处理,我们就需要操作图片像素数据。那么问题来了,我们应该如何获取图片的像素数据呢?
3.1 getImageData 方法
针对上述问题,我们可以利用 CanvasRenderingContext2D 提供的 getImageData 来获取图片像素数据,其中 getImageData() 返回一个 ImageData 对象,用来描述 canvas 区域隐含的像素数据,这个区域通过矩形表示,起始点为(sx, sy)、宽为 sw、高为 sh。其中 getImageData 方法的语法如下:
ctx.getImageData(sx, sy, sw, sh);相应的参数说明如下:
- sx:将要被提取的图像数据矩形区域的左上角 x 坐标。
- sy:将要被提取的图像数据矩形区域的左上角 y 坐标。
- sw:将要被提取的图像数据矩形区域的宽度。
- sh:将要被提取的图像数据矩形区域的高度。
3.2 putImageData 方法
在获取到图片的像素数据之后,我们就可以对获取的像素数据进行处理,比如进行灰度化或反色处理。当完成处理后,若要在页面上显示处理效果,则我们需要利用 CanvasRenderingContext2D 提供的另一个 API —— putImageData。
该 API 是 Canvas 2D API 将数据从已有的 ImageData 对象绘制到位图的方法。 如果提供了一个绘制过的矩形,则只绘制该矩形的像素。此方法不受画布转换矩阵的影响。putImageData 方法的语法如下:
void ctx.putImageData(imagedata, dx, dy);
void ctx.putImageData(imagedata, dx, dy, dirtyX, dirtyY, dirtyWidth, dirtyHeight);相应的参数说明如下:
- imageData:
ImageData,包含像素值的数组对象。 - dx:源图像数据在目标画布中的位置偏移量(x 轴方向的偏移量)。
- dy:源图像数据在目标画布中的位置偏移量(y 轴方向的偏移量)。
- dirtyX(可选):在源图像数据中,矩形区域左上角的位置。默认是整个图像数据的左上角(x 坐标)。
- dirtyY(可选):在源图像数据中,矩形区域左上角的位置。默认是整个图像数据的左上角(y 坐标)。
- dirtyWidth(可选):在源图像数据中,矩形区域的宽度。默认是图像数据的宽度。
- dirtyHeight(可选):在源图像数据中,矩形区域的高度。默认是图像数据的高度。
3.3 图片灰度化处理
介绍完 getImageData() 和 putImageData() 方法,下面我们来看一下具体如何利用它们实现图片灰度化:
获取远程图片并灰度化
阿宝哥:获取远程图片并灰度化示例
预览容器
![]()
Canvas容器
在以上示例中,我们先从 Github 上下载阿宝哥的头像,然后先进行本地预览,接着调用 draw() 方法把获取的图像绘制到页面的 Canvas 容器中,同时为灰度化按钮绑定监听事件。
当用户点击灰度化按钮时,将会触发灰度化处理函数,在该函数内部会对通过 ctx.getImageData() 方法获取的图片像素进行灰度化处理,处理完成后再通过 ctx.putImageData() 方法把处理过的像素数据更新到 Canvas 上。
以上代码成功运行后,最终的灰度化效果如下图所示:
![[1.3万字] 玩转前端二进制_第22张图片](http://img.e-com-net.com/image/info9/1071b8894ee94dc4b3f6ad7e6129f64d.jpg "abao-avatar-gray-scale.jpg")
四、图片压缩
在一些场合中,我们希望在上传本地图片时,先对图片进行一定的压缩,然后再提交到服务器,从而减少传输的数据量。在前端要实现图片压缩,我们可以利用 Canvas 对象提供的 toDataURL() 方法,该方法接收 type 和 encoderOptions 两个可选参数。
其中 type 表示图片格式,默认为 image/png。而 encoderOptions 用于表示图片的质量,在指定图片格式为 image/jpeg 或 image/webp 的情况下,可以从 0 到 1 的区间内选择图片的质量。如果超出取值范围,将会使用默认值 0.92,其他参数会被忽略。
下面我们来看一下如何对前面已进行灰度化处理的图片进行压缩。
预览容器
![]()
Canvas容器
压缩预览容器
![]()
在以上代码中,我们设默认的图片质量是 0.8,而图片类型是 image/webp 类型。当用户点击压缩按钮时,则会调用 Canvas 对象的 toDataURL() 方法实现图片压缩。 以上代码成功运行后,最终的处理效果如下图所示:
![[1.3万字] 玩转前端二进制_第23张图片](http://img.e-com-net.com/image/info9/0d851f266c3043f4acce64dc909ae341.jpg)
其实 Canvas 对象除了提供 toDataURL() 方法之外,它还提供了一个 toBlob() 方法,该方法的语法如下:
canvas.toBlob(callback, mimeType, qualityArgument)和 toDataURL() 方法相比,toBlob() 方法是异步的,因此多了个 callback 参数,这个 callback 回调方法默认的第一个参数就是转换好的 blob文件信息。
五、图片上传
在获取压缩后图片对应的 Data URL 数据之后,可以把该数据直接提交到服务器。针对这种情形,服务端需要做一些相关处理,才能正常保存上传的图片,这里以 Express 为例,具体处理代码如下:
const app = require('express')();
app.post('/upload', function(req, res){
let imgData = req.body.imgData; // 获取POST请求中的base64图片数据
let base64Data = imgData.replace(/^data:image\/\w+;base64,/, "");
let dataBuffer = Buffer.from(base64Data, 'base64');
fs.writeFile("abao.png", dataBuffer, function(err) {
if(err){
res.send(err);
}else{
res.send("图片上传成功!");
}
});
});然而对于返回的 Data URL 格式的图片数据一般都会比较大,为了进一步减少传输的数据量,我们可以把它转换为 Blob 对象:
function dataUrlToBlob(base64, mimeType) {
let bytes = window.atob(base64.split(",")[1]);
let ab = new ArrayBuffer(bytes.length);
let ia = new Uint8Array(ab);
for (let i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob([ab], { type: mimeType });
}在转换完成后,我们就可以压缩后的图片对应的 Blob 对象封装在 FormData 对象中,然后再通过 AJAX 提交到服务器上:
function uploadFile(url, blob) {
let formData = new FormData();
let request = new XMLHttpRequest();
formData.append("imgData", blob);
request.open("POST", url, true);
request.send(formData);
}六、阿宝哥有话说
6.1 如何查看图片的二进制数据
要查看图片对应的二进制数据,我们就需要借助一些现成的编辑器,比如 Windows 平台下的 WinHex 或 macOS 平台下的 Synalyze It! Pro 十六进制编辑器。这里我们使用 Synalyze It! Pro 这个编辑器,以十六进制的形式来查看阿宝哥头像对应的二进制数据。
![[1.3万字] 玩转前端二进制_第24张图片](http://img.e-com-net.com/image/info9/71a6cac436a04a08bce6b78f3ee7479b.jpg)
6.2 如何区分图片的类型
计算机并不是通过图片的后缀名来区分不同的图片类型,而是通过 “魔数”(Magic Number)来区分。 对于某一些类型的文件,起始的几个字节内容都是固定的,根据这几个字节的内容就可以判断文件的类型。
常见图片类型对应的魔数如下表所示:
| 文件类型 | 文件后缀 | 魔数 |
|---|---|---|
| JPEG | jpg/jpeg | 0xFFD8FF |
| PNG | png | 0x89504E47 |
| GIF | gif | 0x47494638(GIF8) |
| BMP | bmp | 0x424D |
这里我们以阿宝哥的头像(abao.png)为例,验证一下该图片的类型是否正确:
![[1.3万字] 玩转前端二进制_第25张图片](http://img.e-com-net.com/image/info9/83a81e96b88b46edaa86807a557b1632.jpg)
在日常开发过程中,如果遇到检测图片类型的场景,我们可以直接利用一些现成的第三方库。比如,你想要判断一张图片是否为 PNG 类型,这时你可以使用 is-png 这个库,它同时支持浏览器和 Node.js,使用示例如下:
Node.js
// npm install read-chunk
const readChunk = require('read-chunk');
const isPng = require('is-png');
const buffer = readChunk.sync('unicorn.png', 0, 8);
isPng(buffer);
//=> trueBrowser
(async () => {
const response = await fetch('unicorn.png');
const buffer = await response.arrayBuffer();
isPng(new Uint8Array(buffer));
//=> true
})();6.3 如何获取图片的尺寸
图片的尺寸、位深度、色彩类型和压缩算法都会存储在文件的二进制数据中,我们继续以阿宝哥的头像(abao.png)为例,来了解一下实际的情况:
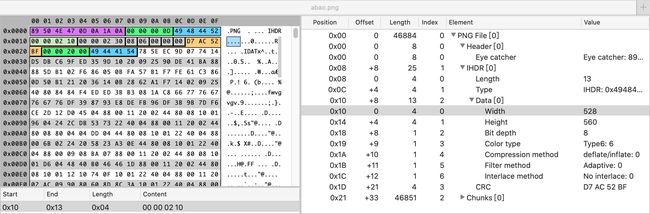
528(十进制) => 0x0210(十六进制)560(十进制)=> 0x0230(十六进制)
因此如果想要获取图片的尺寸,我们就需要依据不同的图片格式对图片二进制数据进行解析。幸运的是,我们不需要自己实现该功能,image-size 这个 Node.js 库已经帮我们实现了获取主流图片类型文件尺寸的功能,使用示例如下:
同步方式
var sizeOf = require('image-size');
var dimensions = sizeOf('images/abao.png');
console.log(dimensions.width, dimensions.height);异步方式
var sizeOf = require('image-size');
sizeOf('images/abao.png', function (err, dimensions) {
console.log(dimensions.width, dimensions.height);
});image-size 这个库功能还是蛮强大的,除了支持 PNG 格式之外,还支持 BMP、GIF、ICO、JPEG、SVG 和 WebP 等格式。
6.4 如何解码 PNG 图片中的像素数据
相信小伙们平时也听过图片解码、音视频解码。解码 PNG 图片就是把一张图片从二进制数据转换成包含像素数据的 ImageData。前面我们已经讲过,可以利用 CanvasRenderingContext2D 提供的 getImageData() 方法来获取图片像素数据。
那么 getImageData() 方法内部是如何处理的呢?下面我们来简单介绍一下大致流程,这里我们以一张 2px * 2px 的图片为例,下图是放大展示的效果:
![[1.3万字] 玩转前端二进制_第26张图片](http://img.e-com-net.com/image/info9/ddc8872bfecc4cd3b1c6cf335c9b0286.jpg "pixels-large.png")
(图片来源:https://vivaxyblog.github.io/...)
同样,我们先使用 Synalyze It! Pro 十六进制编辑器打开上面的 2px * 2px 的图片:
![[1.3万字] 玩转前端二进制_第27张图片](http://img.e-com-net.com/image/info9/23d8f1ac03cb408bac053371718860ef.jpg)
PNG 图片的像素数据是保存在 IDAT 块中,除了 IDAT 块之外,还包含其他的数据块,完整的数据块如下所示:
![[1.3万字] 玩转前端二进制_第28张图片](http://img.e-com-net.com/image/info9/8f4e31c19c0344b5aaa3b052697b27a3.jpg)
(图片来源:https://dev.gameres.com/Progr...)
在解析像素数据之前,我们先了解像素数据是如何编码的。每行像素都会先经过过滤函数处理,每行像素的过滤函数可以不同。然后所有行的像素数据会经过 deflate 压缩算法压缩。这里阿宝哥使用 pako 这个库进行解码操作:
const pako = require("pako");
const compressed = new Uint8Array([120, 156, 99, 16, 96, 216, 0, 0, 0, 228, 0, 193]);
try {
const result = pako.inflate(compressed);
console.dir(result);
} catch (err) {
console.log(err);
}在以上代码中,通过调用 pako.inflate() 方法执行解压操作,最终的解压后的像素数据如下:
Uint8Array [ 0, 16, 0, 176 ]获取解压的像素数据之后,还要解码扫描线,然后根据色板中的索引,来还原出图片的像素信息。这里阿宝哥就不详细展开了,感兴趣的小伙伴可以阅读 一步一步解码 PNG 图片 这篇文章。
6.5 如何实现大文件分片上传
File 对象是特殊类型的 Blob,且可以用在任意的 Blob 类型的上下文中。所以针对大文件传输的场景,我们可以使用 slice 方法对大文件进行切割,然后分片进行上传,具体示例如下:
const file = new File(["a".repeat(1000000)], "test.txt");
const chunkSize = 40000;
const url = "https://httpbin.org/post";
async function chunkedUpload() {
for (let start = 0; start < file.size; start += chunkSize) {
const chunk = file.slice(start, start + chunkSize + 1);
const fd = new FormData();
fd.append("data", chunk);
await fetch(url, { method: "post", body: fd }).then((res) =>
res.text()
);
}
}6.6 如何实现文件下载
在一些场景中,我们会通过 Canvas 进行图片编辑或使用 jsPDF、sheetjs 等一些第三方库进行文档处理,当文件文件处理完成后,我们需要把文件下载并保存到本地。针对这些场景,我们可以使用纯前端的方案实现文件下载。
“Talk is cheap”,阿宝哥来举一个简单的 Blob 文件下载的示例:
index.html
Blob 文件下载示例
index.js
const download = (fileName, blob) => {
const link = document.createElement("a");
link.href = URL.createObjectURL(blob);
link.download = fileName;
link.click();
link.remove();
URL.revokeObjectURL(link.href);
};
const downloadBtn = document.querySelector("#downloadBtn");
downloadBtn.addEventListener("click", (event) => {
const fileName = "blob.txt";
const myBlob = new Blob(["一文彻底掌握 Blob Web API"], { type: "text/plain" });
download(fileName, myBlob);
});在示例中,我们通过调用 Blob 的构造函数来创建类型为 "text/plain" 的 Blob 对象,然后通过动态创建 a 标签来实现文件的下载。在实际项目开发过程中,我们可以使用成熟的开源库,比如 FileSaver.js 来实现文件保存功能。