读书笔记-OpenCL编程指南 HelloWorld
main函数会实现或调用一组函数,完成以下操作:

可以和OpenCL入门二:OpenCL基础概念中的代码进行对比
OpenCL内核

__kernel void vector_add(global const float *a, global const float *b, global float *result)
{
int gid = get_global_id(0);
result[gid] = a[gid] + b[gid];
}
————————————————
版权声明:本文为CSDN博主「肥叔菌」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/asmartkiller/article/details/86611145
主函数





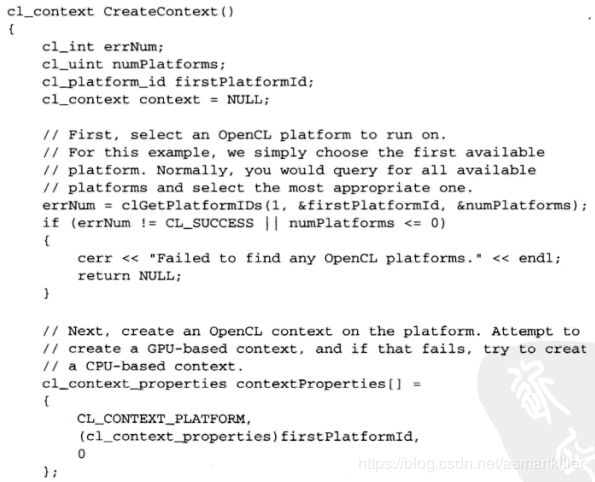
选择OpenCL平台并创建一个上下文

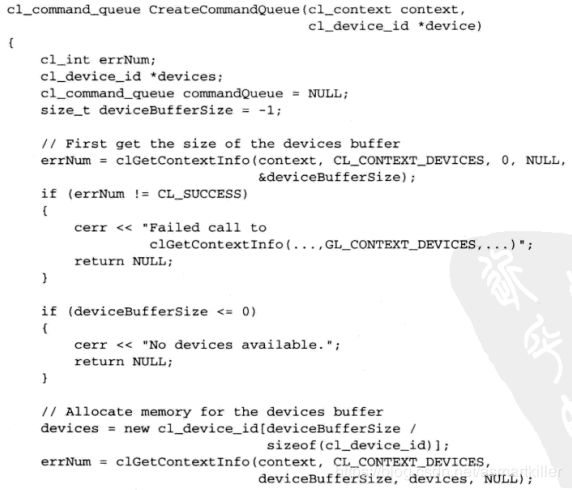
选择设备并创建命令队列

创建和构建程序对象

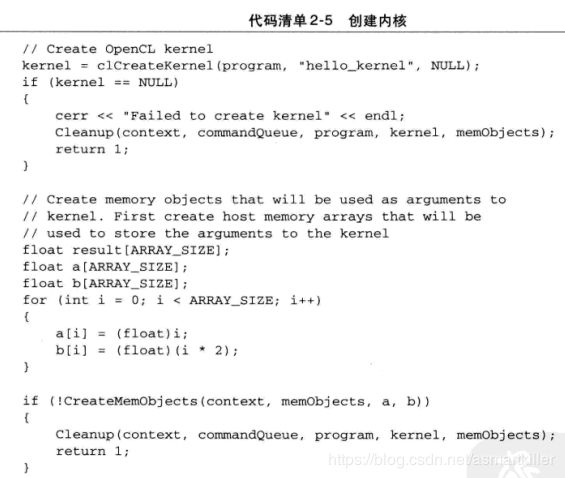
执行内核


cl_context context = 0;
cl_command_queue commandQueue = 0;
cl_program program = 0;
cl_device_id device = 0;
cl_kernel kernel = 0;
cl_mem memObjects[3] = { 0, 0, 0};
cl_int errNum;
// 创建OpenCL上下文
context = CreateContext(&device);
//获得OpenCL设备,并创建命令队列
commandQueue = CreateCommandQueue(context, device);
// 创建OpenCL程序
program = CreateProgram(context, device, "device.cl");
// 创建OpenCL内核
kernel = clCreateKernel(program, "vector_add", NULL);
// 创建OpenCL内存对象
float result[ARRAY_SIZE];
float a[ARRAY_SIZE];
float b[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++)
{
a[i] = (float)i;
b[i] = (float)(i * 2);
}
if (!CreateMemObjects(context, memObjects, a, b))
{
return 1;
}
// 设置内核参数
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
if (errNum != CL_SUCCESS)
{
return 1;
}
// 执行内核
size_t gloabalWorkSize = ARRAY_SIZE;
size_t localWorkSize = 1;
std::cout << "GPU 运行开始:" << time_stamp() << std::endl;
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL, &gloabalWorkSize, &localWorkSize, 0, NULL, NULL);
std::cout << "GPU 运行结束:" << time_stamp() << std::endl;
//计算结果拷贝回主机
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE, 0, sizeof(float) * ARRAY_SIZE, result, 0, NULL, NULL);
for (int i = 0; i < ARRAY_SIZE; i++)
{
printf("i = %d:%f\n",i,result[i]);
}
————————————————
版权声明:本文为CSDN博主「肥叔菌」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/asmartkiller/article/details/86611145
检查OpenCL中的错误
![]()


