【Linux基础】常用高级命令
引入
我在前两篇博客中介绍了基本的常用命令,这篇就来讨论一下常用的高级命令
文件相关命令
| 序号 | 命令 | 功能 |
|---|---|---|
| 1 | dd | 拷贝文件 |
| 2 | df | 查看磁盘使用情况 |
| 3 | du | 查看文件或目录所占用的磁盘空间的大小 |
| 4 | fdisk | 磁盘分区工具 |
| 5 | find | 文件搜索 |
| 6 | locate | 查找文件 |
| 7 | ln | 创建连接 |
| 8 | tar | 解压缩文件 |
| 9 | awk | 行级文件分析工具 |
1.dd(Disk Dump) 复制文件并对原文件的内容进行转换和格式化处理
参数
- if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file >
- of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >
- count=blocks:只拷贝输入的blocks块
- bs=bytes:同时设置读入/输出的块大小为bytes个字节
实例:

2.df (Disk Free )查看磁盘使用情况
参数:
- -a 全部文件系统的列表
- -h 方便阅读方式显示
- -i 显示node信息
- -l 只显示本地文件系统
- -T 文件系统类型
实例

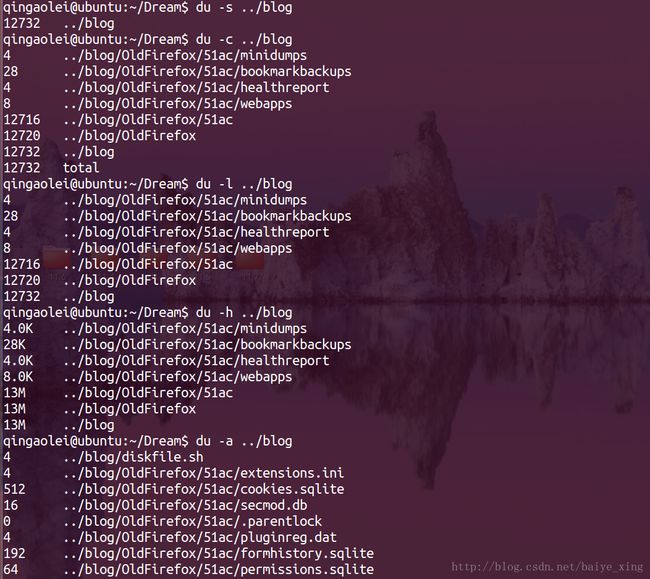
3.du ( Disk Usage)查看文件或目录所占用的磁盘空间的大小
| 参数 | 描述 |
|---|---|
| -a | 显示目录占用的磁盘空间大小,还要显示其下目录和文件占用磁盘空间的大小 |
| -s | 显示目录占用的磁盘空间大小,不要显示其下子目录和文件占用的磁盘空间大小 |
| -c | 显示几个目录或文件占用的磁盘空间大小,还要统计它们的总和 |
| -l | 统计硬链接占用磁盘空间的大小 |
| -h | 以人类可读的方式显示 |
实例:
4.fdisk:(manipulate disk partition table)磁盘分区工具
- -l 查看硬盘及分区信息

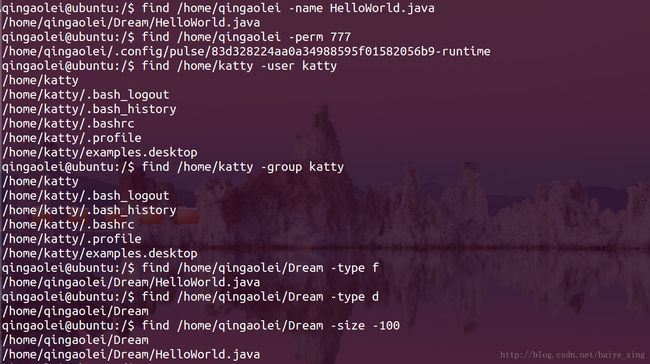
5.find:文件搜索
| 参数 | 描述 |
|---|---|
| -name | 按照文件名查找文件。 |
| -perm | 按照文件权限来查找文件。 |
| -user | 按照文件属主来查找文件。 |
| -group | 按照文件所属的组来查找文件。 |
| -mtime -n +n | -n表示文件更改时间距现在n天以内,+ n表示文件更改时间距现在n天以前 |
| -type | 查找某一类型的文件 |
| -size -n | 查找小于n块的文件 |
实例:

6.locate:查找文件
-i 查找时不区分大小写
locate 查找文件比find快,因为locate查找的是Linux文件数据库的索引值

7.ln (link):创建连接
(1)参数
- -s 创建软连接,
- -v 显示详细的处理过程
(2)软连接
- 以路径的形式存在。类似于Windows操作系统中的快捷方式
- 可以 跨文件系统 ,硬链接不可以
- 可以对一个不存在的文件名进行链接
- 可以对目录进行链接
(3)硬链接
- 以文件副本的形式存在,但同步更新,不占用实际空间
- 不允许给目录创建硬链接
- 只有在同一个文件系统中才能创建
- 共享i节点,i节点引用计数递增,删除任意一个文件不会对其他文件造成影响,因为只有引用计数为零时才真正删除文件
实例

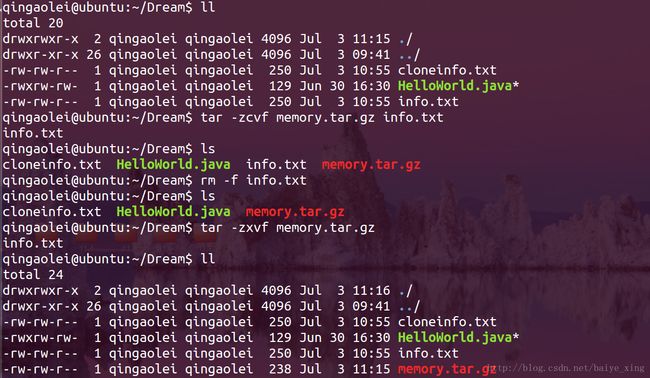
8.tar( Tape ARchive):解压缩文件
| 参数 | 描述 |
|---|---|
| -c | 产生tar打包文件 |
| -x | 产生的解压缩文件 |
| -v | 显示详细信息 |
| -f | 指定压缩后的文件名 |
| -z | 打包同时压缩 |
实例:
9.awk: 行级文件分析工具
| 参数 | 描述 |
|---|---|
| $0 | 表示整个当前行 |
| $1 | 每行第一个字段 |
| NF | 字段数量变量 |
| NR | 每行的记录号,多文件记录递增 |
| FNR | 与NR类似,不过多文件记录不递增,每个文件都从1开始 |
| \t | 制表符 |
| \n | 换行符 |
| FS | BEGIN时定义分隔符 |
| RS | 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入) |
| ~ | 匹配,与==相比不是精确比较 |
| !~ | 不匹配,不精确比较 |
| == | 等于,必须全部相等,精确比较 |
| != | 不等于,精确比较 |
| && | 逻辑与 |
| + | 匹配时表示1个或1个以上 |
| /[ 0-9 ][ 0-9 ]+/ | 两个或两个以上数字 |
| / [0-9 ][ 0-9 ] */ | 一个或一个以上数字 |
| FILENAME | 文件名 |
| OFS | 输出字段分隔符, 默认也是空格,可以改为制表符等 |
| ORS | 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕 |
| -F’[:#/]’ | 定义三个分隔符 |
实例:

权限相关命令
sudo(super user do)使用root身份执行命令
当前用户切换到root(或其它指定切换到的用户),然后以root(或其它指定的切换到的用户)身份执行命令,执行完成后,直接退回到当前用户
sudo命令的工作流程如下:
- 当用户执行sudo命令时,系统会检查/etc/sudoers文件,判断该用户是否有执行sudo命令的权限。
- 如果用户具有可执行sudo的权限,系统会提示用户“输入用户自己的密码”来确认。
- 如果密码输入成功,则开始sudo使用指定的用户执行指定的命令。
实例

网络相关命令
1.iptables
(1)定义
iptables只是一个工作在用户空间的一个工具而已,用户可以使用这个工具的一个命令来跟工作在内核空间中的netfiter组件打交道的.iptables防火墙就是如此。
(2)简单命令
重启iptables服务
/etc/init.d/iptables restart
service iptables restart设置开机自动启动:chkconfig iptables on
(3)iptables的结构
iptables常用的三个表
- filter表:过滤数据包的,IPTABLES几乎所有的数据包过滤都在此表中实现的,
- nat表:网络地址转换的(NAT),在iptables中可以做SNAT(源地址转换),DNAT(目标地址转换),PANT(即跟SNAT差不多,不一样的是SNAT的源地址是固定的,而PNAT的源地址是不固定的)
- mangle表:修改数据包头部信息的
iptables常用的五个链
- PREROUTING:路由前
- INPUT:数据包流入口
- FORWARD:转发管卡
- OUTPUT:数据包出口
- POSTROUTING:路由后
(4)iptables的4个状态
NEW:新发出请求;连接追踪模板中不存在此连接的相关信息条目,将其识别为第一次发出的请求;
ESTABLISHED:NEW状态之后,连接追踪模板中为其建立的条目失效之前期间内所进行的通信状态;
RELATED:相关联的连接;如ftp协议中的数据连接与命令连接之间的关系;
INVALID:无效的连接;
UNTRACKED:未进行追踪的连接;
(4)参数
| 参数 | 描述 |
|---|---|
| -N | 新增一条自定义链 |
| -t | 指定使用哪个表,默认使用filter表 |
| -A | 添加一条新规则,追加,默认在最下面 |
| -I | 插入一条新规则 ,加一数字表示插入到哪行,默认在最上面 |
| -D | 删除一条新规则 ,加一数字表示删除哪行 |
| -R | 替换一条新规则 ,加一数字表示替换哪行 |
| -F | 清空链中的所有规则 |
| -N | 新建一个链 |
| -X | 删除一个自定义链,删除之前要保证次链是空的,而且没有被引用 |
| -E | 重命名链 |
| -L | 查看规则 |
| -s | 源地址 |
| -d | 目标地址 |
| -p | 协议{tcp |
| -i | 从哪个网络接口进入 |
| -o | 从哪个网络接口出去 |
2.tcpdump(dump the traffic on a network)网络抓包工具
| 参数 | 描述 |
|---|---|
| -a | 将网络地址和广播地址转变成名字; |
| -c | 指定抓包数量 |
| -d | 将匹配信息包的代码以人们能够理解的汇编格式给出; |
| -e | 在输出行打印出数据链路层的头部信息; |
| -f | 将外部的Internet地址以数字的形式打印出来; |
| -F | 从指定的文件中读取表达式,忽略其它的表达式; |
| -i | 指定监听的网络接口; |
| -l | 使标准输出变为缓冲行形式 |
| -n | 不把网络地址转换成名字; |
| -s | 指定抓包大小(快照长度) |
| -t | 在输出的每一行不打印时间戳; |
| -v | 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息; |
| -vv | 输出详细的报文信息; |
| -r | 从指定的文件中读取包(这些包一般通过-w选项产生); |
| -w | 直接将包写入文件中,并不分析和打印出来; |
| -T | 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc 和snmp(简单网络管理协议;) |
执行命令:tcpdump -n -i eth0 port 80 输出结果如下
常用参数组合
(1)tcpdump -nvvv -i any -c 3 port 22 and port 8080:过滤源和目的端口
tcpdump 只输出端口号是 22 和 8080 的数据包。这点在分析网络问题的时候很有用,因为可以通过这个方法来关注某一个特定会话(session)的数据包。
(2) tcpdump -nvvv -i any -c 3 host 10.0.3.1 :查找特定主机的流量
tcpdump 只会显示源 IP 或者目的 IP 地址是 10.0.3.1 的数据包。
(3) tcpdump -nvvv -i any -c 20 ‘port 80 or port 443’:查找两个端口号的流量
使用 or 操作符去截获发送和接收端口为 80 或 443 的数据流。这在 Web 服务器上特别有用,因为服务器通常有两个开放的端口,端口号 80 表示 http 连接,443 表示 https。
(4)tcpdump -nvvv -i any -c 2 icmp :获取ICMP 数据包
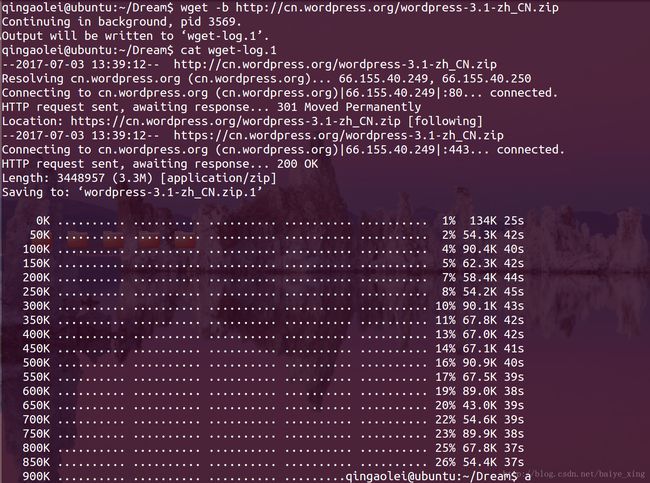
3.wget:从指定的URL下载文件
参数
- -b, (background) 启动后转入后台执行
- -c, (continue ) 接着下载上次的任务(断点续传)
- -o, (output) 下载并以不同的文件名保存
进程相关命令
1.top:性能分析工具
| 参数 | 描述 |
|---|---|
| -c | 显示完整的命令 |
| -i<时间> | 设置间隔时间 |
| -u<用户名> | 指定用户名 |
| -p<进程号> | 指定进程 |
| -n<次数> | 循环显示的次数 |
交互式命令的操作
| 操作 | 描述 |
|---|---|
| d | 指定每两次屏幕信息刷新之间的时间间隔 |
| c | 切换显示命令名称和完整命令行 |
| h | 显示帮助画面,给出一些简短的命令总结说明 |
| k | 终止一个进程。 |
| i | 忽略闲置和僵死进程。这是一个开关式命令。 |
| q | 退出程序 |
| r | 重新安排一个进程的优先级别 |
| S | 切换到累计模式 |
| s | 改变两次刷新之间的延迟时间(单位为s),默认值是5 s |
| f或者F | 从当前显示中添加或者删除项目 |
| o | 改变显示项目的顺序 |
| l | 切换显示平均负载和启动时间信息 |
| m | 切换显示内存信息 |
| t | 切换显示进程和CPU状态信息 |
| u | 仅显示指定用户 |
| M | 根据驻留内存大小进行排序 |
| P | 根据CPU使用百分比大小进行排序 |
| T | 根据时间/累计时间进行排序 |
| W | 将当前设置写入~/.toprc文件中 |
| 1 | 查看每个cpu的负载情况 |
| 2 | 查看NUMA-Nodes的状态,(NUMA:非统一内存访问架构) |
实例

分析:
top - 15:16:13 up 4:32, 2 users, load average: 0.00, 0.03, 0.06
top - 15:21:31 up 4:37, 2 users, load average: 0.08, 0.03, 0.05
//15:21:31表示当前时间;up 4:37表示系统运行时间为4小时37分;2 user表示当前登录用户数为2
//load average: 0.08, 0.03, 0.05表示系统负载,即任务队列的平均长度。
//三个数值分别表示1分钟、5分钟、15分钟前到现在的平均值
Tasks: 191 total, 1 running, 190 sleeping, 0 stopped, 0 zombie
//表示系统现在共有191个进程,其中处于运行中(running)的有1个,190个在休眠(sleeping),
//stoped状态的有0个,僵尸状态(zombie)的有0个。
%Cpu(s): 1.0 us, 0.3 sy, 0.0 ni, 91.0 id, 7.5 wa, 0.0 hi, 0.2 si, 0.0 st
//1.0 us 表示用户空间占用CPU的百分比;0.3 sy 表示内核空间占用CPU的百分比。
//0.0 ni 表示改变过优先级的进程占用CPU的百分比;91.0 id 表示空闲CPU百分比
//7.5 wa 表示IO等待占用CPU的百分比;0.0 hi 表示硬中断(Hardware IRQ)占用CPU的百分比
//0.0 si 表示软中断(Software Interrupts)占用CPU的百分比;0.0st表示虚拟机占用CPU百分比
KiB Mem: 1025548 total, 893692 used, 131856 free, 16852 buffers
//内存状态
//1025548 total表示物理内存总量(1GB);;893692 used表示使用中的内存总量(0.89GB)
//131856 free 表示空闲内存总量(131M);16852 buffers 表示缓存的内存量 (16M)
KiB Swap: 3068924 total, 31216 used, 3037708 free. 291748 cached Mem
//swap交换分区
//3068924 total 表示交换区总量(3GB);31216 used — 使用的交换区总量(31M)
//3037708 free 表示空闲交换区总量(3GB);291748 cached Mem表示缓冲的交换区总量(291MB)
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
//PID 表示进程id;
//USER 表示进程所有者的用户名;
//PR 表示优先级
//NI 表示nice值。负值表示高优先级,正值表示低优先级
//VIRT 表示进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
//RES 表示进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
//SHR 表示共享内存大小,单位kb
//S 表示进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
//%CPU 表示上次更新到现在的CPU时间占用百分比
//%MEM 表示进程使用的物理内存百分比
//TIME+ 表示进程使用的CPU时间总计,单位1/100秒
//COMMAND 表示命令名/命令行注:因为top命令是实时的,用Ctrl+S可以暂停,Ctrl+Q继续
还有一个iotop命令,可以直接查看io的状况

2.ulimit :限制 shell 启动进程所占用的资源
| 参数 | 描述 |
|---|---|
| -H | 设置硬资源限制,一旦设置不能增加。 |
| -S | 设置软资源限制,设置后可以增加,但是不能超过硬资源设置。 |
| -a | 显示当前所有的 limit 信息 |
| -c | 最大的 core 文件的大小, 以 blocks 为单位。 |
| -d | 进程最大的数据段的大小,以 Kbytes 为单位。 |
| -f | 进程可以创建文件的最大值,以 blocks 为单位。 |
| -l | 最大可加锁内存大小,以 Kbytes 为单位。 |
| -m | 最大内存大小,以 Kbytes 为单位。 |
| -n | 可以打开最大文件描述符的数量。 |
| -p | 管道缓冲区的大小,以 Kbytes 为单位。 |
| -s | 线程栈大小,以 Kbytes 为单位。 |
| -t | 最大的 CPU 占用时间,以秒为单位。 |
| -u | 用户最大可用的进程数。 |
| -v | 进程最大可用的虚拟内存,以 Kbytes 为单位。 |
实例

3.w :显示目前登入系统的用户信息
| 参数 | 描述 |
|---|---|
| -f | 开启或关闭显示用户从何处登入系统。 |
| -h | 不显示各栏位的标题信息列。 |
| -l | 使用详细格式列表,此为预设值。 |
| -s | 使用简洁格式列表,不显示用户登入时间,终端机阶段作业和程序所耗费的CPU时间。 |
| -u | 忽略执行程序的名称,以及该程序耗费CPU时间的信息。 |
| -V | 显示版本信息 |
实例:

计划任务命令
1.at :使任务定时运行一次
- at –d 或 atrm 删除队列中的任务
- at –l 或 atq 查看队列中的任务
注:ctrl+d保存任务退出

2.crontab:设置周期性被执行的指令
参数
- -e:编辑某个用户的crontab文件内容。如果不指定用户,则表示编辑当前用户的crontab文件。
- -l:显示某个用户的crontab文件内容,如果不指定用户,则表示显示当前用户的crontab文件内容。
- -r:删除某个用户的crontab文件,如果不指定用户,则默认删除当前用户的crontab文件。
计划命令的时间格式
分钟 小时 日 月 星期 命令
* * * * * *注:查看当前的周期性任务命令 :ps -el | grep crond
其他高级命令
1.管道 | 将一个命令的输出传送给另一个命令,作为另一个命令的输出
例: ll /etc | more
2.grep 将指定内容进行过滤后输出
例1:过滤文件名为init 的文件: ll /etc | grep init
例2:统计文件名为init 的文件个数: ll /etc | grep init | wc –l

3.输入输出重定向
输出重定向(>):把输出结果显示到某个文件
追加输出重定向(>>):把输出结果追加到某个文件最后
输入重定向(<):将输入的信息重定向
错误重定向(2<):将程序的错误信息放入文件中
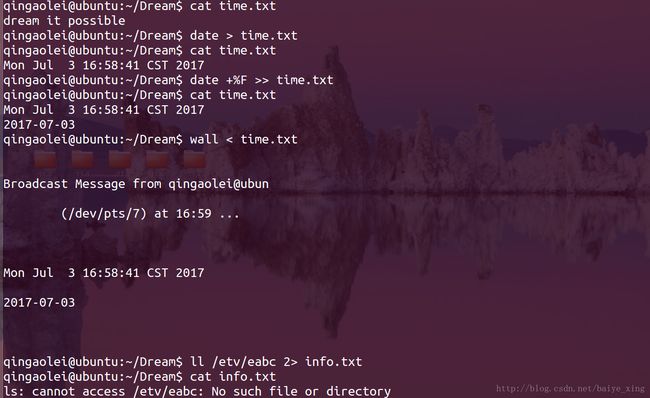
实例:
本人才疏学浅,若有错,请指出,谢谢!
如果你有更好的建议,可以留言我们一起讨论,共同进步!
衷心的感谢您能耐心的读完本篇博文!