TensorFlow的环境配置与安装(win10+GeForce GTX1060+CUDA 9.0+cuDNN7.3+tensorflow-gpu 1.12.0+python3.5.5)
记录一下安装win10+GeForce GTX1060+CUDA 9.0+cuDNN7.3+tensorflow-gpu 1.12.0+python3.5.5
之前已经安装过pycharm、Anaconda以及VS2013,因此,安装记录从此后开始
总体步骤大致如下:
1、确认自己电脑显卡型号是否支持CUDA(此处有坑)

此处有坑!不要管NVIDIA控制面板组件中显示的是CUDA9.2.148。
你下载的CUDA不一定需要匹配,尤其是CUDA9.2,最好使用CUDA9.0,我就在此坑摔的比较惨。
2、下载CUDA以及cuDNN,注意版本对应
①查看版本匹配:
https://www.tensorflow.org/install/source_windows
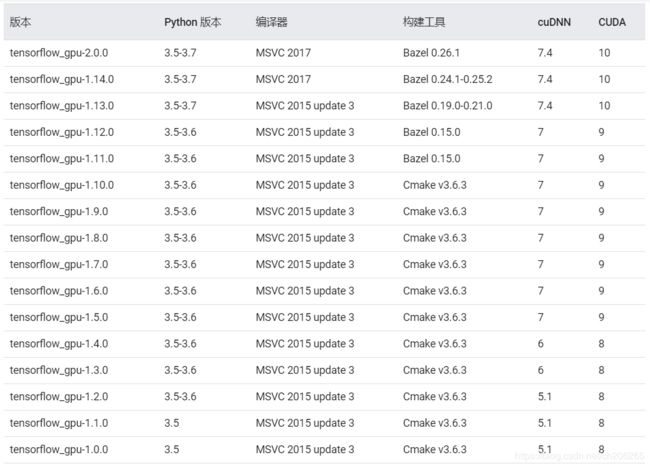
②下载CUDA:
https://developer.nvidia.com/cuda-toolkit-archive

官网上下载的CUDA 9.0有好几个版本,其中主要是cuda_9.0.176_win10.exe,其他的四个是补丁。
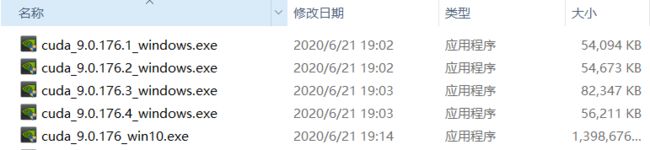
③下载cuDNN:
https://developer.nvidia.com/cudnn
https://developer.nvidia.com/rdp/cudnn-archive

下载cuDNN需要注册一个NVIDIA的账号。
3、安装CUDA和cuDNN,并设置环境变量(重要)
①CUDA安装
我是按照默认路径安装的,没有修改。此外,使用自定义安装,但是几乎全选了,除了一个当前版本已经是最新版本的组件没有勾选。
切记CUDA的安装路径,因为安装cuDNN以及设置环境变量时需要。


②cuDNN9.0安装
cuDNN是一个压缩包,解压后的内容如下
 :
:
全选并复制所有内容,粘贴到CUDA的安装路径下,默认路径是:

③设置环境变量(重要)
这部分我主要参考的是:https://blog.csdn.net/qilixuening/article/details/77503631
计算机上点右键,打开属性->高级系统设置->环境变量,可以看到系统中多了两个环境变量,接下来,分别是:
CUDA_PATH和CUDA_PATH_V8_0。
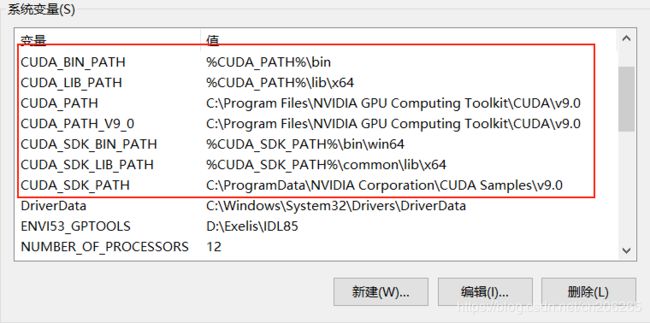
还要在系统变量中新建以下几个环境变量:
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64
如下图所示:
然后在系统变量中找到 PATH,点击编辑并添加:
%CUDA_LIB_PATH%
%CUDA_BIN_PATH%
%CUDA_SDK_LIB_PATH%
%CUDA_SDK_BIN_PATH%
再添加如下4条(默认安装路径):
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\x64;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin;
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\common\lib\x64;
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\bin\win64;

如果你选用了自定义路径,上述这些默认路径都应该相应替换为你的自定义路径。
④查验是否安装成功
重启计算机(必须),然后在Anaconda prompt中输入nvcc -V。(注意,V是大写)返回以下信息则安装成功。

4、创建tensorflow-gpu环境并激活
(此部分可参考的教程比较多,可自行搜索)
①conda create --name tensorflow-gpu python=3.5
在Anaconda Prompt 中输入conda create --name tensorflow-gpu python=3.5,创建名为tensorflow-gpu的环境(名字可以自己改,不一定都叫tensorflow-gpu)。
②activate tensorflow-gpu
按照提示,接下来activate tensorflow-gpu,进入到新创建的环境,退出时使用deactivate
③conda info --envs
最后,conda info --envs,查看创建的所有环境,确保tensorflow-gpu环境创建成功
5、安装tensorflow-gpu
使用activate进入到tensorflow-gpu环境,使用以下命令进行安装:
pip install --ignore-installed --upgrade tensorflow-gpu==1.12.0
如果安装缓慢请参考其他教程换源。
6、查验tensorflow是否安装成功
这部分主要参考:https://zhuanlan.zhihu.com/p/58607298
①activate到tensorflow-gpu环境中然后输入python进入到python中,输入一下代码:
import tensorflow as tf
hello = tf.constant('Hello , Tensorflow! ')
sess = tf.Session()
print(sess.run(hello))预期输出:
b'Hello , Tensorflow! '中间会有一大堆关于 GPU的Log信息,例如:
2020-06-22 09:47:38.562662: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2020-06-22 09:47:39.111893: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties:
name: GeForce GTX 1060 major: 6 minor: 1 memoryClockRate(GHz): 1.6705
pciBusID: 0000:01:00.0
totalMemory: 6.00GiB freeMemory: 4.97GiB
2020-06-22 09:47:39.134322: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
2020-06-22 09:47:41.602201: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-06-22 09:47:41.612905: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
2020-06-22 09:47:41.618302: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
2020-06-22 09:47:41.631165: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 4722 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060, pci bus id: 0000:01:00.0, compute capability: 6.1)如果只是平时做小规模的训练,可以在Python Code前设置log等级:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'如果想彻底解决,请参考:https://blog.csdn.net/zhaohaibo_/article/details/80573676
②查看TensorFlow和Keras版本:
import tensorflow as tf
from tensorflow.keras import layers
print(tf.VERSION)
print(tf.keras.__version__)输出:
1.12.0
2.1.6-tf7、在pycharm中调用tensorflow,
并查验tensorflow是否能够调用gpu做运算
①在PyCharm中新建Project
②进入中Existing interpreter右侧浏览目录
③在Interpreter右侧浏览目录中找到自己安装Anaconda的路径,在其中的envs文件夹中,有上文中自己创建的tensorflow-gpu环境,选中其中python.exe即可。


④在pycharm中查验tensorflow是否能够调用gpu做运算查验tensorflow是否能够调用gpu做运算:
创建一个.py文件,用TensorFlow,来比较一下CPU和GPU的时间差异:
例子来源:https://zhuanlan.zhihu.com/p/58607298
import tensorflow as tf
import timeit
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# See https://www.tensorflow.org/tutorials/using_gpu#allowing_gpu_memory_growth
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.device('/cpu:0'):
random_image_cpu = tf.random_normal((100, 1000, 100, 3))
net_cpu = tf.layers.conv2d(random_image_cpu, 32, 7)
net_cpu = tf.reduce_sum(net_cpu)
with tf.device('/gpu:0'):
random_image_gpu = tf.random_normal((100, 1000, 100, 3))
net_gpu = tf.layers.conv2d(random_image_gpu, 32, 7)
net_gpu = tf.reduce_sum(net_gpu)
sess = tf.Session(config=config)
# Test execution once to detect errors early.
try:
sess.run(tf.global_variables_initializer())
except tf.errors.InvalidArgumentError:
print(
'如果出了这个Error表示GPU配置不成功!\n\n')
raise
def cpu():
sess.run(net_cpu)
def gpu():
sess.run(net_gpu)
# Runs the op several times.
print('Time (s) to convolve 32x7x7x3 filter over random 100x1000x100x3 images '
'(batch x height x width x channel). Sum of ten runs.')
print('CPU (s):')
cpu_time = timeit.timeit('cpu()', number=10, setup="from __main__ import cpu")
print(cpu_time)
print('GPU (s):')
gpu_time = timeit.timeit('gpu()', number=10, setup="from __main__ import gpu")
print(gpu_time)
print('GPU speedup over CPU: {}x'.format(int(cpu_time / gpu_time)))
sess.close()输出:
Time (s) to convolve 32x7x7x3 filter over random 100x1000x100x3 images (batch x height x width x channel). Sum of ten runs.
CPU (s):
25.24234085335886
GPU (s):
1.5711942943447745
GPU speedup over CPU: 16x输出表明:这个任务GPU和6个i7的CPU相比快了16倍!
安装踩坑总结:
其中最大的坑就是CUDA、cuDNN、tensorflow-gpu以及python版本之间的匹配了。有时候明明按照官方的版本匹配列表安装,也是不行。
安装之后如果出现“ImportError: DLL load failed: 找不到指定的模块”错误,一般问题都是出在了版本不匹配上。
最需要注意的是CUDA9.2 。最初在NVIDIA控制面板,显示我的显卡支持CUDA 9.2.148,因此我按照推荐列表,选择tensorflow-gpu1.12.0+cuDNN 7.5.0.56+CUDA 9.2.148 +python3.5.5。注意此处有坑!!无论如何都是安装不成功,一直都是“ImportError: DLL load failed: 找不到指定的模块”这个错误。
后来看到有网友说,推荐列表中只给出CUDA版本号 的第一位,一般使用的都是CUDA9.0或者CUDA10.0,后面版本可能会出现不兼容。
于是,卸载CUDA9.2(不要管NVIDIA控制面板组件中显示的是CUDA9.2.148,不一定需要匹配),重新在推荐列表中寻找匹配的cuDNN以及tensorflow-gpu版本,最后成功安装。
20200706更新:
如果要安装keras,那么其版本也是要和tensorflow版本相对应的,参考链接如下:
https://www.cnblogs.com/carle-09/p/11661261.html
