Style2paints V3论文解读(下):设计思想深入分析
版权声明: 未经同意,禁止转载。(更新时间:2020-06-23)
接上一篇,继续解读Two-stage Sketch Colorization论文 。(返回该论文笔记首页)
目录
11. 深入理解“两阶段上色方法”的设计思想{*}
11.1 从“算法设计”的角度分析
11.2 从“概率论”的角度分析
11.3 从“如何训练更深层GAN”的角度分析
11. 深入理解“两阶段上色方法”的设计思想{*}
到目前为止,仍然有一个问题没想明白,即:为什么“两阶段上色方法”的上色效果优于“一阶段上色方法”?(其本质原理是什么?)
深度神经网络属于“黑盒模型”,至今仍难以清楚地解释其内部运行机制。本解读报告试图从以下三个角度分析“两阶段(Two-stage)线稿上色方法”的设计思想,希望能起到抛砖引玉的作用{*}。
(注:笔者未进行过本文相关GAN的训练测试,以下结论仅供参考。)
11.1 从“算法设计”的角度分析
在设计编译器算法时,要设计一个直接能把“高级程序代码”转换为“汇编代码”的算法几乎是不可能的,因为二者的抽象层次差异太大了。为了解决这一问题,编译器的设计者们采用的解决思路为:将复杂的编译过程拆分为多个步骤,每个步骤完成一个难度相对较低的目标。(即:每个步骤负责把上一步骤输出语言的抽象层次降低一点。)且每个步骤相对独立,只考虑本步骤内的问题。[ref-1]
其分步转换过程如下图所示。经过词法分析、语法分析等多个步骤之后,完成从“高级程序代码”到 “汇编代码”的转换。其中的token流、语法树、中间代码均为“半成品”;虽然对最终用户不可见,但能起到显著降低算法设计难度的作用。
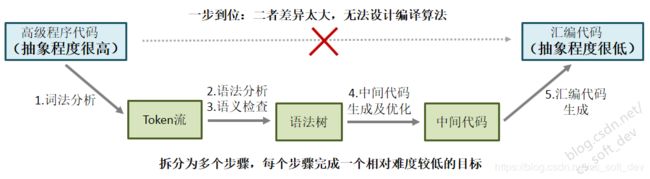 编译算法:拆分为多个步骤,每个步骤完成一个相对难度较低的目标
编译算法:拆分为多个步骤,每个步骤完成一个相对难度较低的目标
本文解决的是“线稿上色问题”,而“编译算法”解决的是“机器语言翻译问题”。“语言”可广义地定义为:思想的表达。从语言的广义定义来看,“绘画”也可视为一种“语言”。所以,“线稿上色问题”也可抽象地视为从“线稿+颜色提示”到“绘画”的“语言翻译问题”。故二者具有相通之处。(实际上,Pix2Pix [ref-2],一种用于解决Image-to-Image Translation问题的GAN,也可用于线稿上色。)
“两阶段上色方法”的设计思想与“编译算法”具有类似之处。通过把复杂的上色问题拆分为两个阶段,每个阶段拥有难度相对较低的目标,且每个阶段相对独立,以此来降低问题求解的难度。其过程示意图如下图所示。第一阶段输出的“草图”是一个“半成品”,其完成程度介于“线稿”与“最终绘画”之间,起到降低问题求解难度,以及连接前后两个阶段的“桥梁”作用。
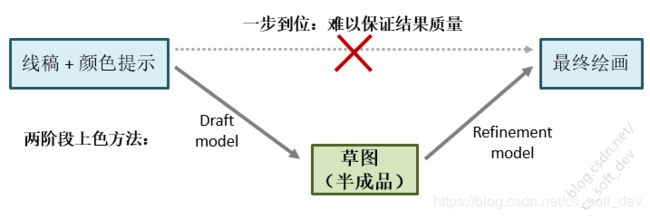 两阶段上色方法抽象示意图
两阶段上色方法抽象示意图
具体如何降低问题的求解难度呢?
(1)将一个复杂问题拆分为多个子问题后,单个子问题的难度显著低于原问题。训练网络的本质是学习一个从输入域到输出域的“变换函数”。如下图所示,可直观地感受到“从线稿到草图”的变换难度(子问题1),以及 “从草图到最终绘画”的变换难度(子问题2),要显著低于“从线稿到最终绘画”的变换难度(原始问题)。笔者推测,变换函数难度越低,GAN训练的成功率越高。
 两阶段上色方法:将高难度问题拆分为两个难度较低的子问题
两阶段上色方法:将高难度问题拆分为两个难度较低的子问题
(2)将一个复杂问题拆分为多个子问题后,各个子问题相对独立,更易于设计和调试算法。GAN可视为一种“黑盒算法”,训练GAN的过程就是在“设计和调试算法”。以下从GAN训练的角度进行分析。
训练网络最耗时的过程是调节超参数。对于“两阶段上色方法”,由于两个阶段GAN的训练过程是独立的,如果调参过程中输出结果不理想,只需重新训练其中一个存在问题的GAN即可。而对于一步到位的“一阶段上色方法”,尝试每个参数组合都需要重新训练整个GAN。关于独立训练子网络的优势,会在11.3节进行深入讨论。
11.2 从“概率论”的角度分析
Refinement模型的网络结构与“基于风格迁移的线稿上色”网络结构很类似。这实质上是把“基于颜色提示的线稿上色问题”转换为“基于风格迁移的上色问题”。(由于accurate hints是可选的,暂不考虑它,后面再另外进行讨论。)但转化为“风格迁移问题”能带来什么好处呢?
笔者尝试从“输入数据分布”的角度进行分析。研究表明[ref-3] [ref-4] [ref-5],深度神经网络的泛化能力是非常有限的。当测试阶段输入数据分布与训练阶段差异较大时,就难以保证神经网络输出高质量、稳定的结果。由于训练深度网络非常耗时、且训练数据集非常有限,训练阶段的输入数据分布往往只能覆盖一部分情况。由此可得出一个结论:测试阶段输入数据分布越广,其中包含的训练阶段未见过的情况越多,神经网络输出低质量结果的概率就越高。所以,要想让神经网络以较大的概率输出好的结果,需要尽量将测试阶段的输入数据分布控制在一个较小的范围内。
但对于“基于颜色提示的线稿上色问题”而言,测试阶段用户可能输入的draft hints几乎有无穷种排列组合:需要考虑不同坐标、个数、颜色,以及与特定线稿的对应关系(在特定线稿中,提示点是落衣服的口袋上还是领子上?)draft hints的数据分布范围太广了!故难以保证上色网络(指单阶段上色方法)输出的大部分结果具有较高的质量。或者说上色网络会出现较大的不稳定性:只要用户多增加一个颜色提示,上色结果就会突然变得很差(PaintsChainer常见问题)。
为了解决这一问题,本文采用了一个巧妙的思路:将“基于颜色提示的线稿上色问题”转换为“基于风格迁移的上色问题”。即:先借助草图模型,将用户输入的draft hints转换为“色彩参考图”(草图),然后再将“色彩参考图”输入Refinement模型(而draft hints没有输入Refinement模型)。这种转换能显著减小测试阶段Refinement模型输入数据的分布范围。举例来说,如下图所示,用户输入的draft hints有接近无数种可能的情况(记为N种情况),而草图模型可能生成草图的种数要远小于N。即:在草图中,对于一种颜色,用一个“面”来代替许多个“点”,使得可能出现的情况种数大幅下降。虽然无法定量证明,但可以直观地感受到这一点。
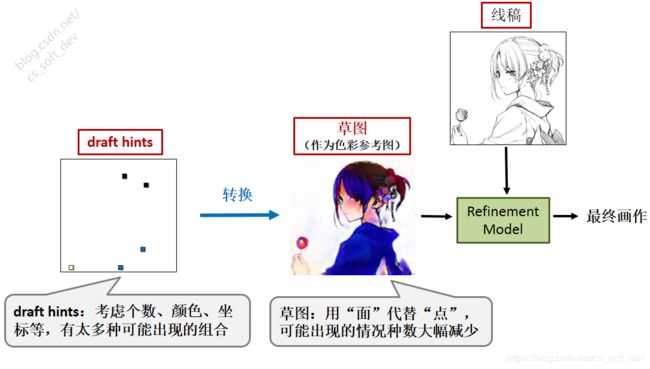 将用户输入的draft hints转换为“色彩参考图”(草图),能显著减少可能出现的情况种数
将用户输入的draft hints转换为“色彩参考图”(草图),能显著减少可能出现的情况种数
准确地说,转换之后的问题是“风格迁移上色问题”的特例:“色彩参考图”的语义分割结果与线稿是一致的。而“风格迁移上色问题”没有这个一致性要求。因此,本文方法的上色成功率要高于“风格迁移上色问题”。
而对于草图模型,虽然由于输入draft hints分布很广,导致难以保证输出草图是高质量的;但低质量的草图作为“色彩风格参考图”,已经足够了。
注:作者说明过,GitHub仓库中的代码版本,是论文的后续改进版本,主要供艺术家上色使用,与论文存在一定差异。因此,GitHub版本用户界面上显示的草图,实际上是经过一轮修正后的草图。最原始的草图由于色彩比较混乱,没有显示在用户界面上。
最后,再讨论一下accurate hints的问题:为什么accurate hints不存在输入数据分布太广,而导致refinement模型输出结果不稳定的问题?笔者推测可能的原因如下:(1)draft hints被训练为:使用稀疏的提示点实现“联想上色”功能,即能够根据上色经验,为不包含颜色提示的区域自动适配合适的颜色,因此其输入分布的范围对结果质量的影响较大。(2)而根据实验结果来看,accurate hints被训练为简单地从输入向输出的小范围区域直接拷贝颜色,没有“联想上色”功能(或者说联想的程度比较低),因此其输入的分布变化对结果质量的影响不大。
11.3 从“如何训练更深层GAN”的角度分析
深度学习的性能优于传统神经网络的重要原因之一,在于网络层数的增加 [ref-6]。层数越多,相当于复合函数的嵌套数越多,就能从数据中学习到更复杂的规律。从大量实验结果来看,一般网络层数越深,模型的性能就越好。但是,随之而来的一个问题是:层数越深的网络,单次训练耗时就越长,为网络调参就越辛苦。实验室的算力是有限的,人所能接受的最长等待时间也是有限的,当调参所耗的时间超出人的最大耐心之后,就无法再加深网络的层数了。(注意“生成问题”的调参要比“识别问题”更麻烦,由于需要人工评估输出结果的质量,调参需要更长时间,且无法自动化为GAN调参。)
那么有没有可能:既能加深网络的层数,同时调参时间又不至于过长?本文提出了一个解决方法:将深层网络拆分为两个层数更少的子网络,分别单独进行训练;测试阶段再将其连接起来。
如下图例子所示,训练同样层数的生成器。(1)“一阶段上色方法”每尝试一个参数组合,就需要等待4天才能评估结果。“两阶段上色方法”由于拆分成两个子网络单独训练,每次训练只需等2天就能评估结果。(2)当输出结果不理想时,前者需要重新训练整个网络(34层)。而后者只需重新训练其中一个存在问题的子网络(17层),另一个子网络不需要重新训练。很明显:两阶段上色方法能大幅减少用于调参的时间,并且有利于快速迭代。
所以,本文实际上找到了一种网络设计范式,使得在有限的算力(时间)下,能够对更深层的图像翻译GAN进行训练和调参。
 单次训练时长对比(图中的时间仅为示例值)
单次训练时长对比(图中的时间仅为示例值)
另外,如何让多个单独训练的网络协同工作,是下一代深度学习技术的研究方向之一。本文提出的“两阶段上色方法”可视为“多网络协同工作”的一个成功案例。
最后,感谢作者开源了相关代码与模型! (注意:作者禁止将代码用于商业和盈利目的,请尊重版权!)
参考文献:
{*}为本blog为了便于理解论文而补充介绍的内容,论文原文中没有出现。
[Zhang et al. 2017b] Richard Zhang, Jun-Yan Zhu, Phillip Isola, Xinyang Geng, Angela S Lin, Tianhe Yu, and Alexei A Efros. Real-time user-guided image colorization with learned deep priors. ACM Transactions on Graphics (TOG), 9(4), 2017.
[ref-1] 邹昌伟. C编译器剖析[M]. 清华大学出版社, 2016.
[ref-2] Isola P, Zhu J, Zhou T, et al. Image-to-Image Translation with Conditional Adversarial Networks[C]. Computer Vision and Pattern Recognition, 2017: 5967-5976.
[ref-3] Azulay A, Weiss Y. Why do deep convolutional networks generalize so poorly to small image transformations[J]. arXiv: Computer Vision and Pattern Recognition, 2018.
[ref-4] Rosenfeld A, Zemel R S, Tsotsos J K, et al. The Elephant in the Room.[J]. arXiv: Computer Vision and Pattern Recognition, 2018.
[ref-5] Recht B, Roelofs R, Schmidt L, et al. Do CIFAR-10 Classifiers Generalize to CIFAR-10?[J]. arXiv: Learning, 2018.
[ref-6] 周志华主题演讲:《关于深度学习的思考》,2018京东人工智能创新峰会
相关论文:
Style2paints V4相关论文简介:为数位板绘画作品添加3D光照效果