直击AAAI 2020,一文读完微软亚研6篇精选论文


来源 | 微软研究院AI头条 (ID: MSRAsia)
编者按:AAAI 2020中微软亚洲研究院有29篇论文入选,本文为大家介绍的6篇精选论文涵盖多维数据普适分析、文本风格迁移、句子改写、集成学习、实体链接任务等多个前沿主题,如果你不能去到大会现场,先来看看这些精选论文吧。

低资源文本风格迁移数据集
A Dataset for Low-Resource Stylized Sequence-to-Sequence Generation
论文链接:https://www.msra.cn/wp-content/uploads/2020/01/A-Dataset-for-Low-Resource-Stylized-Sequence-to-Sequence-Generation.pdf
风格迁移是最近自然语言生成领域一个非常火的主题,随着各项技术的提出,当前风格迁移算法已经可以较好地对文本序列进行“情感极性”和“文本规范性”的迁移。然而,在很多的现实应用中,我们需要同时进行 Sequence2Sequence 和风格迁移两个任务,例如在对话机器人之中,我们要求机器不但可以对用户所输入的对话给出相关的回复,还可以保证回复的规范性。

图1:不同风格对话样例
如图1所示,当用户咨询关于 Windows 的问题时,应该给出的回复是正规而礼貌的,而不是随意而不礼貌的。为了研究当前算法对此类问题的进展,我们提出了两个数据集—— Machine Translation Formality Corpus(MTFC) 和 Twitter Conversation Formality Corpus(TCFC),分别研究机器翻译风格迁移和对话风格迁移。
其中,MTFC 的任务定义为,给定一句中文口语,翻译的结果应该为正规的英文书面语。为了完成这个任务,MTFC 包含从 Opensubtitle 下载并清洗的约1400万中英互译口语语料,以及 GYAFC 数据集中所包含的5万英文非正规文本到正规文本的句对。而 TCFC 的任务定义为,给定一个推特(Twitter)风格的对话上文,给出正规而礼貌的对话回复。TCFC 提供170万的推特对话语料作为训练数据。
为了验证模型在这个任务的表现,MTFC 的验证集和测试集分别包含2865和1412个中文口语到英文书面语的句对(每一句中文口语提供4句英文书面语作为参照)。与之类似,TCFC 的验证集和测试集分别包含980和978个样例(每一个对话上文对应2个风格正规的对话回复)。该论文还验证了 Pivot Model、Teacher Student Model、Back-translation Model 三种基线模型的效果,其中 Back-translation 模型的表现最佳。
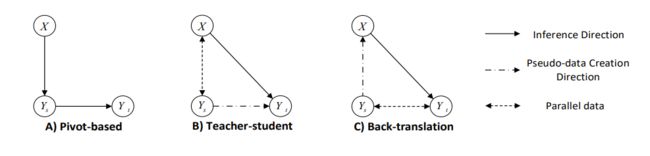
图2:三种基线模型的效果

通过预训练生成跨语种自然语言
Cross-Lingual Natural Language Generation via Pre-Training
论文链接: https://arxiv.org/abs/1909.10481
自然语言生成模型的训练需要大规模的训练数据,然而大多数的数据集都是以英语等资源丰富的语言提供的,限制了这些模型在其它语言上的应用。本篇论文提出了一种跨语言预训练方法,使得我们可以将文本生成任务的监督信号在不同语言间迁移,从而实现自然语言生成模型的跨语言的零样本或少样本学习。
在自然语言生成模型的跨域语言迁移中, 通常模型用英语进行训练,然后在其它语言上进行测试. 以文本摘要为例:

图3:文本摘要示例
本篇论文针对该问题的特点提出了预训练模型 XNLG。XNLG 是一个序列到序列的 Transformer 模型,它的预训练包括两个阶段:编码预训练、解码预训练,以及两个维度:单语预训练、跨语言预训练,共计4个预训练任务,如图4所示:
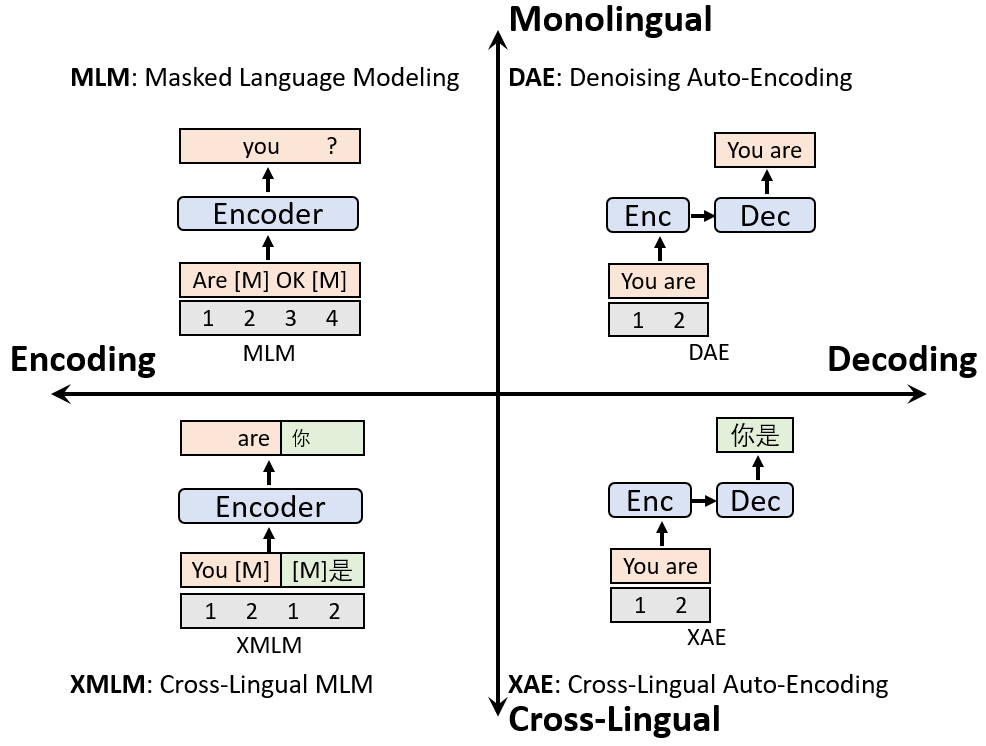
图4:XNLG 的预训练任务
我们在跨语言零样本问题生成/文本摘要任务(用英文训练,在其它语言上测试)上进行了实验,如图5所示。结果表明,XNLG 可以超越基于机器翻译的流水线模型。
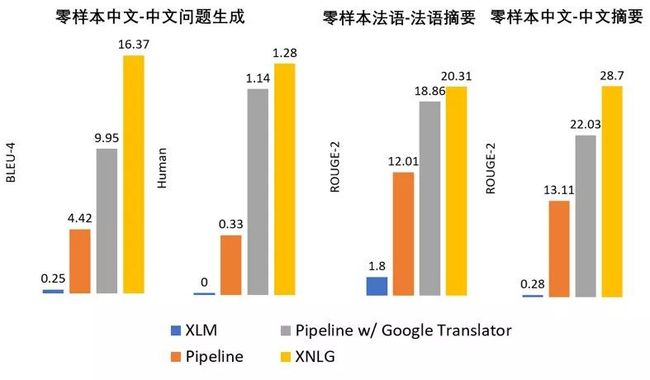
图5:跨语言零样本问题生成/文本摘要任务实验结果
此外,我们还实验了在有不同数目的目标语言训练数据的情况下,XNLG 的跨语言迁移效果的变化情况,如图6所示。结果表明,在各种数据量上 XNLG 都能将源语言的知识迁移到目标语言上并且提升目标语言上的效果,尤其是当目标语言训练数据量较少时。
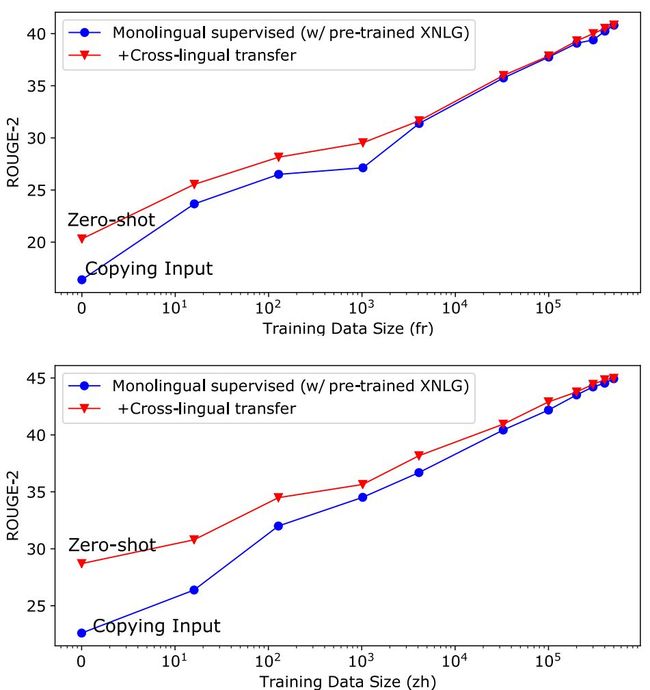
图6:跨语言迁移实验结果

基于事实感知的句子切分改写任务与置换不变训练
Fact-aware Sentence Split and Rephrase with Permutation Invariant Training
论文链接:https://arxiv.org/pdf/2001.11383.pdf
句子切分改写任务是将输入的复杂长句转化为多个语义等价的简单短句,通常采用 seq2seq 模型在平行语料上进行训练,这类方法主要面临以下两种问题:
1. 对于复杂长句,编码器很难准确地捕捉到其中所陈述的事实,因此解码出的简单句经常会丢失信息或者生成一些错误的事实表述(如图7(a)所示);
2. 由于从复杂句中派生出的多个简单句,可以以任何一种顺序方式呈现,这种排列的随机性会困扰 seq2seq 模型应该以怎样的顺序生成多个简单短句(如图7(b)所示)。

图7:seq2seq 模型在句子切分改写任务中面临的问题示例
为了解决上述这些问题,本篇论文引入了基于事实感知的句子编码 FaSE 以及置换无关训练的策略 PIT。整个模型的框架如图8所示,FaSE 借助多任务学习的方式使得编码器编码的特征不仅用于句子切分改写任务,同时还用于判断从当前复杂句中是否可以推断出给定的事实。引入事实判定的辅助任务使得模型能够从复杂长句中更好地捕获事实信息,从而提高句子切分的准确率;PIT 策略被广泛用于解决多谈话者场景下语音分离任务中的标签排序问题。在句子切分改写任务中,我们引入 PIT 策略来寻找具有最小损失的排列顺序作为优化的目标,从而缓解由于排列顺序随机性给 seq2seq 模型学习带来的影响,从而使得整个训练过程更加稳定。

图8:模型框架
我们提出的方法在 WebSplit-v1.0 数据集上取得了较为显著的结果,其中 FaSE 和 PIT 都分别带来了明显提升;我们还将其作为 OpenIE 任务的预处理部分,也显著地提升了 Stanford OpenIE 的结果。

通过建模隐含的实体类型信息来改进实体链接任务
Improving Entity Linking by Modeling Latent Entity Type Information
论文链接:https://arxiv.org/abs/2001.01447
实体链接(Entity Linking)任务旨在研究如何将文本中对实体有歧义的“提及” (mention) 链接到目标知识库所对应的实体上去,其结果可以用来帮助许多与知识相关的任务,如问答、信息抽取等。在研究方法上,实体链接任务经历了从传统的基于特征工程的方法到目前基于神经网络的端到端方法的过渡。
目前一些先进的基于神经网络的实体链接模型容易将“提及”链接到类型不一致的实体上去。如图9所示,本篇论文的基线方法 DeepED(Ganea and Hofmann 2017)错误地将提及 “Milwaukee” 链接到球队类型的实体 Milwaukee_Brewers,尽管介词 “In” 明显地暗示 “Milwaukee” 应该指代地点类型的实体 Milwaukee。

图9:基线方法 DeepED(Ganea and Hofmann 2017)在标准数据集 AIDA-CoNLL 开发集上的类型错误示例
基于这一观察,本篇论文分析了其主要原因有两方面:1)提及的上下文所蕴含的实体类型信息建模不够充分;2)实体的向量表示对实体类型不敏感。基于此,我们提出了一种简单有效的基于预训练语言模型的实体表示方法和一个基于 BERT 的实体相似度特征,以更好地捕捉实体类型信息。
本篇论文在标准数据集上通过领域内和领域间测试证明了模型的有效性。同时通过详细的实验分析,展示出论文所提出的方法真正纠正了大部分基线模型所产生的类型错误。
最后,论文通过在训练中得到的模型所对应的上下文表示空间中检索最邻近上下文,直观地展示出基于 BERT 的上下文表示更好地捕捉了隐含的实体类型信息。

图10:本篇论文和基线方法在上下文表示空间中的最邻近上下文

Table2Analysis: 多维数据普适分析模式的建模与推荐
Table2Analysis: Modeling and Recommendation of Common Analysis Patterns for Multi-Dimensional Data
论文链接:https://www.microsoft.com/en-us/research/publication/table2analysis-modeling-and-recommendation-of-common-analysis-patterns-for-multi-dimensional-data/

图11:多维数据普适分析的一个实例
从科学研究探索到商业智能分析,在知识发现和决策自动化的过程中,我们常面对一个关键问题:对多维数据集(表格)进行分析时,大家通常如何从中提取出信息?譬如图11中的销售数据(有日期、区域、销售代表、销售额四个维度),大多数分析师会进行哪些常见的分析呢?对此,本篇论文提出了 Table2Analysis 框架,从大量 Excel 用户创建的(表格、分析)例子中学习普适的分析模式,并基于此对新的表格推荐语义上常见的数据分析。
Table2Analysis 是一个 table-to-sequence 的框架。首先我们定义了一种分析语言,将数据分析过程编码为一系列的操作符,每个操作符可以是预定义的分析操作(如开始分析的一个部分、选定聚合函数等),也可以是选择数据表格中的一个维度。举例来说,“sum of sales by region”可以被表示成 [ANA][Sales][SEP][Region][Sum]。在分析语言的基础上,推荐常见分析则可被抽象为:给定一个表格,生成由这个表格中的维度组成的操作符序列。

图12:模型框架
要生成分析操作符序列,在 Table2Analysis 框架中我们采取了逐步一个个生成的方式,通过从大量用户创建的(表格、分析)对中学到的语言模型(也即图12中的动作值函数)来作为下一步选择的启发函数。但这种方式存在很多挑战:输入的操作符可能来自任何表格,有无限种可能性;简单 seq2seq 的训练方法在实际推断时的曝光偏差;因为对操作符序列的严格语法要求,无法直接使用传统自然语言处理中的很多模型和训练方法……对此,我们对神经网络的输入层进行了设计,并采用并行搜索采样的方法来减少曝光偏差。
在我们收集的一个大型表格数据集上,Table2Analysis 对数据透视表(PivotTable)推荐的召回率在 top-5 达到了0.78,top-1 也有0.65。这验证了 Table2Analysis 框架的有效性。

用于神经机器翻译的转导集成学习
Transductive Ensemble Learning for Neural Machine Translation
论文链接:https://www.msra.cn/wp-content/uploads/2020/01/Transductive-Ensemble-Learning-for-Neural-Machine-Translation.pdf
集成学习(Ensemble learning)利用多个不同的模型,在测试阶段用投票的方式对样本进行判别。然而,我们观察到,在神经机器翻译(NMT)的任务中,当参加测试的模型的准确率很高时,集成学习将不会对最终结果带来显著提升。类似的现象在相关文献也有所体现。因此,如何将多个强 NMT 模型集成起来得到更好的测试效果,是本篇论文研究的课题。我们提出了传导集成学习模型(Transductive Ensemble Learning,简记为 TEL),能够通过训练的方法,将多个强 NMT 模型集成到一个模型中,得到更好的测试效果。我们在 WMT 英语-德语翻译和英语-芬兰语翻译上验证了我们算法有效性。特别地,我们在 WMT’16-WMT’18 英德翻译任务上取得了当前最佳的效果。
在 TEL 模型中,我们将两个语言空间记成 X 和 Y,将训练集、验证集和测试集记成 D_train={(x_i,y_i)}_(i=1)^(N_tr), D_valid={(x ̅_i,y ̅_i)}_(i=1)^(N_val), D_test={x_j^* }_(j=1)^(N_test)。注意我们可以得到测试集的输入,但没有对应的标签。具体过程如下:
(A) 我们首先要在 D_train 上训练,得到 K 个不同的模型。利用不同的随机种子即可。将得到的模型记做 f_1,f_2,⋯,f_K 。
(B) 将验证集和测试集中的样本利用上述 K 个模型进行翻译:D_v={(x,f_k (x))|x∈D_valid,k∈[K]}, D_t={(x,f_k (x))|x∈D_test,k∈[K]}。
(C)在 D_v∪D_t 上微调: -min∑_((x,y)∈D_v∪D_t) logP(y│x;f_0) 中 f_0 可以从 f_1,f_2,⋯,f_K 中任选一个作为初始化模型。当模型在验证集上取得最佳效果时,训练停止。
首先,我们在有标数据和利用 back-translation 做了数据增强的两组设置下得到了如图13所示的实验结果。结果表明,我们的算法 TEL 在不同的设置下都能够取得一定的提高。
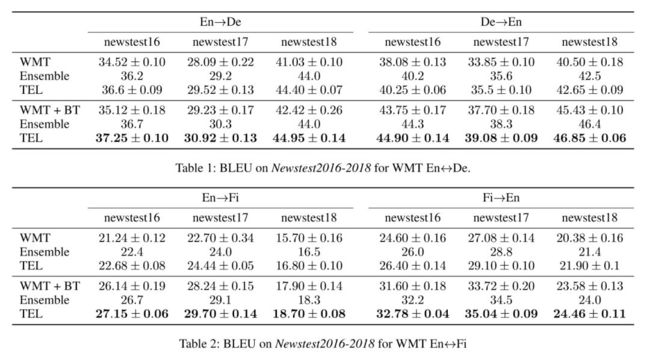
图13:TEL 在 WMT 英语-德语翻译和英语-芬兰语翻译上的实验结果
最后,我们使用了更大规模的无标数据,在 WMT 英德互译上取得了如下结果:

图14:TEL 算法在 WMT 英德互译上的实验结果
通过大量实验,我们发现:(1)TEL 算法可以提升很强的基准 NMT 模型;(2)TEL 算法对 K 值具有鲁棒性;(3)即使只有部分测试集的输入,TEL 算法仍然能够取得一定翻译效果的提高。
(*本文由AI科技大本营转载,转载请联系原作者)
【end】
◆
精彩推荐
◆

推荐阅读
福利直达!CSDN技术公开课评选进行中
一文告诉你,如何使用Python构建一个“谷歌搜索”系统 | 内附代码
小米回应 50 亿疫情贷款申请;爱奇艺 App 崩溃;OpenSSH 8.2 发布
大神如何一招完美解决Hadoop集群无法正常关闭的问题!| 博文精选
Python 爬取李子柒辣椒酱 1794 条数据,有人嫌牛肉粒太小...... | 原力计划
比特币技术栈的演进

你点的每个“在看”,我都认真当成了AI