【ReID】【skimming】Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in
补一下2017年的ICCV paper,Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro。文章首次将GAN(DCGAN)引入ReID任务中,提出了一个不需要额外搜集data,而只依靠training data,以GAN生成无标签的数据,且提出了label smoothing regu-
larization for outliers (LSRO)方法,平滑无标签图像,防止过拟合,提高模型泛化能力。
论文一览:

痛点
人脸识别能够早早商用,很大程度上是因为中国的商业公司早已经实现全国所有人脸库的搜集,落地就相当于在training set上做test,很容易就达到99.99%的准确率。
相比起来ReID的数据是非常难搜集的,由于监控摄像隐私保护和各个地方政府政策原因,现如今的ReID的公开数据集也并不是很多,以至于一直没有如ImageNet这样的百万级数据集的出现。此外即使有条件搜集数据,这些海量数据要标注也非常困难,需要消耗大量的人力物力,以上也是ReID落定难的一大原因之一。
文章针对的点就是这两大困难:
1)数据搜集难。文章是首先在ReID中使用GAN的文章。
2)搜集到的数据标注难。在文章以前GAN生成的unlabelled images主要有两种处理方法,一个是All in one方法:即将所有生成的数据单独归为一个新类(id)。一个是用伪标签pseudo label:将生成的image输入网络生成prediction,让网络预测其属于哪一类,这个id作为生成图像的id。文章不使用这些方法,而提出一种新的方法,
模型
文章提出的pipeline如下图:
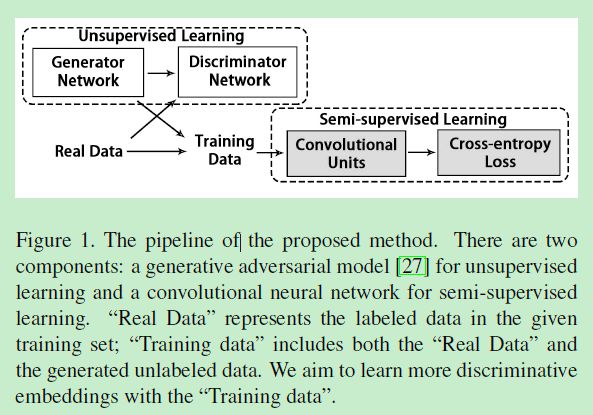
GAN生成器的初始输入文章选择100维的随机向量,并用FC层将其扩张到4x4x16的张量。再经过反卷积网络扩张到128x128x3。
GAN的辨别器输入则包括生成图像和真实图像,这个辨别器将判断生成的图片是不是真的/假的。
CNN backbone使用ResNet50,
生成的图像和training set(真实图像)一起喂给ResNet训练。
Label Smoothing Regularization(LSR)
之前的LSR方法是以一个很小的值来作为non-ground truth image的label,如此可减少过拟合,
假设training class有K个,根据交叉熵loss我们有:

其中 p ( k ) p(k) p(k)是属于第k类的概率,而 q ( k ) q(k) q(k)是ground truth的分布,y为ground truth的label,有:
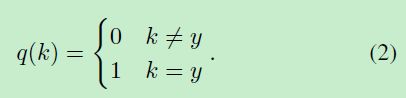
假设忽略 q ( k ) = 0 q(k)=0 q(k)=0的情况,交叉熵loss有:

所以有结论:最小化交叉熵损失等效于最大化ground truth类的预测概率。
而label smoothing regularization (LSR)则把non-ground truth考虑进来,labal 分布有:
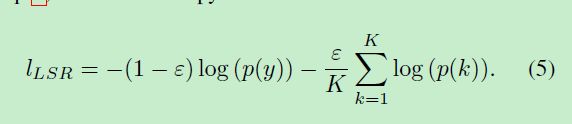
其会附带注意其他class,而不只是ground truth。
label smoothing regularization for outliers (LSRO)
文章的LSRO从LSR改进而来。即LSRO使用了一个统一的label 分布:
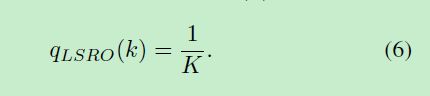
示意图如下:即所有的class都使用均等统一的分布:

作者这样出于两点考虑:
1)生成的样本不属于任何预定义的类
2)网络不会以太高的置信度来预测某一个class,可以解决过度拟合问题。
则基于LSRO的交叉熵损失可以写成:

若为真实图片,Z=0,若为生成图片,Z=1。
可以看到LSRO最大的特点就是承认生成图片的无特定类别属性,但是不是因此单独给它一个id,而是直接让其label属于所有label的平均概率,它属于所有label中的某一个是等可能的,比较巧妙。
实验
具体实验配置可以查看文章
DukeMTMC-ReID和CUB-200-2011的生成图像可视化:

market1501测的(当时的)SOTA如下:

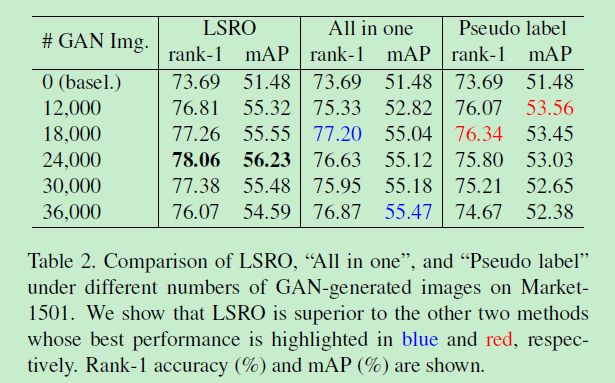
LSRO与我们刚刚提到的All in one和伪标签Pseudo label横向方法对比如下:
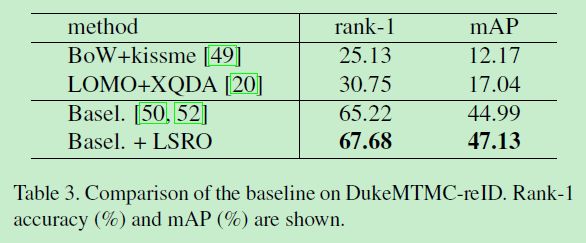
DukeMTMC-reID测得SOTA如下:
真实数据扩充(from CUHK03)与GAN生成数据(from Market1501)扩充对比:
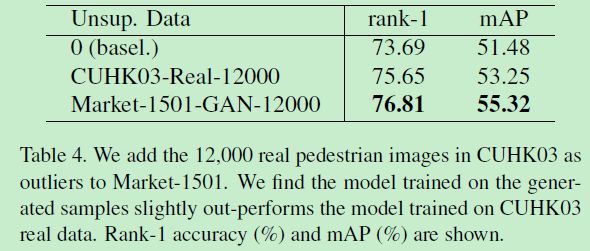
CUHK03的扩充居然提点,且居然没有GANsheng
在CUHK03测的SOTA:

DukeMTMC-reID结果可视化,红框为错误,蓝框为正确:

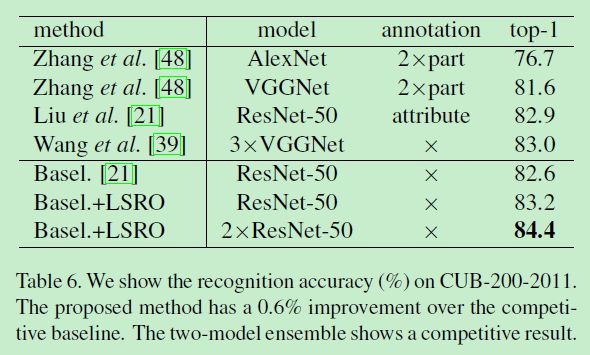
细粒度分类数据集CUB-200-2011测得SOTA:
参考文献
[1] Zheng Z, Zheng L, Yang Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 3754-3762.