语料库的获取与词频分析
声明:代码的运行环境为Python3。Python3与Python2在一些细节上会有所不同,希望广大读者注意。本博客以代码为主,代码中会有详细的注释。相关文章将会发布在我的个人博客专栏《Python自然语言处理》,欢迎大家关注。
一、古腾堡语料库
# 古腾堡语料库
from nltk.corpus import gutenberg # 加载古腾堡语料库
gutenberg.fileids()
Out[2]:
['austen-emma.txt',
'austen-persuasion.txt',
'austen-sense.txt',
'bible-kjv.txt',
'blake-poems.txt',
'bryant-stories.txt',
'burgess-busterbrown.txt',
'carroll-alice.txt',
'chesterton-ball.txt',
'chesterton-brown.txt',
'chesterton-thursday.txt',
'edgeworth-parents.txt',
'melville-moby_dick.txt',
'milton-paradise.txt',
'shakespeare-caesar.txt',
'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt',
'whitman-leaves.txt']
emma = gutenberg.words('austen-emma.txt') # 加载austen-emma.txt这个文件
print(emma)
['[', 'Emma', 'by', 'Jane', 'Austen', '1816', ']', ...]
for fileid in gutenberg.fileids():
num_chars = len(gutenberg.raw(fileid)) # 以字符为单位,获取文本的长度
num_words = len(gutenberg.words(fileid)) # 以单词为单位,获取文本的长度
num_sents = len(gutenberg.sents(fileid)) # 以句子为单位,获取文本的长度
num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)])) # 获取文本中不重复的单词个数
print(num_chars, num_words, num_sents, num_vocab, fileid)
887071 192427 7752 7344 austen-emma.txt
466292 98171 3747 5835 austen-persuasion.txt
673022 141576 4999 6403 austen-sense.txt
4332554 1010654 30103 12767 bible-kjv.txt
38153 8354 438 1535 blake-poems.txt
249439 55563 2863 3940 bryant-stories.txt
84663 18963 1054 1559 burgess-busterbrown.txt
144395 34110 1703 2636 carroll-alice.txt
457450 96996 4779 8335 chesterton-ball.txt
406629 86063 3806 7794 chesterton-brown.txt
320525 69213 3742 6349 chesterton-thursday.txt
935158 210663 10230 8447 edgeworth-parents.txt
1242990 260819 10059 17231 melville-moby_dick.txt
468220 96825 1851 9021 milton-paradise.txt
112310 25833 2163 3032 shakespeare-caesar.txt
162881 37360 3106 4716 shakespeare-hamlet.txt
100351 23140 1907 3464 shakespeare-macbeth.txt
711215 154883 4250 12452 whitman-leaves.txt
macbeth_sentences = gutenberg.sents('shakespeare-macbeth.txt') # 以句子为单位获取文本内容
print(macbeth_sentences)
[['[', 'The', 'Tragedie', 'of', 'Macbeth', 'by', 'William', 'Shakespeare', '1603', ']'], ['Actus', 'Primus', '.'], ...]
print(macbeth_sentences[1037]) # 获取下标为1037的句子
['Good', 'night', ',', 'and', 'better', 'health', 'Attend', 'his', 'Maiesty']
longest_len = max([len(s) for s in macbeth_sentences]) # 获取最长句子的长度
print(longest_len)
158
print([s for s in macbeth_sentences if len(s) == longest_len]) # 打印出最长的句子
[['Doubtfull', 'it', 'stood', ',', 'As', 'two', 'spent', 'Swimmers', ',', 'that', 'doe', 'cling', 'together', ',', 'And', 'choake', 'their', 'Art', ':', 'The', 'mercilesse', 'Macdonwald', '(', 'Worthie', 'to', 'be', 'a', 'Rebell', ',', 'for', 'to', 'that', 'The', 'multiplying', 'Villanies', 'of', 'Nature', 'Doe', 'swarme', 'vpon', 'him', ')', 'from', 'the', 'Westerne', 'Isles', 'Of', 'Kernes', 'and', 'Gallowgrosses', 'is', 'supply', "'", 'd', ',', 'And', 'Fortune', 'on', 'his', 'damned', 'Quarry', 'smiling', ',', 'Shew', "'", 'd', 'like', 'a', 'Rebells', 'Whore', ':', 'but', 'all', "'", 's', 'too', 'weake', ':', 'For', 'braue', 'Macbeth', '(', 'well', 'hee', 'deserues', 'that', 'Name', ')', 'Disdayning', 'Fortune', ',', 'with', 'his', 'brandisht', 'Steele', ',', 'Which', 'smoak', "'", 'd', 'with', 'bloody', 'execution', '(', 'Like', 'Valours', 'Minion', ')', 'caru', "'", 'd', 'out', 'his', 'passage', ',', 'Till', 'hee', 'fac', "'", 'd', 'the', 'Slaue', ':', 'Which', 'neu', "'", 'r', 'shooke', 'hands', ',', 'nor', 'bad', 'farwell', 'to', 'him', ',', 'Till', 'he', 'vnseam', "'", 'd', 'him', 'from', 'the', 'Naue', 'toth', "'", 'Chops', ',', 'And', 'fix', "'", 'd', 'his', 'Head', 'vpon', 'our', 'Battlements']]
二、网络和聊天文本语料库
# 网络和聊天文本
from nltk.corpus import webtext # 加载语料库
webtext.fileids()
for fileid in webtext.fileids(): # 获取文本内容
print(fileid, webtext.raw(fileid)[:65], '...')
firefox.txt Cookie Manager: "Don't allow sites that set removed cookies to se ...
grail.txt SCENE 1: [wind] [clop clop clop]
KING ARTHUR: Whoa there! [clop ...
overheard.txt White guy: So, do you have any plans for this evening?
Asian girl ...
pirates.txt PIRATES OF THE CARRIBEAN: DEAD MAN'S CHEST, by Ted Elliott & Terr ...
singles.txt 25 SEXY MALE, seeks attrac older single lady, for discreet encoun ...
wine.txt Lovely delicate, fragrant Rhone wine. Polished leather and strawb ...
from nltk.corpus import nps_chat # 获取聊天室语料库
chatroom = nps_chat.posts('10-19-20s_706posts.xml')
print(chatroom[123])
['i', 'do', "n't", 'want', 'hot', 'pics', 'of', 'a', 'female', ',', 'I', 'can', 'look', 'in', 'a', 'mirror', '.']
三、布朗语料库
from nltk.corpus import brown
brown.categories() # 查看布朗语料库的分类
Out[11]:
['adventure',
'belles_lettres',
'editorial',
'fiction',
'government',
'hobbies',
'humor',
'learned',
'lore',
'mystery',
'news',
'religion',
'reviews',
'romance',
'science_fiction']
brown.words(categories='news') # 查看news分类里面词链表的结果
Out[12]: ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
brown.words(fileids=['cg22']) # 查看cg22文本里面的词链表结果
Out[13]: ['Does', 'our', 'society', 'have', 'a', 'runaway', ',', ...]
brown.sents(categories=['news', 'editorial', 'reviews']) # 展示多个分类的内容
Out[14]: [['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation', 'of', "Atlanta's", 'recent', 'primary', 'election', 'produced', '``', 'no', 'evidence', "''", 'that', 'any', 'irregularities', 'took', 'place', '.'], ['The', 'jury', 'further', 'said', 'in', 'term-end', 'presentments', 'that', 'the', 'City', 'Executive', 'Committee', ',', 'which', 'had', 'over-all', 'charge', 'of', 'the', 'election', ',', '``', 'deserves', 'the', 'praise', 'and', 'thanks', 'of', 'the', 'City', 'of', 'Atlanta', "''", 'for', 'the', 'manner', 'in', 'which', 'the', 'election', 'was', 'conducted', '.'], ...]
import nltk
news_text = brown.words(categories='news') # 保存news分类的结果
fdist = nltk.FreqDist([w.lower() for w in news_text]) # 将单词转换为小写,统计词频
modals = ['can', 'could', 'may', 'might', 'must', 'will'] # 定义一个情态动词列表
for m in modals: # 统计一下情态动词的词频数量
print(m + ':', fdist[m])
can: 94
could: 87
may: 93
might: 38
must: 53
will: 389
cfd = nltk.ConditionalFreqDist( # 条件频率分布函数
(genre, word)
for genre in brown.categories() #文体
for word in brown.words(categories=genre)) # 单词
genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
cfd.tabulate(conditions=genres, samples=modals) # 获取一个交叉图
can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
四、路透社语料库
from nltk.corpus import reuters
print(len(reuters.fileids())) # 文档的数目
print(len(reuters.categories())) # 分类数目
10788
90
reuters.categories('training/9865') # 支持单个搜索和列表搜索
Out[20]: ['barley', 'corn', 'grain', 'wheat']
reuters.categories(['training/9865', 'training/9880'])
Out[21]: ['barley', 'corn', 'grain', 'money-fx', 'wheat']
五、就职演讲语料库
#就职演讲语料库
from nltk.corpus import inaugural
inaugural.fileids()
print([fileid[:4] for fileid in inaugural.fileids()]) # 打印出语料库中每个文件名的前四个字符
['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', '1825', '1829', '1833', '1837', '1841', '1845', '1849', '1853', '1857', '1861', '1865', '1869', '1873', '1877', '1881', '1885', '1889', '1893', '1897', '1901', '1905', '1909', '1913', '1917', '1921', '1925', '1929', '1933', '1937', '1941', '1945', '1949', '1953', '1957', '1961', '1965', '1969', '1973', '1977', '1981', '1985', '1989', '1993', '1997', '2001', '2005', '2009']
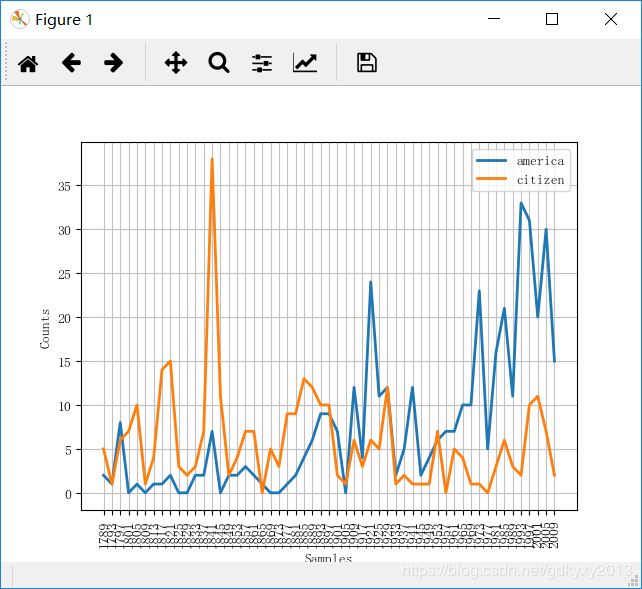
cfd = nltk.ConditionalFreqDist( # 查看'america'和'citizen'两个单词在随着时间的推移在文章中出现的频数
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target))
cfd.plot()图像如下:

六、其他语料库(不同语言的语料库)
nltk.corpus.cess_esp.words()
Out[25]: ['El', 'grupo', 'estatal', 'Electricité_de_France', ...]
nltk.corpus.floresta.words()
Out[26]: ['Um', 'revivalismo', 'refrescante', 'O', '7_e_Meio', ...]
nltk.corpus.indian.words('hindi.pos')
Out[27]: ['पूर्ण', 'प्रतिबंध', 'हटाओ', ':', 'इराक', 'संयुक्त', ...]
nltk.corpus.udhr.fileids()
Out[28]:
['Abkhaz-Cyrillic+Abkh',
'Abkhaz-UTF8',
'Achehnese-Latin1',
'Achuar-Shiwiar-Latin1',
'Adja-UTF8',
'Afaan_Oromo_Oromiffa-Latin1',
'Afrikaans-Latin1',
'Aguaruna-Latin1',
'Akuapem_Twi-UTF8',
'Albanian_Shqip-Latin1',
'Amahuaca',
'Amahuaca-Latin1',
'Amarakaeri-Latin1',
'Amuesha-Yanesha-UTF8',
...
print(nltk.corpus.udhr.words('Javanese-Latin1')[11:])
['Saben', 'umat', 'manungsa', 'lair', 'kanthi', 'hak', ...]
# 条件频率分布的例子
from nltk.corpus import udhr
languages = ['Chickasaw', 'English', 'German_Deutsch',
'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
cfd = nltk.ConditionalFreqDist(
(lang, len(word))
for lang in languages
for word in udhr.words(lang + '-Latin1'))
cfd.plot(cumulative=True)图像如下:

七、载入自己的语料库
from nltk.corpus import PlaintextCorpusReader
corpus_root = 'F:/icwb2-data/training' #文件目录
wordlists = PlaintextCorpusReader(corpus_root, ['pku_training.utf8','cityu_training.utf8','msr_training.utf8','pku_training.utf8'])
wordlists.fileids()
Out[31]:
['pku_training.utf8',
'cityu_training.utf8',
'msr_training.utf8',
'pku_training.utf8']
# 打印出相关的信息
print(len(wordlists.words('pku_training.utf8')))
1119084
print(len(wordlists.sents('pku_training.utf8')))
4
语料库的基本函数:

八、条件频率分布
1、条件与事件
'''
text = ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said',...]
pairs = [('news', 'The'), ('news', 'Fulton'), ('news', 'County'),...]
'''2、按文本计算词频
genre_word = [(genre, word)
for genre in ['news', 'romance']
for word in brown.words(categories=genre)]
len(genre_word)
Out[35]: 170576
print(genre_word[:4])
[('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ('news', 'Grand')]
nltk.ConditionalFreqDist(genre_word).conditions() # 显示文体
Out[37]: ['news', 'romance']
print(nltk.ConditionalFreqDist(genre_word)['news'])
print(nltk.ConditionalFreqDist(genre_word)['news']['could']) # 某个条件下,某个特定词语出现的次数
86
3、绘制分布图和分布表
from nltk.corpus import inaugural
cfd2 = nltk.ConditionalFreqDist(
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target))
cfd2.plot()图形如下:
from nltk.corpus import udhr
languages = ['Chickasaw', 'English', 'German_Deutsch',
'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
udhr.fileids()
cfd3 = nltk.ConditionalFreqDist(
(lang, len(word))
for lang in languages
for word in udhr.words(lang + '-Latin1'))
cfd3.tabulate(conditions=['English', 'German_Deutsch'],
samples=range(10), cumulative=True)
0 1 2 3 4 5 6 7 8 9
English 0 185 525 883 997 1166 1283 1440 1558 1638
German_Deutsch 0 171 263 614 717 894 1013 1110 1213 1275
4、使用双链词生成随机文本
def generate_model(cfdist, word, num=15):
for i in range(num):
print(word)
word = cfdist[word].max() # 选择这个词语之后最大可能出现的词语
text = nltk.corpus.genesis.words('english-kjv.txt')
bigrams = nltk.bigrams(text)
cfd4 = nltk.ConditionalFreqDist(bigrams)
print(list(cfd4['living']))
['creature', 'thing', 'soul', '.', 'substance', ',']
generate_model(cfd4, 'living')
living
creature
that
he
said
,
and
the
land
of
the
land
of
the
land
常用的条件频率分布方法:
九、词典
1、词汇列表语料库
def unusual_words(text): # 定义一个函数,找出文本中不常见的词语
text_vocab = set(w.lower() for w in text if w.isalpha())
english_vocab = set(w.lower() for w in nltk.corpus.words.words())
unusual = text_vocab.difference(english_vocab) # 计算差集
return sorted(unusual) # 打印出差集词语
unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt')) # 应用到古腾堡语料库中
Out[46]:
['abbeyland',
'abhorred',
'abilities',
'abounded',
'abridgement',
'abused',
'abuses',
'accents',
'accepting',
'accommodations',
'accompanied',
'accounted',
'altered',
'altering',
'amended',
'amounted',
'amusements',
'ankles',
'annamaria',
'annexed',
'announced',
'announcing',
'annuities',
...from nltk.corpus import stopwords # 停用词语料库
stopwords.words('english') # 列举出english中的停用词
Out[48]:
['i',
'me',
'my',
'myself',
'we',
'our',
'ours',
'ourselves',
'you',
"you're",
"you've",
"you'll",
"you'd",
'your',
'yours',
'yourself',
...def content_fraction(text): # 获取非停用词在列表中所占的比例
stopwords = nltk.corpus.stopwords.words('english')
content = [w for w in text if w.lower() not in stopwords]
return len(content) / len(text)
content_fraction(nltk.corpus.reuters.words())
Out[49]: 0.735240435097661
names = nltk.corpus.names # 姓名词汇表
names.fileids()
Out[51]: ['female.txt', 'male.txt']
male_names = names.words('male.txt')
female_names = names.words('female.txt')
manAndWoman = [w for w in male_names if w in female_names]
print(manAndWoman) # 查看男女通用的姓名有哪些
['Abbey', 'Abbie', 'Abby', 'Addie', 'Adrian', 'Adrien', 'Ajay', 'Alex', 'Alexis', 'Alfie', 'Ali', 'Alix', 'Allie', 'Allyn', 'Andie', 'Andrea', 'Andy', 'Angel', 'Angie', 'Ariel', 'Ashley', 'Aubrey', 'Augustine', 'Austin', 'Averil', 'Barrie', 'Barry', 'Beau', 'Bennie', 'Benny', 'Bernie', 'Bert', 'Bertie', 'Bill', 'Billie', 'Billy', 'Blair', 'Blake', 'Bo', 'Bobbie', 'Bobby', 'Brandy', 'Brett', 'Britt',...]
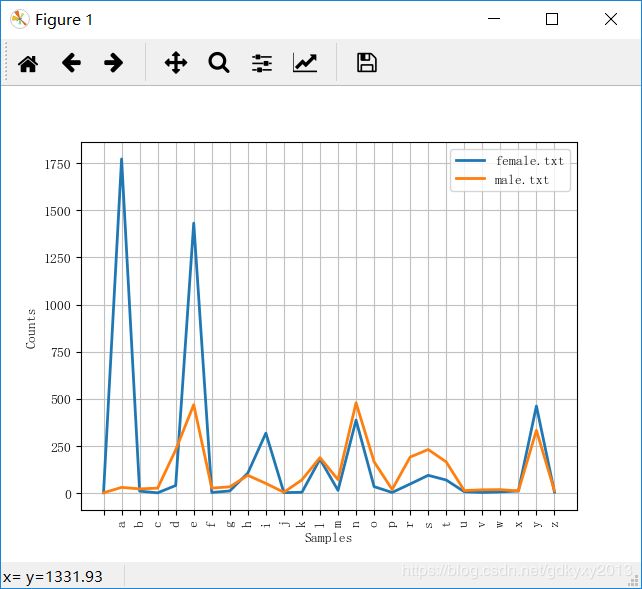
cfd5 = nltk.ConditionalFreqDist( # 获取名字的最后一个字母
(fileid, name[-1])
for fileid in names.fileids()
for name in names.words(fileid))
cfd5.plot()图像如下:
2、发音词典
entries = nltk.corpus.cmudict.entries()
len(entries)
Out[54]: 133737
for entry in entries[39943:39951]: # 打印出一部分发音词典的内容
print(entry)
('explorer', ['IH0', 'K', 'S', 'P', 'L', 'AO1', 'R', 'ER0'])
('explorers', ['IH0', 'K', 'S', 'P', 'L', 'AO1', 'R', 'ER0', 'Z'])
('explores', ['IH0', 'K', 'S', 'P', 'L', 'AO1', 'R', 'Z'])
('exploring', ['IH0', 'K', 'S', 'P', 'L', 'AO1', 'R', 'IH0', 'NG'])
('explosion', ['IH0', 'K', 'S', 'P', 'L', 'OW1', 'ZH', 'AH0', 'N'])
('explosions', ['IH0', 'K', 'S', 'P', 'L', 'OW1', 'ZH', 'AH0', 'N', 'Z'])
for word, pron in entries: # 找出三音素的词语,开头是p,结尾是t
if len(pron) == 3:
ph1, ph2, ph3 = pron
if ph1 == 'P' and ph3 == 'T':
print(word, ph2)
pait EY1
pat AE1
pate EY1
patt AE1
peart ER1
...def stress(pron): # 返回重音的情况
return [char for phone in pron for char in phone if char.isdigit()]
print([w for w, pron in entries if stress(pron) == ['0', '1', '0', '2', '0']]) # 重音在第二个元素,次重音在第四个元素
['abbreviated', 'abbreviated', 'abbreviating', 'accelerated', 'accelerating', 'accelerator', 'accelerators', 'accentuated', 'accentuating', 'accommodated', 'accommodating', 'accommodative', 'accumulated', 'accumulating', 'accumulative', 'accumulator', 'accumulators', 'accusatory',...]
3、比较词典
from nltk.corpus import swadesh
swadesh.fileids()
Out[58]:
['be',
'bg',
'bs',
'ca',
'cs',
'cu',
...fr2en = swadesh.entries(['fr', 'en']) # 英语和法语同义词匹配
print(fr2en)
[('je', 'I'), ('tu, vous', 'you (singular), thou'), ('il', 'he'), ('nous', 'we'), ('vous', 'you (plural)'), ('ils, elles', 'they'), ('ceci', 'this'), ('cela', 'that'), ('ici', 'here'), ('là', 'there'), ('qui', 'who'), ('quoi', 'what'), ('où', 'where'), ('quand', 'when'), ('comment', 'how'), ...]
de2en = swadesh.entries(['de', 'en']) # German-English
es2en = swadesh.entries(['es', 'en']) # Spanish-English
translate.update(dict(de2en))
translate.update(dict(es2en))
print(translate['Hund'])
dog
print(translate['perro'])
dog
languages = ['en', 'de', 'nl', 'es', 'fr', 'pt', 'la']
for i in [139, 140, 141, 142]: # 比较德语和拉丁语的差别
print(swadesh.entries(languages)[i])
('say', 'sagen', 'zeggen', 'decir', 'dire', 'dizer', 'dicere')
('sing', 'singen', 'zingen', 'cantar', 'chanter', 'cantar', 'canere')
('play', 'spielen', 'spelen', 'jugar', 'jouer', 'jogar, brincar', 'ludere')
('float', 'schweben', 'zweven', 'flotar', 'flotter', 'flutuar, boiar', 'fluctuare')
4、词汇工具
from nltk.corpus import toolbox
toolbox.entries('rotokas.dic')
Out[65]:
[('kaa',
[('ps', 'V'),
('pt', 'A'),
('ge', 'gag'),
('tkp', 'nek i pas'),
('dcsv', 'true'),
('vx', '1'),
('sc', '???'),
('dt', '29/Oct/2005'),
...
十、Wordnet
1、同义词
from nltk.corpus import wordnet as wn
wn.synsets('motorcar') # 找到与motorcar同义的词
Out[66]: [Synset('car.n.01')]
wn.synset('car.n.01').lemma_names() # 查看car.n.01里面的内容
Out[67]: ['car', 'auto', 'automobile', 'machine', 'motorcar']
wn.synset('car.n.01').definition() # 定义
Out[68]: 'a motor vehicle with four wheels; usually propelled by an internal combustion engine'
wn.synset('car.n.01').examples() # 例子
Out[69]: ['he needs a car to get to work']
wn.synset('car.n.01').lemmas()
Out[70]:
[Lemma('car.n.01.car'),
Lemma('car.n.01.auto'),
Lemma('car.n.01.automobile'),
Lemma('car.n.01.machine'),
Lemma('car.n.01.motorcar')]
wn.lemma('car.n.01.automobile')
Out[71]: Lemma('car.n.01.automobile')
wn.lemma('car.n.01.automobile').synset()
Out[72]: Synset('car.n.01')
wn.lemma('car.n.01.automobile').name()
Out[73]: 'automobile'
wn.synsets('car')
Out[74]:
[Synset('car.n.01'),
Synset('car.n.02'),
Synset('car.n.03'),
Synset('car.n.04'),
Synset('cable_car.n.01')]
motorcar = wn.synset('car.n.01')
types_of_motorcar = motorcar.hyponyms() # 获取下位词级
print(types_of_motorcar[26])
Synset('stanley_steamer.n.01')
sorted([lemma.name() for synset in types_of_motorcar for lemma in synset.lemmas()])
Out[78]:
['Model_T',
'S.U.V.',
'SUV',
'Stanley_Steamer',
'ambulance',
'beach_waggon',
'beach_wagon',
'bus',
'cab',
'compact',
2、其他词汇关系
wn.synset('tree.n.01').part_meronyms() # 树的部分
Out[79]:
[Synset('burl.n.02'),
Synset('crown.n.07'),
Synset('limb.n.02'),
Synset('stump.n.01'),
Synset('trunk.n.01')]
wn.synset('tree.n.01').substance_meronyms() # 树的子元素
Out[80]: [Synset('heartwood.n.01'), Synset('sapwood.n.01')]
wn.synset('tree.n.01').member_holonyms() # 组成树的成员
Out[81]: [Synset('forest.n.01')]
for synset in wn.synsets('mint', wn.NOUN): # 打印出同义词之间具体的关系
print(synset.name() + ':', synset.definition())
batch.n.02: (often followed by `of') a large number or amount or extent
mint.n.02: any north temperate plant of the genus Mentha with aromatic leaves and small mauve flowers
mint.n.03: any member of the mint family of plants
mint.n.04: the leaves of a mint plant used fresh or candied
mint.n.05: a candy that is flavored with a mint oil
mint.n.06: a plant where money is coined by authority of the government
wn.synset('mint.n.04').part_holonyms()
Out[84]: [Synset('mint.n.02')]
wn.synset('mint.n.04').substance_holonyms()
Out[85]: [Synset('mint.n.05')]
wn.synset('walk.v.01').entailments()
Out[86]: [Synset('step.v.01')]
wn.lemma('supply.n.02.supply').antonyms() # 查看反义词
Out[87]: [Lemma('demand.n.02.demand')]
3、语义相似度
right = wn.synset('right_whale.n.01')
orca = wn.synset('orca.n.01')
minke = wn.synset('minke_whale.n.01')
tortoise = wn.synset('tortoise.n.01')
novel = wn.synset('novel.n.01')
right.lowest_common_hypernyms(minke) # 查找相关性比较强的词语
Out[88]: [Synset('baleen_whale.n.01')]
wn.synset('baleen_whale.n.01').min_depth()
Out[89]: 14
right.path_similarity(minke) # 比较相似度
Out[90]: 0.25