【阅读笔记】In-Domain GAN Inversion for Real Image Editing
论文名称:In-Domain GAN Inversion for Real Image Editing
论文作者:Jiapeng Zhu, Yujun Shen, Deli Zhao, Bolei Zhou
发行时间:Submitted on 31 Mar 2020, last revised 11 May 2020
论文地址:https://arxiv.org/abs/2004.00049
代码开源:https://github.com/genforce/idinvert
- 一. 概要
- 二. In-Domain GAN Inversion
- 2.1. 模型说明
- 2.1.1. 符号说明
- 2.1.2. 潜在空间的选择
- 2.2. Domain-Guided Encoder
- 2.3. Domain-Regularized Optimization
- 2.1. 模型说明
- 三. 实验
- 3.1. 反演图像的质量和速度
- 3.2. 真实图像编辑
- 3.2.1. Image Interpolation
- 3.2.2. Semantic Manipulation
- 3.2.3. Semantic Diffusion
- 3.3. 消融实验
一. 概要
本文首次提出同时对重构图像的潜在空间的语义级和目标函数的像素级进行考虑,而不像传统方法那样(只关注像素级)无法将反演的潜码定位到原始潜在空间的语义域上。即提出了 in-domain GAN inversion 的方法,具体实现如下:
- 首先对
domain-guided encoder进行训练,来将输入图像映射成 GANs 潜在空间的潜在编码。 - 再使用
domain-regularized optimization来对编码器得到的潜在编码进行微调来确保产生的潜在编码在语义域内。
二. In-Domain GAN Inversion

2.1. 模型说明
2.1.1. 符号说明
GAN 模型:
- 生成器 G ( ⋅ ) : Z → X G(\cdot):\mathcal{Z}\to\mathcal{X} G(⋅):Z→X,将潜在编码生成为高分辨率的图像。
- 辨别器 D ( ⋅ ) D(\cdot) D(⋅),判断合成图像的真伪。
GAN inversion 方法是学习生成器 G ( ⋅ ) G(\cdot) G(⋅) 的逆映射,即能找到一个最佳潜在编码 z i n v z^{inv} zinv 来恢复给定的真实图像 x r e a l x^{real} xreal。文中将 GAN 学到的语义空间定义为 S \mathcal{S} S。期望 z i n v z^{inv} zinv 能通预训练好的 GAN 的先验知识 S S S 保持一致。
2.1.2. 潜在空间的选择
本文选择的是在 StyleGAN 中的 W \mathcal{W} W 空间,只是为了方便起见,后续仍然使用 z z z 来表示潜在编码。
选择的理由:
- 更加关注语义信息。
- 性能更佳。
- 引入比较简单。
2.2. Domain-Guided Encoder
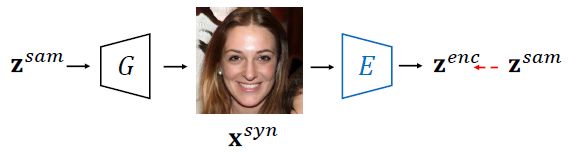
上图便是传统的编码器架构,从潜在空间 Z \mathcal{Z} Z 中随机采样出一些潜在编码 z s a m z^{sam} zsam,然后将其输入生成器 G ( ⋅ ) G(\cdot) G(⋅) 中来得到相对应的合成图像 x s y n x^{syn} xsyn。之后编码器就会采用 x s y n x^{syn} xsyn 作为输入,在 z s a m z^{sam} zsam 的监督下进行训练来得到最终的潜在编码 z e n c z^{enc} zenc。损失函数如下所示:
min Θ E L E = ∣ ∣ z s a m − E ( G ( z s a m ) ) ∣ ∣ 2 \mathop{\min}\limits_{\Theta_E}\mathcal{L}_{E}=||z^{sam}-E(G(z^{sam}))||_2 ΘEminLE=∣∣zsam−E(G(zsam))∣∣2
其中, ∣ ∣ ⋅ ∣ ∣ 2 ||\cdot||_2 ∣∣⋅∣∣2 表示 l 2 l_2 l2 距离, Θ E \Theta_E ΘE 表示编码器 E ( ⋅ ) E(\cdot) E(⋅) 的参数。文中认为,仅仅对 z s a m z^{sam} zsam 进行监督来实现的重构五注意得到一个准确的编码器,而且这种方法并没有考虑生成器 G ( ⋅ ) G(\cdot) G(⋅) 的梯度,相当于生成器的内部知识没有被考虑进去,无法提供生成器的领域知识来指导编码器的训练。作者提出的解决方法如下图所示。
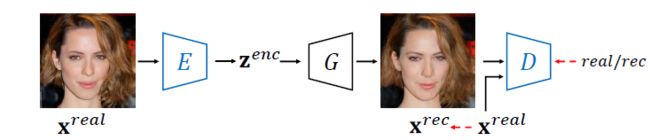
区别于传统编码器:
- 编码器的输出将作为生成器的输入,这样我们的目标函数的参数将来源于图像空间而不是潜在空间。其涉及到在训练阶段中生成器的语义知识,并提供准确的监督和更多的信息,保证输出编码与生成器的语义域保持一致。
- 我们的编码器直接使用真实图像进行训练,而不是传统的使用合成图像训练。因为通常都是对真实图像进行图像操纵,显然我们的这种方法更加适用。
- 在训练过程中固定预训练好的生成器,而让判别器和编码器同时进行对抗式训练。这样可以从
GAN模型中获取更多的信息,同时确保输入的编码在语义上尽可能和生成器一致。
对应,我们训练过程中的目标函数如下所示:
min Θ E L E = ∣ ∣ x r e a l − G ( E ( x r e a l ) ) ∣ ∣ 2 + λ 1 ∣ ∣ F ( x r e a l ) − F ( G ( E ( x r e a l ) ) ) ∣ ∣ 2 − λ 2 E x r e a l ∼ P d a t a [ D ( G ( E ( x r e a l ) ) ) ] \mathop{\min}\limits_{\Theta_E}\mathcal{L}_{E} = ||x^{real}-G(E(x^{real}))||_2+\lambda_1||F(x^{real})-F(G(E(x^{real})))||_2-\lambda_2\mathop{\mathbb{E}}\limits_{x^{real}\sim P_{data}}[D(G(E(x^{real})))] ΘEminLE=∣∣xreal−G(E(xreal))∣∣2+λ1∣∣F(xreal)−F(G(E(xreal)))∣∣2−λ2xreal∼PdataE[D(G(E(xreal)))]
min Θ D L D = E x r e a l ∼ P d a t a [ D ( G ( E ( x r e a l ) ) ) ] − E x r e a l ∼ P d a t a [ D ( x r e a l ) ] + γ 2 E x r e a l ∼ P d a t a [ ∣ ∣ ▽ x D ( x r e a l ) ∣ ∣ 2 2 ] \mathop{\min}\limits_{\Theta_D}\mathcal{L}_{D} = \mathop{\mathbb{E}}\limits_{x^{real}\sim P_{data}}[D(G(E(x^{real})))]-\mathop{\mathbb{E}}\limits_{x^{real}\sim P_{data}}[D(x^{real})]+\frac{\gamma}{2}\mathop{\mathbb{E}}\limits_{x^{real}\sim P_{data}}[||\triangledown _xD(x^{real})||_2^2] ΘDminLD=xreal∼PdataE[D(G(E(xreal)))]−xreal∼PdataE[D(xreal)]+2γxreal∼PdataE[∣∣▽xD(xreal)∣∣22]
其中, P d a t a P_{data} Pdata 表示真实数据的概率分布。 γ \gamma γ 表示梯度正则化的超参数,实验里取值为 10 10 10。 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 为损失权重来平衡不同函数部分,实验中对应的取值为 5 e − 5 5e^{-5} 5e−5 和 0.1 0.1 0.1。 F ( ⋅ ) F(\cdot) F(⋅) 表示 VGG 特征提取模块(conv4_3),这通常用来计算 perceptual-loss。这一训练步骤主要是对编码器和辨别器的参数进行更新,训练完毕后,编码器就能直接将输入的图像编码成较合适的潜在编码。
2.3. Domain-Regularized Optimization
尽管我们提出的编码器产生的潜在编码能够很好的重构目标图像,也确保了其编码语义性是有意义的,但仍然需要用 Domain-Regularized Optimization 来微调编码使其更好拟合目标函数的像素值。简而言之,本文提出一种优化方案来对编码器产生的潜在编码再次进行微调,来使得重构的结果更加精准。
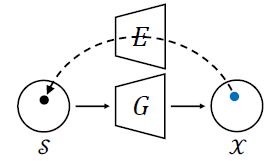
如上图所示,不同于传统的自由地优化方案,文中提出的优化方案对潜在编码的反推进行了限制。Domain-Regularized Optimization 主要有两个改进点:
- 使用本文提出的编码器的输出的潜在编码作为优化起点,这样可以避免潜在编码陷入局部最小值,并且显著缩短优化过程。
- 将
Domain-Guided Encoder作为正则化器,将潜在编码保留在生成器的语义域内。
对应目标函数为:
z i n v = arg min z ∣ ∣ x − G ( z ) ∣ ∣ 2 + λ 3 ∣ ∣ F ( x ) − F ( G ( z ) ) ∣ ∣ 2 + λ 4 ∣ ∣ z − E ( G ( z ) ) ∣ ∣ 2 z^{inv}=\arg\mathop{\min}\limits_{z}||x-G(z)||_2+\lambda_3||F(x)-F(G(z))||_2+\lambda_4||z-E(G(z))||_2 zinv=argzmin∣∣x−G(z)∣∣2+λ3∣∣F(x)−F(G(z))∣∣2+λ4∣∣z−E(G(z))∣∣2
其中, x x x 表示待反转的目标函数, λ 3 \lambda_3 λ3 和 λ 4 \lambda_4 λ4 为损失权重,实验中对应的取值为 5 e − 5 5e^{-5} 5e−5 和 2 2 2。
三. 实验
3.1. 反演图像的质量和速度
将文中提出的方法同一些其他的 GAN inversion 进行比较。具体比对有:
- 传统:
traditional encoderMSE-based optimization:Image2StyleGAN
- 本文提出的方法:
Domain-Guided Encoder(不包含Domain-Regularized Optimization)In-Domain Inversion(包含Domain-Regularized Optimization)
定性结果如下图所示,可见本文提出的编码器在映射有较大的优势,同时,完整的算法(e)的效果最好:
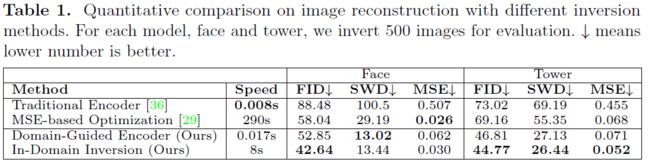
定量分析如下表所示,可见我们的方法不但快速,而且具有更好的重建结果:
3.2. 真实图像编辑
文中分别对3种图像编辑任务进行了评估:
- image interpolation:两种图像之间插值得到新图像
- semantic image manipulation:通过操纵图像的某一种或多种语义来得到新的图像
- semantic image diffusion:将目标图中最具代表性的区域扩散到另一幅图像的上下文中,并保持对应区域不变。
3.2.1. Image Interpolation
图像插值的本质是对潜在编码进行语义插值:
z = λ z 1 + ( 1 − λ ) z 2 z = \lambda z_1 + (1-\lambda)z_2 z=λz1+(1−λ)z2
显然,这种插值产生的语义变换是连续的。文中将之前的 SOTA:Image2StyleGAN 和作者提出的 in-domain inversion 方法进行了比较,如下图所示,显然作者提出的方法产生的人脸图像更加的平滑,产生的塔图像更加的清晰也没有那么多的伪影。
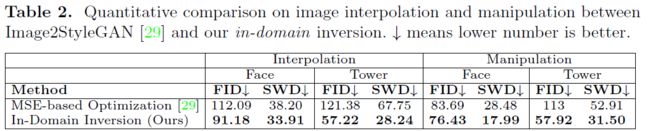
定量分析结果如下表所示,新方法的效果远远超过了之前的SOTA方法:
3.2.2. Semantic Manipulation
从 InterFaceGAN中可得知,二元语义之间存在一边界,详细介绍可见链接。重点是可以利用线性变换来对潜码进行处理。即:
x e d i t = G ( z i n v + α n ) x^{edit}=G(z^{inv}+\alpha n) xedit=G(zinv+αn)
这里的 n n n 其实就是潜在空间中特定语义所对应的法向量,具体是通过 SVM 对样本进行分类来得到对应的边界,然后就能得到一法向量,再对其归一化便得到了 n n n。而 α \alpha α 便是操纵的程度。换句话说,如果潜在代码向这个方向移动,则输出图像中包含的语义应该相应地有所变化。
首先看对人脸的定性分析,如上图所示。Image2StyleGAN 在操纵眼镜属性时并没有成功添加眼镜,反而影响了头发,而作者提供的方法则成功了。Image2StyleGAN 处理后女演员的脖子变得较模糊。
再看对塔的定性分析,如上图所示,作者提出的 in-domain 方法在减少或增加语义上,产生的效果都超过了基于 MSE 优化的方法。这里还有一个有趣的现象,在上图的最后一行,in-domain 方法产生的结果忽略了红色的巴士,这很好的说明了我们模型的语义性,即巴士这一对象不在塔合成模型的语义域中,所以不会生成它。
定量分析结果如下表所示,从所有的评估指标来看作者提出的方法都优于 Image2StyleGAN:
3.2.3. Semantic Diffusion
语义扩散的目标是将目标图中最具代表性的区域扩散到另一幅图像的上下文中。即融合结果在适应上下文变化的同时还能保持目标图像的特征不变。

上图展示了一些成功语义扩散的效果图,可以看到该算法较好地保持了目标人脸的身份,即图像的中心区域同目标图像完全相同,而且合理地融合了不同的环境。

为了更好的理解语义扩散,文中还展示了这一操作的中间结果,如上图所示。进行语义扩散的实现步骤如下所示:
-
从目标图像中crop出所需要的部分,将这部分patch粘贴到对应的上下文图像上。
-
将粘贴后的图像输入
In-Domain编码器中得到潜在编码,便完成了潜在编码的初始化。 -
使用 Masked Optimization 对潜在编码进行refine,即只使用目标图像的前景区域进行重构损失 L = ∣ ∣ M a s k ( x ) − M a s k ( G ( z ) ) ∣ ∣ 2 + λ 3 ∣ ∣ F ( M a s k ( x ) ) − F ( M a s k ( G ( z ) ) ) ∣ ∣ 2 L=||Mask(x)-Mask(G(z))||_2+\lambda_3||F(Mask(x))-F(Mask(G(z)))||_2 L=∣∣Mask(x)−Mask(G(z))∣∣2+λ3∣∣F(Mask(x))−F(Mask(G(z)))∣∣2 的计算:
-
x x x 是真实图像
-
z z z 是前一阶段得到的潜码
-
这里的 M a s k ( ⋅ ) Mask(\cdot) Mask(⋅) 指仅保留patch中的内容,其他位置上像素的值则用 0 0 0 填充。
-
-
从上图的中间结果可得知如下三点:
In-Domain编码器的输出总是会重建一个有意义的脸,并保持大多数语义的输入(例如,性别和头发)。这是因为我们的编码器产生的所有编码都在语义域内。- 掩码优化这一方法能够保留目标人脸的身份信息,并进一步将其风格(如肤色)运用到周围环境中,实现无缝融合。其不改变中间 patch的内容,仅仅影响从编码器初始化所继承的上下文样式(例如发型)。换句话说,只使用前景patch作为参考,周围环境将自编码器初始化开始自适应地改变
Image2StyleGAN在语义扩散任务中无法生成语义上有意义的脸部(脸部边界不平滑),因为其只关注像素值而不在意语义信息。

影响语义扩散任务的一个重要因素是 patch 的大小。作者做了一系列大小的实验,实验结果如上图所示。显然,patch块越大,身份信息保存的更好。
3.3. 消融实验

本文在这一部分对 in-domain inversion 进行了分析。即通过更改 λ 4 \lambda_4 λ4 的取值来研究 Domain-Guided 编码器在优化过程中起到的作用。
上图便是 λ 4 = 0 , 2 , 40 \lambda_4=0,2,40 λ4=0,2,40 所产生的效果:重构图像的质量和编辑图像的质量之间的权衡。**较大的 λ 4 \lambda_4 λ4 会使优化偏向于域约束,从而使得得到的潜在编码在语义上更有意义。不过过大的代价是目标图像不能理想地恢复每个像素上的值。**因此,实验中 λ 4 = 2 \lambda_4=2 λ4=2。