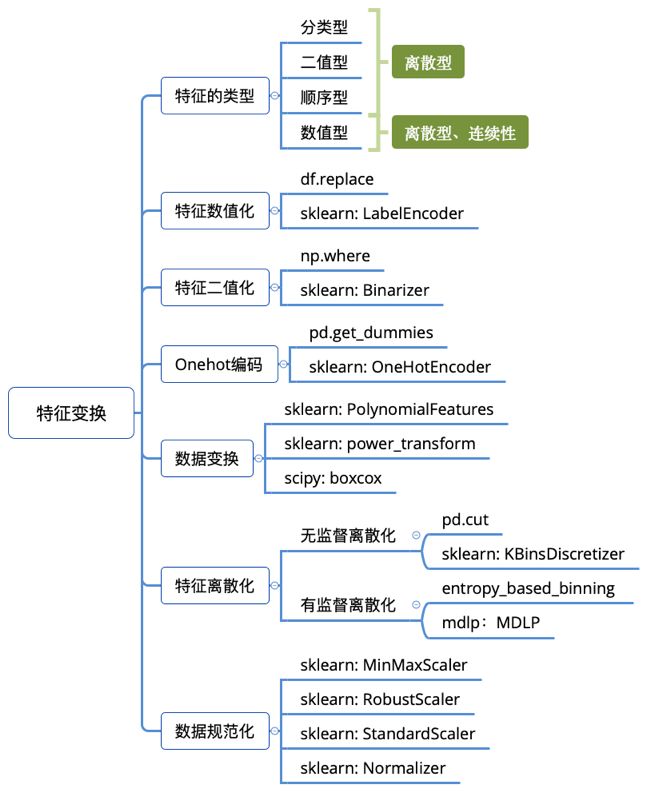
2.2 特征工程 - 特征变换
特征工程 - 特征变换
案例1:特征二值化 – 图像二值化
下载cv2
!pip install --upgrade pip
!pip install opencv-python
下载图片
!wget http://pic1.win4000.com/wallpaper/2018-12-10/5c0df6d577576.jpg
!cp 5c0df6d577576.jpg nvshen.jpg
Jupyter中显示图片
%matplotlibatplotlib inline
import matplotlib.pyplot as plt
import cv2
def show_img(img):
if len(img.shape) == 3:
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])
plt.imshow(img)
else:
plt.imshow(img, cmap='gray')
plt.axis("off")
plt.show()
image = cv2.imread("nvshen.jpg")
show_img(image)

进行灰度化处理
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
show_img(gray_image)

二值化操作
ret,thr = cv2.threshold(gray_image, 127, 255, cv2.THRESH_BINARY)
show_img(thr)

案例2:数据变化 – Box-cox
Box-Cox变换属于广义幂变换
加载数据集
import pandas as pd
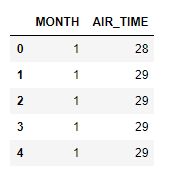
df = pd.read_csv('./DataSet/boxcox/sample_data.csv')
df.head()
数据可视化 – 直方图
%matplotlib inline
import matplotlib.pyplot as plt
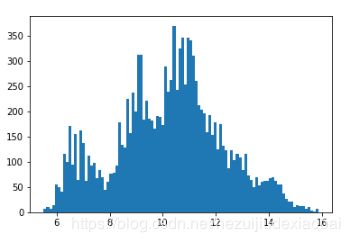
h = plt.hist(df['AIR_TIME'], bins=100)

非正态 -> 正态分布 – scipy
from scipy import stats
import numpy as np
scipy_box_cox = stats.boxcox(np.asarray(df['AIR_TIME'].values))[0]
plt.hist(scipy_box_cox, bins=100)
非正态 -> 正态分布 – sklearn
from sklearn.preprocessing import power_transform
sklearn_box_cox = power_transform(df[['AIR_TIME']], method='box-cox')
plt.hist(sklearn_box_cox, bins=100)

案例3 特征离散化
使用鸢尾花数据集
加载数据集
import numpy as np
from sklearn.datasets import load_iris
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
iris = load_iris()
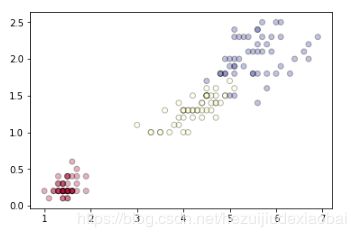
显示原始数据的分布情况
X = iris.data
y = iris.target
X = X[:, [2, 3]]
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.3, cmap=plt.cm.RdYlBu, edgecolor='black')
对数据离散化 && 显示分布
Xd = KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform').fit_transform(X)
plt.scatter(Xd[:, 0], Xd[:, 1], c=y, cmap=plt.cm.RdYlBu, edgecolor='black')

未离散化 Vs 离散化 (可视化)
import matplotlib.pyplot as plt
fig = plt.figure()
fig.add_subplot(1, 2 ,1)
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.3, cmap=plt.cm.RdYlBu, edgecolor='black')
fig.add_subplot(1, 2 ,2)
plt.scatter(Xd[:, 0], Xd[:, 1], c=y, cmap=plt.cm.RdYlBu, edgecolor='black')
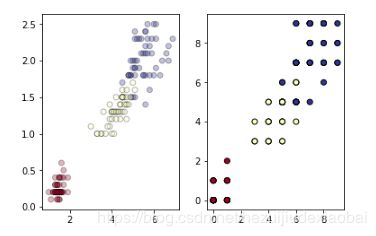
未离散化 Vs 离散化 (决策树&交叉验证)
dtc = DecisionTreeClassifier(random_state=0)
# 评估未离散化
score1 = cross_val_score(dtc, X, y, cv=5)
print('未离散化:', 'mean:', np.mean(score1), '\tstd:', np.std(score1))
# 评估离散化
score2 = cross_val_score(dtc, Xd, y, cv=5)
print('离散化:', 'mean:', np.mean(score2), '\tstd:', np.std(score2))
![]()
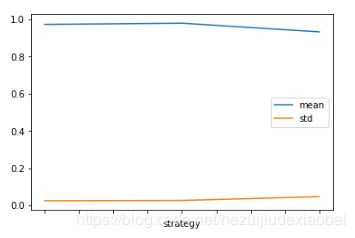
离散化策略大比拼#1
strategys = {'uniform', 'quantile', 'kmeans'}
for strategy in strategys:
km = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy=strategy).fit_transform(X)
s = cross_val_score(dtc, km, y, cv=5)
print(strategy, 'mean:', np.mean(s),'\tstd:', np.std(s))

离散化策略大比拼#2
vs = pd.DataFrame()
strategys = {'uniform', 'quantile', 'kmeans'}
for strategy in strategys:
km = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy=strategy).fit_transform(X)
s = cross_val_score(dtc, km, y, cv=5)
vs_ = pd.DataFrame([(strategy,np.mean(s), np.std(s))]) #行数据
vs = pd.concat([vs, vs_], axis=0)
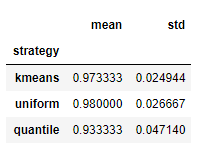
vs

处理数据#1
vs.columns = ['strategy', 'mean', 'std'] #设置列标签
vs.reset_index(drop=True, inplace=True) #重置索引index
vs

处理数据#2
vs = vs.set_index('strategy') #设置strategy为索引index
vs
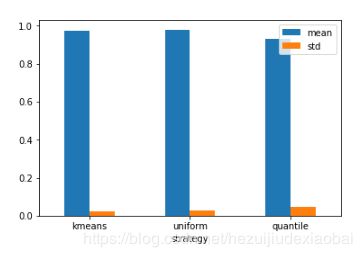
可视化#1
vs.plot.bar(rot=0)
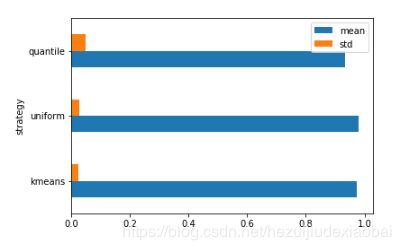
可视化#2
vs.plot.barh()
可视化#3
vs.plot.line()
案例4 数据规范化
读取数据集“/winemag/wine_data.csv”的前三个特征(“Class_label”“Alcohol”“Malic_acid”),
并对特征“Alcohol”“Malic_acid”的数据分别进行标准化和最小最大区间化操作,
然后用图示的方式比较原始数据和规范化之后的数据分布。
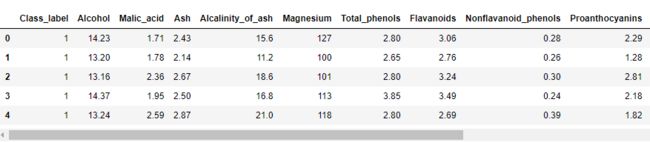
加载数据集
加载数据#1
import pandas as pd
df = pd.read_csv('./DataSet/winemag/wine_data.csv')
df.head()
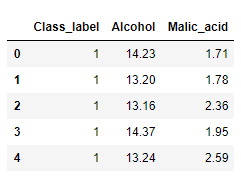
加载数据#2
import pandas as pd
df = pd.read_csv('./DataSet/winemag/wine_data.csv', usecols=[0,1,2])
df.head()
标椎化 && 区间化
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
# 标准化
std_scaler = StandardScaler()
df_std = std_scaler.fit_transform(df[['Alcohol', 'Malic_acid']])
# 区间化
mm_scaler = MinMaxScaler()
df_mm = mm_scaler.fit_transform(df[['Alcohol', 'Malic_acid']])
可视化数据分布
plt.figure(figsize=(10, 8))
plt.scatter(df['Alcohol'], df['Malic_acid'], color='green', label='input scale', alpha=0.5) #原始数据
plt.scatter(df_std[:,0], df_std[:,1], color='red', label='Standardized', alpha=0.3) #标准化
plt.scatter(df_mm[:,0], df_mm[:,1], color='blue', label='min-max scaled', alpha=0.3) #区间化
plt.title('Alcohol and Malic Acid content of the wine dataset')
plt.xlabel('Alcohol')
plt.ylabel('Malic Acid')
plt.legend(loc='upper left')
plt.grid()
plt.tight_layout() #

参考资料
plt.tight_layout()