helm学习笔记
helm学习笔记
安装helm
wget https://storage.googleapis.com/kubernetes-helm/helm-v2.13.1-linux-amd64.tar.gz
tar -zxf helm-v2.13.1-linux-amd64.tar.gz
mv linux-amd64 helm2.13.1
mv helm2.13.1 /usr/local/
cd /usr/local/helm2.13.1/
cp helm /usr/local/bin/
chmod a+x /usr/local/bin/helm
cat > rbca.yml <此时kubectl get pod -n kube-system,查看pod时,会显示tiller创建失败,原因是docker镜像是,在国内下载不到。故下载好后docker load -i到images中。之后就可以看到tiller启动成功了。helm-tiller.tar 下载地址:https://pan.baidu.com/s/1JV1mEqz35o-1Skj1ETv2nQ 提取码: 9vcc
docker load -i helm-tiller.tar
kubectl get pod -n kube-system
helm hello word
cat > ./Chart.yaml < templates/deployment.yml < templates/service.yml < 实现效果:
[root@k8s-master01 hello-word]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-world-867d967d7d-bng8x 1/1 Running 0 2m29s
[root@k8s-master01 hello-word]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world NodePort 10.106.75.28 80:30607/TCP 3m15s
kubernetes ClusterIP 10.96.0.1 443/TCP 10d
[root@k8s-master01 hello-word]# helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
gangly-billygoat 1 Tue Feb 18 11:19:15 2020 DEPLOYED hello-world-1.0.0 default
[root@k8s-master01 hello-word]# helm status gangly-billygoat
LAST DEPLOYED: Tue Feb 18 11:26:23 2020
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
hello-world-867d967d7d-bng8x 1/1 Running 0 10m
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world NodePort 10.106.75.28 80:30607/TCP 10m
==> v1beta1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
hello-world 1/1 1 1 10m
修改yml后,需upgrade
helm upgrade gangly-billygoat .
查看历史版本
[root@k8s-master01 hello-word]# helm history gangly-billygoat
REVISION UPDATED STATUS CHART DESCRIPTION
1 Tue Feb 18 11:19:15 2020 SUPERSEDED hello-world-1.0.0 Install complete
2 Tue Feb 18 11:26:23 2020 DEPLOYED hello-world-1.0.0 Upgrade complete
浏览器访问http://192.168.183.21:30607/,可以得到Nginx页面。
删除release
[root@k8s-master01 hello-word]# helm delete gangly-billygoat
release "gangly-billygoat" deleted
[root@k8s-master01 hello-word]# helm list
[root@k8s-master01 hello-word]# helm ls --deleted
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
gangly-billygoat 2 Tue Feb 18 11:26:23 2020 DELETED hello-world-1.0.0 default
恢复删除release
[root@k8s-master01 ~]# helm rollback gangly-billygoat 2
Rollback was a success! Happy Helming!
[root@k8s-master01 ~]# helm list --deleted
[root@k8s-master01 ~]# helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
gangly-billygoat 3 Tue Feb 18 15:59:21 2020 DEPLOYED hello-world-1.0.0 default
变量使用,创建values.yaml,然后再templates/deployment.yml中引入values.yaml中的参数。之后需要修改image,只需修改values.yaml文件的内容
cat > values.yaml < templates/deployment.yml < 命令行参数指定
helm upgrade gangly-billygoat --set image.tag='v2' . #指定tag
helm upgrade gangly-billygoat --set image.repository='hub.hdj.com/privatelib/wangyanglinux' . #指定repository
helm upgrade gangly-billygoat --set image.repository='hub.hdj.com/privatelib/wangyanglinux' --set image.tag='v2' . #指定repository,同时指定tag
永久删除release,需要加–purge参数
[root@k8s-master01 hello-word]# helm delete --purge gangly-billygoat
release "gangly-billygoat" deleted
[root@k8s-master01 hello-word]# helm list
[root@k8s-master01 hello-word]# helm list --deleted
Debug,预生成
使用模板动态生成K8s资源清单,非常需要能提前预览生成的结果。使用–dry-run --debug 选项来打印出生成的清单文件内容,而不执行部署。
helm install . --dry-run --debug
helm dashboard
helm repo update #更新helm repo
helm fetch stable/kubernetes-dashboard #下载kubernetes-dashboard
tar -zxf kubernetes-dashboard-1.10.1.tgz
cd > kubernetes-dashboard <此时需要用到镜像:k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1,国内直接下载不到,附上下载好的包dashboard.tar:https://pan.baidu.com/s/1JV1mEqz35o-1Skj1ETv2nQ 提取码: 9vcc,下载后上传至每个节点,导入docker的images中。
docker load -i dashboard.tar
最终效果:
[root@k8s-master01 kubernetes-dashboard]# kubectl get svc -n kube-system |grep dashboard
kubernetes-dashboard NodePort 10.108.167.165 443:30310/TCP 15m
[root@k8s-master01 kubernetes-dashboard]# kubectl get svc -n kube-system |grep dashboard
kubernetes-dashboard ClusterIP 10.108.167.165 443/TCP 15m
修改svc kubernetes-dashboard ,类型改为NodePort
kubectl edit svc kubernetes-dashboard -n kube-system
之后效果:
[root@k8s-master01 kubernetes-dashboard]# kubectl get svc -n kube-system |grep dashboard
kubernetes-dashboard NodePort 10.108.167.165 443:30310/TCP 18m
此时可以使用火狐浏览器打开地址:https://192.168.183.10:30310/访问到dashboard页面。此时,用Chrome浏览器打开,提示无法进入,需要导入kubernetes的ca证书 /etc/kubernetes/pki/ca.crt。用火狐可以直接打开。
打开之后,提示需要配置Kubeconfig或者token。Kubeconfig为~/.kube/config。
获取token:
[root@k8s-master01 kubernetes-dashboard]# kubectl -n kube-system get secret | grep kubernetes-dashboard-token #获取kubernetes-dashboard-token的secret名
kubernetes-dashboard-token-tcvx6 kubernetes.io/service-account-token 3 21m
[root@k8s-master01 kubernetes-dashboard]# kubectl -n kube-system describe secret kubernetes-dashboard-token-tcvx6 #获取token
Name: kubernetes-dashboard-token-tcvx6
Namespace: kube-system
Labels:
Annotations: kubernetes.io/service-account.name: kubernetes-dashboard
kubernetes.io/service-account.uid: 6d1ba92b-5dd4-4209-bfb9-bcca96f2fe02
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 11 bytes
token: eyJhbMwZXOPixx......040wDAvu6vg #这个token为我们要找的
之后可以进入dashboard页面中。
helm 安装 prometheus
需要安装的image:https://pan.baidu.com/s/1JV1mEqz35o-1Skj1ETv2nQ 提取码: 9vcc,上传prometheus.tar.gz,导入所有的tar。
下载prometheus:
git clone https://github.com/coreos/kube-prometheus.git
cd kube-prometheus/manifests/
修改配置grafana-service.yaml 、prometheus-service.yaml、alertmanager-service.yaml。
[root@k8s-master01 manifests]# cat alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort #增加
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30300 #增加
selector:
alertmanager: main
app: alertmanager
sessionAffinity: ClientIP
[root@k8s-master01 manifests]# cat grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort #增加
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100 #增加
selector:
app: grafana
[root@k8s-master01 manifests]# cat prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort #增加
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30200 #增加
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
kubectl create namespace monitoring
kubectl apply -f . #需要多执行几次
期间有些image会升级至新的版本,可以describe pod,查看image镜像地址,将 quay.io换成quay.mirrors.ustc.edu.cn,之后再改tag即可。列如,我安装镜像是quay.io/coreos/kube-state-metrics:v1.7.1,但是describe查看后发现需要quay.io/coreos/kube-state-metrics:v1.9.4,我先获取到quay.mirrors.ustc.edu.cn/coreos/kube-state-metrics:v1.9.4,然后再改成quay.io/coreos/kube-state-metrics:v1.9.4,操作如下:
[root@k8s-node01 prometheus]# docker pull quay.mirrors.ustc.edu.cn/coreos/kube-state-metrics:v1.9.4
v1.9.4: Pulling from coreos/kube-state-metrics
e8d8785a314f: Pull complete
59555d1fe31c: Pull complete
Digest: sha256:0574408a601f029ce325c96f1c4650284ab687f269890fa00abc9d50232bf745
Status: Downloaded newer image for quay.mirrors.ustc.edu.cn/coreos/kube-state-metrics:v1.9.4
quay.mirrors.ustc.edu.cn/coreos/kube-state-metrics:v1.9.4
[root@k8s-node01 prometheus]# docker images|grep kube-state-metrics
quay.mirrors.ustc.edu.cn/coreos/kube-state-metrics v1.9.4 3eab960b6ee2 2 weeks ago 32.8MB
[root@k8s-node01 prometheus]# docker tag quay.mirrors.ustc.edu.cn/coreos/kube-state-metrics:v1.9.4 quay.io/coreos/kube-state-metrics:v1.9.4
[root@k8s-node01 prometheus]# docker save -o quay.io/coreos/kube-state-metrics:v1.9.4 kube-state-metrics.tar #导出image,然后scp到其他节点中,docker load -i 导入。
最终效果:打开http://192.168.183.10:30200,可以看到:

在Expression中输入下面表达式,可以查看相关参数。
sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ) )
访问grafana地址:http://192.168.183.10:30100,用户名密码都是admin。第一次进入需要修改默认密码。输入111111进入。
进入:Configuration -> Data Sources ,点击prometheus。点击test,测试,提示成功。
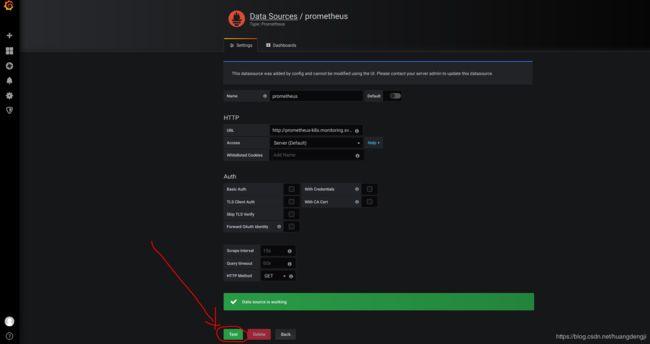
点击dashboard

import所有。

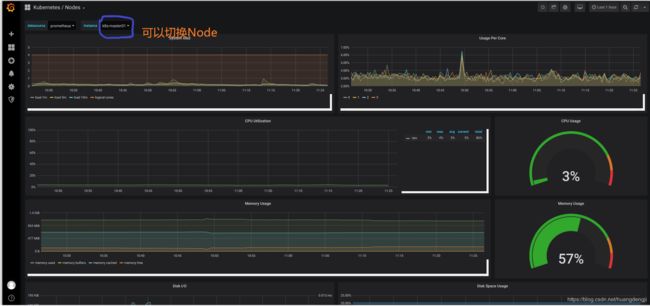
进入:Dashboard -> Manager ,点击Nodes。可以看到Node相关参数。
hpa 实现
上传Google的镜像,然后启动它。hpa-example.tar 下载地址:https://pan.baidu.com/s/1JV1mEqz35o-1Skj1ETv2nQ 提取码: 9vcc
docker load -i hpa-example.tar
kubectl run php-apache --image=gcr.io/google_containers/hpa-example --requests=cup=200m --expose --port=80
创建pha
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10 #创建pha,CPU达到50%时,扩容,最多10个,最少1个
kubectl get pha #查看pha
新建窗口,启动busybox测试:
[root@k8s-master01 ~]# kubectl run -i --tty load-generator --image=busybox /bin/sh #启动busybox
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://php-apache.default.svc.cluster.local;done; #循环访问php-apache
可以看到随着时间的增长,php-apache pod的数据在增加。最多10个,刚开始是1个。
[root@k8s-master01 pha]# kubectl get pod | grep php-apache | wc
10 50 724
[root@k8s-master01 pha]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 10 39m
然后关闭busybox,等待一会再看,pod的数量就慢慢变少了。