【论文翻译】Mastering the game of Go with deep neural networks and tree search( 用深度神经网络和树搜索实现围棋游戏)
【原文作者及来源:Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search.[J]. Nature, 2016, 529(7587):484-489.】
【此译文由COCO主要完成,对MarkDown编辑器正在熟悉过程中,因此,文章中相关公式存在问题,请见谅】
【原文】The game of Go has long been viewed as the most challenging of classic games for artificial intelligence owing to its enormous search space and the difficulty of evaluating board positions and moves. Here we introduce a new approach to computer Go that uses ‘value networks’ to evaluate board positions and ‘policy networks’ to select moves. These deep neural networks are trained by a novel combination of supervised learning from human expert games, and reinforcement learning from games of self-play. Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte Carlo simulation with value and policy networks. Using this search algorithm, our program AlphaGo achieved a 99.8% winning rate against other Go programs, and defeated the human European Go champion by 5 games to 0. This is the first time that a computer program has defeated a human professional player in the full-sized game of Go, a feat previously thought to be at least a decade away.
【翻译】围棋因其庞大的搜索空间以及评估棋局和落子的难度,一直被认为是人工智能领域中最具挑战性的经典游戏。在这里,我们引入了一种新的计算围棋的方法,它使用“价值网络”来评估棋局,利用“策略网络”来选择落子位置。对围棋高手下过的棋局进行监督学习,通过自我博弈的棋局进行强化学习,并将两者结合起来训练深度神经网络。没有任何前向搜索,深度神经网络通过模拟成千上万的随机自我博弈,达到了国家最先进的蒙特卡洛树搜索程序的水准。我们也会介绍一种新的搜索算法,这个算法将蒙特卡仿真和价值网络、策略网络结合起来。通过这个搜索算法,相比于其他的围棋程序,AlphaGo可以达到99.8%的胜算率,并以5比0在欧洲击败人类围棋选手。这是第一次在全尺寸围棋中,一个计算机程序击败了人类职业选手。而这一壮举在以前被认为至少需要十年的时间。
【原文】All games of perfect information have an optimal value function ![]() which determines the outcome of the game, from every board position or state
which determines the outcome of the game, from every board position or state ![]() , under perfect play by all players. These games may be solved by recursively computing the optimal value function in a search tree containing approximately
, under perfect play by all players. These games may be solved by recursively computing the optimal value function in a search tree containing approximately ![]() possible sequences of moves, where b is the game’s breadth (number of legal moves per position) and d is its depth (game length). In large games, such as chess (b ≈ 35, d ≈ 80) and especially Go (b ≈ 250, d ≈ 150), exhaustive search is infeasible , but the effective search space can be reduced by two general principles . First, the depth of the search may be reduced by position evaluation: truncating the search tree at state
possible sequences of moves, where b is the game’s breadth (number of legal moves per position) and d is its depth (game length). In large games, such as chess (b ≈ 35, d ≈ 80) and especially Go (b ≈ 250, d ≈ 150), exhaustive search is infeasible , but the effective search space can be reduced by two general principles . First, the depth of the search may be reduced by position evaluation: truncating the search tree at state![]() and replacing the subtree below s by an approximate value function
and replacing the subtree below s by an approximate value function ![]() that predicts the outcome from state
that predicts the outcome from state![]() . This approach has led to superhuman performance in chess, checkers and othello, but it was believed to be intractable in Go due to the complexity of the game. Second, the breadth of the search may be reduced by sampling actions from a policy
. This approach has led to superhuman performance in chess, checkers and othello, but it was believed to be intractable in Go due to the complexity of the game. Second, the breadth of the search may be reduced by sampling actions from a policy ![]() that is a probability distribution over possible moves
that is a probability distribution over possible moves ![]() in position
in position ![]() . For example, Monte Carlo rollouts search to maximum depth without branching at all, by sampling long sequences of actions for both players from a policy
. For example, Monte Carlo rollouts search to maximum depth without branching at all, by sampling long sequences of actions for both players from a policy ![]() . Averaging over such rollouts can provide an effective position evaluation, achieving superhuman performance in backgammon and Scrabble, and weak amateur level play in Go.
. Averaging over such rollouts can provide an effective position evaluation, achieving superhuman performance in backgammon and Scrabble, and weak amateur level play in Go.
【翻译】当每个棋手都发挥最佳时,完全信息博弈有一个最优值函数![]() ,它决定了每个棋局或者状态
,它决定了每个棋局或者状态 ![]() 之后博弈结果的好坏。这些游戏在包含大约
之后博弈结果的好坏。这些游戏在包含大约![]() 个可能的移动序列的搜索树中,通过递归计算最优值函数。其中b 是游戏的宽度(每次下棋合法的落子个数), d是它的深度(博弈的步数长度)。在国际象棋中, b≈35, d≈80, 但是在围棋中,b ≈250,d ≈150,因此穷举搜索是不可行的,但可以根据两个大体原则减小有效搜索空间。第一个原则是,搜索的深度可以通过棋局评估减少: 在状态
个可能的移动序列的搜索树中,通过递归计算最优值函数。其中b 是游戏的宽度(每次下棋合法的落子个数), d是它的深度(博弈的步数长度)。在国际象棋中, b≈35, d≈80, 但是在围棋中,b ≈250,d ≈150,因此穷举搜索是不可行的,但可以根据两个大体原则减小有效搜索空间。第一个原则是,搜索的深度可以通过棋局评估减少: 在状态 ![]() 时对搜索树进行剪枝,并且通过一个近似的估值函数
时对搜索树进行剪枝,并且通过一个近似的估值函数![]() 来替换
来替换  下面的子树,用这个近似的估值函数预测状态s之后的对弈结果。这种方法在国际象棋、跳棋、黑白棋中都获得了超人的表现。但由于围棋的复杂性,这种方法仍旧难以应付。第二个原则是,搜索的广度可以通过策略
下面的子树,用这个近似的估值函数预测状态s之后的对弈结果。这种方法在国际象棋、跳棋、黑白棋中都获得了超人的表现。但由于围棋的复杂性,这种方法仍旧难以应付。第二个原则是,搜索的广度可以通过策略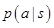 (在位置
(在位置 ![]() 处可能下棋走子
处可能下棋走子![]() 的概率分布)来减少。例如,比如蒙特卡洛走子方法搜索到最大深度时候根本不使用分枝界定法,它通过策略 p 对双方棋手的一系列下棋走法进行采样。计算这些走子的平均数就可以产生一个有效的棋局评估,这在五子棋和拼字游戏中实现了超人的表现,并且能在围棋中达到业余段位水平。
的概率分布)来减少。例如,比如蒙特卡洛走子方法搜索到最大深度时候根本不使用分枝界定法,它通过策略 p 对双方棋手的一系列下棋走法进行采样。计算这些走子的平均数就可以产生一个有效的棋局评估,这在五子棋和拼字游戏中实现了超人的表现,并且能在围棋中达到业余段位水平。
【原文】Rollout: In backgammon parlance, the expected value of a position is known as the "equity" of the position, and estimating the equity by Monte-Carlo sampling is known as performing a "rollout" .
【翻译】Rollout:在西洋双陆棋中,每一个位置的期望值就叫做这个位置的"equity",通过蒙特卡洛采样对"equity"进行估计就叫做进行"rollout"。论文中一般称为快速走棋。
【原文】Monte Carlo tree search (MCTS), uses Monte Carlo rollouts to estimate the value of each state in a search tree. As more simulations are executed, the search tree grows larger and the relevant values become more accurate. The policy used to select actions during search is also improved over time, by selecting children with higher values. Asymptotically, this policy converges to optimal play, and the evaluations converge to the optimal value function. The strongest current Go programs are based on MCTS, enhanced by policies that are trained to predict human expert moves. These policies are used to narrow the search to a beam of high-probability actions, and to sample actions during rollouts. This approach has achieved strong amateur play. However, prior work has been limited to shallow policies or value functions based on a linear combination of input features.
【翻译】蒙特卡洛树搜索,利用Monte Carlo对搜索树中的每个状态的价值进行评估。模拟次数越多,搜索树就越大,相关的估值也变得更加精确。在搜索过程中用于选择下棋动作的策略,也随着时间的推移有所改进,这种改进也就是选择具有更高价值的子树。渐渐地,该策略收敛于最优下法,并且评估也收敛到最优值函数。目前最强的围棋程序是基于MCTS的,通过训练来预测人类棋手的落子,从而越来越强。这些策略过去是用来缩小搜索范围的,使搜索范围成为一束高概率的下棋动作,并且用来在rollout中对动作进行采样。这种方法达到了较好的业余段位水平,但是,以前的工作仅局限于基于对输入特征进行线性组合的估值函数或者浅层策略的限制。
【原文】Recently, deep convolutional neural networks have achieved unprecedented performance in visual domains: for example, image classification, face recognition, and playing Atari games. They use many layers of neurons, each arranged in overlapping tiles, to construct increasingly abstract, localized representations of an image. We employ a similar architecture for the game of Go. We pass in the board position as a 19 × 19 image and use convolutional layers to construct a representation of the position. We use these neural networks to reduce the effective depth and breadth of the search tree: evaluating positions using a value network, and sampling actions using a policy network. We train the neural networks using a pipeline consisting of several stages of machine learning (Fig. 1). We begin by training a supervised learning (SL) policy network ![]() directly from expert human moves. This provides fast, efficient learning updates with immediate feedback and high-quality gradients. Similar to prior work, we also train a fast policy
directly from expert human moves. This provides fast, efficient learning updates with immediate feedback and high-quality gradients. Similar to prior work, we also train a fast policy ![]() that can rapidly sample actions during rollouts. Next, we train a reinforcement learning (RL) policy network that improves the SL policy network
that can rapidly sample actions during rollouts. Next, we train a reinforcement learning (RL) policy network that improves the SL policy network ![]() by optimizing the final outcome of games of self-play. This adjusts the policy towards the correct goal of winning games, rather than maximizing predictive accuracy. Finally, we train a value network
by optimizing the final outcome of games of self-play. This adjusts the policy towards the correct goal of winning games, rather than maximizing predictive accuracy. Finally, we train a value network ![]() that predicts the winner of games played by the RL policy network against itself. Our program AlphaGo efficiently combines the policy and value networks with MCTS.
that predicts the winner of games played by the RL policy network against itself. Our program AlphaGo efficiently combines the policy and value networks with MCTS.
【翻译】近日,深度卷积神经网络在视觉领域取得了前所未有的成绩,例如图像分类、人脸识别和Atari游戏。它们使用许多层神经元,层与层之间像瓦片一样排列重叠在一起,来构造逐渐抽象的、局部的图像表示。我们采用类似的架构来进行围棋游戏。我们将棋局看成一个19×19的图像,并且使用卷积层来表示棋局。我们使用神经网络来减少搜索树的有效深度和广度:使用价值网络评估棋局;使用策略网络来对落子动作进行取样。我们使用由机器学习的几个阶段组成的训练流程来训练神经网络(图1)。我们首先直接利用人类棋手的落子训练监督学习(SL)策略网络![]() 。这通过即时的反馈和高质量的梯度,提供了快速、高效的学习更新。与以前的工作类似,我们还训练了快速走棋策略网络
。这通过即时的反馈和高质量的梯度,提供了快速、高效的学习更新。与以前的工作类似,我们还训练了快速走棋策略网络 ![]() ,使其能在rollout中迅速对动作进行采样。接下来,我们训练强化学习(RL)策略网络
,使其能在rollout中迅速对动作进行采样。接下来,我们训练强化学习(RL)策略网络![]() ,通过优化自我博弈的最终结果,来改善SL策略网络的性能。我们以是否能够赢得比赛为标准,而不是以最大限度地提高预测精度为标准对策略进行调整。最后,我们训练一个价值网络
,通过优化自我博弈的最终结果,来改善SL策略网络的性能。我们以是否能够赢得比赛为标准,而不是以最大限度地提高预测精度为标准对策略进行调整。最后,我们训练一个价值网络![]() ,来预测通过训练过后的RL策略网进行自我博弈的结果。AlphaGo就是利用MCTS将上述策略网络和价值网络有效结合在一起的。
,来预测通过训练过后的RL策略网进行自我博弈的结果。AlphaGo就是利用MCTS将上述策略网络和价值网络有效结合在一起的。
【原文】Figure 1 | Neural network training pipeline andarchitecture.
【翻译】图1 神经网络训练流程图和结构
【原文】a. A fast rollout policy![]() and supervised learning (SL) policy network
and supervised learning (SL) policy network ![]() are trained to predict human expert moves in a data set ofpositions. A reinforcement learning (RL) policy network
are trained to predict human expert moves in a data set ofpositions. A reinforcement learning (RL) policy network![]() is initialized to the SL policy network, and is then improvedby policy gradient learning to maximize the outcome (that is, winning moregames) against previous versions of the policy network. A new data set isgenerated by playing games of self-play with the RL policy network. Finally, avalue network
is initialized to the SL policy network, and is then improvedby policy gradient learning to maximize the outcome (that is, winning moregames) against previous versions of the policy network. A new data set isgenerated by playing games of self-play with the RL policy network. Finally, avalue network![]() is trained by regression to predict the expected outcome(that is, whether the current player wins) in positions from the self-play dataset.
is trained by regression to predict the expected outcome(that is, whether the current player wins) in positions from the self-play dataset.
【翻译】a.一个快速走子策略 ![]() 和监督学习SL策略网络
和监督学习SL策略网络![]() 来训练用于预测人类棋手在一些棋局数据集中的落子。强化学习(RL)策略网络
来训练用于预测人类棋手在一些棋局数据集中的落子。强化学习(RL)策略网络 ![]() 被初始化为SL策略网络,并且通过策略梯度学习来使结果与之前策略网络的版本相比最大化(也就是,赢得更多的比赛),进而使该网络得到改善,这样就会产生一个新的数据集合。通过结合RL策略网络进行自我对弈,最终通过回归训练,产生一个价值网络
被初始化为SL策略网络,并且通过策略梯度学习来使结果与之前策略网络的版本相比最大化(也就是,赢得更多的比赛),进而使该网络得到改善,这样就会产生一个新的数据集合。通过结合RL策略网络进行自我对弈,最终通过回归训练,产生一个价值网络![]() ,来预测自我博弈数据集中棋局的期望结果(也就是当前玩家是否能赢)
,来预测自我博弈数据集中棋局的期望结果(也就是当前玩家是否能赢)
【原文】b, Schematic representation of the neural network architecture used in AlphaGo. The policy network takes a representation of the board position s as its input, passes it through many convolutional layers with parameters σ (SL policy network) or ρ (RL policy network), and outputs a probability distribution ![]() or
or ![]() over legal moves a, represented by a probability map over the board. The value network similarly uses many convolutional layers with parameters θ, but outputs a scalar value
over legal moves a, represented by a probability map over the board. The value network similarly uses many convolutional layers with parameters θ, but outputs a scalar value ![]() that predicts the expected outcome in position s′.
that predicts the expected outcome in position s′.
【翻译】b, AlphaGo使用的神经网络体系结构示意图。策略网络将棋局的状态s作为输入,将它通过很多带有参数σ(SL策略网络)或者参数ρ(RL策略网络)的卷积层,输出一个合法下棋动作a的概率分布: ![]() 或者
或者 ![]() ,由棋盘的概率图表示。与之相似,价值网络使用很多参数为θ的卷积层,但是输出是一个标量值
,由棋盘的概率图表示。与之相似,价值网络使用很多参数为θ的卷积层,但是输出是一个标量值![]() ,它预测了棋局s′的期望结果。
,它预测了棋局s′的期望结果。
【原文】Supervised learning of policy networks
For the first stage of the training pipeline, we build on prior work on predicting expert moves in the game of Go using supervised learning. The SL policy network ![]() alternates between convolutional layers with weights
alternates between convolutional layers with weights ![]() , and rectifier nonlinearities. A final softmax layer outputs a probability distribution over all legal moves
, and rectifier nonlinearities. A final softmax layer outputs a probability distribution over all legal moves 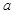 . The input
. The input ![]() to the policy network is a simple representation of the board state (see Extended Data Table 2). The policy network is trained on randomly sampled state-action pairs
to the policy network is a simple representation of the board state (see Extended Data Table 2). The policy network is trained on randomly sampled state-action pairs![]() , using stochastic gradient ascent to maximize the likelihood of the human move
, using stochastic gradient ascent to maximize the likelihood of the human move ![]() selected in state
selected in state ![]()

【翻译】策略网络的监督学习

扩展数据表2 神经网络的输入特征



The second stage of the training pipeline aims at improving the policy network by policy gradient reinforcement learning (RL). The RL policy network

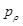 和随机选择先前一次迭代的策略网络进行博弈。通过从对手池中随机选取策略网络与之博弈,可以防止过拟合,从而使训练更稳定。我们使用一个奖励函数
和随机选择先前一次迭代的策略网络进行博弈。通过从对手池中随机选取策略网络与之博弈,可以防止过拟合,从而使训练更稳定。我们使用一个奖励函数
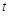 时,
时,
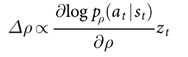
【原文】We evaluated the performance of the RL policy network in game play, sampling each move ![]() from its output probability distribution over actions. When played head-to-head, the RL policy network won more than 80% of games against the SL policy network. We also tested against the strongest open-source Go program, Pachi, a sophisticated Monte Carlo search program, ranked at 2 amateur dan on KGS, that executes 100,000 simulations per move. Using no search at all, the RL policy network won 85% of games against Pachi. In comparison, the previous state-of-the-art, based only on supervised learning of convolutional networks, won 11% of games against Pachi and 12% against a slightly weaker program, Fuego.
from its output probability distribution over actions. When played head-to-head, the RL policy network won more than 80% of games against the SL policy network. We also tested against the strongest open-source Go program, Pachi, a sophisticated Monte Carlo search program, ranked at 2 amateur dan on KGS, that executes 100,000 simulations per move. Using no search at all, the RL policy network won 85% of games against Pachi. In comparison, the previous state-of-the-art, based only on supervised learning of convolutional networks, won 11% of games against Pachi and 12% against a slightly weaker program, Fuego.
【翻译】我们评估了RL策略网络在游戏中的性能,从它输出的下棋动作的概率分布中,对每一下棋动作 ![]() 进行取样。当正面交锋时,RL策略网络相比于SL策略网络,赢得了超过80%的游戏。我们还测试了最强大的开源围棋程序Pachi。它是一个复杂的蒙特卡洛搜索程序,在KGS围棋服务器中业余段位第二,每次移动执行100000次模拟。RL策略网络在不使用搜索的情况下,相比于Pachi,胜率为85%。相比之下,先前最先进的、仅仅基于监督学习的卷积网络,相比于Pachi和较弱的程序Fuego,胜率为12%和11%。
进行取样。当正面交锋时,RL策略网络相比于SL策略网络,赢得了超过80%的游戏。我们还测试了最强大的开源围棋程序Pachi。它是一个复杂的蒙特卡洛搜索程序,在KGS围棋服务器中业余段位第二,每次移动执行100000次模拟。RL策略网络在不使用搜索的情况下,相比于Pachi,胜率为85%。相比之下,先前最先进的、仅仅基于监督学习的卷积网络,相比于Pachi和较弱的程序Fuego,胜率为12%和11%。
【原文】Reinforcement learning of value networks
The final stage of the training pipeline focuses on position evaluation, estimating a value function ![]() that predicts the outcome from position
that predicts the outcome from position ![]() of games played by using policy
of games played by using policy ![]() for both players.
for both players.
![]()
Ideally, we would like to know the optimal value function under perfect play![]() ; in practice, we instead estimate the value function
; in practice, we instead estimate the value function ![]() for our strongest policy, using the RL policy network
for our strongest policy, using the RL policy network ![]() . We approximate the value function using a value network
. We approximate the value function using a value network ![]() with weights
with weights ![]() , . This neural network has a similar architecture to the policy network, but outputs a single prediction instead of a probability distribution. We train the weights of the value network by regression on state-outcome pairs
, . This neural network has a similar architecture to the policy network, but outputs a single prediction instead of a probability distribution. We train the weights of the value network by regression on state-outcome pairs ![]() , using stochastic gradient descent to minimize the mean squared error (MSE) between the predicted value
, using stochastic gradient descent to minimize the mean squared error (MSE) between the predicted value![]() , and the corresponding outcome
, and the corresponding outcome ![]() .
.
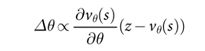
![]()
理想的情况是,我们想知道在完美下法时的最优价值函数 ![]() ;然而在现实中,我们利用当前最强大的RL策略网络
;然而在现实中,我们利用当前最强大的RL策略网络 ![]() 来对价值函数
来对价值函数 ![]() 做评估,并将
做评估,并将 ![]() 作为最佳策略。我们使用具有
作为最佳策略。我们使用具有![]() 权重的价值网络
权重的价值网络 ![]() 来近似表示价值函数,
来近似表示价值函数,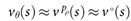 。该神经网络与策略网络具有相似的体系结构,但输出的不是概率分布,而是单一的预测值。我们通过对状态结果对
。该神经网络与策略网络具有相似的体系结构,但输出的不是概率分布,而是单一的预测值。我们通过对状态结果对 ![]() 进行回归来训练价值网络的权值,采用随机梯度下降使预测估值
进行回归来训练价值网络的权值,采用随机梯度下降使预测估值![]() 和相应的结局
和相应的结局 ![]() 之间的均方误差(MSE)达到最小化。
之间的均方误差(MSE)达到最小化。
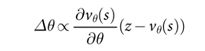
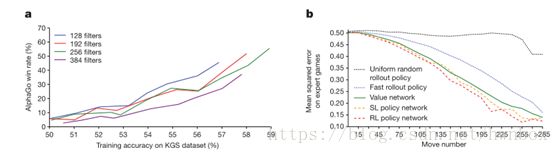
【原文】Figure 2 | Strength and accuracy of policy andvalue networks.
【翻译】图二价值网络和策略网络的健壮性和精确度
【原文】a, Plot showing the playing strength of policy networks as a function of their training accuracy. Policy networks with 128, 192, 256 and 384 convolutional filters per layer were evaluated periodically during training; the plot shows the winning rate of AlphaGo using that policy network against the match version of AlphaGo.
【翻译】a,图展示了策略网络的下棋能力随着训练精确度的函数。具有128、192、256和384个卷积核的策略网络在训练过程中被周期性评估;该图显示了AlphaGo使用策略网络的获胜概率随着不同精确度版本的变化。
【原文】b, Comparison of evaluation accuracy between the value network and rollouts with different policies. Positions and outcomes were sampled from human expert games. Each position was evaluated by a single forward pass of the value network![]() , or by the mean outcome of 100 rollouts, played out using either uniform random rollouts, the fast rollout policy
, or by the mean outcome of 100 rollouts, played out using either uniform random rollouts, the fast rollout policy ![]() , the SL policy network
, the SL policy network ![]() or the RL policy network
or the RL policy network![]() . The mean squared error between the predicted value and the actual game outcome is plotted against the stage of the game (how many moves had been played in the given position).
. The mean squared error between the predicted value and the actual game outcome is plotted against the stage of the game (how many moves had been played in the given position).
【翻译】b,价值网络与rollout相对于不同策略的评估精确度比较。棋局和最终结果是从人类专业棋手的博弈对局中取样的。每一个棋局都是由一个单独的向前传递的估值网络![]() 评估的,或者在包括使用正式的随机rollout、快速走棋网络
评估的,或者在包括使用正式的随机rollout、快速走棋网络![]() ,SL策略网络
,SL策略网络 ![]() 或者RL策略网络
或者RL策略网络![]() 进行playout后使用100次rollout 的平均结果进行评估。预测值和实际比赛结局之间的均方误差随着博弈的进行阶段的变化(博弈总共下了多少步)显示在了图中。
进行playout后使用100次rollout 的平均结果进行评估。预测值和实际比赛结局之间的均方误差随着博弈的进行阶段的变化(博弈总共下了多少步)显示在了图中。
【原文】Searching with policy and value networks
AlphaGo combines the policy and value networks in an MCTS algorithm (Fig. 3) that selects actions by lookahead search. Each edge ![]() of the search tree stores an action value
of the search tree stores an action value ![]() , visit count
, visit count ![]() ,and prior probability
,and prior probability ![]() . The tree is traversed by simulation (that is, descending the tree in complete games without backup), starting from the root state. At each time step
. The tree is traversed by simulation (that is, descending the tree in complete games without backup), starting from the root state. At each time step![]() of each simulation, an action
of each simulation, an action![]() is selected from state
is selected from state ![]()
![]()
so as to maximize action value plus a bonus
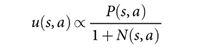
![]()
用来最大化动作价值与额外的奖励的和,额外的奖励为

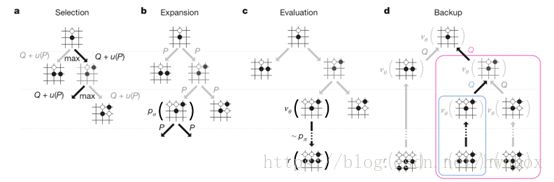
【原文】Figure 3 | Monte Carlo tree search in AlphaGo.
【翻译】 图三 AlphaGo中的蒙特卡洛树搜索
【原文】a,Each simulation traverses the tree by selecting the edge with maximum action value Q, plus a bonus u(P) that depends on a stored prior probability P for that edge.
b, The leaf node may be expanded; the new node is processed once by the policy network ![]() and the output probabilities are stored as prior probabilities P for each action.
and the output probabilities are stored as prior probabilities P for each action.
c, At the end of a simulation, the leaf node is evaluated in two ways: using the value network![]() ; and by running a rollout to the end of the game with the fast rollout policy
; and by running a rollout to the end of the game with the fast rollout policy![]() , then computing the winner with function r.
, then computing the winner with function r.
d, Action values Q are updated to track the mean value of all evaluations r(·) and v θ (·) in the subtree below that action.
【翻译】a, 每一次模拟遍历搜索树,通过下棋动作估值 Q加上一个额外奖励 u(P)(依赖于存储的该边的先验概率 P)之和来选择边 。
b,叶子结点可以被扩展。新节点通过策略网络![]() 被处理一次,并且输出概率存储为下棋动作的先验概率P。
被处理一次,并且输出概率存储为下棋动作的先验概率P。
c,在每次模拟最后,叶节点通过两种方法被评估:利用价值网络![]() ;利用rollout结合快速走棋策略网络
;利用rollout结合快速走棋策略网络![]() ,然后用函数r计算出赢家。
,然后用函数r计算出赢家。
d,下棋动作价值Q被更新,来追踪经过该边的所有的评价r(·) 的平均值和该落子动作子树的v θ (·) 。
【原文】that is proportional to the prior probability but decays with repeated visits to encourage exploration. When the traversal reaches a leaf node![]() at step
at step ![]() , the leaf node may be expanded. The leaf position
, the leaf node may be expanded. The leaf position ![]() is processed just once by the SL policy network
is processed just once by the SL policy network![]() . The output probabilities are stored as prior probabilities for each legal action
. The output probabilities are stored as prior probabilities for each legal action ,
, ![]() .The leaf node is evaluated in two very different ways: first, by the value network
.The leaf node is evaluated in two very different ways: first, by the value network![]() ; and second, by the outcome
; and second, by the outcome ![]() of a random rollout played out until terminal step T using the fast rollout policy p π ; these evaluations are combined, using a mixing parameter
of a random rollout played out until terminal step T using the fast rollout policy p π ; these evaluations are combined, using a mixing parameter ![]() , into a leaf evaluation
, into a leaf evaluation![]() .
.
【翻译】额外的奖励与先验概率成正相关,但与访问次数成负相关,这是为了鼓励更多的探索。当遍历在步骤 到达叶节点 ![]() 时,叶节点可以被扩展。叶节点的棋局仅通过SL策略网络
时,叶节点可以被扩展。叶节点的棋局仅通过SL策略网络 ![]() 进行了一次处理。输出的概率存储下来作为每一合法下法动作 a 的先验概率
进行了一次处理。输出的概率存储下来作为每一合法下法动作 a 的先验概率![]() :
:![]() 。叶节点以两种非常不同的方式进行评估:第一,通过价值网络
。叶节点以两种非常不同的方式进行评估:第一,通过价值网络  ;第二,通过一个采用快速走子策略
;第二,通过一个采用快速走子策略![]() 的随机rollout,rollout直到终点步骤T,产生的结果为
的随机rollout,rollout直到终点步骤T,产生的结果为 ![]() ,并用
,并用 ![]() 来进行评估;这两种评估相结合,通过混合参数
来进行评估;这两种评估相结合,通过混合参数![]() ,形成叶评价
,形成叶评价 ![]()
![]()
【原文】At the end of simulation, the action values and visit counts of all traversed edges are updated. Each edge accumulates the visit count and mean evaluation of all simulations passing through that edge
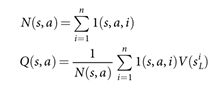
Where![]() is the leaf node from the
is the leaf node from the ![]() th simulation, and
th simulation, and ![]() indicates whether an edge
indicates whether an edge ![]() was traversed during the
was traversed during the ![]() th simulation. Once the search is complete, the algorithm chooses the most visited move from the root position. It is worth noting that the SL policy network
th simulation. Once the search is complete, the algorithm chooses the most visited move from the root position. It is worth noting that the SL policy network![]() performed better in AlphaGo than the stronger RL policy network
performed better in AlphaGo than the stronger RL policy network![]() , presumably because humans select a diverse beam of promising moves, whereas RL optimizes for the single best move. However, the value function derived from the stronger RL policy network performed better in AlphaGo than a value function derived from the SL policy network.
, presumably because humans select a diverse beam of promising moves, whereas RL optimizes for the single best move. However, the value function derived from the stronger RL policy network performed better in AlphaGo than a value function derived from the SL policy network.
【翻译】在模拟的结尾,对所有被遍历的边的落子动作价值和访问次数进行更新。每条边的访问次数进行累积,并且计算出通过该边的所有模拟的价值的平均值。

其中![]() 是第
是第![]() 次模拟的叶节点,
次模拟的叶节点, ![]() 表示在第
表示在第![]() 次模拟期间边
次模拟期间边 ![]() 是否被遍历。一旦搜索完成,该算法从根开始选择访问次数最多的节点。值得注意的是,AlphaGo利用SL策略网络
是否被遍历。一旦搜索完成,该算法从根开始选择访问次数最多的节点。值得注意的是,AlphaGo利用SL策略网络 ![]() 时,比更强的RL策略网络
时,比更强的RL策略网络![]() 表现更好,大概是因为在SL中,人类从一束前景很好的下棋走法中选择了变化较多的走法,然而 RL的最优下棋走法过于单一。但是,AlphaGo利用起源于强大的RL策略网络的价值函数,比利用起源于SL策略网络的价值函数表现更好。
表现更好,大概是因为在SL中,人类从一束前景很好的下棋走法中选择了变化较多的走法,然而 RL的最优下棋走法过于单一。但是,AlphaGo利用起源于强大的RL策略网络的价值函数,比利用起源于SL策略网络的价值函数表现更好。
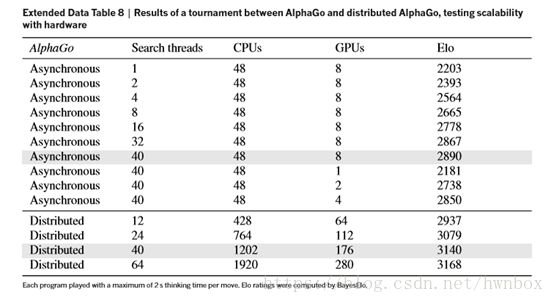
【原文】Evaluating policy and value networks requires several orders of magnitude more computation than traditional search heuristics. To efficiently combine MCTS with deep neural networks, AlphaGo uses an asynchronous multi-threaded search that executes simulations on CPUs, and computes policy and value networks in parallel on GPUs.The final version of AlphaGo used 40 search threads, 48 CPUs, and 8 GPUs. We also implemented a distributed version of AlphaGo thatexploited multiple machines, 40 search threads, 1,202 CPUs and 176 GPUs. The Methods section provides full details of asynchronous and distributed MCTS.
【翻译】对策略网络和价值网络的评估比传统的启发式搜索在计算上多几个数量级。为了把蒙特卡洛和深度神经网络有效地结合起来,AlphaGo在很多CPU上采用异步多线程搜索进行模拟,并在并行的GPU上计算策略和价值网络。AlphaGo最终版本使用40个搜索线程,48个CPU和8个GPU。我们还实现了一个分布式版本的AlphaGo,它利用多台计算机,40个搜索线程,1202个CPU和176个GPU。方法部分提供异步和分布MCTS的全部细节和情况。
【原文】Evaluating the playing strength of AlphaGo
To evaluate AlphaGo, we ran an internal tournament among variants of AlphaGo and several other Go programs, including the strongest commercial programs Crazy Stone and Zen, and the strongest open source programs Pachi and Fuego. All of these programs are basedon high performance MCTS algorithms. In addition, we included the open source program GnuGo, a Go program using state-of-the-art search methods that preceded MCTS. All programs were allowed 5 s of computation time per move.
【翻译】评价AlphaGo下棋能力
为了评估AlphaGo的性能,我们在AlphaGo的变种和其他几个围棋程序之间进行了内部比赛,包括最强大的商业程序CrazyStone和Zen,以及最强的开放源码的程序Pachi和Fuego。所有这些程序都是基于高性能的MCTS算法的。此外,我们也邀请了开源程序GnuGo,它使用了最先进的蒙特卡洛树搜索。所有程序只允许使用最多5秒的时间对每一步的移动进行计算。
【原文】The results of the tournament (see Fig. 4a) suggest that single-machine AlphaGo is many dan ranks stronger than any previous Go program, winning 494 out of 495 games (99.8%) against other Go programs. To provide a greater challenge to AlphaGo, we also played games with four handicap stones (that is, free moves for the opponent); AlphaGo won 77%, 86%, and 99% of handicap games against Crazy Stone, Zen and Pachi, respectively. The distributed version of AlphaGo was significantly stronger, winning 77% of games against single-machine AlphaGo and 100% of its games against other programs.
【翻译】这次比赛的结果(见图4a)表明,单机AlphaGo比以往任何的围棋程序在段位排名中都靠前。与其他的围棋程序相比,单机AlphaGo在495场比赛中赢得了494场(胜率为99.8%)。为了挑战AlphaGo,我们还在让对手四目棋的情况下进行了博弈(即对手可以自由落子);在与CrazyStone、Zen和Pachi的对阵中,AlphaGo获胜率分别为77%、86%,和99%。AlphaGo分布式版本明显更强,对单机AlphaGo的对弈胜率为77%,对其他程序的胜率为100%。
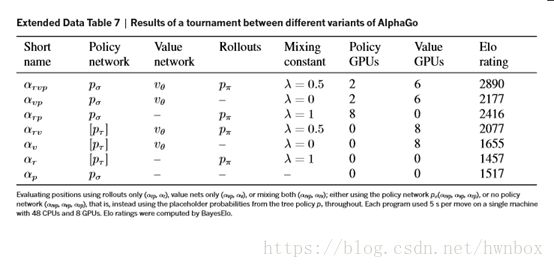
【原文】We also assessed variants of AlphaGo that evaluated positions using just the value network (λ = 0) or just rollouts (λ = 1) (see Fig. 4b). Even without rollouts AlphaGo exceeded the performance of all other Go programs, demonstrating that value networks provide a viable alternative to Monte Carlo evaluation in Go. However, the mixed evaluation (λ = 0.5) performed best, winning ≥95% of games against other variants. This suggests that the two position-evaluation mechanisms are complementary: the value network approximates the outcome of games played by the strong but impractically slow![]() , while the rollouts can precisely score and evaluate the outcome of games played by the weaker but faster rollout policy
, while the rollouts can precisely score and evaluate the outcome of games played by the weaker but faster rollout policy![]() . Figure 5 visualizes the evaluation of a real game position by AlphaGo.
. Figure 5 visualizes the evaluation of a real game position by AlphaGo.
【翻译】我们也对AlphaGo的不同版本进行了评估,比如只使用价值网络(λ= 0)或只是使用rollout(λ= 1)(见图4b)。即使没有使用rollouts,AlphaGo的表现也超过了其他所有围棋程序的性能,证明价值网络在围棋程序上提供了一个替代蒙特卡洛评价的可行选择。然而,价值网络和rollout的混合版本(λ= 0.5)表现最佳,相对于其他变种的博弈,胜率超过95%。这表明,两个棋局评价机制是互补的:价值网络通过更强但更慢的![]() 来逼近博弈的结果,而rollouts可以在较弱但更快的策略
来逼近博弈的结果,而rollouts可以在较弱但更快的策略 ![]() 下得到更精确的评分和评价结局。图5显示了AlphaGo在一场真正博弈中的棋局评估能力。
下得到更精确的评分和评价结局。图5显示了AlphaGo在一场真正博弈中的棋局评估能力。

【原文】Figure 4 | Tournament evaluation of AlphaGo.
【翻译】 图四 AlphaGo的比赛评估
【原文】a, Results of a tournament between different Go programs (see Extended Data Tables 6–11). Each program used approximately 5 s computation time per move. To provide a greater challenge to AlphaGo, some programs (pale upper bars) were given four handicap stones (that is, free moves at the start of every game) against all opponents. Programs were evaluated on an Elo scale: a 230 point gap corresponds to a 79% probability of winning, which roughly corresponds to one amateur dan rank advantage on KGS; an approximate correspondence to human ranks is also shown, horizontal lines show KGS ranks achieved online by that program. Games against the human European champion Fan Hui were also included; these games used longer time controls. 95% confidence intervals are shown.
【翻译】a,和不同围棋程序的比赛结果(见扩展数据表6-11)。每个程序使用大约5秒来计算每次落子。为了挑战AlphaGo,一些程序得到了所有对手让4步子的优势(也就是说,每场比赛开始时的自由移动)。程序以Elo体系被评估;一个230分的差距相当于79%的胜率,大致相当于在KGS服务器上高一个业余段位;相对于人类棋手的段位也显示了出来,水平的线显示了程序在在线比赛中达到的KSG等级。对战欧洲冠军樊麾的比赛也包含了进去,这些比赛使用了很长的时间控制。图中显示了95%的置信区间。
【原文】b, Performance of AlphaGo, on a single machine, for different combinations of components. The version solely using the policy network does not perform any search.
【翻译】b, 单机版本的AlphaGo在组成部分的不同组合下的性能表现。只使用策略网络的版本没有使用任何搜索算法。
【原文】c, Scalability study of MCTS in AlphaGo with search threads and GPUs, using asynchronous search (light blue) or distributed search (dark blue), for 2 s per move.
【翻译】c, MTCS关于搜索线程和GPU的可扩展性研究,使用了异步的搜索(蓝色高亮部分)和分布式搜索(深蓝色部分),每次移动使用了2s的时间。
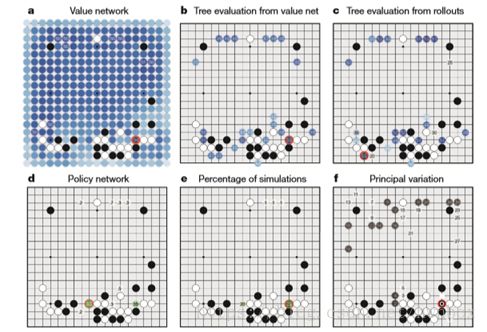
【原文】Figure 5 | How AlphaGo (black, to play) selected its move in an informal game against Fan Hui.
【翻译】 图5 AlphaGo(执黑)是如何在对战樊麾的正式比赛中选择落子的
【原文】For each of the following statistics, the location of the maximum value is indicated by an orange circle.
a, Evaluation of all successors s′ of the root position s, using the value network vθ(s′); estimated winning percentages are shown for the top evaluations.
b, Action values Q(s, a) for each edge (s, a) in the tree from root position s; averaged over value network evaluations only (λ = 0).
c, Action values Q(s, a), averaged over rollout evaluations only (λ = 1).
d, Move probabilities directly from the SL policy network, pσ(a | s) ; reported as a percentage (if above 0.1%).
e, Percentage frequency with which actions were selected from the root during simulations.
f, The principal variation (path with maximum visit count) from AlphaGo’s search tree. The moves are presented in a numbered sequence. AlphaGo selected the move indicated by the red circle; Fan Hui responded with the move indicated by the white square; in his post-game commentary he preferred the move (labelled 1) predicted by AlphaGo.
【翻译】如下的每个统计,具有最大估值的落子位置用橘黄圆圈进行了表示。
a,根节点s的所有后继结点 s’的评价,使用的是价值网络vθ(s′),评估的结果中靠前的会赢的百分数在图中显示出来了。
b,根节点s所在树的边(s, a)的落子动作价值Q(s, a),只是使用价值网络的评价(λ = 0)。
c,落子动作价值Q(s, a),只是使用rollout评价(λ = 1)。
d,直接利用SL策略网络pσ(a | s)计算出来的移动概率;大于0.1%时,报告为一个百分比。
e, 从根节点开始的模拟过程中落子位置选择的百分频率。
f, AlphaGo搜索树理论上的走子选择序列(一个搜索过程中具有最大访问次数的路径)。下棋走子展示成了一个数字序列。AlphaGo选择的落子位置标成了红色圆圈。樊麾应对的移动标成了白色的正方形;在他的复盘过程中,他提到了被AlphaGo预测到的移动(标注为1)
【原文】Finally, we evaluated the distributed version of AlphaGo against Fan Hui, a professional 2 dan, and the winner of the 2013, 2014 and 2015 European Go championships. Over 5–9 October 2015 AlphaGo and Fan Hui competed in a formal five-game match. AlphaGo won the match 5 games to 0 (Fig. 6 and Extended Data Table 1). This is the first time that a computer Go program has defeated a human professional player, without handicap, in the full game of Go—a feat that was previously believed to be at least a decade away.
【翻译】最后,我们评估了分布式AlphaGo版本对战樊麾的表现,樊麾是排名为职业2段的选手,是2013, 2014和2015年欧洲围棋锦标赛的赢家。在2015年10月5日到9日,AlphaGo和樊麾参加了五场正式的围棋比赛。AlphaGo以5:0赢得比赛(图6和扩展数据表1)。这是在一次完整的和在人类不让子的情况下,计算机围棋程序第一次打败了职业棋手,这在以前认为是至少10年之后才会发生的事件。

【原文】Figure 6 | Games from the match between AlphaGo and the European champion, Fan Hui.
【翻译】 图六 欧洲冠军樊麾对战AlphaGo的比赛
【原文】Moves are shown in a numbered sequence corresponding to the order in which they were played. Repeated moves on the same intersection are shown in pairs below the board. The first move number in each pair indicates when the repeat move was played, at an intersection identified by the second move number (see Supplementary Information).
【翻译】下棋走的每一步按照下棋顺序由数字序列显示出来。重复落子的地方在棋盘的下面成双成对显示出来。每一对数字中第一个数字的落子,重复下到了第二个数字显示的交叉地方。(详见补充信息)。

【原文】METHODS
Problem setting. Many games of perfect information, such as chess, checkers, othello, backgammon and Go, may be defined as alternating Markov games. In these games, there is a state space S (where state includes an indication of the current player to play); an action space ![]() defining the legal actions in any given state
defining the legal actions in any given state![]() ; a state transition function
; a state transition function ![]() defining the successor state after selecting action
defining the successor state after selecting action in state
in state![]() and random input
and random input ![]() (for example, dice); and finally a reward function
(for example, dice); and finally a reward function ![]() describing the reward received by player
describing the reward received by player ![]() in state
in state![]() . We restrict our attention to two-player zero-sum games,
. We restrict our attention to two-player zero-sum games,![]() , with deterministic state transitions,
, with deterministic state transitions, ![]() , and zero rewards except at a terminal time stepT . The outcome of the game
, and zero rewards except at a terminal time stepT . The outcome of the game ![]() is the terminal reward at the end of the game from the perspective of the current player at time step
is the terminal reward at the end of the game from the perspective of the current player at time step![]() . A policy
. A policy![]() is a probability distribution over legal actions
is a probability distribution over legal actions ![]() .A value function is the expected outcome if all actions for both players are selected according to policy
.A value function is the expected outcome if all actions for both players are selected according to policy![]() , that is,
, that is, ![]() . Zero-sum games have a unique optimal value function
. Zero-sum games have a unique optimal value function ![]() that determines the outcome from state
that determines the outcome from state![]() following perfect play by both players,
following perfect play by both players,
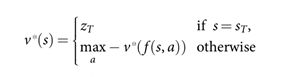
 ,带有确定性状态转换:
,带有确定性状态转换:
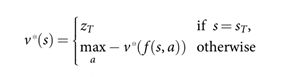
【原文】Reinforcement learning can learn to approximate the optimal value function directly from games of self-play . The majority of prior work has focused on a linear combination ![]() of features
of features ![]() with weights
with weights ![]() . Weights were trained using temporal-difference learning in chess, checkers and Go; or using linear regression in othello and Scrabble . Temporal-difference learning has also been used to train a neural network to approximate the optimal value function, achieving superhuman performance in backgammon; and achieving weak kyu-level performance in small-board Go using convolutional networks.
. Weights were trained using temporal-difference learning in chess, checkers and Go; or using linear regression in othello and Scrabble . Temporal-difference learning has also been used to train a neural network to approximate the optimal value function, achieving superhuman performance in backgammon; and achieving weak kyu-level performance in small-board Go using convolutional networks.
【翻译】强化学习可以直接从自我博弈中学习到近似的最优值函数。先前的大部分工作都集中在具有权重 ![]() 的特征
的特征![]() 的线性组合
的线性组合 ![]() 上。权重利用时空差异学习在国际象棋、跳棋和围棋上进行训练;或在奥赛罗和拼字游戏上利用线性回归进行训练。时间差学习也被用来训练神经网络,使其逼近最优值函数,在五子棋上达到了超人的表现;实现采用卷积网络在小棋盘上实现弱级水平的性能。
上。权重利用时空差异学习在国际象棋、跳棋和围棋上进行训练;或在奥赛罗和拼字游戏上利用线性回归进行训练。时间差学习也被用来训练神经网络,使其逼近最优值函数,在五子棋上达到了超人的表现;实现采用卷积网络在小棋盘上实现弱级水平的性能。
【原文】n alternative approach to minimax search is Monte Carlo tree search (MCTS), which estimates the optimal value of interior nodes by a double approximation![]() . The first approximation,
. The first approximation, ![]() Monte Carlo simulations to estimate the value function of a simulation policy
Monte Carlo simulations to estimate the value function of a simulation policy![]() . The second approximation,
. The second approximation, ![]() , uses a simulation policy
, uses a simulation policy ![]() in place of minimax optimal actions. The simulation policy selects actions according to a search control function
in place of minimax optimal actions. The simulation policy selects actions according to a search control function![]() , such as UCT, that selects children with higher action values,
, such as UCT, that selects children with higher action values,![]() , plus a bonus
, plus a bonus ![]() that encourages exploration; or in the absence of a search tree at state
that encourages exploration; or in the absence of a search tree at state![]() , it samples actions from a fast rollout policy
, it samples actions from a fast rollout policy 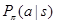 . As more simulations are executed and the search tree grows deeper, the simulation policy becomes informed by increasingly accurate statistics. In the limit, both approximations become exact and MCTS (for example, with UCT) converges to the optimal value function
. As more simulations are executed and the search tree grows deeper, the simulation policy becomes informed by increasingly accurate statistics. In the limit, both approximations become exact and MCTS (for example, with UCT) converges to the optimal value function![]() .The strongest current Go programs are based on MCTS 13–15,36 .
.The strongest current Go programs are based on MCTS 13–15,36 .
【翻译】极大极小搜索的另一种可选方法是蒙特卡洛树搜索(MCTS),通过双重近似来估计内部节点的最优值 ,![]() 。第个一近似:
。第个一近似:![]() ,通过 n 步 Monte Carlo模拟,估计了模拟策略
,通过 n 步 Monte Carlo模拟,估计了模拟策略 ![]() 下的值函数。第二个近似:
下的值函数。第二个近似: ,采用代替极大极小最优动作的模拟策略
,采用代替极大极小最优动作的模拟策略![]() 。模拟策略根据搜索控制函数
。模拟策略根据搜索控制函数![]() 来选择动作,如UCT,选择具有较大动作值的“儿子”,
来选择动作,如UCT,选择具有较大动作值的“儿子”, ![]() ,加上一个额外的
,加上一个额外的![]() ;或在缺少s 状态下的搜索树时,通过快速走子策略
;或在缺少s 状态下的搜索树时,通过快速走子策略![]() 中对动作进行采样。随着模拟次数的增加,搜索树变得越来越深,评估策略也变得越来越精确。在极限情况下,两个近似都变得准确,MCTS(例如UCT)也收敛到最优值函数
中对动作进行采样。随着模拟次数的增加,搜索树变得越来越深,评估策略也变得越来越精确。在极限情况下,两个近似都变得准确,MCTS(例如UCT)也收敛到最优值函数![]() 。现在最强的围棋程序就是基于MCTS的。
。现在最强的围棋程序就是基于MCTS的。
【原文】MCTS has previously been combined with a policy that is used to narrow the beam of the search tree to high-probability moves; or to bias the bonus term towards high-probability moves. MCTS has also been combined with a value function that is used to initialize action values in newly expanded nodes, or to mix Monte Carlo evaluation with minimax evaluation. By contrast, AlphaGo’s use of value functions is based on truncated Monte Carlo search algorithms, which terminate rollouts before the end of the game and use a value function in place of the terminal reward. AlphaGo’s position evaluation mixes full rollouts with truncated rollouts, resembling in some respects the well-known temporal-difference learning algorithm ![]() . AlphaGo also differs from prior work by using slower but more powerful representations of the policy and value function; evaluating deep neural networks is several orders of magnitude slower than linear representations and must therefore occur asynchronously.
. AlphaGo also differs from prior work by using slower but more powerful representations of the policy and value function; evaluating deep neural networks is several orders of magnitude slower than linear representations and must therefore occur asynchronously.
【翻译】MCTS先前已经与用于与束窄搜索树使其成为高概率移动或偏向高概率移动的额外奖励的策略进行结合。MCTS也已经与在新扩展节点上用于初始化动作值,或用于蒙特卡洛评价与极大极小评价进行混合的价值函数相结合。相比之下,AlphaGo对价值函数的使用是基于截断的蒙特卡洛搜索算法,这里的蒙特卡洛搜索算法在比赛结束前终止rollout,并且使用价值函数来代替最终奖励。AlphaGo的棋局评估混合了完整的和截断的rollout,在某些方面类似于著名的时间差算法![]() 。在使用更慢但是更强大的策略和价值函数上,AlphaGo也不同于先前的工作;评价深度神经网络比评价线性表示慢了几个数量级,因此必须异步。
。在使用更慢但是更强大的策略和价值函数上,AlphaGo也不同于先前的工作;评价深度神经网络比评价线性表示慢了几个数量级,因此必须异步。
【原文】The performance of MCTS is to a large degree determined by the quality of the rollout policy. Prior work has focused on handcrafted patterns or learning rollout policies by supervised learning, reinforcement learning, simulation balancing or online adaptation; however, it is known that rollout-based position evaluation is frequently inaccurate. AlphaGo uses relatively simple rollouts, and instead addresses the challenging problem of position evaluation more directly using value networks.
【翻译】MCTS的性能很大程度上是由rollout策略的质量决定的。以前的工作都集中在手工模式或利用监督学习、强化学习、模拟平衡或在线自适应学习rollout策略;然而大家都知道,基于rollout的位置评价往往是不准确的。AlphaGo采用相对简单的rollout,同时更直接地利用价值网络应对棋局评估的挑战。
【原文】Search algorithm. To efficiently integrate large neural networks into AlphaGo, we implemented an asynchronous policy and value MCTS algorithm (APV-MCTS). Each node![]() in the search tree contains edges
in the search tree contains edges![]() for all legal actions
for all legal actions![]() .Each edge stores a set of statistics,
.Each edge stores a set of statistics,
![]()
【翻译】搜索算法。为了将大型神经网络与AlphaGo进行有效整合,我们实现了一个异步策略和价值MCTS算法(APV-MCTS)。对于所有的合法动作![]() ,搜索树中的每个节点 都包含边
,搜索树中的每个节点 都包含边![]() 。每条边都存储一组统计:
。每条边都存储一组统计:
![]()
【原文】where ![]() is the prior probability,
is the prior probability, ![]() and
and ![]() are Monte Carlo estimates of total action value, accumulated over
are Monte Carlo estimates of total action value, accumulated over ![]() and
and ![]() leaf evaluations and rollout rewards, respectively, and
leaf evaluations and rollout rewards, respectively, and ![]() is the combined mean action value for that edge. Multiple simulations are executed in parallel on separate search threads. The APV-MCTS algorithm proceeds in the four stages outlined in Fig. 3.
is the combined mean action value for that edge. Multiple simulations are executed in parallel on separate search threads. The APV-MCTS algorithm proceeds in the four stages outlined in Fig. 3.
其中 ![]() 是先验概率,
是先验概率,![]() 和
和 ![]() 是蒙特卡洛对总的动作价值的估计, 分别在
是蒙特卡洛对总的动作价值的估计, 分别在![]() 和
和![]() 个叶子节点的价值评估和rollout奖励进行累计,
个叶子节点的价值评估和rollout奖励进行累计,![]() 是该边的联合平均动作价值。多个模拟在独立的线程上并行执行,APV-MCTS算法在四个阶段的收益在图3中进行概述。
是该边的联合平均动作价值。多个模拟在独立的线程上并行执行,APV-MCTS算法在四个阶段的收益在图3中进行概述。
【原文】Selection (Fig. 3a). The first in-tree phase of each simulation begins at the root of the search tree and finishes when the simulation reaches a leaf node at time step L. At each of these time steps, t < L, an action is selected according to the statistics in the search tree, ![]() ,using a variant of the PUCT algorithm,
,using a variant of the PUCT algorithm, ![]() , where
, where ![]() is a constant determining the level of exploration; this search control strategy initially prefers actions with high prior probability and low visit count, but asymptotically prefers actions with high action value.
is a constant determining the level of exploration; this search control strategy initially prefers actions with high prior probability and low visit count, but asymptotically prefers actions with high action value.
【翻译】 选择(见图三). 第一阶段,各个仿真从搜索树的根开始,当模拟在时间步L到达叶子节点时结束。在每一个时间步t<L时,一个动作的选择是根据搜索树中的统计数据, 。利用PUCT算法的一个变种,
。利用PUCT算法的一个变种,![]() ,其中
,其中 ![]() 是一个确定搜索水平的常数;这个搜索控制策略最初偏爱高先验概率和低访问数的落子动作,但逐渐地更偏爱具有高价值的动作。
是一个确定搜索水平的常数;这个搜索控制策略最初偏爱高先验概率和低访问数的落子动作,但逐渐地更偏爱具有高价值的动作。
【原文】Evaluation (Fig. 3c). The leaf position![]() added to a queue for evaluation
added to a queue for evaluation ![]() by the value network, unless it has previously been evaluated. The second rollout phase of each simulation begins at leaf node
by the value network, unless it has previously been evaluated. The second rollout phase of each simulation begins at leaf node![]() and continues until the end of the game. At each of these time-steps, , actions are selected by both players according to the rollout policy,
and continues until the end of the game. At each of these time-steps, , actions are selected by both players according to the rollout policy,![]() . When the game reaches a terminal state, the outcome
. When the game reaches a terminal state, the outcome ![]() is computed from the final score.
is computed from the final score.
【翻译】模拟(图3c)。除非叶子之前已经被评估,否则它所代表的棋局 ![]() 通过价值网络加入到评价队列
通过价值网络加入到评价队列![]() 中。每个模拟的第二个rollout阶段从叶节点
中。每个模拟的第二个rollout阶段从叶节点 ![]() 开始,一直持续到比赛结束。在每一个时间步 时,落子动作是双方棋手根据rollout策略
开始,一直持续到比赛结束。在每一个时间步 时,落子动作是双方棋手根据rollout策略![]() 来选择的。当比赛结束时,结果
来选择的。当比赛结束时,结果![]() 从最终点目中计算出来。
从最终点目中计算出来。
【原文】Backup (Fig. 3d). At each in-tree step of the simulation, the rollout statistics are updated as if it has lost ![]() games,
games,![]() ;
; ![]()
![]() ; this virtual loss discourages other threads from simultaneously exploring the identical variation. At the end of the simulation, the rollout statistics are updated in a backward pass through each step
; this virtual loss discourages other threads from simultaneously exploring the identical variation. At the end of the simulation, the rollout statistics are updated in a backward pass through each step![]() , replacing the virtual losses by the outcome,
, replacing the virtual losses by the outcome, ![]() ;
; ![]() . Asynchronously, a separate backward pass is initiated when the evaluation of the leaf position
. Asynchronously, a separate backward pass is initiated when the evaluation of the leaf position ![]() completes. The output of the value network
completes. The output of the value network  is used to update value statistics in a second backward pass through each step
is used to update value statistics in a second backward pass through each step![]() ,
,![]() ,
,![]() . The overall evaluation of each state action is a weighted average of the Monte Carlo estimates,
. The overall evaluation of each state action is a weighted average of the Monte Carlo estimates, ![]() , that mixes together the value network and rollout evaluations with weighting parameterλ . All updates are performed lock-free.
, that mixes together the value network and rollout evaluations with weighting parameterλ . All updates are performed lock-free.
【翻译】回传(图3d)。在模拟树的每一步 中,rollout数据被更新,就好比输了
中,rollout数据被更新,就好比输了![]() 场游戏:
场游戏:![]() ;
; ![]()
![]() 。这个虚拟的损失阻止其他线程同时探索相同的路径。在模拟结束时,在每一步
。这个虚拟的损失阻止其他线程同时探索相同的路径。在模拟结束时,在每一步 ![]() ,rollout统计数据反向回溯更新,用结果替换虚拟损失
,rollout统计数据反向回溯更新,用结果替换虚拟损失![]() ;
;![]() 。当叶子位置
。当叶子位置 ![]() 的评估完成后,单独的逆向回溯才会异步地开始。价值网络
的评估完成后,单独的逆向回溯才会异步地开始。价值网络 ![]() 的输出被用来更新在每一步
的输出被用来更新在每一步 ![]() 中第二次反向回溯的统计值
中第二次反向回溯的统计值![]() ,
,![]() 。每个状态动作的总体评价是蒙特卡洛估计的加权平均,
。每个状态动作的总体评价是蒙特卡洛估计的加权平均,![]() ,它将价值网络和具有加权参数λ 的rollout评估混合在一起。所有更新都是在无锁的状态下执行的。
,它将价值网络和具有加权参数λ 的rollout评估混合在一起。所有更新都是在无锁的状态下执行的。
【原文】Expansion (Fig. 3b). When the visit count exceeds a threshold, ![]() , the successor state
, the successor state ![]() is added to the search tree. The new node is initialized to
is added to the search tree. The new node is initialized to![]() ,
, ![]() , using a tree policy
, using a tree policy ![]() (similar to the rollout policy but with more features, see Extended Data Table 4) to provide place-holder prior probabilities for action selection. The position
(similar to the rollout policy but with more features, see Extended Data Table 4) to provide place-holder prior probabilities for action selection. The position![]() is also inserted into a queue for asynchronous GPU evaluation by the policy network. Prior probabilities are computed by the SL policy network
is also inserted into a queue for asynchronous GPU evaluation by the policy network. Prior probabilities are computed by the SL policy network ![]() with a softmax temperature set to β; these replace the placeholder prior probabilities,
with a softmax temperature set to β; these replace the placeholder prior probabilities, ![]() , using an atomic update. The threshold
, using an atomic update. The threshold![]() is adjusted dynamically to ensure that the rate at which positions are added to the policy queue matches the rate at which the GPUs evaluate the policy network. Positions are evaluated by both the policy network and the value network using a mini-batch size of 1 to minimize end-to-end evaluation time.
is adjusted dynamically to ensure that the rate at which positions are added to the policy queue matches the rate at which the GPUs evaluate the policy network. Positions are evaluated by both the policy network and the value network using a mini-batch size of 1 to minimize end-to-end evaluation time.
【翻译】扩展(图3b)。当访问计数超过阈值时![]() 后,后继状态
后,后继状态![]() 才会被被添加到搜索树中。新节点被初始化为
才会被被添加到搜索树中。新节点被初始化为 ![]() ,
,![]() ,
, ![]() ,使用Tree policy
,使用Tree policy![]() (类似于rollout策略,但特征更多,参见扩展数据表4)来为动作选择提供place-holder先验概率。通过策略网络,将棋局
(类似于rollout策略,但特征更多,参见扩展数据表4)来为动作选择提供place-holder先验概率。通过策略网络,将棋局![]() 插入到异步GPU的评估队列中,由SL策略网络
插入到异步GPU的评估队列中,由SL策略网络![]() 利用softmax层温度集β 来计算先验概率,计算完毕后,这些更新将取代place-holder先验概率:
利用softmax层温度集β 来计算先验概率,计算完毕后,这些更新将取代place-holder先验概率:![]() 。动态地调整阈值
。动态地调整阈值![]() 以确保棋局添加到策略队列的速率与GPU评价策略网络的速度相匹配。棋局由策略网络和使用批大小为1的价值网络相结合进行评估,来使端到端评估时间最小化。
以确保棋局添加到策略队列的速率与GPU评价策略网络的速度相匹配。棋局由策略网络和使用批大小为1的价值网络相结合进行评估,来使端到端评估时间最小化。
【原文】We also implemented a distributed APV-MCTS algorithm. This architecture consists of a single master machine that executes the main search, many remote worker CPUs that execute asynchronous rollouts, and many remote worker GPUs that execute asynchronous policy and value network evaluations. The entire search tree is stored on the master, which only executes the in-tree phase of each simulation. The leaf positions are communicated to the worker CPUs, which execute the rollout phase of simulation, and to the worker GPUs, which compute network features and evaluate the policy and value networks. The prior probabilities of the policy network are returned to the master, where they replace placeholder prior probabilities at the newly expanded node. The rewards from rollouts and the value network outputs are each returned to the master, and backed up the originating search path.
【翻译】我们还实现了一个分布式APV-MCTS算法。该体系由一个执行主要搜索的主机和许多执行异步rollout的远程CPU,以及许多执行异步策略和价值网络评估的远程GPU组成。整个搜索树存储在主目录中,它只执行每个模拟的树内搜索阶段。叶子的棋局状态传送到CPU,让其执行仿真的rollout阶段;同时也传送到GPU,让其生成网络的特征并通过策略和价值网络进行评估。策略网络将得到的先验概率返回给主机,并在新扩展节点上替换place-holder先验概率。Rollout的奖励和价值网络的输出返回给主机,并回退到起始搜索路径。
【原文】At the end of search AlphaGo selects the action with maximum visit count; this is less sensitive to outliers than maximizing action value. The search tree is reused at subsequent time steps: the child node corresponding to the played action becomes the new root node; the subtree below this child is retained along with all its statistics, while the remainder of the tree is discarded. The match version of AlphaGo continues searching during the opponent’s move. It extends the search if the action maximizing visit count and the action maximizing action value disagree. Time controls were otherwise shaped to use most time in the middle-game. AlphaGo resigns when its overall evaluation drops below an estimated 10% probability of winning the game, that is ![]() .
.
【翻译】在搜索最后,AlphaGo选择具有最大访问计数的动作;没有选择落子动作价值最大的动作,是因为前者对于离群值更不敏感。在随后的时间步骤中,搜索树被重复使用:与所做落子动作相一致的子节点成为新的根节点;该子节点下面的子树与它所有的统计数据一起保留,而树的其余部分将被丢弃。在对手进行落子时,AlphaGo的match版本继续进行搜索。如果落子动作使最大化的访问计数与最大化的动作价值不一致,它将对搜索进行扩展。另外,时间控制在中局使用最多的时间。当AlphaGo总体评价为胜率估计低于10%时,也就是:![]() 时,AlphaGo就会放弃比赛。
时,AlphaGo就会放弃比赛。
【原文】AlphaGo does not employ the all-moves-as-first or rapid action value estimation heuristics used in the majority of Monte Carlo Go programs; when using policy networks as prior knowledge, these biased heuristics do not appear to give any additional benefit. In addition, AlphaGo does not use progressive widening, dynamic komi or an opening book. The parameters used by AlphaGo in the Fan Hui match are listed in Extended Data Table 5.
【翻译】AlphaGo不采用“每次都选择最好的动作”或用于多数蒙特卡洛程序的快速动作价值估计启发式算法;当使用策略网络作为先验知识时,这些偏见的启发式算法似乎没有提供任何额外的优点。此外,AlphaGo不使用逐步扩大、动态贴目或一本打开的书??。AlphaGo在对战樊麾时使用的参数列在扩展数据表5中。

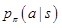 is a linear softmax policy based on fast, incrementally computed, local pattern-based features consisting of both ‘response’ patterns around the previous move that led to state
is a linear softmax policy based on fast, incrementally computed, local pattern-based features consisting of both ‘response’ patterns around the previous move that led to state
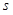 , and ‘non-response’ patterns around the candidate move α in state
, and ‘non-response’ patterns around the candidate move α in state
【翻译】rollout策略
【原文】Symmetries. In previous work, the symmetries of Go have been exploited by using rotationally and reflectionally invariant filters in the convolutional layers. Although this may be effective in small neural networks, it actually hurts performance in larger networks, as it prevents the intermediate filters from identifying specific asymmetric patterns. Instead, we exploit symmetries at run-time by dynamically transforming each position
【翻译 】对称性。在以往的工作中,围棋的对称性已通过使用旋转和对称不变过滤器的卷积层而被开发。虽然这在小型神经网络中可能有效,但它在更大的网络中表现不佳,因为它阻止了中间过滤器识别特定的非对称模式。代替它的是,我们利用八个反射和旋转
【原文】Policy network: classification. We trained the policy network
 对棋局进行分类。该数据集包含排名6段和9段的棋手进行的160000场比赛的2940万个棋局;35.4%的游戏都是让子游戏。数据集被分割成一个测试集(前一百万个位置)和一个训练集(剩下的2840万个位置)。被放弃的落子动作被排除在数据集之外。每个棋局由原始棋盘描述
对棋局进行分类。该数据集包含排名6段和9段的棋手进行的160000场比赛的2940万个棋局;35.4%的游戏都是让子游戏。数据集被分割成一个测试集(前一百万个位置)和一个训练集(剩下的2840万个位置)。被放弃的落子动作被排除在数据集之外。每个棋局由原始棋盘描述
【原文】DistBelief: We have developed a software framework called DistBelief that can utilize computing clusters with thousands of machines to train large models.
【翻译】DistBelief:我们开发了一个叫做DistBelief的软件框架,它可以利用计算带有几千个机器的簇来训练大型模型。
【原文】Policy network: reinforcement learning. We further trained the policy network by policy gradient reinforcement learning. Each iteration consisted of a mini-batch of n games played in parallel, between the current policy network
 from a previous iteration, randomly sampled from a pool of opponents, so as to increase the stability of training. Weights were initialized to
from a previous iteration, randomly sampled from a pool of opponents, so as to increase the stability of training. Weights were initialized to
【翻译】策略网络:强化学习。我们通过策略梯度强化学习进一步训练了策略网络。每次迭代都包括并行进行的 n个小批量的比赛,包括目前正在训练的策略网络
 。每进行500次迭代,我们都会将参数
。每进行500次迭代,我们都会将参数
 to approximate the value function of the RL policy network
to approximate the value function of the RL policy network
【翻译】价值网络:回归。我们训练了一个价值网络
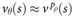 ,通过RL策略网络
,通过RL策略网络
 对最初的
对最初的
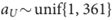 中均匀随机选取一个落子动作(反复执行直到
中均匀随机选取一个落子动作(反复执行直到
【原文】Features for policy/value network. Each position
【翻译】策略/价值网络的特征。每个棋局
【原文】Neural network architecture. The input to the policy network is a 19 × 19 × 48 image stack consisting of 48 feature planes. The first hidden layer zero pads the input into a 23 × 23 image, then convolves k filters of kernel size 5 × 5 with stride 1 with the input image and applies a rectifier nonlinearity. Each of the subsequent hidden layers 2 to 12 zero pads the respective previous hidden layer into a 21 × 21 image, then convolves k filters of kernel size 3 × 3 with stride 1, again followed by a rectifier nonlinearity. The final layer convolves 1 filter of kernel size 1 × 1 with stride 1, with a different bias for each position, and applies a softmax function. The match version of AlphaGo used k = 192 filters; Fig. 2b and Extended Data Table 3 additionally show the results of training with k = 128, 256 and 384 filters.
【翻译】神经网络体系结构。策略网络的输入是一个由48个特征图组成的19×19×48图像块。输入图像在首个隐藏层通过零填充形成23×23大小的图像,将输入图像与K个卷积核大小为5*5、步长为1的滤波器做卷积操作,然后加入一个非线性层。剩下的2到12隐藏层,每个隐藏层使用零填充形成21×21大小的图像,然后与K个卷积核大小为3×3、步长为1的滤波器进行卷积操作,再加一个非线性层。最后一层与一个卷积核的大小1×1、步长为1的滤波器进行卷积操作,每个位置使用一个不同的偏差,并应用一个softmax函数。AlphaGo的竞赛版本使用k= 192个滤波器。图2b和扩展数据表3还显示用k = 128、256和384滤波器进行训练的结果。
【原文】The input to the value network is also a 19 × 19 × 48 image stack, with an additional binary feature plane describing the current colour to play. Hidden layers 2 to 11 are identical to the policy network, hidden layer 12 is an additional convolution layer, hidden layer 13 convolves 1 filter of kernel size 1 × 1 with stride 1, and hidden layer 14 is a fully connected linear layer with 256 rectifier units. The output layer is a fully connected linear layer with a single tanh unit.
【翻译】对价值网络的输入也是一个19×19×48的图像块,加入了描述当前颜色的二进制特征层。2至11隐藏层与策略网络的隐层相同,第12层是一个额外的卷积层,第13层与卷积核大小为1×1、步长为1的滤波器进行卷积操作,第14个隐藏层是包含256个线性单元的全连接线性层。输出层是包含一个tanh单元的全连接线性层。
【原文】Evaluation. We evaluated the relative strength of computer Go programs by running an internal tournament and measuring the Elo rating of each program. We estimate the probability that program a will beat program b by a logistic function
【翻译】评价。我们通过进行内部比赛和测量每个程序的ELO等级对计算机围棋程序运行的相对强度进行了评估。我们通过一个逻辑函数
【原文】With the exception of distributed AlphaGo, each computer Go program was executed on its own single machine, with identical specifications, using the latest available version and the best hardware configuration supported by that program (see Extended Data Table 6). In Fig. 4, approximate ranks of computer programs are based on the highest KGS rank achieved by that program; however, the KGS version may differ from the publicly available version.
【翻译】除了分布式AlphaGo这个例外,每个计算机围棋程序都在它自己的单机上执行。单机具有相同规格,使用最新的版本和支持该程序(见扩展数据表6)的最好的硬件配置。在图4中,计算机程序的大致排名是根据它们在KGS上的最高等级进行排名的;但是,KGS版本可能与公开可用的版本不同。