redis内部数据结构之字典
需要深入redis,其中重要的一步就是要看懂它里面所使用的数据结构,其中最重要的就是字典,它几乎就是redis实现各种功能的骨架。
1、字典数据结构
redis作为一个nosql数据库,所有的key-value都是存储在一个字典中,而字典则是用哈希表实现的。
字典使用两个哈希表,一般只使用ht[0],只有当Rehash时候才使用ht[1];
哈希表采用链表的方式解决键碰撞问题;
Redis的Rehash操作是渐进式的,服务器程序会主动Rehash,在查找、添加、删除元素等操作时也会在Rehash进行时执行一次rehash操作。
下面看下在redis中哈希表是什么样的:
上图所示结构对应代码如下:
// 字典
typedef struct dict {
// 哈希表(2个)
dictht ht[2];
// rehash索引,若rehashidx == -1,则表示未开始进行rehash,
// 否则rehashidx的值表示rehash正进行到ht[0]这个hash表上哪个索引节点
int rehashidx;
// 安全迭代器数量
int iterators;
} dict;
// 哈希表
typedef struct dictht {
// 哈希表 (指向一个dictEntry*数组,俗称“桶”)
dictEntry **table;
// 哈希表大小
unsigned long size;
// 位掩码,通过hash_value & sizemask得出节点在哈希表索引
unsigned long sizemask;
// 哈希表中节点数量
unsigned long used;
} dictht;
// 哈希节点
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下一个节点
struct dictEntry *next;
} dictEntry;
2、字典扩容
关于redis中的字典,最特别的无疑是dict中维护着两个哈希表(ht[0],ht[1]),为什么要有两个呢?在解释这个之前我们先看下哈希表的rehash;
rehash目的:
当我们不断的往哈希表(ht[0])插入新的键值对,如果两个键的hash值相同,那么它们将以链表的形式放入到同一个“桶”中,如下图key1和key4:
这样带来的问题就是,随着我们往哈希表里插入越来越多的键值对,哈希表性能会急剧下降(查找操作都退化成链表查找);
所以,我们就需要扩大原来的哈希表,使得哈希表大小和哈希表中的节点数的比例能够维持在1:1(dictht.size:dictht.used),这时候哈希表才能达到最佳查询性能O(1)
rehash过程:
创建一个新的哈希表,大小是当前的两倍(准确说还必须是2的幂次),然后把全部键值对重新散列到新的哈希表中,最后再用它替换原来的哈希表;
rehash问题:
我们考虑下面一种情况:客户端A插入一个键值对,这时候发现dictht.used与dictht.size的比例大于1(查询性能开始下降),于是执行rehash操作,假设目前哈希表中有10万个键值对,那么redis就会一直埋头苦干,直到完成对这个10万个键值对的rehash操作,并且在这个过程中,其他客户端请求都会被阻塞(因为redis是单线程);很显然我们是无法忍受这种情况的发生,那redis是如何解决这个问题呢?
渐进式rehash:
“渐进式”意味着rehash过程不是一次做完而是每次做一点,这样就可以避免由于rehash过程太久导致其他客户端请求被阻塞,具体过程如下:
1. 在ht[1]上分配一个更大的哈希表;
2. “分多次”把ht[0]上的键值对重新散列到ht[1]上;
3. 当处理完所有键值对时,让ht[0]指向新的哈希表;

现在还有一个问题,我们说了 “分多次把ht[0]上的键值对重新散列到ht[1]上”,那么这个分多次究竟是多少次?并且每次处理多少键值对才最合适?
redis准备rehash时,会把dict.rehashidx置为0(标示rehash开始),然后当执行任意一个哈希表操作(添加,删除,查找等),就会执行一次_dictRehashStep函数;
_dictRehashStep函数每次rehash把ht[0]上的第一个不为空索引上的全部键值对迁移到ht[1]上,并且用dict.rehashidx的值标示当前rehash正进行到了哪个索引;
也就是说按照上图,第一次迁移key1,key4键值对(这时候dict.rehashidx的值为0),第二次迁移key2键值对(这时候dict.rehashidx的值为1),第三次迁移key3键值对(这时候dict.rehashidx的值为2),至此rehash完毕(dict.rehashidx被复位成-1),相关伪代码:
# 任意dict操作(添加,删除,查找)
def anyDictOperation(dict):
# 如果正在进行rehash
if dict.rehashidx != -1:
_dictRehashStep(dict)
# 执行字典操作
dictOperation(dict)
def _dictRehashStep(dict):
# 如果当前安全迭代器数量不为0,暂停此次rehash
if dict.iterators > 0 : return
idx = dict.rehashidx
# 获取第一个不为空的索引
while len(dict.ht[0].table[idx]) <= 0:
idx++
# 迁移该索引节点上的所有键值对到ht[1]上
for key, val in dict.ht[0].table[idx].getKeyValuePairs:
redisServer.ht[0].table.used--
redisServer.ht[1].table.used++
redisServer.ht[1].table.hash(key, val)
# 当所有键值对迁移完毕,用新的哈希表替换老的,并且重置ht[1]
if dict.ht[0].table.used == 0:
dict.ht[0] = dict.ht[1]
dict.ht[1].reset()
dict.rehashindx = -1 # 复位另外,redis在执行服务器执行例行任务时(serverCron),也会定期去做一部分rehash操作伪代码:
def serverCron():
# 循环redis所有数据库
for num in redisServer.dbnums:
if redisServer.db[num].dict.rehashidx != -1 :
# 第二个参数用来限制rehash执行多久,单位毫秒
dictRehashMilliseconds(redisServer.db[num].dict, 1)
# 其他例行任务...
def dictRehashMilliseconds(dict, timeout_ms):
start_time = now_time()
while now_time() - start_time < timeout_ms:
_dictRehashStep(dict)至此,我们已经分析完:为什么要在dict中维护两个哈希表(ht[0],ht[1]);
关于redis字典的更多细节,请参看:dict.h和dict.c代码以及redis.c/serverCron函数
3、字典的API函数
| 函数名称 |
作用 |
复杂度 |
| dictCreate |
创建一个新字典 |
O(1) |
| dictResize |
重新规划字典的大小 |
O(1) |
| dictExpand |
扩展字典 |
O(1) |
| dictRehash |
对字典进行N步渐进式Rehash |
O(N) |
| _dictRehashStep |
对字典进行1步尝试Rehash |
O(N) |
| dictAdd |
添加一个元素 |
O(1) |
| dictReplace |
替换给定key的value值 |
O(1) |
| dictDelete |
删除一个元素 |
O(N) |
| dictRelease |
释放字典 |
O(1) |
| dictFind |
查找一个元素 |
O(N) |
| dictFetchValue |
通过key查找value |
O(N) |
| dictGetRandomKey |
随机返回字典中一个元素 |
O(1) |
(1)创建新字典
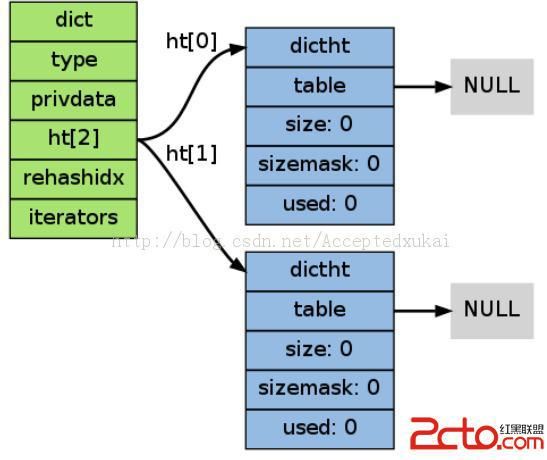
通过dictCreate函数创建一个新字典dict *dictCreate(dictType *type, void *privDataPtr).
一个空字典的示意图如下(图片来自Redis设计与实现一书),ht[1]只在Rehash时使用:
(2)字典添加元素
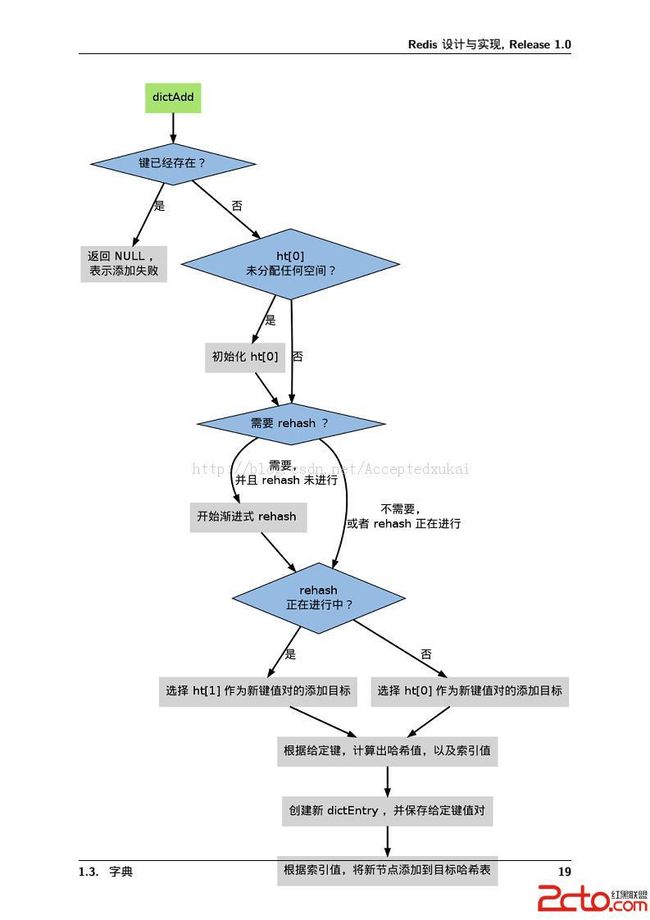
根据字典当前的状态,将一个key-value元素添加到字典中可能会引起一系列复制的操作:
如果字典未初始化(即字典的0号哈希表ht[0]的table为空),那么需要调用dictExpand函数对它初始化;
如果插入的元素key已经存在,那么添加元素失败;
如果插入元素时,引起碰撞,需要使用链表来处理碰撞;
如果插入元素时,引起程序满足Rehash的条件时,先调用dictExpand函数扩展哈希表的size,然后准备渐进式Rehash操作。
字典添加元素的流程图(来自Redis设计与实现):
/* Expand or create the hash table */
intdictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size); //得到需要扩展到的size
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
returnDICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size= realsize;
n.sizemask = realsize-1;
n.table= zcalloc(realsize * sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table== NULL) {
d->ht[0] = n;
returnDICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
//准备渐进式rehash,rehash的字典table为0号
d->ht[1] = n;
d->rehashidx = 0;
returnDICT_OK;
}
/* Expand the hash table if needed */
staticint _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) returnDICT_OK;
// 如果哈希表为空,那么将它扩展为初始大小
if (d->ht[0].size== 0) returndictExpand(d, DICT_HT_INITIAL_SIZE);
/*如果哈希表的已用节点数 >= 哈希表的大小,并且以下条件任一个为真:
1) dict_can_resize 为真
2) 已用节点数除以哈希表大小之比大于 dict_force_resize_ratio
那么调用 dictExpand 对哈希表进行扩展,扩展的体积至少为已使用节点数的两倍
*/
if (d->ht[0].used >= d->ht[0].size&&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size> dict_force_resize_ratio))
{
returndictExpand(d, d->ht[0].used*2);
}
returnDICT_OK;
}
staticint _dictKeyIndex(dict *d, const void *key)
{
unsignedinth, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return-1;
/* Compute the key hash value */
h = dictHashKey(d, key);//通过hash函数得到key所在的bucket索引位置
//查找在现有字典中是否出现了该key
for(table= 0; table<= 1; table++) {
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return-1;
he = he->next;
}
//如果系统没在rehash则不需要查找ht[1]
if (!dictIsRehashing(d)) break;
}
returnidx;
}
dictEntry *dictAddRaw(dict *d, void *key)
{
intindex;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);// 尝试渐进式地 rehash 桶中一组元素
/* Get the index of the new element, or -1 if
* the element already exists. */
// 查找可容纳新元素的索引位置,如果元素已存在, index为 -1
if ((index= _dictKeyIndex(d, key)) == -1)
returnNULL;
/* Allocate the memory and store the new entry */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// 决定该把新元素放在那个哈希表
entry = zmalloc(sizeof(*entry));
//头插法,插入节点
entry->next= ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);//关联起key
returnentry;
}
/* Add an element to the target hash table */
//添加一个元素
intdictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key);
if (!entry) returnDICT_ERR;
dictSetVal(d, entry, val);//关联起value
returnDICT_OK;
}