
1.你知道我们公司是做什么的吗?为什么想来我们公司?
网宿科技是做CDN,content delivery network,内容分发的。通过实现优质节点的选择,保证用户的体验更加流畅稳定。优质节点的定义是指内容被复制到各个地区的不同服务器上面,距离离访问者最近的。
我最喜欢的一款游戏是阴阳师,体验很棒,后来了解到网易的这款游戏是与网宿科技合作,其背后的原理是CDN技术,会觉得这是件很酷的事;像百度腾讯京东都是网宿科技的客户,所以这个公司真的很厉害。本科是机械,所以比较喜欢偏技术的公司,女友是厦门的,很想留在厦门,而网宿科技是厦门为数不多搞技术的,从我的学长那里也知道网宿科技愿意培养新人,乐于分享;数据分析团队是刚建起来的,所以我相信可以在这个优秀的公司成长很大,我也希望能够在这个公司进入一种ALL IN的状态,为这个团队献上一份力实现自己的价值。
2.请自我介绍下。
您好,我姓谢,叫光武,本科机械。看到这个公司的招聘要求我是很激动的,强调的是R语言和建模。而我决定转去数据分析就是因为这两个要素。在大二下的时候一门学科概率论与数理统计,激发了我对统计学强大的兴趣。之后花两个月时间写的那篇以小见大之样本方差的无偏性,把统计学的逻辑梳理一遍,那种全身心投入的那种状态让我感到非常痴迷。R语言是统计编程语言,因为统计学所以就开始学R语言实现相关算法。之后国际建模比赛和队友商量四天四夜一起解决世界上的难题时也让我着迷不已。本专业的优化设计也涉及到大量的建模过程,还有优化的问题。
贵公司强调R语言,所以我猜测团队是偏统计方向的机器学习,这也是我学习的重点。
当然,数据分析它强调的也是一种思维能力,侧重点不是在于严格的数学证明和强悍的编程能力。我不打算进一步读研的原因也在于这里,因为用数学或者通过建模去解决一个实际问题,让产品迭代真的是一件很酷的事。
3.你这个建模比赛是怎么完成的?用了哪些算法?K均值聚类的优缺点讲一下?是如何改进的?简要讲一下PCA算法。
建模比赛的内容简历上写的挺清楚,我着重讲一下数据处理和算法部分把。其实花最多时间的还是用R语言的dplr包 tidy data,数据规整后,主要采用了K均值聚类 PCA AHP三个算法。当然,K均值聚类并不是用来填充数据的,我是先利用完整的变量进行聚类,把观测值分成了5类,含缺失值部分则采用该类数据的均值替代。PCA是用于特征选择,最后利用方差解释比率的碎石图选择了四个变量。AHP则是分配权重,具体过程是队友用MATLAB实现的,主要是矩阵、特征值的处理。
K均值聚类算法步骤:首先是确定K值,K值的选取本质上是一个optimal优化问题,当时用的R语言的Nbclust包实现的,这个包有24个指标来确定K值,支持的指标越多,说明K值越优;还有一种方法是根据类内平方和的elbow(拐点)。随机划分成K类,然后以该类的均值为中心,离该中心越近则被归为该类,这里的距离一样是用欧式距离定义。欧式距离是绝对距离。迭代停止条件在R中是默认为10次,或者当所有的观测值不再重新分配为止。
优点是算法简单易理解,伸缩性好,适用于大数据。缺点是对异常值非常敏感。当有异常值时可以选用基于中心值的聚类方法。(异常值的查看通过箱线图或者残差图)聚类算法还有系统聚类算法,通过谱系图来剪枝的聚类算法。
PCA,Principal Component Analysis,主成分分析方法通过计算主成分和它的得分来理解数据。主成分可以从两种角度理解:第一种是从线性代数的角度看,通过特征分解求得一个使得方差最大化的优化问题,第二个则是通过几何得角度,即求得一个。第二种从几何的角度看,提供了一个与观测最为接近的低维线性空间,即该空间离所有观测欧氏距离最近。
其缺点是变量的选择只能考虑方差,不能考虑到偏差,而且对于无监督机器学习来说,并不能通过验证集或者测试集来判断他的MSE,结果无法衡量,因此无法确定所找到的变量是否是最有价值的模式,解决办法是通过定性分析和多次选择来做决定。
4.你这篇统计文章的大概思路是什么?有哪些亮点?
写这篇 文章《以小见大之样本方差的无偏性》,进入了一种我向往的状态那种ALL IN 的状态。我通过样本方差这个点,把统计学的逻辑梳理了一遍,而数据分析的工具就是统计学。统计学是什么:design,设计,数据的收集、埋点,比如通过GA,talkingdata, 友盟这些工具或者抽样调查的方式来获取数据;description,描述,从均值方差偏度峰度异常值这些到同比环比定基比移动平均去分析数据,寻找趋势tipping point,去发现问题;之后则是inference,统计推断,用机器学习算法去建立模型,做出预测推断。
当时让我困惑的点,是为什么样本可以去估计总体?他们差别那么大,怎么可能会没有偏差?数据所收集到的基本都是总体的一个部分,或者说用短时期的数据去推测长时期的趋势,他何以可能去做到这点?从理论层面上,这个问题可以追溯到大数定律、中心极限定理、概率。
在理清楚这个原理后,那么又如何去做到更加精确地去描述这个总体?这便到了数理统计的三大核心:参数估计、假设检验、非参数估计。
而无偏性就是由于参数估计所引起的,样本的方差的公式是用RSS/n-1,这个n-1的自由度保证了估计的没有偏差。而无偏估计又有很多个,从这个概念也就有了MSE,mean sum of error,用来选择到底用哪个无偏估计。这就有了机器学习一个非常关键的调参指标---test MSE或者说validate MSE。在选择机器学习算法的关键是方差偏差的均衡。像SVM LR LDA LASSO RIDGE 这些算法本质区别是因考虑到方差偏差均衡,loss function 的不同所引起的。
所以正是因为这篇文章,才慢慢打通了我的一些概念。在运用统计去做数据分析时,它是建立在一个概率基础上的。数据分析是什么,收集数据,发现问题,提出目标,建立模型,调参,验证测试改版,然后又收集数据,这样不断循环的一个过程。
5.你都知道哪些分类算法,举一个你最熟悉的算法应用实例。
分类算法有CART,C4.5,SVM,LR,LDA,KNN,朴素贝叶斯,随机森林等。
比较熟悉的是朴素贝叶斯,其原理是贝叶斯算法,通过确定特征属性下的某类概率,概率大的被归为该类。可以用来识别黄牛账户或者真假用户。比如先确定假用户的几个特征值:IP地址的重复,消费次数,消费金额,好友头像;然后获取训练样本,得到真假用户的先验概率和在已知用户真假条件下特征属性的概率。最后根据这些特征属性对用户进行分类。
6.相比于其他人,你认为你的核心优势是什么?
1)专业是机械,所以训练的系统化思维还有建模能力。
2)最核心的优势我觉得是自身的渴望,相比于数学、计算机专业的,我是因为兴趣才自我驱动去自学,学习统计、编程、机器学习。自身的渴望最大的优势是学习动力和学习激情较高。
3)抗压能力较强,因为大学一直涉猎很多领域包括哲学、历史、文学,在写作平台上码了15万字之多,所以能够控制好情绪,也有多个方式比如看动漫、打篮球去排解压力。
7.L1正则化可以进行特征筛选的原因,从几何和后验概率的角度考虑
正则化一般用来解决curse of dimensionality,即解决参数过多导致的过拟合问题,L1正则化是各个参数绝对值累加,也叫做L1惩罚项或者叫1范数,用于lasso模型。相比起ridge模型的L2正则化来说,它最大的特点在于可以把系数强制设为0。
(在分类算法中,LR和SVM的区别也类似,后者的loss term可以为0,而LR则是无限接近0.
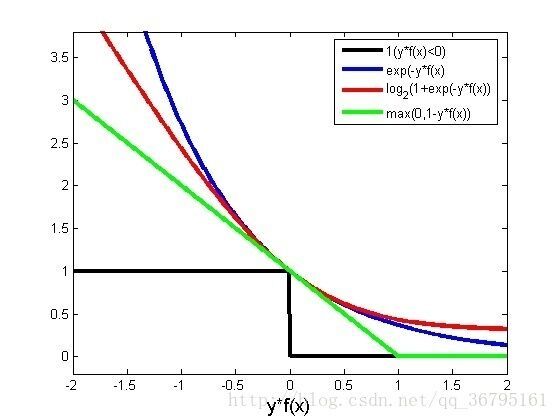
loss function损失函数刻画的是拟合程度的量化,LF值越低代表着**测试集上**实际值与预测值的差距越小,因而越小表示模型越好。)
从几何角度解释L1,比如lasso 可以转化成优化问题求解,其约束条件是绝对值之和小于某个值。
拿一个二维问题举例的话,这个约束条件是一个菱形区域。在这个限制条件下,目标函数越小越好,即目标函数与该区域第一相交的位置。
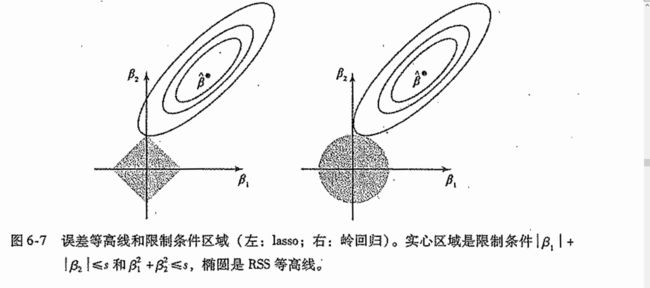
这幅图是一个很好的例子,对于L1正则化,第一次相交的点是在坐标轴处,即有一个系数为0,把该项删除,从而达到特征选择的目的。而对于L2来说,第一次相交一般不在坐标轴,但同样可以看出他们第一次相交时,有一个系数被压缩了,接近0但不会等于0.
从后验概率的角度看的话, 正则化是为模型参数估计增加一个先验知识,先验知识会引导损失函数最小值过程朝着约束方向迭代。整个最优化问题可以看做是一个最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计。L1正则化是假设参数数服从均值为0,尺度为lambda的尖峰拉普拉斯分布,因此倾向于得到一个许多系数(完全)为零的模型,即稀疏解模型。
8.结合你自己所做的数据分析项目,谈谈你对数据分析的理解。
从解决问题的角度看,数据分析是用来驱动决策与业务增长。
拿建模比赛来说,实际问题是为了驱动决策,最终做成一个数据分析报告,使得决策者能够根据你的结论来做出选择,而数据分析得出的结论特点是有数据佐证,把问题量化。
另一个问题是运营层面的,数据分析贯穿了内容、产品、用户、流量整个运营体系,做的那份航空公司数据分析报告就是从用户运营的角度把用户分群,对不同的用户实现不同的营销方案从而实现业务增长。
从方法上看,数据分析大体可以划分为三个步骤:数据规划(以业务需求为导向,确定指标体系和维度体系),数据采集(通过工程师的埋点、第三方统计工具等去收集所需要的数据),最后则是数据分析(通过数据挖掘、建模等,发现问题,定位问题,并快速给出解决方案)
从建模比赛还有数据分析报告上发现数据规划相当重要,因为未经数据规划会得到非常庞杂、dirty的数据,前期tidy data 会花费大量时间,最好的解决办法是能有一个北极星指标为目标。数据分析过程中理解变量,classify variables是最为重要的环节的,这个也与之前的数据规划息息相关。
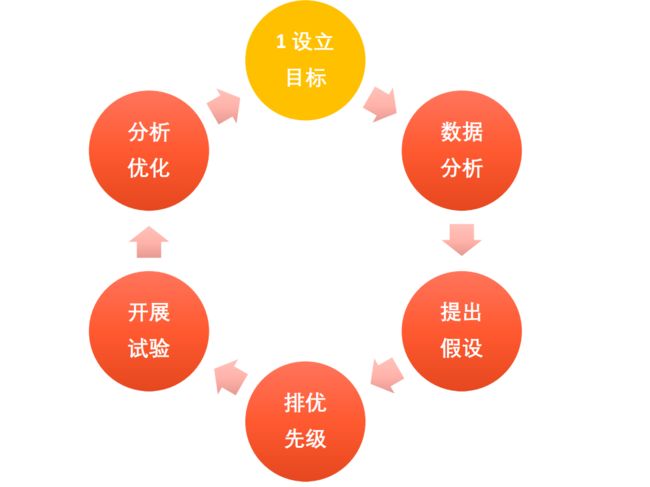
从这三个层次出发和以往的项目经验,数据分析大致就是以下六个步骤的循环:设立目标,数据分析,提出假设,排优先级,开展试验,分析优化。
9.你认为数据分析中特别重要的思维或者能力是什么?
我认为最重要的是宏观与微观的结合。宏观是一种产品思维或者定性思维,对整个市场、用户体验、产品功能等各个维度上,有个较为清晰的认知,这点在数据规划上非常重要,而数据规划又是整个数据分析流程的开端。微观则是一种工程思维或者定量思维,通过对数据的挖掘、建模来进行推断和预测,把问题当作一个工程解决。
这两者是相辅相成的,在特征选择中我们会发现机器学习往往处于非常shallow的层面,在这个层面机器学习只能看到一些非常表面的现象,特征非常多,数据稀疏的要命,很多算法表现的很糟糕。举一个简单例子,通过对大规模语料库的统计,机器学习可能会发现这样一个规律:所有的“他”都是不穿bra的。而如果进行定性分析的话,无需进行任何统计学习,我们可以直接判断“他”是根本不会去bra的。在无监督学习中,作用更加明显了。
10.特征筛选与特征评价
在特征选择中我们会发现机器学习往往处于非常shallow的层面,在这个层面机器学习只能看到一些非常表面的现象,特征非常多,数据稀疏的要命,很多算法表现的很糟糕。举一个简单例子,通过对大规模语料库的统计,机器学习可能会发现这样一个规律:所有的“他”都是不穿bra的。而如果进行定性分析的话,无需进行任何统计学习,我们可以直接判断“他”是根本不会去bra的。在无监督学习中,作用更加明显了。
11.决策树处理连续型变量的方法
决策树处理连续型变量时叫做回归树,它采用自上而下贪婪的分裂原则:递归二叉分裂,使得RSS 最小的分裂规则。以该类的平均值作为最终的预测,其好处是易于理解,处理速度快,预测结果可靠,可以处理缺失值。
为了通过交叉验证得到测试mse最小,采用代价复杂性剪枝,代价复杂性剪枝是使得RSS+α*终端节点个数 这个值最小。α通过验证集确定。
12.决策树算法中的预剪枝与后剪枝
决策树算法生成的树非常详细和庞大,导致训练集拟合的很好,测试集效果却很差,即过拟合,overfiting的问题。
预剪枝方法很简单,就是设定某个阈值使树不再生长,这个阈值可以是纯度,也可以是分类的最小个数等。
后剪枝是在生成的过拟合树上剪枝,常用的算法有三种,错误率降低剪枝(reduce error pruning)、悲观剪枝(pessimistic error pruning)、代价复杂性剪枝(cost complexity pruning)。
REP需要一个测试集,算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
PEP不需要测试集,一般来说是有某个子树的根节点来代替整个子树。它根据被替换子树的错误数减去标准差 与 新子树的错误树进行比较。C4.5比较常用。
CCP用于CART的回归树。