MapReduce调度与执行原理之任务执行(一)
前言 :本文旨在理清在Hadoop中一个MapReduce作业(Job)在提交到框架后的整个生命周期过程,权作总结和日后参考,如有问题,请不吝赐教。本文不涉及Hadoop的架构设计,如有兴趣请参考相关书籍和文献。在梳 理过程中,我对一些感兴趣的源码也会逐行研究学习,以期强化基础。
作者 :Jaytalent
开始日期 :2013年9月9日参考资料:【1】《Hadoop技术内幕--深入解析MapReduce架构设计与实现原理》董西成【2】 Hadoop 1.0.0 源码
【3】《Hadoop技术内幕--深入解析Hadoop Common和HDFS架构设计与实现原理》蔡斌 陈湘萍
一个MapReduce作业的生命周期大体分为5个阶段
【1】:
1. 作业提交与初始化
2. 任务调度与监控
3.
任务运行环境准备
4.
任务执行
5.
作业完成
这篇文章将任务的准备、执行到整个作业完成的过程进行研究。
一、任务启动
任务启动过程由TaskTracker完成。启动过程如下:首先判断是否是第一次收到某个作业的任务,若是就进行作业本地化,然后创建任务目录,否则直接创建任务目录。接下来启动JVM,并从TaskTracker获取任务,进行任务本地化并执行任务。任务执行后,若该JVM没有到重用次数上限,则再次从TaskTracker获取任务,重复上述过程。总体上讲,主要包括作业本地化、任务本地化和启动任务三步。本地化的目的是为任务运行创建一个环境,包括工作目录、下载运行所需文件和设置环境变量等。作业本地化由该作业第一个任务启动时执行。下面依次来看上述步骤。
1. 作业本地化
我们先从TaskTracker(以下简称TT)收到心跳响应说起。在TT的offerService方法中,通过transmitHeartbeat方法收到心跳响应,并从中提取出需要执行的命令:
HeartbeatResponse heartbeatResponse = transmitHeartBeat(now);
TaskTrackerAction[] actions = heartbeatResponse.getActions();
if (actions != null){
for(TaskTrackerAction action: actions) {
if (action instanceof LaunchTaskAction) {
addToTaskQueue((LaunchTaskAction)action);
} else if (action instanceof CommitTaskAction) {
CommitTaskAction commitAction = (CommitTaskAction)action;
}
}
} private void addToTaskQueue(LaunchTaskAction action) {
if (action.getTask().isMapTask()) {
mapLauncher.addToTaskQueue(action);
} else {
reduceLauncher.addToTaskQueue(action);
}
}
addToTaskQueue方法将任务注册后加入待启动任务列表,并通知等待线程有新任务加入。
public void addToTaskQueue(LaunchTaskAction action) {
synchronized (tasksToLaunch) {
TaskInProgress tip = registerTask(action, this);
tasksToLaunch.add(tip);
tasksToLaunch.notifyAll();
}
} void startNewTask(final TaskInProgress tip) throws InterruptedException {
Thread launchThread = new Thread(new Runnable() {
@Override
public void run() {
try {
RunningJob rjob = localizeJob(tip);
tip.getTask().setJobFile(rjob.getLocalizedJobConf().toString());
// Localization is done. Neither rjob.jobConf nor rjob.ugi can be null
launchTaskForJob(tip, new JobConf(rjob.getJobConf()), rjob);
} catch (Throwable e) {
String msg = ("Error initializing " + tip.getTask().getTaskID() +
":\n" + StringUtils.stringifyException(e));
LOG.warn(msg);
tip.reportDiagnosticInfo(msg);
}
}
});
launchThread.start();
} synchronized (rjob) {
if (!rjob.localized) {
while (rjob.localizing) {
rjob.wait();
}
if (!rjob.localized) {
//this thread is localizing the job
rjob.localizing = true;
}
}
}
if (!rjob.localized) {
Path localJobConfPath = initializeJob(t, rjob, ttAddr);
}
这样做的好处是在进行作业本地化时,不需要直接对rjob对象加锁,也就不会阻塞TT的其他线程,如MapEventsFetcherTread(而只会阻塞其他任务启动线程)。
作业本地化的过程如下(initializeJob内部):
作业本地化的过程如下(initializeJob内部):
// save local copy of JobToken file
final String localJobTokenFile = localizeJobTokenFile(t.getUser(), jobId);
synchronized (rjob) {
rjob.ugi = UserGroupInformation.createRemoteUser(t.getUser());
Credentials ts = TokenCache.loadTokens(localJobTokenFile, conf);
Token jt = TokenCache.getJobToken(ts);
if (jt != null) { //could be null in the case of some unit tests
getJobTokenSecretManager().addTokenForJob(jobId.toString(), jt);
}
for (Token token : ts.getAllTokens()) {
rjob.ugi.addToken(token);
}
} FileSystem userFs = getFS(jobFile, jobId, conf);
// Download the job.xml for this job from the system FS
final Path localJobFile =
localizeJobConfFile(new Path(t.getJobFile()), userName, userFs, jobId); taskController.initializeJob(t.getUser(), jobId.toString(),
new Path(localJobTokenFile), localJobFile, TaskTracker.this,
ttAddr);至此,作业本地化结束。
2. 启动任务
任务启动过程可分为两步:JVM启动和任务启动。为了避免不同任务间互相干扰,TT为每个任务启动了独立的JVM。JVM的启动过程如下:
map和reduce各自启动TaskRunner,在run方法中,首先获取工作目录,环境变量,启动命令,命令参数和标准输入输出对象等:
final File workDir =
new File(new Path(localdirs[rand.nextInt(localdirs.length)],
TaskTracker.getTaskWorkDir(t.getUser(), taskid.getJobID().toString(),
taskid.toString(),
t.isTaskCleanupTask())).toString());
List classPaths = getClassPaths(conf, workDir,
taskDistributedCacheManager);
Vector vargs = getVMArgs(taskid, workDir, classPaths, logSize);
String setup = getVMSetupCmd();
File[] logFiles = prepareLogFiles(taskid, t.isTaskCleanupTask());
File stdout = logFiles[0];
File stderr = logFiles[1];
List setupCmds = new ArrayList();
for(Entry entry : env.entrySet()) {
StringBuffer sb = new StringBuffer();
sb.append("export ");
sb.append(entry.getKey());
sb.append("=\"");
sb.append(entry.getValue());
sb.append("\"");
setupCmds.add(sb.toString());
}
setupCmds.add(setup);
launchJvmAndWait(setupCmds, vargs, stdout, stderr, logSize, workDir); public void launchJvm(TaskRunner t, JvmEnv env
) throws IOException, InterruptedException {
if (t.getTask().isMapTask()) {
mapJvmManager.reapJvm(t, env);
} else {
reduceJvmManager.reapJvm(t, env);
}
}
该方法中,通过一个标志spawnNewJvm来表示是否需要启动新的JVM,默认是不需要。判断是否启动新JVM的依据是当前已经启动的JVM数量是否到达最大的slot数量:
boolean spawnNewJvm = false;
if (numJvmsSpawned >= maxJvms) {
...
}else {
spawnNewJvm = true;
} JvmRunner jvmRunner = jvmIter.next().getValue();
JobID jId = jvmRunner.jvmId.getJobId();
//look for a free JVM for this job; if one exists then just break
if (jId.equals(jobId) && !jvmRunner.isBusy() && !jvmRunner.ranAll()){
setRunningTaskForJvm(jvmRunner.jvmId, t); //reserve the JVM
return;
} if ((jId.equals(jobId) && jvmRunner.ranAll()) ||
(!jId.equals(jobId) && !jvmRunner.isBusy())) {
runnerToKill = jvmRunner;
spawnNewJvm = true;
}
if (spawnNewJvm) {
if (runnerToKill != null) {
LOG.info("Killing JVM: " + runnerToKill.jvmId);
killJvmRunner(runnerToKill);
}
spawnNewJvm(jobId, env, t);
return;
} public void runChild(JvmEnv env) throws IOException, InterruptedException{
int exitCode = 0;
try {
env.vargs.add(Integer.toString(jvmId.getId()));
TaskRunner runner = jvmToRunningTask.get(jvmId);
if (runner != null) {
Task task = runner.getTask();
//Launch the task controller to run task JVM
String user = task.getUser();
TaskAttemptID taskAttemptId = task.getTaskID();
String taskAttemptIdStr = task.isTaskCleanupTask() ?
(taskAttemptId.toString() + TaskTracker.TASK_CLEANUP_SUFFIX) :
taskAttemptId.toString();
exitCode = tracker.getTaskController().launchTask(user,
jvmId.jobId.toString(), taskAttemptIdStr, env.setup,
env.vargs, env.workDir, env.stdout.toString(),
env.stderr.toString());
}
} catch (IOException ioe) {
} finally { // handle the exit code
// although the process has exited before we get here,
// make sure the entire process group has also been killed.
kill();
updateOnJvmExit(jvmId, exitCode);
deleteWorkDir(tracker, firstTask);
}
} // create the working-directory of the task
if (!currentWorkDirectory.mkdir()) {
throw new IOException("Mkdirs failed to create "
+ currentWorkDirectory.toString());
}
//mkdir the loglocation
String logLocation = TaskLog.getAttemptDir(jobId, attemptId).toString();
if (!localFs.mkdirs(new Path(logLocation))) {
throw new IOException("Mkdirs failed to create "
+ logLocation);
} // get the JVM command line.
String cmdLine =
TaskLog.buildCommandLine(setup, jvmArguments,
new File(stdout), new File(stderr), logSize, true);
// write the command to a file in the
// task specific cache directory
// TODO copy to user dir
Path p = new Path(allocator.getLocalPathForWrite(
TaskTracker.getPrivateDirTaskScriptLocation(user, jobId, attemptId),
getConf()), COMMAND_FILE);
String commandFile = writeCommand(cmdLine, rawFs, p); shExec = new ShellCommandExecutor(new String[]{
"bash", "-c", commandFile},
currentWorkDirectory);
shExec.execute(); JvmTask myTask = umbilical.getTask(context);
if (myTask.shouldDie()) {
break;
} else {
if (myTask.getTask() == null) {
taskid = null;
currentJobSegmented = true;
if (++idleLoopCount >= SLEEP_LONGER_COUNT) {
//we sleep for a bigger interval when we don't receive
//tasks for a while
Thread.sleep(1500);
} else {
Thread.sleep(500);
}
continue;
}
} final JobConf job = new JobConf(task.getJobFile());
...
//setupWorkDir actually sets up the symlinks for the distributed
//cache. After a task exits we wipe the workdir clean, and hence
//the symlinks have to be rebuilt.
TaskRunner.setupWorkDir(job, new File(cwd));taskFinal.run(job, umbilical); // run the task二、任务执行
1. 执行过程概述
我们知道MapReduce中主要有两种任务:Map任务和Reduce任务。这一小节结合代码来详细分析这两种任务的执行过程。总的来说,一个Map任务又可以细分为5个阶段:Read,Map,Collect,Spill和Combine;一个Reduce任务也可以细分为5个阶段:Shuffle,Merge,Sort,Reduce和Write。
具体地,对于Map任务,首先通过用户提供的InputFormat将InputSplit解析成key/value对,然后交给map函数处理。接着使用Partitioner组件对map函数的输出进行分片,确定将每个键值对交给哪个Reduce任务进一步处理。然后将键值对及其分片信息写到缓冲区中,当缓冲区快满时,执行spill操作,将数据排序后写入磁盘。最后将磁盘上的数据合并成一个输出文件。
对于Reduce任务,首先通过HTTP请求获取来自各个Map任务输出文件中属于自己分片的数据,边拷贝边合并。完成拷贝后,按照key对数据进行一次排序。然后将数据交给reduce函数处理。最后,将处理结果输出到磁盘。
过程图解如下(图片来自: http://www.myexception.cn/open-source/428094.html):
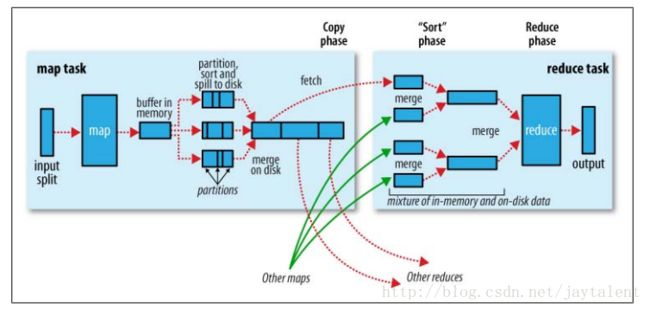
下面详细分析上述过程。
2. Map任务执行过程
假设使用的旧MapReduce API,那么MapTask的run方法会调用runOldMapper方法:
if (useNewApi) {
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
} public void run(RecordReader input, OutputCollector output,
Reporter reporter)
throws IOException {
try {
// allocate key & value instances that are re-used for all entries
K1 key = input.createKey();
V1 value = input.createValue();
while (input.next(key, value)) {
// map pair to output
mapper.map(key, value, output, reporter);
if(incrProcCount) {
reporter.incrCounter(SkipBadRecords.COUNTER_GROUP,
SkipBadRecords.COUNTER_MAP_PROCESSED_RECORDS, 1);
}
}
} finally {
mapper.close();
}
} MapOutputCollector collector = null;
if (numReduceTasks > 0) {
collector = new MapOutputBuffer(umbilical, job, reporter);
} else {
collector = new DirectMapOutputCollector(umbilical, job, reporter);
}
runner.run(in, new OldOutputCollector(collector, conf), reporter);
collect方法由用户在map函数中调用,比如:
collector.collect(key, value, partitioner.getPartition(key, value, partitions)); public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
分区结束后,一个key/value二元组变成一个三元组。collect方法接下来将三元组写入MapOutputBuffer的一个环形缓冲区中。在缓冲区使用量达到一定阈值时,spillThread将数据写入临时文件,这是spill过程。环形缓冲区的使用使得collect和spill过程可以并发执行,事实上,collect和spill分别是缓冲区的生产者和消费者,稍后在代码中可以看到。
缓冲区的大小可以通过io.sort.mb参数配置,默认是100MB。MapOutputBuffer的缓冲区采用二级索引机制,对应三级缓冲区。第三级级称为kvbuffer,存储的是具体的key/value值。第二级称为kvindices,其中每一个元素为一个三元组,每一元分别表示键值对所属分区,key在kvbuffer中的开始位置和value在kvbuffer中的开始位置。第一级称为kvoffsets,保存键值对信息(三元组)在kvindices中的偏移位置。由于kvoffsets每个元素只是一个整数,而kvindices的每个元素要占用三个整数,所以二者内存分配比例为1:3。为这两个数组分配的内存总大小的比例为io.sort.record,percent。kvbuffer默认最多使用95%的缓冲区。各部分缓冲区的分配如下:
final float spillper = job.getFloat("io.sort.spill.percent",(float)0.8);
final float recper = job.getFloat("io.sort.record.percent",(float)0.05);
final int sortmb = job.getInt("io.sort.mb", 100);
if (spillper > (float)1.0 || spillper < (float)0.0) {
throw new IOException("Invalid \"io.sort.spill.percent\": " + spillper);
}
if (recper > (float)1.0 || recper < (float)0.01) {
throw new IOException("Invalid \"io.sort.record.percent\": " + recper);
}
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException("Invalid \"io.sort.mb\": " + sortmb);
}
sorter = ReflectionUtils.newInstance(
job.getClass("map.sort.class", QuickSort.class, IndexedSorter.class), job);
LOG.info("io.sort.mb = " + sortmb);
// buffers and accounting
int maxMemUsage = sortmb << 20;
int recordCapacity = (int)(maxMemUsage * recper);
recordCapacity -= recordCapacity % RECSIZE;
kvbuffer = new byte[maxMemUsage - recordCapacity];
bufvoid = kvbuffer.length;
recordCapacity /= RECSIZE;
kvoffsets = new int[recordCapacity];
kvindices = new int[recordCapacity * ACCTSIZE];
1. kvoffsets的写入。
这里定义了几个指针:kvstart表示存有数据内存段的初始位置,kvindex表示未存储数据内存段的初始位置,kvend用于spill时指示需要写入磁盘的范围为[kvstart, kvend),此时kvend=kvindex,而正常写入时kvstart=kvend。
下一个写入位置即为kvindex,则确定下一个kvindex位置:
final int kvnext = (kvindex + 1) % kvoffsets.length; kvfull = kvnext == kvstart;
final boolean kvsoftlimit = ((kvnext > kvend)
? kvnext - kvend > softRecordLimit
: kvend - kvnext <= kvoffsets.length - softRecordLimit);
if (kvstart == kvend && kvsoftlimit) {
LOG.info("Spilling map output: record full = " + kvsoftlimit);
startSpill();
}
2. kvbuffer的写入。
操作该缓冲区的指针包括:bufstart,bufend,bufvoid,bufindex,bufmark等。其中bufstart,bufend和bufindex含义与kvstart,kvend和kvindex的含义相同。bufvoid指向kvbuffer中有效内存结束为止,kvmark表示最后写入一个完整的键值对结束的位置。
写入一个key和value后都要移动bufindex指针:
写入一个key和value后都要移动bufindex指针:
System.arraycopy(b, off, kvbuffer, bufindex, len);
bufindex += len;
一个完整的key/value写完后,要移动bufmark:
bufmark = bufindex;bufend = bufmark;
写过后:
bufstart = bufend;首先是达到spill的阈值了,需要溢写:
final boolean bufsoftlimit = (bufindex > bufend)
? bufindex - bufend > softBufferLimit
: bufend - bufindex < bufvoid - softBufferLimit;
if (bufsoftlimit || (buffull && !wrap)) {
LOG.info("Spilling map output: buffer full= " + bufsoftlimit);
startSpill();
} if (bufstart <= bufend && bufend <= bufindex) {
buffull = bufindex + len > bufvoid;
wrap = (bufvoid - bufindex) + bufstart > len;
} int headbytelen = bufvoid - bufmark;
bufvoid = bufmark;
if (bufindex + headbytelen < bufstart) {
System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex);
System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen);
bufindex += headbytelen;
} else {
byte[] keytmp = new byte[bufindex];
System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex);
bufindex = 0;
out.write(kvbuffer, bufmark, headbytelen);
out.write(keytmp);
} final int size = ((bufend <= bufindex)
? bufindex - bufend
: (bufvoid - bufend) + bufindex) + len;
bufstart = bufend = bufindex = bufmark = 0;
kvstart = kvend = kvindex = 0;
bufvoid = kvbuffer.length;
throw new MapBufferTooSmallException(size + " bytes");
插一句,
collect过程在将key写入缓冲区时调用的是keySerializer的serialize方法。那么该方法的内部是如何做的呢?首先keySerializer在初始化时是这样的:
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb); public void open(OutputStream out) {
if (out instanceof DataOutputStream) {
dataOut = (DataOutputStream) out;
} else {
dataOut = new DataOutputStream(out);
}
}public void serialize(Writable w) throws IOException {
w.write(dataOut);
}
下篇内容继续Map任务的结束以及Reduce任务的执行过程。