微服务应用故障定位系统实现原理剖析
当下最流行的设计架构便是微服务架构,越来越多的企业将老的服务拆分成微服务模式、在新的业务中采用微服务架构的设计理念进行技术架构设计。
其中实践的最好的莫过于阿里了,早期淘宝的架构是一个单体式架构,即Linux操作系统+apache服务器+mysql数据库+PHP开发的程序,所有的功能如用户注册与管理、商品管理、订单管理全都集中在一个程序包里,业务越扩展越大,这个程序包也变得越来越大,最终长成了巨无霸应用,难以承受业务的继续增长,技术团队也难以进行维护。
不过办法总比困难多,在千百个日夜轮回的摸索与实践后,终于找到了合适的解决方案,即进行重构,将原来的巨无霸应用进行业务抽象,拆分成独立的子服务,由不同的团队进行开发与维护。
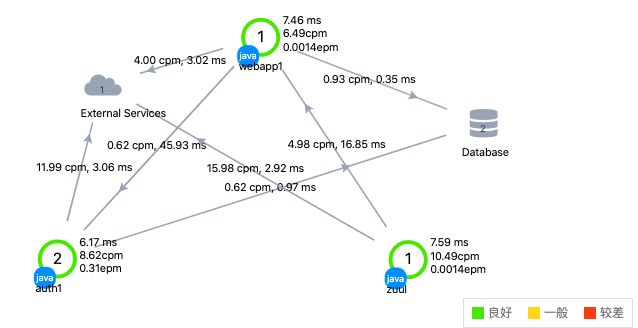
以淘宝的体量来看,该应用足以拆分上千个子业务,下图是2012年淘宝的整个服务调用拓扑图,如果到2020年,那么业务必定会更加的复杂。

不只是淘宝会有这么复杂的微服务链路,任何一个企业,只要采用微服务架构的模式进行技术架构设计,势必都会产生复杂的链路调用,也势必都会面临着着四个问题:
1)定位故障难。当客服向你反馈用户无法进行下单时,很难去排查故障原因。表面上只是一个简单的下单操作,背后却是由几十个微服务所构成的,而且是由不同的业务团队进行开发,出现问题了需要牵扯十几个部门一起排查,定位故障及根本原因太难了。
2)规划容量难。对于服务平台来说,隔三差五的搞个活动、做个促销啥的再正常不过了,一般搞大活动之前都会对业务进行压测,制定本次活动的机器资源安排,然而测试环境与生产环境情况并不完全一样,每个服务的参与程度、重要性都是不一样的,规划合适的容量太难了。
3)梳理链路难。在当下,互联网企业的人员流动是非常正常的事情,往往一个系统的从开发到完成经历了多个人的手,只有从头到尾全参与的人才知道系统的技术架构,核心人员流动后对于系统的架构梳理、性能优化就变得非常难了。一个刚入职的新人往往要花比较久的时间才能梳理清楚业务,才能在业务开发的时候处理得当,不影响上下游业务。
4)浪费资源多。由定位故障难产生的人力成本、规划容量难产生的机器资源成本、梳理链路难产生的人力成本导致了企业资源的浪费。
这些都是实行微服务架构带来的问题,那微服务架构问题这么多?难道是要让我们不用它了吗?
其实不然,有了问题就必然会有解决方案。一套完整的微服务解决方案也必然包含故障定位部分,那么业内是如何来实现微服务的故障定位呢?
目前业内的解决方案一般包含三个模块,即数据采集、数据分析、数据呈现。
数据采集是在应用的每个服务上安装探针,当服务的进程启动时,该探针也会启动,采集服务运行中的数据。
数据分析是通过收集的数据获取链路调用关系、程序执行情况。
数据呈现即在前端页面呈现链路拓扑、服务执行情况。研发人员通过前台就可知道整个服务链路情况、程序运行情况,快速定位故障根因,完美解决了微服务架构的四大问题!
目前用的最多的应用基本是java语言开发的,因此我们以java应用来进行讲解整个监控系统的实现。
第一部分:探针。
我们知道java程序都是在JVM中运行的,实质上是将java代码编译成的class文件,jvm做的第一件事情便是通过java.lang.ClassLoader去加载类(比如A.class),此时探针agent会截取A.class类嵌入监控代码生成A’.class类,之后所有的用户请求都会在A’.class类里执行,而我们的监控代码把这些都完完全全的记录下来了,并且定时发给了后台。
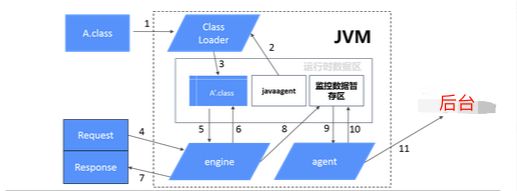
第二部分:后台。
探针采集了数据后需要后台分析,我们先看一个真实每天都在上演的业务场景,用户在页面发起“添加购物车”、“从购物车删除商品”、“从购物车进入商品结算”等等,其实整个系统运行的每一秒都在发生着N个用户请求,每个请求的链路调用请求不完全一致,对于添加购物车服务来说:购物车服务B调用用户服务C、C调用商品服务D;对于从购物车删除商品来说:购物车服务B调用商品服务D、商品服务D调用商品库存服务E;对从购物车进入商品结算来说,购物车服务B调用结算服务E、支付服务F….就这短短的一秒钟,产生了B->C->D、B->D->E、B->E->F….的服务链路,如果其中的某次调用C->D出了问题,那么B系统的研发人员完全不知道问题出现在哪里了。这个时候我们要引入两个专业的名词spanid、traceID。
对于故障问题的定位,通过traceID就可以进行跟踪。用户的请求一发起,我们就给它打上了traceID的标签,随着这个请求继续的往后面发生调用,traceID就继续跟着到了下游系统中,一直到请求的调用执行完成,而所有的执行都会记录在日志中。当某次调用发生错误时,我们只要获取到这个traceID,在整个日志中进行搜索,就可以知道它卡在哪里了,找到了问题的根本原因。
对于调用链路的梳理,通过spanID就可以进行还原。当整个用户请求开始发生时,我们把第一次链路的调用赋值为0,每深入一次就叠加一次,比如B->C->D中,B->C是0.1、C->D是0.1.1;每进行一次同深度的调用再自加一次,比如B->D->E中,B->C是0.2、C->D是0.2.1。后台系统通过上万笔的调用链路分析处理,最终会给到一个链路调用拓扑图。

因为监控代码在代码的执行都进行了埋点,所以通过代码开始和代码结束的时间戳对比就能获取到整个代码执行的时间和次数,进而获取到用户请求的执行时间和执行次数,再进而获取到服务的执行时间和执行次数,再再获取到整个应用的执行时间和执行次数,后台把数据处理好了之后传递给到前端,就可以呈现给到用户整个微服务应用的执行情况了,程序员哥哥们再也不用担心微服务应用的故障问题找不到,天天996了。
只谈微服务架构的设计,而不谈其出现的问题与解决方案便是耍流氓。
在微服务架构时代,对于整个系统的监控、调用链路的追踪、服务的熔断限流等机制都是必不可少的。
工欲善其事,必先利其器。随着云计算、5G、人工智能等的普及应用,容器技术、Devops的广泛应用,微服务必定是会大放异彩,而其背后的助力无疑是整个监控系统~