作者:郑志铨
Titan 是由 PingCAP 研发的一个基于 RocksDB 的高性能单机 key-value 存储引擎,其主要设计灵感来源于 USENIX FAST 2016 上发表的一篇论文 WiscKey。WiscKey 提出了一种高度基于 SSD 优化的设计,利用 SSD 高效的随机读写性能,通过将 value 分离出 LSM-tree 的方法来达到降低写放大的目的。
我们的基准测试结果显示,当 value 较大的时候,Titan 在写、更新和点读等场景下性能都优于 RocksDB。但是根据 RUM Conjecture,通常某些方面的提升往往是以牺牲其他方面为代价而取得的。Titan 便是以牺牲硬盘空间和范围查询的性能为代价,来取得更高的写性能。随着 SSD 价格的降低,我们认为这种取舍的意义会越来越明显。
设计目标
Titan 作为 TiKV 的一个子项目,首要的设计目标便是兼容 RocksDB。因为 TiKV 使用 RocksDB 作为其底层的存储引擎,而 TiKV 作为一个成熟项目已经拥有庞大的用户群体,所以我们需要考虑已有的用户也可以将已有的基于 RocksDB 的 TiKV 平滑地升级到基于 Titan 的 TiKV。
因此,我们总结了四点主要的设计目标:
- 支持将 value 从
LSM-tree中分离出来单独存储,以降低写放大。 - 已有 RocksDB 实例可以平滑地升级到 Titan,这意味着升级过程不需要人工干预,并且不会影响线上服务。
- 100% 兼容目前 TiKV 所使用的所有 RocksDB 的特性。
- 尽量减少对 RocksDB 的侵入性改动,保证 Titan 更加容易升级到新版本的 RocksDB。
架构与实现
Titan 的基本架构如下图所示:

图 1:Titan 在 Flush 和 Compaction 的时候将 value 分离出
LSM-tree,这样做的好处是写入流程可以和 RockDB 保持一致,减少对RocksDB的侵入性改动。
Titan 的核心组件主要包括:BlobFile、TitanTableBuilder、Version 和 GC,下面将逐一进行介绍。
BlobFile
BlobFile 是用来存放从 LSM-tree 中分离出来的 value 的文件,其格式如下图所示:
图 2:
BlobFile主要由 blob record 、meta block、meta index block 和 footer 组成。其中每个 blob record 用于存放一个 key-value 对;meta block 支持可扩展性,可以用来存放和BlobFile相关的一些属性等;meta index block 用于检索 meta block。
BlobFile 有几点值得关注的地方:
-
BlobFile中的 key-value 是有序存放的,目的是在实现Iterator的时候可以通过 prefetch 的方式提高顺序读取的性能。 - 每个 blob record 都保留了 value 对应的 user key 的拷贝,这样做的目的是在进行 GC 的时候,可以通过查询 user key 是否更新来确定对应 value 是否已经过期,但同时也带来了一定的写放大。
-
BlobFile支持 blob record 粒度的 compression,并且支持多种 compression algorithm,包括Snappy、LZ4和Zstd等,目前 Titan 默认使用的 compression algorithm 是LZ4。
TitanTableBuilder
TitanTableBuilder 是实现分离 key-value 的关键。我们知道 RocksDB 支持使用用户自定义 table builder 创建 SST,这使得我们可以不对 build table 流程做侵入性的改动就可以将 value 从 SST 中分离出来。下面将介绍 TitanTableBuilder 的主要工作流程:
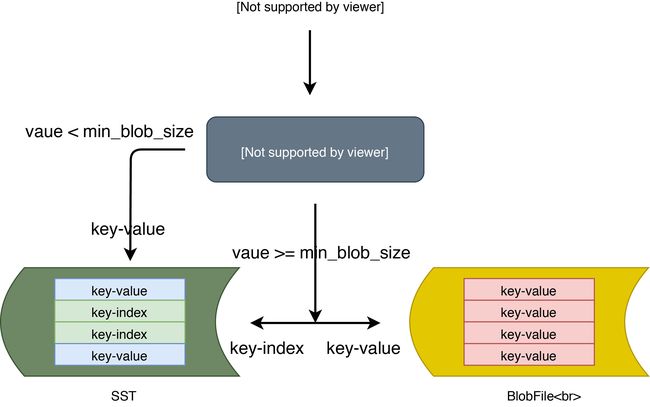
图 3:
TitanTableBuilder通过判断 value size 的大小来决定是否将 value 分离到BlobFile中去。如果 value size 大于等于min_blob_size则将 value 分离到BlobFile,并生成 index 写入SST;如果 value size 小于min_blob_size则将 value 直接写入SST。
Titan 和 Badger 的设计有很大区别。Badger 直接将 WAL 改造成 VLog,这样做的好处是减少一次 Flush 的开销。而 Titan 不这么设计的主要原因有两个:
- 假设
LSM-tree的 max level 是 5,放大因子为 10,则LSM-tree总的写放大大概为 1 + 1 + 10 + 10 + 10 + 10,其中 Flush 的写放大是 1,其比值是 42 : 1,因此 Flush 的写放大相比于整个 LSM-tree 的写放大可以忽略不计。 - 在第一点的基础上,保留
WAL可以使 Titan 极大地减少对 RocksDB 的侵入性改动,而这也正是我们的设计目标之一。
Version
Titan 使用 Version 来代表某个时间点所有有效的 BlobFile,这是从 LevelDB 中借鉴过来的管理数据文件的方法,其核心思想便是 MVCC,好处是在新增或删除文件的同时,可以做到并发读取数据而不需要加锁。每次新增文件或者删除文件的时候,Titan 都会生成一个新的 Version ,并且每次读取数据之前都要获取一个最新的 Version。

图 4:新旧
Version按顺序首尾相连组成一个双向链表,VersionSet用来管理所有的Version,它持有一个current指针用来指向当前最新的Version。
Garbage Collection
Garbage Collection (GC) 的目的是回收空间,一个高效的 GC 算法应该在权衡写放大和空间放大的同时,用最少的周期来回收最多的空间。在设计 GC 的时候有两个主要的问题需要考虑:
- 何时进行 GC
- 挑选哪些文件进行 GC
Titan 使用 RocksDB 提供的两个特性来解决这两个问题,这两个特性分别是 TablePropertiesCollector 和 EventListener 。下面将讲解我们是如何通过这两个特性来辅助 GC 工作的。
BlobFileSizeCollector
RocksDB 允许我们使用自定义的 TablePropertiesCollector 来搜集 SST 上的 properties 并写入到对应文件中去。Titan 通过一个自定义的 TablePropertiesCollector —— BlobFileSizeCollector 来搜集每个 SST 中有多少数据是存放在哪些 BlobFile 上的,我们将它收集到的 properties 命名为 BlobFileSizeProperties,它的工作流程和数据格式如下图所示:

图 5:左边
SST中 Index 的格式为:第一列代表BlobFile的文件 ID,第二列代表 blob record 在BlobFile中的 offset,第三列代表 blob record 的 size。右边BlobFileSizeProperties中的每一行代表一个BlobFile以及SST中有多少数据保存在这个BlobFile中,第一列代表BlobFile的文件 ID,第二列代表数据大小。
EventListener
我们知道 RocksDB 是通过 Compaction 来丢弃旧版本数据以回收空间的,因此每次 Compaction 完成后 Titan 中的某些 BlobFile 中便可能有部分或全部数据过期。因此我们便可以通过监听 Compaction 事件来触发 GC,通过搜集比对 Compaction 中输入输出 SST 的 BlobFileSizeProperties 来决定挑选哪些 BlobFile 进行 GC。其流程大概如下图所示:

图 6:inputs 代表参与 Compaction 的所有
SST的BlobFileSizeProperties,outputs 代表 Compaction 生成的所有SST的BlobFileSizeProperties,discardable size 是通过计算 inputs 和 outputs 得出的每个BlobFile被丢弃的数据大小,第一列代表BlobFile的文件 ID,第二列代表被丢弃的数据大小。
Titan 会为每个有效的 BlobFile 在内存中维护一个 discardable size 变量,每次 Compaction 结束之后都对相应的 BlobFile 的 discardable size 变量进行累加。每次 GC 开始时就可以通过挑选 discardable size 最大的 BlobFile 来作为作为候选的文件。
Sample
每次进行 GC 前我们都会挑选一系列 BlobFile 作为候选文件,挑选的方法如上一节所述。为了减小写放大,我们可以容忍一定的空间放大,所以我们只有在 BlobFile 可丢弃的数据达到一定比例之后才会对其进行 GC。我们使用 Sample 算法来获取每个候选文件中可丢弃数据的大致比例。Sample 算法的主要逻辑是随机取 BlobFile 中的一段数据 A,计其大小为 a,然后遍历 A 中的 key,累加过期的 key 所在的 blob record 的 size 计为 d,最后计算得出 d 占 a 比值 为 r,如果 r >= discardable_ratio 则对该 BlobFile 进行 GC,否则不对其进行 GC。上一节我们已经知道每个 BlobFile 都会在内存中维护一个 discardable size,如果这个 discardable size 占整个 BlobFile 数据大小的比值已经大于或等于 discardable_ratio 则不需要对其进行 Sample。
基准测试
我们使用 go-ycsb 测试了 TiKV 在 Txn Mode 下分别使用 RocksDB 和 Titan 的性能表现,本节我会简要说明下我们的测试方法和测试结果。由于篇幅的原因,我们只挑选两个典型的 value size 做说明,更详细的测试分析报告将会放在下一篇文章。
测试环境
- CPU:Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz(40个核心)
- Memory:128GB(我们通过 Cgroup 限制 TiKV 进程使用内存不超过 32GB)
- Disk:SATA SSD 1.5TB(fio 测试:4KB block size 混合随机读写情况下读写 IOPS 分别为 43.8K 和 18.7K)
测试计划
数据集选定的基本原则是原始数据大小(不算上写放大因素)要比可用内存大,这样可以防止所有数据被缓存到内存中,减少 Cache 所带来的影响。这里我们选用的数据集大小是 64GB,进程的内存使用限制是 32GB。
| Value Size | Number of Keys (Each Key = 16 Bytes) | Raw Data Size |
|---|---|---|
| 1KB | 64M | 64GB |
| 16KB | 4M | 64GB |
我们主要测试 5 个常用的场景:
- Data Loading Performance:使用预先计算好的 key 数量和固定的 value 大小,以一定的速度并发写入。
- Update Performance:由于 Titan 在纯写入场景下不需要 GC(
BlobFile中没有可丢弃数据),因此我们还需要通过更新来测试GC对性能的影响。 - Output Size:这一步我们会测量更新场景完成后引擎所占用的硬盘空间大小,以此反映 GC 的空间回收效果。
- Random Key Lookup Performance:这一步主要测试点查性能,并且点查次数要远远大于 key 的数量。
- Sorted Range Iteration Performance:这一步主要测试范围查询的性能,每次查询 2 million 个相连的 key。
测试结果
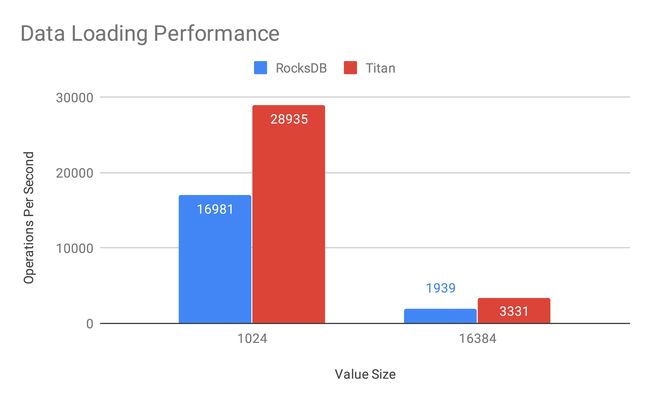
图 7 Data Loading Performance:Titan 在写场景中的性能要比 RocksDB 高 70% 以上,并且随着 value size 的变大,这种性能的差异会更加明显。值得注意的是,数据在写入 KV Engine 之前会先写入 Raft Log,因此 Titan 的性能提升会被摊薄,实际上裸测 RocksDB 和 Titan 的话这种性能差异会更大。

图 8 Update Performance:Titan 在更新场景中的性能要比 RocksDB 高 180% 以上,这主要得益于 Titan 优秀的读性能和良好的 GC 算法。
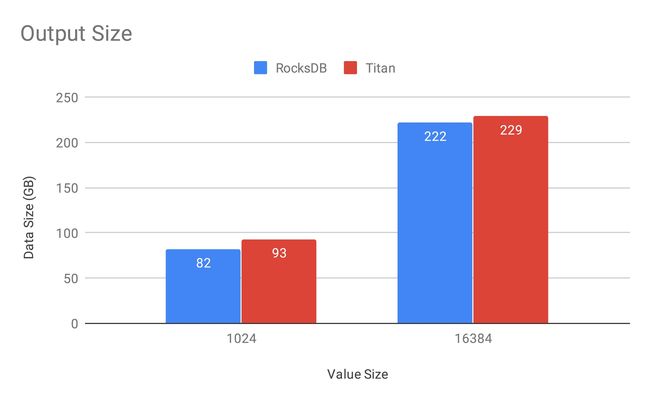
图 9 Output Size:Titan 的空间放大相比 RocksDB 略高,这种差距会随着 Key 数量的减少有略微的缩小,这主要是因为
BlobFile中需要存储 Key 而造成的写放大。

图 10 Random Key Lookup: Titan 拥有比 RocksDB 更卓越的点读性能,这主要得益与将 value 分离出
LSM-tree的设计使得LSM-tree变得更小,因此 Titan 在使用同样的内存量时可以将更多的index、filter和DataBlock缓存到 Block Cache 中去。这使得点读操作在大多数情况下仅需要一次 IO 即可(主要是用于从BlobFile中读取数据)。
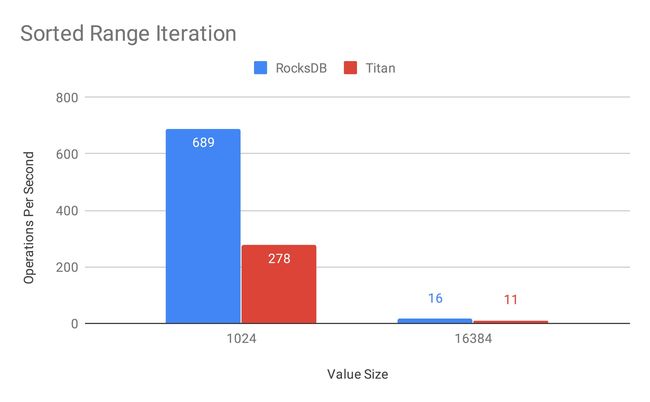
图 11 Sorted Range Iteration:Titan 的范围查询性能目前和 RocksDB 相比还是有一定的差距,这也是我们未来优化的一个重要方向。
本次测试我们对比了两个具有代表性的 value size 在 5 种不同场景下的性能差异,更多不同粒度的 value size 的测试和更详细的性能报告我们会放在下一篇文章去说明,并且我们会从更多的角度(例如 CPU 和内存的使用率等)去分析 Titan 和 RocksDB 的差异。从本次测试我们可以大致得出结论,在大 value 的场景下,Titan 会比 RocksDB 拥有更好的写、更新和点读性能。同时,Titan 的范围查询性能和空间放大都逊于 RocksDB 。
兼容性
一开始我们便将兼容 RocksDB 作为设计 Titan 的首要目标,因此我们保留了绝大部分 RocksDB 的 API。目前仅有两个 API 是我们明确不支持的:
MergeSingleDelete
除了 Open 接口以外,其他 API 的参数和返回值都和 RocksDB 一致。已有的项目只需要很小的改动即可以将 RocksDB 实例平滑地升级到 Titan。值得注意的是 Titan 并不支持回退回 RocksDB。
如何使用 Titan
创建 DB
#include
#include "rocksdb/utilities/titandb/db.h"
// Open DB
rocksdb::titandb::TitanDB* db;
rocksdb::titandb::TitanOptions options;
options.create_if_missing = true;
rocksdb::Status status =
rocksdb::titandb::TitanDB::Open(options, "/tmp/testdb", &db);
assert(status.ok());
...
或
#include
#include "rocksdb/utilities/titandb/db.h"
// open DB with two column families
rocksdb::titandb::TitanDB* db;
std::vector column_families;
// have to open default column family
column_families.push_back(rocksdb::titandb::TitanCFDescriptor(
kDefaultColumnFamilyName, rocksdb::titandb::TitanCFOptions()));
// open the new one, too
column_families.push_back(rocksdb::titandb::TitanCFDescriptor(
"new_cf", rocksdb::titandb::TitanCFOptions()));
std::vector handles;
s = rocksdb::titandb::TitanDB::Open(rocksdb::titandb::TitanDBOptions(), kDBPath,
column_families, &handles, &db);
assert(s.ok());
Status
和 RocksDB 一样,Titan 使用 rocksdb::Status 来作为绝大多数 API 的返回值,使用者可以通过它检查执行结果是否成功,也可以通过它打印错误信息:
rocksdb::Status s = ...;
if (!s.ok()) cerr << s.ToString() << endl;
销毁 DB
std::string value;
rocksdb::Status s = db->Get(rocksdb::ReadOptions(), key1, &value);
if (s.ok()) s = db->Put(rocksdb::WriteOptions(), key2, value);
if (s.ok()) s = db->Delete(rocksdb::WriteOptions(), key1);
在 TiKV 中使用 Titan
目前 Titan 在 TiKV 中是默认关闭的,我们通过 TiKV 的配置文件来决定是否开启和设置 Titan,相关的配置项包括 [rocksdb.titan] 和 [rocksdb.defaultcf.titan], 开启 Titan 只需要进行如下配置即可:
[rocksdb.titan]
enabled = true
注意一旦开启 Titan 就不能回退回 RocksDB 了。
未来的工作
优化 Iterator
我们通过测试发现,目前使用 Titan 做范围查询时 IO Util 很低,这也是为什么其性能会比 RocksDB 差的重要原因之一。因此我们认为 Titan 的 Iterator 还存在着巨大的优化空间,最简单的方法是可以通过更加激进的 prefetch 和并行 prefetch 等手段来达到提升 Iterator 性能的目的。
GC 速度控制和自动调节
通常来说,GC 的速度太慢会导致空间放大严重,过快又会对服务的 QPS 和延时带来影响。目前 Titan 支持自动 GC,虽然可以通过减小并发度和 batch size 来达到一定程度限制 GC 速度的目的,但是由于每个 BlobFile 中的 blob record 数目不定,若 BlobFile 中的 blob record 过于密集,将其有效的 key 更新回 LSM-tree 时仍然可能堵塞业务的写请求。为了达到更加精细化的控制 GC 速度的目的,后续我们将使用 Token Bucket 算法限制一段时间内 GC 能够更新的 key 数量,以降低 GC 对 QPS 和延时的影响,使服务更加稳定。
另一方面,我们也正在研究自动调节 GC 速度的算法,这样我们便可以,在服务高峰期的时候降低 GC 速度来提供更高的服务质量;在服务低峰期的时候提高 GC 速度来加快空间的回收。
增加用于判断 key 是否存在的 API
TiKV 在某些场景下仅需要判断某个 key 是否存在,而不需要读取对应的 value。通过提供一个这样的 API 可以极大地提高性能,因为我们已经看到将 value 移出 LSM-tree 之后,LSM-tree 本身会变的非常小,以至于我们可以将更多地 index、filter 和 DataBlock 存放到内存当中去,这样去检索某个 key 的时候可以做到只需要少量甚至不需要 IO 。
