netty nio踩坑实例
主要内容
一 项目背景&技术选型
二 设计开发&遇到的问题
三 问题排查&分析
四 netty nio底层原理
五 解决方案&总结
一 项目背景&技术选型
Elasticsearch的深度分页查询非常耗时且十分消耗性能,自5.1.1版本后最大只能支持1万条数据的分页,如果想获取全部数据需要通过scroll(滚动)查询的方式,因此开发了为scroll查询单独提供了查询方式。
数据传输方式:考虑到使用方和搜索服务器端可能存在大量数据传输的业务需求(如批量导出数据),如上图所示,用户端和服务器端采用netty的socket通信。通信步骤如下:
(1) 使用方首先通过rpc请求获取服务器端通信的基本配置
(2) 用户端通过socket向服务器端提交查询参数
(3) 服务器端解析查询参数,执行scroll查询,并将数据通过socket通信,传输到客户端。发送的每条数据中均带有结束符标识位,用来标识是否迭代完成(此时标识符为false)。
(4) 当服务器端迭代完毕时,发送数据,并将结束标识位设置为true.客户端接收到此数据,关闭与服务器端的链接,导出数据完毕。

基本概念
1.同步 每个请求必须逐个地被处理,一个请求的处理会导致整个流程的暂时等待,这些事件无法并发地执行。用户线程发起I/O请求后需要等待或者轮询内核I/O操作完成后才能继续执行(A、B、C几个请求,必须顺序执行,执行完A才能执行B,执行完B才能执行C)
2.异步多个请求可以并发地执行,一个请求或者任务的执行不会导致整个流程的暂时等待。用户线程发起I/O请求后仍然继续执行,当内核I/O操作完成后会通知用户线程,或者调用用户线程注册的回调函数.(A、B、C几个请求可以同时执行,内核执行完后,通知用户线程)
3.阻塞 某个请求发出后,由于该请求操作需要的条件不满足,请求操作一直阻塞,不会返回,直到条件满足(办理业务:一直排队等待,调用会一直阻塞到读写完成才返回 )
4.非阻塞 请求发出后,若该请求需要的条件不满足,则立即返回一个标志信息告知条件不满足,而不会一直等待。一般需要通过循环判断请求条件是否满足来获取请求结果。 eg.办理业务:抽号后就可以做其他事,如果你等不急,可以去问工作人员到你了没,如果没到你就不能办理业务。(如果不能读写,调用会马上返回,当IO事件分发器会通知可读写时再继续进行读写,不断循环直到读写完成)
IO编程模型。分为:BIO、伪异步IO、NIO、AIO(不做介绍)。
1.同步阻塞(BIO, Blocking IO)最简单的一种IO模型,用户线程在进行IO操作的时候通常是个系统调用,用户线程会由用户空间进入内核空间,内核空间数据包准备好后会将数据拷贝到用户空间,这个时候线程在用户态继续执行。
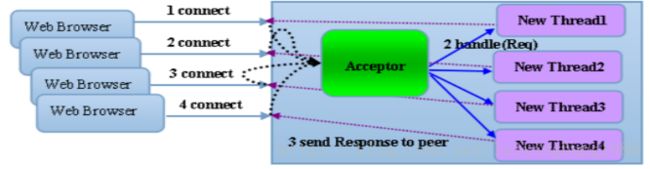
为每个客户端请求创建一个线程进行处理,处理完成后,线程销毁,是典型的一请求应答模型模型。
举例:你去火车站接人,一直在火车站门口等着,直到你想接的人出来。缺陷:一个人去接还好,很多人去接火车站就会堵的水泄不通【线程开辟的太多,消耗系统资源】
2.伪异步I/O编程模型。与BIO一致,为了解决线程创建的问题,后端采用线程池进行优化。
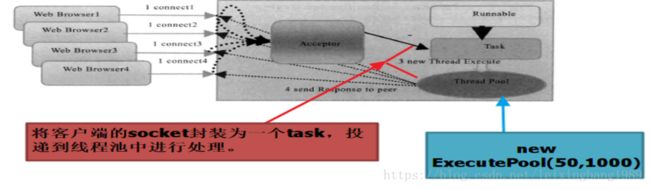
优点:无论客户端有多少并发请求量,服务器端都使用n个线程(n为线程池的活跃线程数)来处理和响应,降低了线程的消耗避免资源耗尽和宕机。
缺陷:当客户端发送消息缓慢或者网络传输较慢,正在活跃线程执行的任务会被阻塞(读取输入流是阻塞的),后续的IO消息会在队列中排队,队列堆满后,新任务会阻塞入队。后续所有的新的客户端连接都将超时。
3.NIO通信模型 (IO多路复用技术)

举例:火车站里面专门找了一个管理员【此时相当于单线程,reactor角色】。每个接站的人(handler)需要在管理员这里注册,每当有人到站【相当于io事件到达】管理员就会打电话通知人来接【相当于事件派发】。
3.NIO通信序列图

4.几种IO模型比较
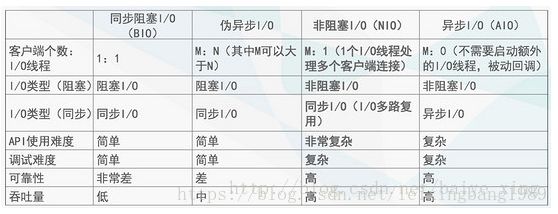
·由于NIO模型可靠性和吞吐量均较高,性能上与AIO相差不多,故选择NIO模型。
·使用java原生NIO模型API复杂,,类库繁杂,存在bug,自己开发可维护性差等情况。而netty健壮性、可拓展性、性能可靠性强,经历成百上千商业项目验证。搜索系统自身也集成了netty,故使用nettyNIO作为技术模型进行开发。
2.1 设计开发
最初的版本按照netty权威指南官方demo来进行开发,设计类如下:

二、设计开发&遇到的问题
服务器端写入EsServerHandler(模拟)

客户端EsClientHandler接收数据方式(模拟):
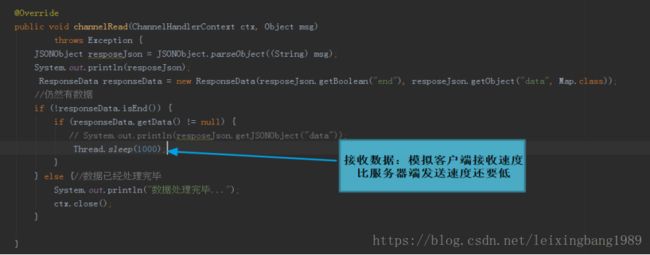
三、问题排查过程
使用抓包神器wireshark
客户端在收到若干条数据后,线程挂住,无法收到服务器端的数据。使用wireshark抓包后,发现服务器端不再发送数据,排除是客户端程序的问题。
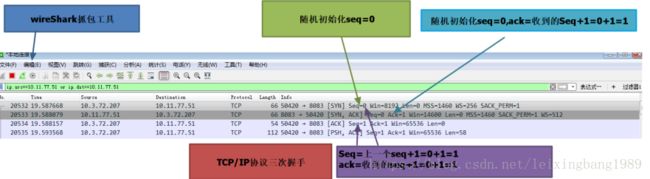
正常的数据发送过程

使用wireshark对服务器进行远程抓包(linux需要安装winpcap作为代理,安装方式:http://haohetao.iteye.com/blog/786545)发现服务器端无任何数据发出。
三、问题排查过程
将问题定位至服务器端:使用虚拟机监控和故障处理工具对服务器端进行排查。
top命令发现服务器端进程CPU飙升,且占用内存较大(RES-SHR=8G)。

使用top -Hp pid(top -Hp 4366 )查看哪些线程占用CPU资源高

排查线程占用CPU高的原因
任取一个占用cpu较高的线程,将线程id转为16进制。printf “%x\n” tid
![]()
![]()
jstack命令查看CPU利用率高的线程正在做什么。jstack pid |grep tid
统计GC线程数量为8个,发现所有CPU高的线程均为GC线程。
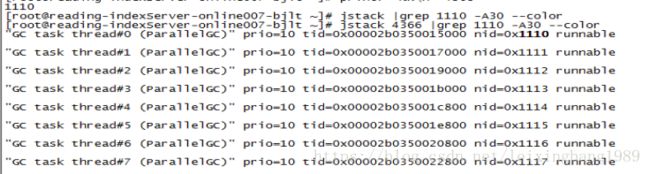
统计GC线程数量:
![]()
查看GC情况
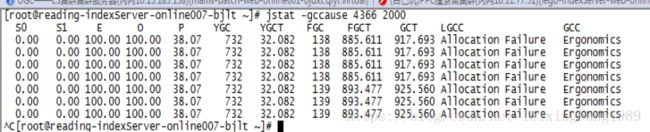
使用GC工具,每隔两秒输出一次,查看GC情况。发现Old分区被占满,FullGc频繁,且每次GC完成后Old分区占用率依然为100%。

·查看GC原因.发现每次GC原因均为上次GC失败
·查看堆内存占用情况。使用jmap -heap pid命令发现 Old Gen和eden 分区均被占满
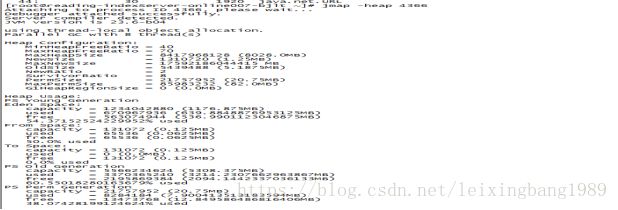
使用内存映像工具jmap 查看堆的占用情况(jmap -histo pid |less ),发现大量的对象均为buffer对象。

三、问题分析
问题分析:
1.内存中含有大量缓存的数据,而数据又无法发出,CPU被打满。当操作系统load较高的时候,操作系统很有可能来不及处理低优先级的网络IO事件,这就导致socket无法发出数据。
2.CPU几乎被打满的原因为FULL GC频繁,而jmap内存映像工具又告诉我们,系统中有大量的缓存待发送的数据。我们可以理解为服务器端生产数据一方为生产者,而服务器端发送socket一方为消费者,当生产者生产速度远大于消费者消费速度时,数据就会在内存中积压。这些积压的数据,最开始在eden分区,经过几次young GC时在s0 和s1区之间来回拷贝,最终进入Old Gen。这些数据并没有被socket发送出去,也就意味着依然会有引用指向他们。因此根据可达性分分析算法,每次FULL GC都不将老年代的垃圾进行有效的回收。这也是导致FULL GC频繁根本原因。
参考:(https://blog.csdn.net/zhoudaxia/article/details/26093321)
3.根据上述推断,我认为数据发送方式存在问题。
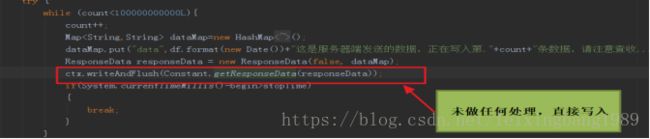
四、netty nio底层原理
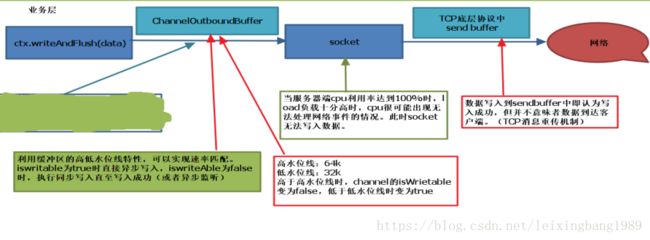
netty中的坑: ctx.writeAndFlush的确是将数据直接发送到socket中,根据TCP IP协议,当数据发送到socket的send buffer时,后续的发送过程都不需要我们去处理。但是当socket的发送速度低于writeAndFlush时,socket的send buffer会被占满。当该buffer被占满后,ctx.writeAndFlush而会将数据发送到netty的缓存ChannelOutBondBuffer中(如jmap工具结果所示),大量的数据会在heap中进行积压,从而导致Full GC 频繁,socket无法发出数据。
知识点:TCP协议能够保证数据通信的完整性。TCP/IP协议中是有消息重传机制的,如果由于网络等原因客户端无法正常收到数据,服务器端会根据ack信息对数据进行重传,只有当客户端确认收到消息后,才会从socket的缓存中删除(与MQ的ack机制非常相似)。参考链接:http://www.ruanyifeng.com/blog/2017/06/tcp-protocol.html
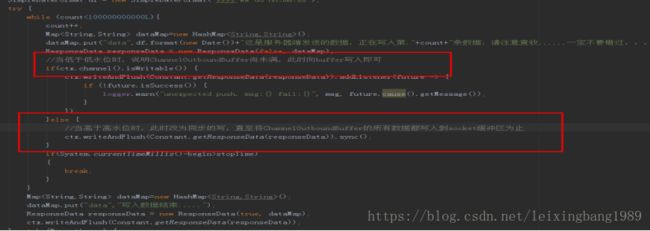
五、问题解决方式
解决方式:调用writeAndFlush()方法前先判断当前Channel的可写入状态,若状态为可写入说明待发送数据量并未堆积超限,可以进行异步发送;否则需要执行sync()方法等待发送数据真正成功写入socket的TCP发送缓冲区,然后在执行下一次的write操作,防止write速率过快导致内存溢出。
参考链接:http://yueyemaitian.iteye.com/blog/2102544
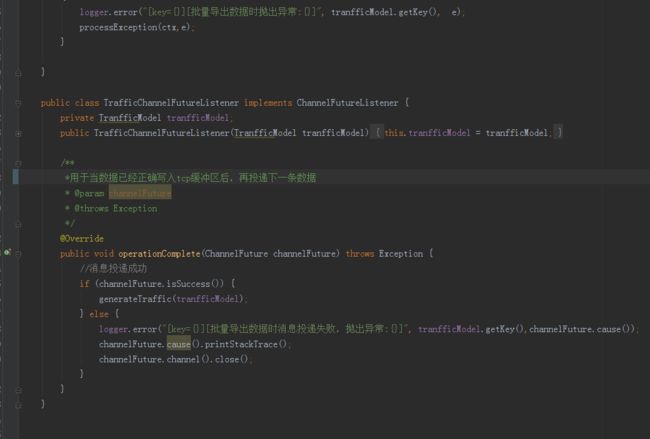
上述同步部分应有优化空间,可以采用监听事件形式,写入tcp缓存后,回调监听事件,再次投递下调数据。
五、总结。
netty的API简单,开发门槛较低,功能强大且性能较高。Netty修复了JDK已有的NIO bug,降低了我们开发的难度,但是使用简单也就意味着包含大量隐藏的坑,这些坑仅靠参考官方demo无法避免,必须理解底层实现原理才能解决。
网上有大量netty源码分析文档,本人在开发中也参考了其中一部分,感触颇深,愿大家多读源码,从此不踩坑。
——by 大邦