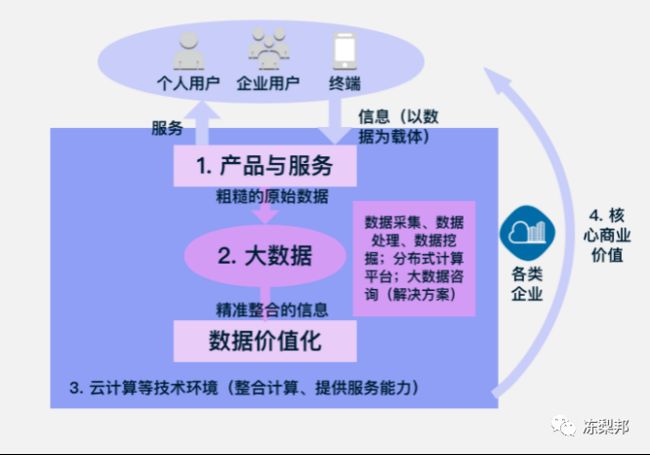
数据采集?预处理?爬虫?

数据采集是啥?
数据采集(DAQ)
定义:数据采集,又称数据获取,是利用一种装置,从系统外部采集数据并输入到系统内部的一个接口。数据采集技术广泛应用在各个领域。比如摄像头,麦克风,都是数据采集工具。
当下的数据体系中,将传统数据体系中没有考虑过的新数据源进行归纳与分类,可将其分为线上行为数据 与 内容数据 两大类。
Ø 线上行为数据:页面数据、交互数据、表单数据、会话数据等。
Ø 内容数据:应用日志、电子文档、机器数据、语音数据、社交媒体数据等。
大数据采集
大数据的主要来源:
1.商业数据
2.互联网数据
3.传感器数据
传统数据采集
1. 来源单一,数据量相对于大数据较小 (不符合4V特性);
2. 结构单一;
3. 关系数据库和并行数据仓库;
大数据的数据采集
1. 来源广泛,数据量巨大;
2. 数据类型丰富,包括结构化,半结构化,非结构化;
3. 分布式数据库;
传统数据采集的不足
1.传统的数据采集来源单一,且存储、管理和分析数据量也相对较小,大多采用关系型数据库和并行数据仓库即可处理。
2.对依靠并行计算提升数据处理速度方面而言,传统的并行数据库技术追求高度一致性和容错性,根据CAP理论,难以保证其可用性和扩展性。
大数据采集新的方法
1.系统日志采集方法
很多互联网企业都有自己的海量数据采集工具,多用于系统日志采集,如Hadoop的Chukwa,Cloudera的Flume,Facebook的Scribe等,这些工具均采用分布式架构,能满足每秒数百MB的日志数据采集和传输需求。
2.网络数据采集方法
网络数据采集是指通过网络爬虫或网站公开API等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。
3.其他数据采集方法
对于企业生产经营数据或学科研究数据等保密性要求较高的数据,可以通过与企业或研究机构合作,使用特定系统接口等相关方式采集数据。
预处理是啥?
定义:数据预处理(Data Preprocessing),是指在主要的处理以前对数据进行的一些处理。
产生背景:现实中的数据大体上都是不完整,不一致的脏数据,无法直接进行数据挖掘,或挖掘结果差强人意。为了提高数据挖掘的质量产生了数据预处理技术。
例如,从各互联网平台、网站上获取的数据。
其它定义:数据的预处理是指对所收集数据进行分类或分组前所做的审核、筛选、排序等必要的处理。
方法:
数据预处理有多种方法:
-
-
数据清理
-
数据集成
-
数据变换
-
数据归约
-
这些预数据处理技术在数据挖掘之前使用,大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间。
爬虫是啥?
上个世纪90年代以Google为代表的搜索引擎公司,为获取互联网上的Web页面信息,再由搜索引擎进行索引和存储从而为用户提供检索服务。这样以来就要求自动高效地获取互联网的信息,网络爬虫就是为了解决这些问题而生的。
目前已经进入了大数据时代,通过对海量数据的分析,能够产生极大商业价值。
数据的获取方式:
1. 企业产生的数据;
2. 数据平台购买的数据;
3. 政府/机构公开的数据;
4. 数据管理咨询公司的数据;
5. 爬取的网络数据;
爬虫的概念
定义一: 网络爬虫又称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
定义二: 向网站发起请求,获取资源后分析并提取有用数据的程序。
定义三: 一种互联网信息的自动化采集程序,代替人工对互联网中的数据进行自动采集和整理,以快速、批量的获取目标数据。
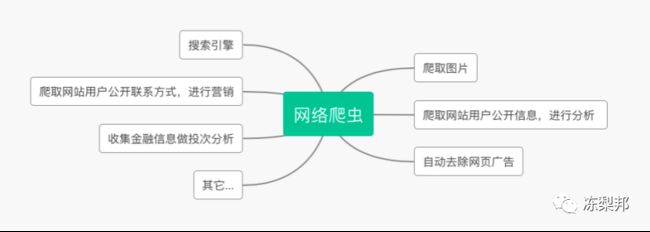
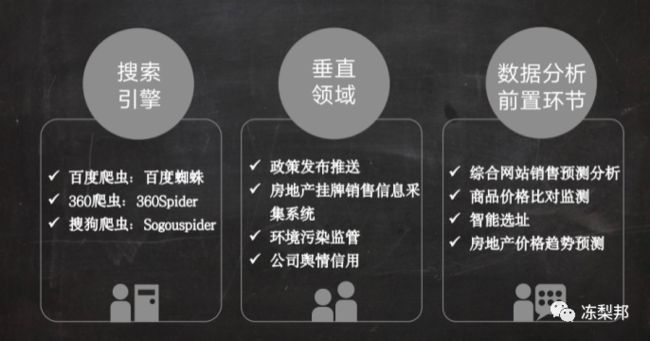
爬虫的用途
行业领域
爬虫的分类
通用网络爬虫和聚焦网络爬虫
1.通用网络爬虫:
-
-
爬取目标资源在全互联网中,爬取目标数据巨大。
-
-
对爬取性能要求非常高。应用于大型搜索引擎中,有非常高的应用价值。
-
通用网络爬虫的基本构成:初始URL集合,URL队列,页面爬行模块,页面分析模 块,页面数据库,链接过滤模块等构成。
-
通用网络爬虫的爬行策略:主要有深度优先爬行策略和广度优先爬行策略。
-
2.聚焦网络爬虫
-
-
将爬取目标定位在与主题相关的页面中。
-
主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
-
聚焦网络爬虫的基本构成:初始URL,URL队列,页面爬行模块,页面分析模 块,页面数据库,连接过滤模块,内容评价模块,链接评价模块等构成。
-
增量式爬虫和累积式爬虫
1.增量式网络爬虫
增量式更新指的是在更新的时候只更新改变的地方,而未改变的地方则不更新只爬取内容发生变化的网页或者新产生的网页,一定程度上能保证所爬取的网页,尽可能是新网页。
2.累积式爬虫
从某一个时间点开始,通过遍历的方式爬取系统所允许存储的和处理网页。
表层爬虫和深层爬虫
1.表层网页:
ü 爬取表层网页的信息的爬虫;
ü 不需要提交表单,使用静态的链接就能够到达的静态网页;
ü 所见既所爬;
2.深层网页:
隐藏在表单后面,不能通过静态链接直接获得,是需要提交一定的关键词之后才能够获取得到的网页。
重要的部分即为表单填写部分:
深层网络爬虫的基本构成:
-
-
URL列表
-
LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)
-
爬行控制器
-
解析器
-
LVS控制器
-
表单分析器
-
表单处理器
-
响应分析器
-
表单填写有两种类型:
-
-
基于领域知识的表单填写(建立一个填写表单的关键词库,在需要的时候,根据语义分析选择对应的关键词进行填写)
-
基于网页结构分析的表单填写(一般是领域只是有限的情况下使用,这种方式会根据网页结构进行分析,并自动的进行表单填写)
-
本期梨主|兵长
