竟然有人号称全网最全python正则,学不会去打他!!!
文章目录
- 抛砖引玉
- 结构化数据
- 非结构化数据
- 半结构化数据
- 非结构化的数据处理
- 结构化的数据处理
- 半结构化的数据处理
- python re模块
- 什么是正则表达式
- 正则表达式可以做什么?
- 正则匹配一般必要步骤
- 提供几个正则开发时,用得到的网站!
- compile函数
- match方法
- search方法
- findall方法
- finditer方法
- 列表与可迭代对象有什么不同
- 可迭代器对象与迭代器有什么区别(小白误区)
- split方法
- sub方法
- search与match函数有什么区别与不同?
- 如何快速匹配中文
- 贪婪模式与非贪婪模式
- 正则匹配大括号与中括号与小括号的区别总结
抛砖引玉
一般对于我们爬虫而言,需要爬取的是某个网站或者某个应用的内容,提取有用的价值。那么爬取的内容无疑是分为两种,非结构化数据与结构化数据
遇到非结构化数据我们如何处理?
答:现有数据,再有结构
遇到结构化数据我们又如何处理呢?
答:先有结构,再有数据
总结:对不同类型的数据我们应该采用不同的方式进行处理
笔者能不能说一下什么是非结构化数据,什么是结构化数据啊?我听着有点懵!
我应声答道:
结构化数据
结构化数据是指:由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。也称作行数据,一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
我给你举个例子把!
| 姓名 | 电话 | 家庭住址 |
|---|---|---|
| 张三 | 13682645831 | 安徽 |
| 李四 | 13546286999 | 济南 |
| 小明 | 13648971245 | 山东 |
总结:这就是典型的结构化数据,也是数据库常用的表,方便存取,数据一目了然,结构已经很清晰了,直接进行取值就可以了。
非结构化数据
非结构化数据是指:数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、HTML、各类报表、图像和音频/视频信息等等。那么我们经常跟我们爬虫打交道的就是HTML,例如如下代码
{";rsv_bdr";:";0";,";p5";:3}">{
'F':'778317EA',
'F1':'9D73F1E4',
'F2':'4C26DF6A',
'F3':'54E5263F',
'T':'1582260877',
'y':'DD7EBFFF'
}" href="http://www.baidu.com/link?url=y8YiZbpqtrwQEFdDjfPT15iC_enWhsFXI2YnC_LhE4ixGH1UTKhqZUvxEpmEMEgU" target="_blank">新闻中心首页_新浪网">">">新浪网新闻中心是新浪网最重要的频道之一,24小时滚动报道国内、国际及社会新闻。每日编发新闻数以万计。">" href="http://www.baidu.com/link?url=y8YiZbpqtrwQEFdDjfPT15iC_enWhsFXI2YnC_LhE4ixGH1UTKhqZUvxEpmEMEgU" class="c-showurl" style="text-decoration:none;">news.sina.com.cn/ c-tools" id="tools_10917320878357133208_3" data-tools="{";title";:";新闻中心首页_新浪网";,";url";:";http://www.baidu.com/link?url=y8YiZbpqtrwQEFdDjfPT15iC_enWhsFXI2YnC_LhE4ixGH1UTKhqZUvxEpmEMEgU";}">">"> - {'rsv_snapshot':'1'}" href="http://cache.baiducontent.com/c?m=9d78d513d9d437ad4f9c94697c61c0171e40c72362d88a5339968449e079461d1023a2ac2755515f8f966b6776fe1403fdf041236b1e&;p=882a9546ccdd5be512b1c7710f5e&;newp=882a9546929f15ef0be29627175092695d0fc20e38d6db01298ffe0cc4241a1a1a3aecbf22291601d1cf786c0aaa4f56eaf133723d0034f1f689df08d2ecce7e6bd47374&;user=baidu&;fm=sc&;query=%D0%C2%CE%C5&;qid=a94b7c1a002530dd&;p1=3" target="_blank" class="m">百度快照"> - https://www.baidu.com/tools?url=http%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dy8YiZbpqtrwQEFdDjfPT15iC_enWhsFXI2YnC_LhE4ixGH1UTKhqZUvxEpmEMEgU&;jump=https%3A%2F%2Fkoubei.baidu.com%2Fp%2Fsentry%3Ftitle%3D%02%E6%96%B0%E9%97%BB%03%E4%B8%AD%E5%BF%83%01%E9%A6%96%E9%A1%B5%01_%01%E6%96%B0%E6%B5%AA%01%E7%BD%91%01%26q%3D%E6%96%B0%E9%97%BB%26from%3Dps_pc4&;key=surl" target="_blank" class="m" data-click="{'rsv_comments':'1'}" data-from="ps_pc4">378条评价
总结:这就是典型的非结构化数据
当然了还有一种半结构化数据,这里不得不提,爬虫也是经常遇到。
半结构化数据
半结构化数据是指:是结构化数据的一种形式,虽不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,也被称为自描述的结构。比如xml跟json,如下代码就是json格式
json文件:
{
"name":"王小二",
"phone":"13624568542",
"address":"陕西"
}
那么可以用什么进行处理呢?
非结构化的数据处理
答:可以使用正则表达式,Xpath,css,对网页源码进行处理
结构化的数据处理
答:如果这个表在网页上依然得使用Xpath,css选择器,正则表达式,当然如果在数据库中,那么就极为方便,增加键值也是十分方便的。
半结构化的数据处理
答:从网页获取的json数据文本转换为json格式,使用python进行取值等操作

咳咳,好了好了,说重点
说了这么多,大家都知道学正则可以做什么?我们今天就要来学习正则。加油!
python re模块
什么是正则表达式
答:通常被用来检索,替换哪些符合某个模式或规则的文本
正则表达式可以做什么?
答:正如概念所说,无非是匹配与过滤,记住正则永远在做这两件事,要么生要么死!
正则匹配一般必要步骤
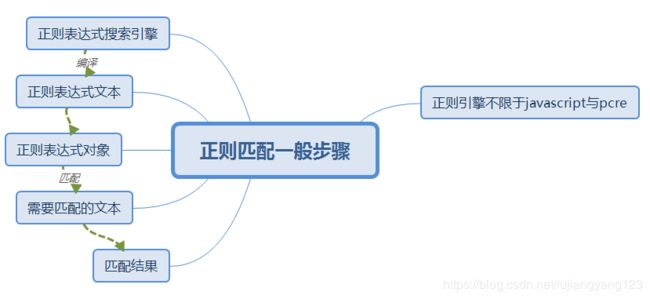
总结:正则表达式引擎编译表达式字符串得到的对象,包含应如何匹配得信息,正则表达式对象对文本进行匹配后得到的结果,包含了这次成功匹配的信息,可以得到匹配后的字符串,以及group()分组,span()索引信息等
提供几个正则开发时,用得到的网站!
请点我
请点我
请点我
温馨提示:具体用法,请自我研究,这里就不一一讲解!
compile函数
compile函数用来干嘛的呢?
答:compile用于编译正则表达式,生成一个Pattern对象,PatternPattern对象包括:match方法,search方法,findall方法,finditer方法,split方法,sub方法,这些常用方法将再下面逐一讲解。
温馨提示:下面讲解的方法都运行了compile函数,也可以不用。
match方法
那么match方法的语法格式是什么样的呢?
答:match(string[, pos[, endpos]])
参数详解:
string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起 始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
醉翁之意不在酒,在乎山水之间也!还是少废话,看代码
import re
# 只匹配一个数字
pattern1=re.compile(r'\d')
res1=pattern1.match("15236485624")
print(res1)
#匹配多个数字
pattern2=re.compile(r'\d+')
res2=pattern2.match("15236485624")
print(res2)
#没匹配到的原因是,match默认从第一个匹配到最后一个,如果开头不是数字直接返回None
pattern3=re.compile(r'\d+')
res3=pattern3.match("phone1:15236485624")
print(res3)
#匹配hello,并忽略大小写
pattern4=re.compile(r'([a-z]+)([a-z+])',re.I)
res4=pattern4.match('HelLo world')
print(res4)
#加上pos跟endpos参数即可成功匹配,本代码可以只添加pos参数也是可以endpos用默认的
pattern5=re.compile(r'\d+')
res5=pattern5.match("phone1:15236485624",7,18)
print(res5)
pattern6=re.compile(r'(\d{11}) (\d{11})')
res6=pattern6.match('15236485624 45684953624')
print(res6)
#查看匹配成功的整个字符串
print(res6.group(0))
#查看匹配成功的第一个分组匹配成功的字符串
print(res6.group(1))
#查看匹配成功的第一个分组匹配成功的字符串
print(res6.group(2))
#返回元组类型的所有组匹配成功的字符串
print(res6.groups())
#返回匹配成功的第一个分组匹配成功的字符串的起始位置
print(res6.start(1))
#返回匹配成功的第一个分组匹配成功的字符串的结束位置
print(res6.end(1))
#返回匹配成功的第一个分组匹配成功的字符串起始与终止索引,以元组形式返回
print(res6.span(1))
#返回匹配成功的第二个分组匹配成功的字符串的起始位置
print(res6.start(2))
#返回匹配成功的第二个分组匹配成功的字符串的结束位置
print(res6.end(2))
#返回匹配成功的第二个分组匹配成功的字符串起始与终止索引,以元组形式返回
print(res6.span(2))
#使用start函数查看匹配的pos参数
print(res6.start())
# 使用end()函数查看匹配的endpos参数
print(res6.end())
#以元组的形式查看pos参数跟endpos参数
print(res6.span())
'''
运行结果:
None
15236485624 45684953624
15236485624
45684953624
('15236485624', '45684953624')
0
11
(0, 11)
12
23
(12, 23)
0
23
(0, 23)
'''
单独使用match方法
import re
#单独使用match函数
#只匹配一个数字
res1=re.match(r'\d',"15236485624")
print(res1)
print(res1.group())
'''
运行结果:
1
'''
search方法
那么search方法的语法格式是什么样的呢?
search(string[, pos[, endpos]])
参数详解:
string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起 始和终点位置,默认值分别是 0 和 len (字符串长度)。 当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
醉翁之意不在酒,在乎山水之间也!还是继续少废话,看代码
import re
#匹配字符串中的电话号码,这里注意:在match方法中是匹配不到的,并且是一次匹配
#匹配phone_one的电话号码
pattern1=re.compile("\d+")
res1=pattern1.search('phone_one:14523564895 phone_two:48625486945')
print(res1)
#匹配phone_two的电话号码
pattern2=re.compile("\d+")
res2=pattern2.search('phone_one:14523564895 phone_two:48625486945',21,)
print(res2)
#查看匹配的数据
print(res2.group())
#查看匹配的起始位置
print(res2.start())
#查看匹配的终止位置
print(res2.end())
#查看匹配的数据在原字符串中的起始位置与结束位置
print(res2.span())
'''
运行结果:
48625486945
32
43
(32, 43)
'''
'''
单独使用search方法
import re
#单独使用search函数
#匹配phone_one的电话号码
pattern1=re.compile("\d+")
res1=re.search(r'\d+','phone_one:14523564895 phone_two:48625486945')
print(res1)
print(res1.group())
'''
运行代码:
14523564895
'''
findall方法
那么findall方法的语法格式是什么样的呢?
findall(string[, pos[, endpos]])
参数详解:
string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起 始和终点位置,默认值分别是 0 和 len (字符串长度)。 findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
常用元字符:
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意一个字符 |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
| ? | 重复匹配0次或1次 |
| * | 重复匹配0次或更多次 |
| + | 重复匹配1次或更多次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n~m次 |
| [a-z] | 匹配[a-z]任意字符 |
| [abc] | a/b/c中的任意一个字符 |
| {n} | 重复n次 |
| \b | 匹配单词的开始和结束 |
| \d | 匹配数字 |
| \w | 匹配字母,数字,下划线 |
| \s | 匹配任意空白,包括空格,制表符(Tab),换行符 |
| \W | 匹配任意不是字母,数字,下划线的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开始和结束的位置 |
| [^a] | 匹配除了a以外的任意字符 |
| [^(123|abc)] | 匹配除了123或者abc这几个字符以外的任意字符 |
代码示例:
import re
#findall用法
#\d匹配数字,将匹配的数据以列表形式返回
pattern1=re.compile("\d")
result1=pattern1.findall("hello 123 567")
print(result1)
#\d+匹配一个或者多个数字,如果是多个数字,则必须连续
pattern2=re.compile('\d+')
result2=pattern2.findall("hello 124 567 eu98de")
print(result2)
#\d{3,}匹配3次或者多次必须多次,必须连续
pattern3=re.compile("\d{3,}")
result3=pattern3.findall("hellp 123 456 uu44jk655")
print(result3)
#\d{3}连续匹配3次
pattern4=re.compile("\d{3}")
result4=pattern4.findall("hellp 123 456 uu44666jk633")
print(result4)
#\d{1,2}可以匹配一次,也可以匹配两次,以更多的优先
pattern5=re.compile('\d{1,2}')
result5=pattern5.findall('hellp 123 456 uu4466jk633')
print(result5)
#re.I 表示忽略大小写,[a-z]匹配a-z的字母5次
pattern6=re.compile("[a-z]{5}",re.I)
result6=re.findall('hello 123 456 uu4466jk633')
print(result6)
#\w+匹配数字,字母,下划线,一次或者多次
pattern7=re.compile("\w+")
result7=pattern7.findall("hellp 123 456 uu4466jk633")
print(result7)
#\W匹配不是下划线,字母,数字
pattern8=re.compile("\W+")
result8=pattern8.findall("hellp 123 456 uu4466jk633")
print(result8)
#[\w\W]+ 可以匹配所有的字符,一次或者多次
pattern8=re.compile('[\w\W]+')
result9=pattern8.findall("hellp 123 456 uu4466jk633")
print(result9)
#[abc]+ 匹配a或者b 或者c一次或者多次
pattern10= re.compile("[abc]+")
result10=pattern10.findall('abc 123 456 abc4466jk633')
print(result10)
#[^abc|123]+ 匹配不是abc或者123的字符
pattern11 = re.compile('[^abc|123]+')
result11 = pattern11.findall("hellp 123 456 uu4466jk633%^&*(")
print(result11)
#.*匹配任意字符,除了换行符
pattern12=re.compile(".*")
result12=pattern12.findall("hellp 123 456 uu4466jk633%^&*(\n")
print(result12)
#re.I表示忽略大小写,[a-z]{5}匹配a-z得字母5次
#只查找字符串0-8之间得字符,要前不要后(左闭右开)
pattern13=re.compile('[a-z]{8}',re.I)
result13=pattern13.findall("hellOpython123 456 u4466Wjk633",0,8)
print(result13)
'''
运行结果:
['1', '2', '3', '5', '6', '7']
['124', '567', '98']
['123', '456', '655']
['123', '456', '446', '633']
['12', '3', '45', '6', '44', '66', '63', '3']
['hello']
['hellp', '123', '456', 'uu4466jk633']
[' ', ' ', ' ']
['hellp 123 456 uu4466jk633']
['abc', 'abc']
['hellp ', ' 456 uu4466jk6', '%^&*(']
['hellp 123 456 uu4466jk633%^&*(', '', '']
['hellOpyt']
'''
单独使用findall方法
import re
#单独使用findall方法
#\d匹配数字,将匹配的数据以列表形式返回
result1=re.findall(r"\d","hello 123 567")
print(result1)
'''
运行代码:
['1', '2', '3', '5', '6', '7']
'''
finditer方法
finditer方法是什么,怎么这么像前面讲的findall啊?
答:没错,你犀利的眼神,正是验证了finder方法的行为与findall是比较形似的,也是搜索整个字符串,获得所有匹配的结果,但是,咳咳,他返回的是一个可迭代对象,那么这里我就说一下,可迭代对象与迭代器有什么不同!列表与可迭代对象有什么不同!
列表与可迭代对象有什么不同
列表与可迭代对象有什么不同?
答:列表需要大量的空间,而可迭代对象不需要消耗内存空间,只有在你想看的时候,你可以揭开面纱去看一看!!!
可迭代器对象与迭代器有什么区别(小白误区)
可迭代对象与迭代器有什么区别?
答:首先可迭代对象包含迭代器,如果一个对象拥有了__iter__方法,他就是一个可迭代对象,如果一个对象拥有了next方法,他就是一个迭代器。那么反之定义可迭代对象,必须实现__iter__方法;定义迭代器必须实现next方法
import re
pattern1=re.compile(r'\d+')
res1=pattern1.finditer("phone_one:78645893654,phone_two:789456123")
#打印的结果是一个迭代的对象需要遍历取值
print(res1)
#进行遍历取出匹配成功的值,与打印匹配成功字符串的索引
for i in res1:
print("匹配成功的字符串{},匹配成功字符串的索引{}".format(i.group(),i.span()))
'''
运行结果:
匹配成功的字符串78645893654,匹配成功字符串的索引(10, 21)
匹配成功的字符串789456123,匹配成功字符串的索引(32, 41)
'''
split方法
咦,这个split方法真熟悉啊,不就是这个分割嘛,返回列表形式的函数吗?
答:没错就是他,他也可以用于正则当中,正则配上这个函数,不是如鱼得水吗,不是跃然纸上的吗,哈哈哈。
废话少说,我知道醉翁之意不在酒,在乎山水之间也!!!
import re
#使用split进行分割为列表
pattern1=re.compile(r'[\s\,\.]+')
res1=pattern1.split('a,b.c d')
print(res1)
'''
运行结果:
['a', 'b', 'c', 'd']
'''
单独使用split方法
import re
#单独使用split方法
#使用split进行分割为列表
res1=re.split(r'[\s\,\.]+','a,b.c d')
print(res1)
'''
运行代码:
['a', 'b', 'c', 'd']
'''
sub方法
之前不是学过一个替换的函数吗?
答:真聪明,之前的确有个替换的函数叫replace(),我们用一个例子来说明他的心有余,而力不足之处吧!
例如:将字符串"电话号码phone1:454-4562-1546请联系我,电话号码phone2:789-456-123请联系我"中的中文与横杠去掉,使用replace虽然可以完成但是异常复杂,稍微复杂一下,replace就失去作用了,让我们看一下正则里的sub()是如何替换的。
sub方法的语法是什么?
答:sub(repl, string[, count])
参数详解:
repl 可以是字符串也可以是一个函数:如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回 替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编 号 0; 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一 个字符串用于替换(返回的字符串中不能再引用分组)。count 用于指定最多替换次数,不指定时全部替换。
代码示例:
count的用法
import re
#不加匹配次数参数,默认全部匹配
res1 = re.sub(r"([-]|[\u4e00-\u9fa5]+)",'',"电话号码phone1:454-4562-1546请联系我,电话号码phone2:789-456-123请联系我")
print(res1)
#只匹配一次
res2 = pattern3.sub('',"phone1:454-4562-1546,phone2:789-456-123",1)
print(res2)
'''
运行结果:
phone1:45445621546,phone2:789456123
phone1:4544562-1546,phone2:789-456-123
'''
总结:sub方法不加count参数,默认全部替换
repl参数的使用
import re
#使用函数用""替换-
pattern3=re.compile("([-])")
def function(m):
return ""
print(pattern3.sub(function,"phone1:454-4562-1546,phone2:789-456-123"))
'''
运行结果:
phone1:45445621546,phone2:789456123
'''
引用分组的使用
import re
pattern2=re.compile(r"(\w+) (\w+)")
res=pattern2.search("hello1 123, hello2 456")
print(res)
#进行引用分组
res2=pattern2.sub(r'\2 \1',"hello1 123, hello2 456")
print(res2)
'''
运行代码:
123 hello1, 456 hello2
'''
单独使用sub方法
import re
#使用函数用""替换-
res1 = re.sub(r"([-])",'',"phone1:454-4562-1546,phone2:789-456-123")
print(res1)
'''
运行代码:
phone1:45445621546,phone2:789456123
'''
总结:使用函数返回值进行替换,使sub方法功能更加强大
search与match函数有什么区别与不同?
答:search比match较为先进,search是任意位置开始匹配,返回的是match对象;而match只能从起始固定位置匹配,如果开头就不符合,直接返回None
代码示例:
import re
pattern1=re.compile("\d+")
res1=pattern1.search('phone_one:14523564895 phone_two:48625486945')
print(res1)
res2=pattern1.match('phone_one:14523564895 phone_two:48625486945')
print(res2)
'''
运行结果:
None
'''
如何快速匹配中文
如何快速匹配中文?
答:在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [\u4e00-\u9fa5]+,这里说主要是因为这个范围并不完 整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
代码示例:
import re
#进行中文的匹配
pattern=re.compile('\u4e00-\u9fa5')
res=pattern.findall("python:蟒蛇")
print(res)
'''
运行结果:
['蟒蛇']
'''
贪婪模式与非贪婪模式
什么是贪婪模式?
答:贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * )
什么是非贪婪模式?
答:非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? )
注意:python里数量词默认是贪婪的!
代码示例:
import re
#贪婪模式,尽可能多的匹配c,所以全部匹配了c
pattern1=re.compile(r'abbc*')
res1=pattern1.findall(r'abbccc')
print(res1)
#非贪婪模式,尽可能的少匹配c,所以只匹配了一个c
pattern2=re.compile(r'abbc*?')
res2=pattern2.findall(r'abbccc')
print(res2)
'''
运行代码:
['abbccc']
['abb']
'''
正则匹配大括号与中括号与小括号的区别总结
博主,我有个埋藏了好久的问题想问你?就是能不能说一下,正则匹配大括号与中括号与小括号的区别?
我随声答道:
()是提取匹配的字符串,表达式中有几个()就有几个相应的匹配的字符串结果,一般使用group()查看.
[]是定义匹配的字符范围,比如[a-z],当然了你也可以这样[a,b,c,d,e,f…],也可以进行取反比如[^a],另外中括号里的字符不再有特殊的含义,比如[.*]代表匹配.或者*。
{}一般用来表示匹配的长度,比如{1}只匹配一次,{1,2}最少匹配一次,最多匹配两次。
注意:正则项目讲解,将再下一篇文章中娓娓道来,还请客观耐心等待!!
来一波,推送吧!
群号:781121386
群名:人生苦短,我学编程
欢迎大家加入我们,一起交流技术!!!
