Elasticsearch对Hbase中的数据建索引实现海量数据快速查询
我已将项目代码上传,地址https://github.com/xiazi123/Test
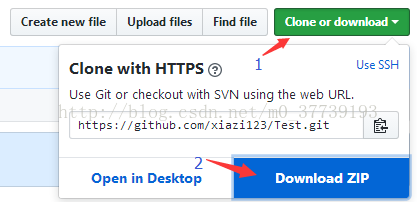
一、将项目导入myeclipse中
方法1:
将下载好的文件(是解压es_hbase6文件夹而不是Test-master)解压到你myeclipse的Workspaces目录中,然后在myeclipse中右键点击Import导入项目
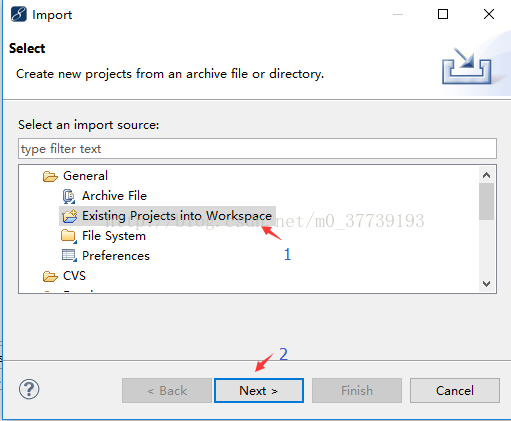
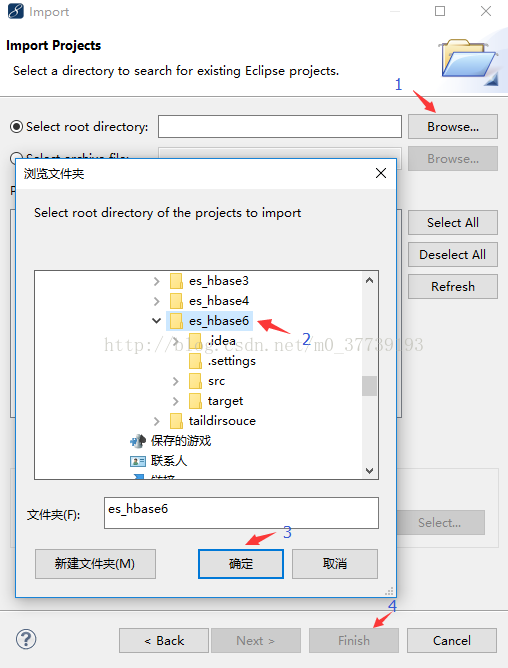
方法2:
将下载好的文件解压到你的Windows桌面,然后在myeclipse(我这里用的是MyEclipse 10.7.1,如果你的版本不同,界面和选项会略有不同)中右键点击Import导入项目
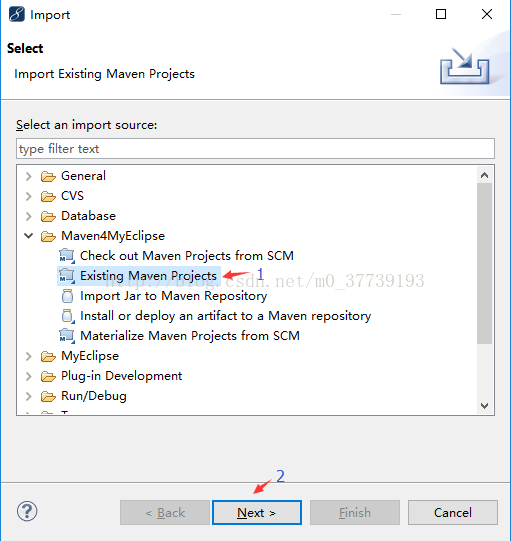
导入成功

二、准备工作:
1.运行这个项目你得安装有hadoop和hbase集群,zookeeper也安装上吧,反正我是不习惯用hbase自带的zookeeper而是自己安装的zookeeper,我安装的都是cdh5.5.2版,的这里的安装步骤我就不累述了,如果你已安装可忽略这步,若没有则可参考我的另两篇文章http://blog.csdn.net/m0_37739193/article/details/71222673和http://blog.csdn.net/m0_37739193/article/details/72457879
2.安装Elasticsearch集群(我的Linux为Centos 7.2)
(1)下载elasticsearch-2.2.0.tar.gz,下载地址:http://download.csdn.net/download/m0_37739193/9985530执行tar -zxvf elasticsearch-2.0.0.tar.gz解压
[hadoop@h153 ~]$ tar -zxvf elasticsearch-2.0.0.tar.gz
(2)同步到其他两个节点:
[hadoop@h153 ~]$ scp -r elasticsearch-2.2.0/ hadoop@h154:/home/hadoop/
[hadoop@h153 ~]$ scp -r elasticsearch-2.2.0/ hadoop@h155:/home/hadoop/
(3)修改配置文件config/elasticsearch.yml
[hadoop@h153 elasticsearch-2.2.0]$ vi config/elasticsearch.yml
添加:
cluster.name: my-application
node.name: node-1
network.host: 192.168.205.153
添加防脑裂配置:
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["192.168.205.153","192.168.205.154","192.168.205.155"]添加:
cluster.name: my-application
node.name: node-2
network.host: 192.168.205.154
添加防脑裂配置:
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["192.168.205.153","192.168.205.154","192.168.205.155"]
[hadoop@h155 elasticsearch-2.2.0]$ vi config/elasticsearch.yml
添加:
cluster.name: my-application
node.name: node-3
network.host: 192.168.205.155
添加防脑裂配置:
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["192.168.205.153","192.168.205.154","192.168.205.155"]
注意:如果要配置集群需要两个节点上的elasticsearch配置的cluster.name相同,都启动可以自动组成集群,nodename随意取但是集群内的各节点不能相同
(4)安装es监控插件(三台虚拟机都装,后来感觉一台装就可以吧,有时间验证一下)
[hadoop@h153 ~]$ cd elasticsearch-2.2.0/bin/
[hadoop@h153 bin]$ ./plugin install mobz/elasticsearch-head
-> Installing mobz/elasticsearch-head...
Trying https://github.com/mobz/elasticsearch-head/archive/master.zip ...
Downloading ..................................................................................DONE
Verifying https://github.com/mobz/elasticsearch-head/archive/master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed head into /home/hadoop/elasticsearch-2.2.0/plugins/head在已经启动了hadoop、hbase、zookeeper集群后再启动es集群
[hadoop@h153 ~]$ ./elasticsearch-2.2.0/bin/elasticsearch
[hadoop@h154 ~]$ ./elasticsearch-2.2.0/bin/elasticsearch
[hadoop@h155 ~]$ ./elasticsearch-2.2.0/bin/elasticsearch
4.导入hbase库中的测试数据存放在你指定的目录下C:\Users\huiqiang\Desktop\es\doc1.txt(内容以Tab键分隔)
1a hbase介绍及安装 阿里巴巴 hbase的服务器体系结构遵从简单的主从服务架 在很多图片上传以及文件下载操作的时候在很多图片上传以及文件上传下载操作的时候
2b docker的实战经验分享 百度 paas从2008年万众瞩目到2012年遭受质疑 最近十天在做一个博客系统,因为域名服务器都闲置已久
3c 实时推荐系统的方式 腾讯 推荐系统介绍,自从1992年施乐的科学家为了解决信息 这篇文章最要分享的是使用Apache的poi来实现数据导出到execl的功能,这里提供三种解决方案
4d hive的优化总结 华为 优化可以分为几个方面着手 在商品详情页处理这里的时候,因为我爱你
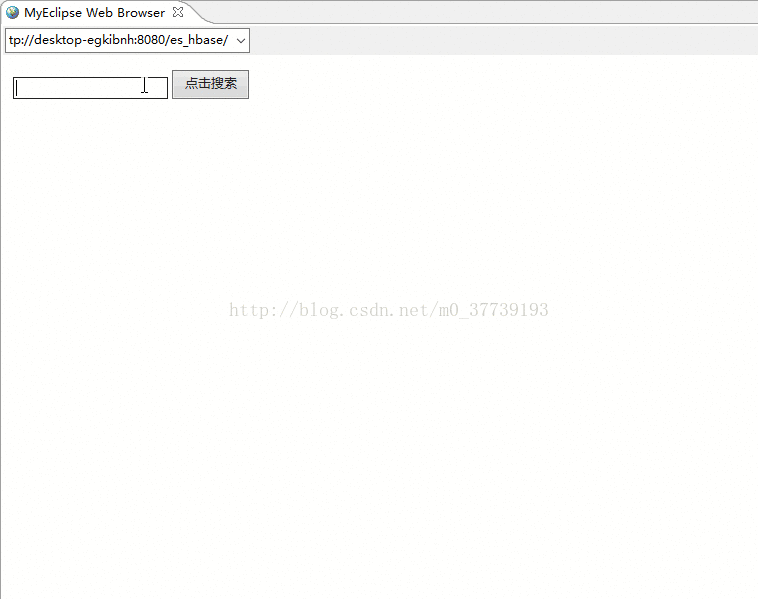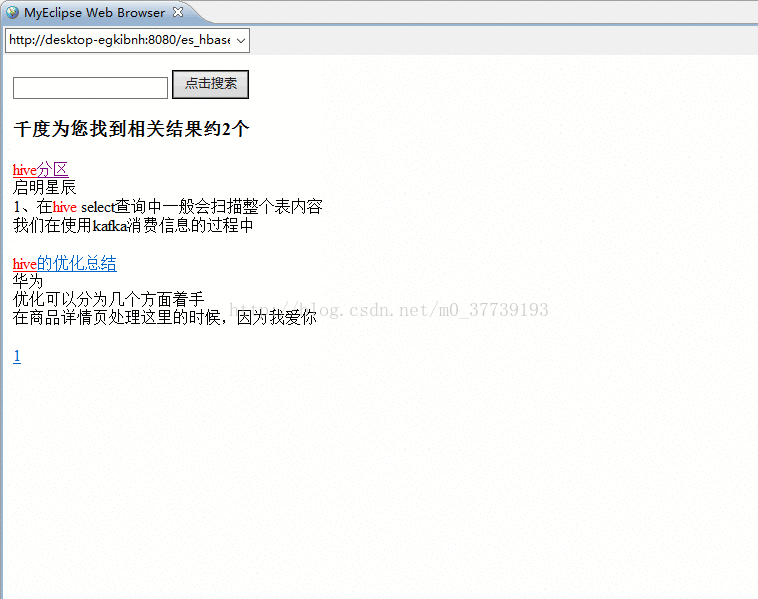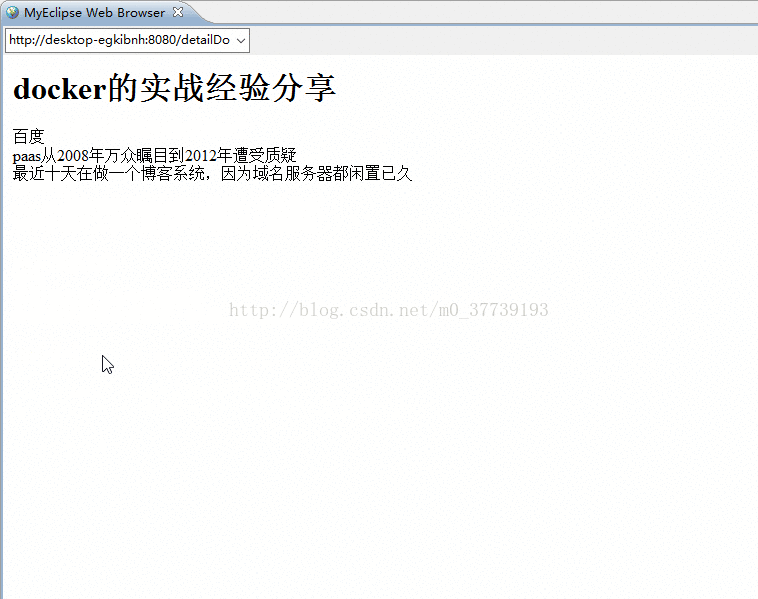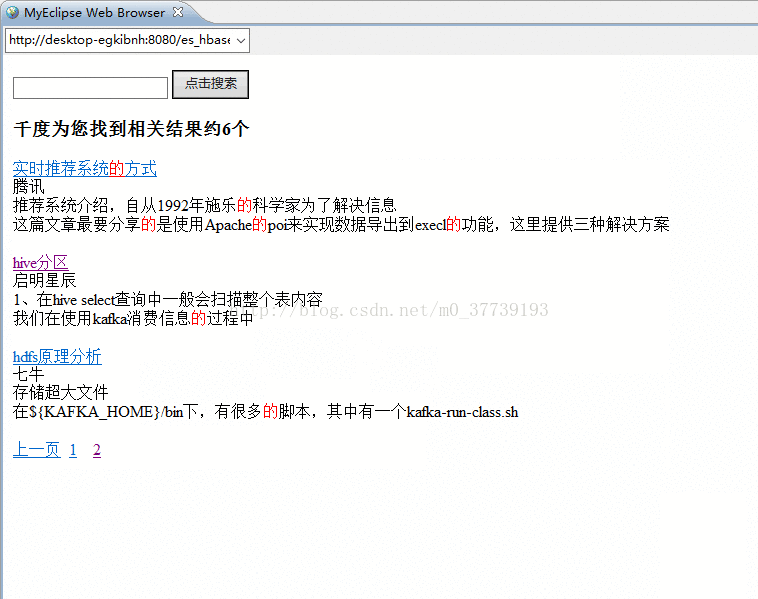
5e hive分区 启明星辰 1、在hive select查询中一般会扫描整个表内容 我们在使用kafka消费信息的过程中
6f hdfs原理分析 七牛 存储超大文件 在${KAFKA_HOME}/bin下,有很多的脚本,其中有一个kafka-run-class.sh
5.在hbase中建立相应的表
hbase(main):010:0> create 'doc','cf1'
相对应HbaseUtils.java中的代码为

三、运行项目:
1.在EsController.java右击运行项目
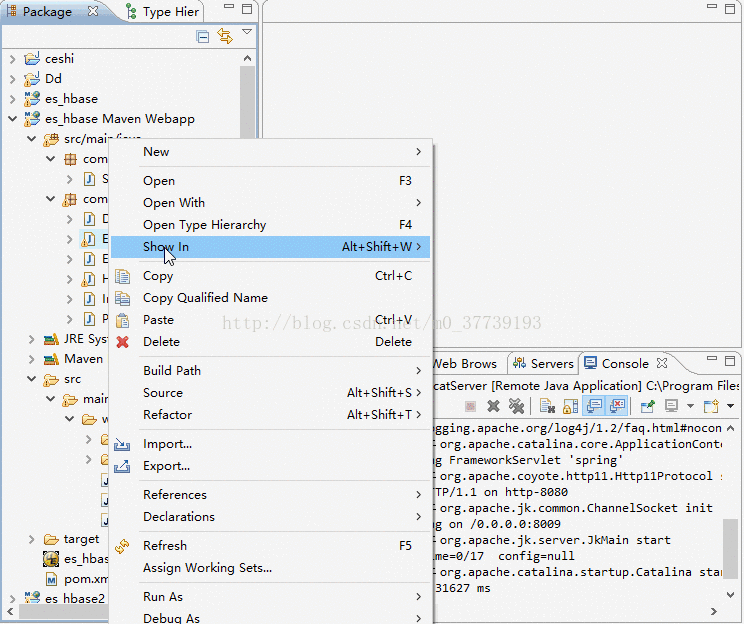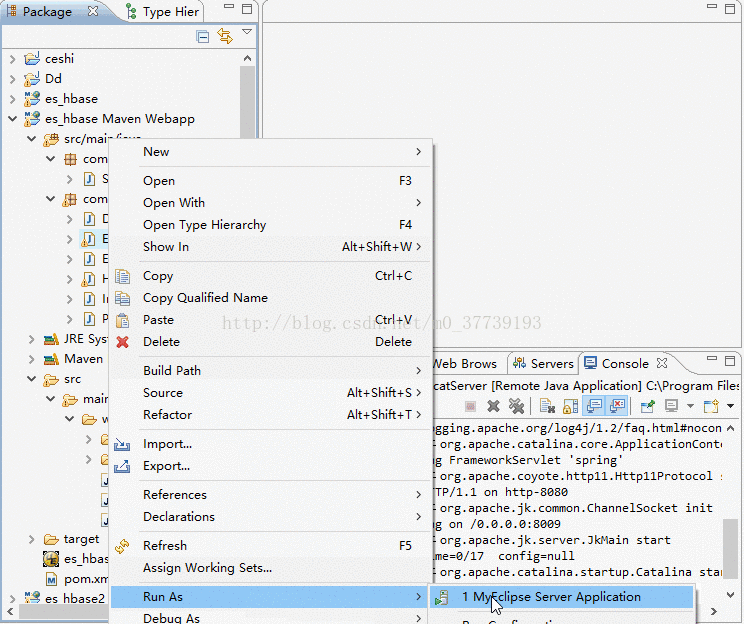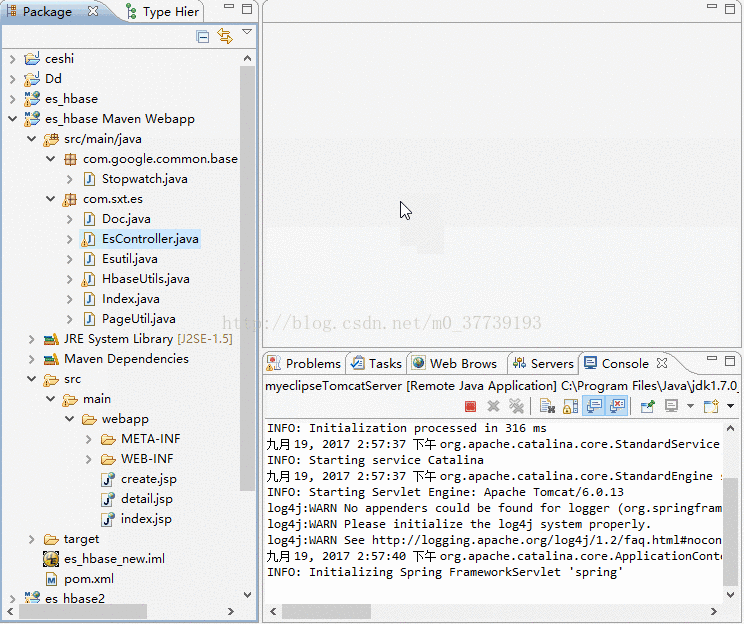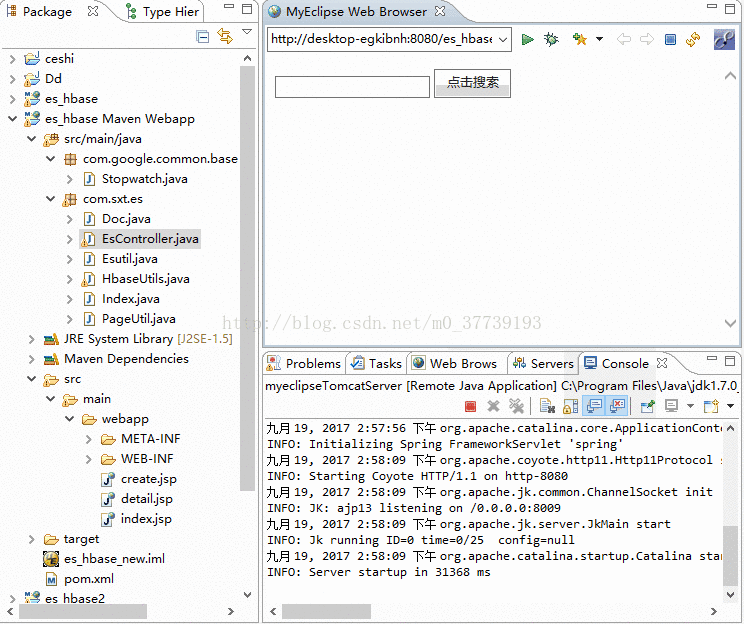
2.登录http://desktop-egkibnh:8080/es_hbase/create.jsp
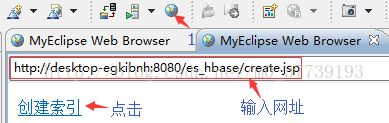
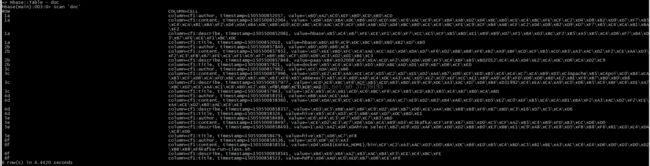
3.点击创建索引,则会往hbase中插入数据并且在es中建立索引(在谷歌浏览器输入http://192.168.205.153:9200/_plugin/head/):
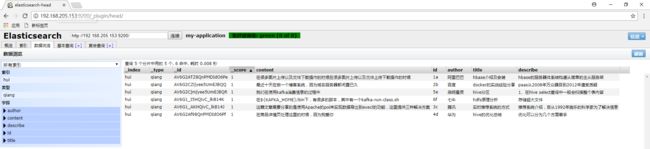
4.在http://desktop-egkibnh:8080/es_hbase/中输入搜索的关键字后搜索:
四、思考:
1.后来我想增加对hbase表中的rowkey在es中也建立索引,但却总是失败。主要遇到了两个问题:
(1)对rowkey设置高亮后搜索rowkey点击无法返回内容。
(2)对rowkey的搜索只能是全部搜索,比如rowkey为abcd,那么只能输入abcd才能搜索到,输入ab则搜索不到。其实并不只rowkey是这样,对所有的英文单词(hive)和数字(2008)都只能全部搜索而不能部分匹配。
后来想想其实rowkey也没必要建立索引,你可以把需要搜索的信息放在列里,rowkey可以用UUID生成来保证每条数据的唯一性,UUID就没必要作为搜索信息了吧。但强迫症的我还是想实现也能够对rowkey建立索引搜索,如果大家有谁能实现了的话,还希望能告我一下,大家一起探讨学习一下哈。
解决问题(2)
解决该问题可使用部分匹配(可参考http://blog.csdn.net/m0_37739193/article/details/78291535),目前我整出了三种类型供大家在不同场景下使用。
注意:在运行项目之前需要先手动用文件创建索引。
类型一
[hadoop@h153 elasticsearch-2.2.0]$ vi hehe.json
{
"settings": {
"number_of_shards": 1,
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
},
"mappings":{
"qiang":{
"dynamic":"strict",
"properties":{
"id":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"title":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"describe":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"author":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"},
"content":{"type":"string","store":"yes","index":"analyzed","analyzer": "autocomplete","search_analyzer": "standard"}
}
}
}
}[hadoop@h153 elasticsearch-2.2.0]$ curl -XPOST '192.168.205.153:9200/hui' -d @hehe.json
最终搜索效果:

局限性:
1.对于一个英文单词只能从前面往后而不能任意输入,比如hive这个单词输入hiv能命中,而输入ive则不可以。
2.只能高亮显示整个英文单词,而不能高亮显示搜索的内容,比如hive这个单词只能这样显示hive,而不能这样显示hive。
3.对特殊字符无能为力,如”_“、”}“、”/“
类型二
[hadoop@h153 elasticsearch-2.2.0]$ vi hehe.json
{
"settings": {
"analysis": {
"filter": {
"trigrams_filter": {
"type": "ngram",
"min_gram": 1,
"max_gram": 5
}
},
"analyzer": {
"trigrams": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"trigrams_filter"
]
}
}
}
},
"mappings":{
"qiang":{
"dynamic":"strict",
"properties":{
"id":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"title":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"describe":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"author":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"},
"content":{"type":"string","store":"yes","index":"analyzed","analyzer": "trigrams","search_analyzer": "standard"}
}
}
}
}最终搜索效果:

局限性:
1.这个也不应该较局限性,是出了我也不知道咋解决的问题,如果一个术语长这样0123223003_0e72262cc4264b27b0ffc0f8cb137d12,那么在输_前半部分的时候能搜索到该术语并且高亮显示,但输_后半部分的时候虽然也能搜索到,但却不高亮显示,一开始我以为是特殊符号“_”的原因,但结果换成012_cc4后却正常,我也是醉了。。。
2.只能高亮显示整个英文单词,而不能高亮显示搜索的内容,比如hive这个单词只能这样显示hive,而不能这样显示hive。
3.对特殊字符无能为力,如”_“、”}“、”/“
类型三
[hadoop@h153 elasticsearch-2.2.0]$ vi hehe.json
{
"settings": {
"analysis": {
"analyzer": {
"charSplit": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "nGram",
"min_gram": "1",
"max_gram": "1",
"token_chars": [
"letter",
"digit",
"punctuation"
]
}
}
}
},
"mappings":{
"qiang":{
"dynamic":"strict",
"properties":{
"id":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"title":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"describe":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"author":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"},
"content":{"type":"string","store":"yes","index":"analyzed","analyzer": "charSplit","search_analyzer": "charSplit"}
}
}
}
}最终搜索效果:
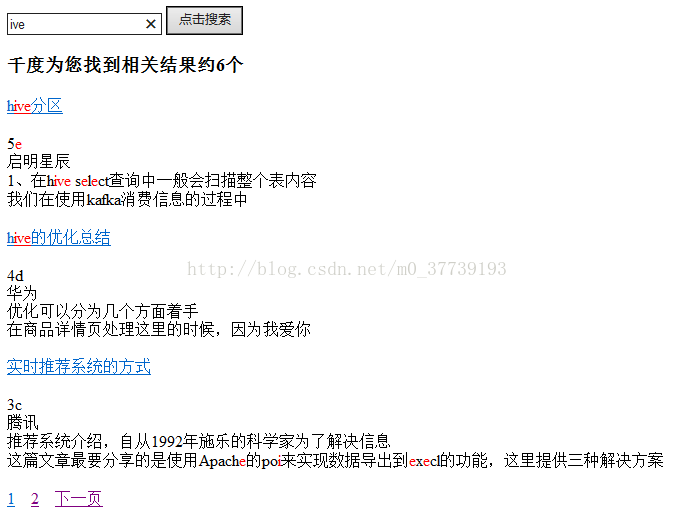
局限性:
1.虽然能这样显示hive,但是却将其他不想要的也搜索出来,目前我并没有想出很好的解决方法(本来想在代码中搜索的api中加入模糊匹配的代码,如搜索关键词key的时候就自动搜索*key*,但我没有成功。即使对英文能成功但是对中文却无能为力)
2.发现了个奇怪的现象,当把max_gram设置成大于1的值时,搜索“提”字能搜索到却不高亮显示,并且搜索中间隔一个字的两个字三个都高亮显示,比如搜索“提供种”,搜索结果为“提供三种”,并且搜“}”和“/”这两个特殊字符能搜到却不高亮显示。