Ubuntu16.04安装vmwaretool、更换软件源、ssh、ftp、mysql、hadoop、eclipse
还有一个月这个学期的大数据课程就结束了,到现在居然还在装软件- -
关键我还没装好- -
花了一个周末的时间来配环境,中间重装了两次虚拟机,因为没有拍摄最初系统的快照,每次重装系统都要花费一小时左右
所以建议大家空间够的话,可以多拍几张快照 做一个步骤拍一个快照,这个教程基本没什么问题了,毕竟也是我花了两天的时间写出来的
衷心希望能帮到各位,别像我一样浪费两天只是在配环境
基本操作就不讲了,连怎么编辑保存linux文件都不会的,先去学学linux基本操作吧,像:wq vim cd 这些指令都是最基本的
Ubuntu16.04(阿里云镜像)
ubuntu 16.04:
http://mirrors.aliyun.com/ubuntu-releases/16.04/
所有的压缩包云盘自取
提取码:socf
切换到root用户
不管哪个系统都直接切换到root用户 权限更高就不用每次都打sudo
sudo su #回车后自己输入密码

装两台虚拟机一台主机一台子机
server端装好进入桌面后首先开ssh权限
vim /etc/ssh/sshd_config
PermitRootLogin 改成yes 允许root用户远程登录

然后重启ssh
systemctl restart sshd
然后修改root账户密码
passwd root

在其他机器上操作流程也一样
到这里就可以用Xshell连接虚拟机root账户了
安装VMtool
找个地方新建vmtools文件夹,我在home文件夹下建的
红框框起来的是重点语句 其他不要看,学会善用ls

更换软件源
//阿里源
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
Ubuntu 的源存放在在 /etc/apt/ 目录下的 sources.list 文件中,修改前我们先备份,在终端中执行以下命令:
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bcakup
然后执行下面的命令打开 sources.list 文件,清空里面的内容,把上面阿里云源复制进去,保存后退出。
vi命令下清空所有行
- 用vi打开文件后 直接输入gg进到第一行
- 按下d,然后输入G(切成大写)回车,此时内容被全部清楚
- 现在可以按i进入编辑模式了
sudo gedit /etc/apt/sources.list
接着在终端上执行以下命令更新软件列表,检测出可以更新的软件:
sudo apt-get update
最后在终端上执行以下命令进行软件更新:
sudo apt-get upgrade
桌面端安装SSH
首先通过apt安装ssh
apt-get install openssh-server
装完ssh记得启动
注:重启命令与关闭命令如下:
/etc/init.d/ssh restart #重启SSH服务
/etc/init.d/ssh stop #关闭SSH服务
安装vsftpd
apt-get install vsftpd
apt-get install ftp
设置参数
vim /etc/vsftpd.conf
添加参数如下
anonymous_enable=NO #这里记得删掉原来的anonymous_enable
anon_root=/opt/ftp
no_anon_password=YES
chroot_local_user=YES
allow_writeable_chroot=YES
userlist_enable=YES
userlist_deny=NO
userlist_file=/etc/vsftpd.user_list
write_enable=YES

做个记录
我填的时候一个变量填错了
查了半天
最后用vsftpd /etc/vsftpd.conf &找到问题

FTP
apt-get install vsftpd
apt-get install ftp
添加允许的账户
vim /etc/vsftpd.user_list

开机启动vsftpd
systemctl enable vsftpd.service
重启vsftpd
systemctl restart vsftpd.service

FTP测试
1.创建目录和设置目录权限
mkdir /opt/ftp
echo "test" > /opt/ftp/test
chmod 755 -R /opt/ftp
2.查看ftp基本命令

登录vsftpd,我直接用第一个jin登录
测试成功

安装Mysql
1.安装Mysql-Client
apt-get install mysql-client
2.安装Mysql-Server
apt-get install mysql-server
3.修改Mysql-server参数
vim /etc/mysql/mysql.conf.d/mysqld.cnf
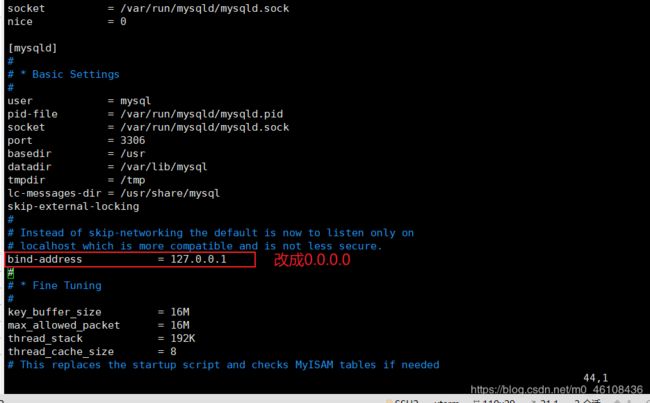
添加如下参数
default-storage-engine = innodb
innodb_file_per_table
collation-server = utf8_general_ci
init-connect = 'SET NAMES utf8'
character-set-server = utf8
如图

4.设置开机启动服务
systemctl enable mysql.service
5.启动Mysql服务
systemctl start mysql.service
6.初始化Mysql
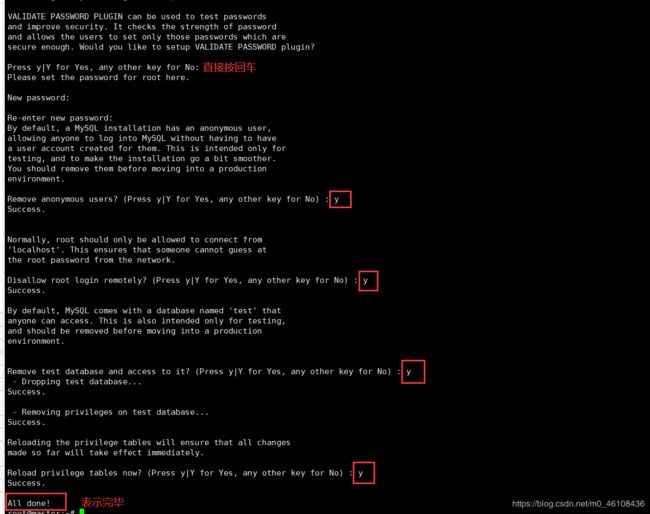
mysql_secure_installation
密码我设成root
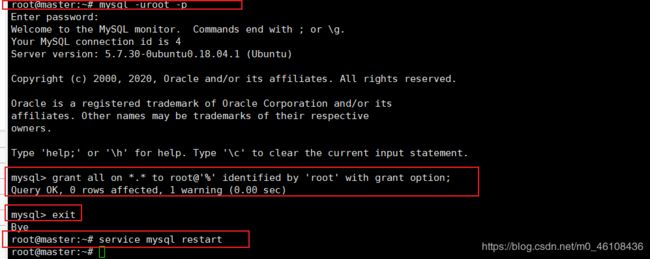
给Mysql的root用户授权,允许访问所有数据库和远程访问
grant all on *.* to root@'%' identified by 'root' with grant option;
grant all on *.* to root@'%' identified by 'root' with grant option;
这样就能用Navicat远程连接了

Hadoop集群部署
修改主机名字和ip映射
- 修改主机名字 主机改成master 其他改成slave1、slave2以此类推
vim /etc/hostname
- 修改ip映射
vim /etc/hosts
不管多少台 每台都要这样写
这里的ip是每个人都不一样的,一定要注意ip和主机名对应,不知道的用ifconfig命令查询主机ip

然后重启一下才能在终端看到机器名的变化
reboot
测试能否互相ping通 能看到消息就直接Ctrl+C结束

注意master和slave都要创建hadoop!
1.各集群节点创建用户hadoop
groupadd -g 730 hadoop
useradd -u 730 -g 730 -m -s /bin/bash hadoop
2.添加用户hadoop到用户组sudo
gpasswd -a hadoop sudo
3.设置用户hadoop的密码
passwd hadoop

4.证书操作
SSH无密码登陆节点
这个操作是要让master节点可以无密码 SSH 登陆到各个slave节点上。
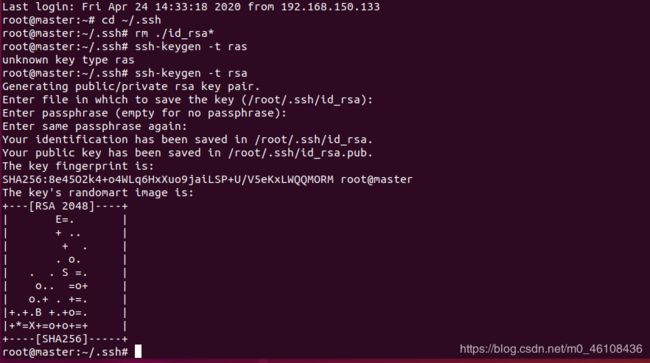
1、首先生成master节点的公匙,在master节点的终端中执行(因为改过主机名,所以还需要删掉原有的再重新生成一次):
执行ssh localhost
ssh localhost
cd ~/.ssh
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以
2、让master节点需能无密码 SSH 本机,在master节点上执行
cat ./id_rsa.pub >> ./authorized_keys
测试是否成功
ssh master

生成公钥后:此时登陆本机不需要输入密码
3、接着在 master节点将上公匙传输到 slave1和slave2节点(在传输前如果不存在目录,先创建)
scp ~/.ssh/id_rsa.pub root@slave1:/home/hadoop/
scp 是 secure copy 的简写,用于在 Linux 下进行远程拷贝文件,类似于 cp 命令,不过 cp 只能在本机中拷贝。执行 scp 时会要求输入 datanode 上 root 用户的密码(root),输入完成后会提示传输完毕,如下所示:

4、接着在 slave1节点上,将 ssh 公匙加入授权:
切换到/home/hadoop目录
cd /home/hadoop/
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat id_rsa.pub >> ~/.ssh/authorized_keys
rm id_rsa.pub # 用完就可以删掉了

如果有其他 slave节点,也要执行将 master公匙传输到 slave节点、在 slave节点上加入授权这两步。这样,在 master节点上就可以无密码 SSH 到各个 slave节点了,可在 master节点上执行如下命令进行检验,如下所示:
输入exit即可退出

有问题看这个
安装Hadoop
用Xftp传到opt目录下

切换到hadoop用户下
su hadoop
解压文件
同理把jdk和eclipse一起解压出来

把圈起来的三个包删掉

修改文件属性
sudo chown -R hadoop:hadoop jdk1.8.0_241 hadoop-2.7.3
进入hadoop配置文件文件夹里
cd /opt/hadoop-2.7.3/etc/hadoop
然后修改hadoop-env.sh文件
vim hadoop-env.sh
把
export JAVA_HOME=${JAVA_HOME}
改成
export JAVA_HOME=/opt/jdk1.8.0_241
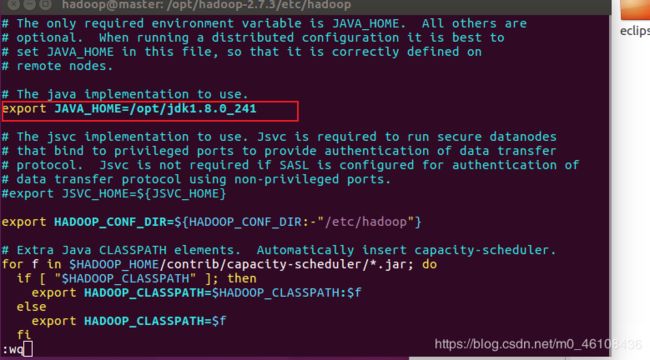
修改Hadoop配置文件
修改core-site.xml文件
因为vim格式不太方便所以这里用gedit
下面几个文件都是修改
![]()
sudo gedit core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.3/tmp</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/opt/hadoop-2.7.3/dfs/namesecondary</value>
</property>
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
新建mapred-site.xml
Ubuntu16.04是没有这个文件的,需要改名操作,这里我们直接新建
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves文件
vim slaves
如果你只配了两台那就像我这样设 如果说你有一台主机两台子机那就设成slave1、slave2
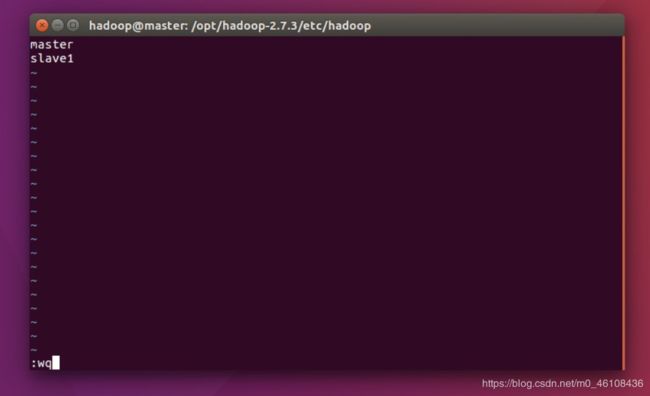
slave节点安装软件
以用户hadoop登录slave1节点
su hadoop
sudo scp -r hadoop@master:/opt/* /opt
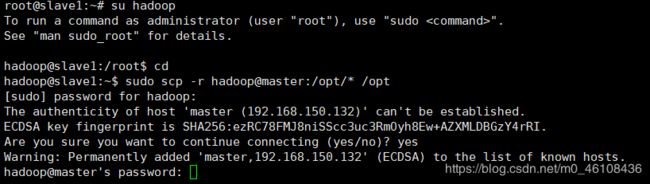
然后会让你输入主机和子机的密码 接下来就开始传输了
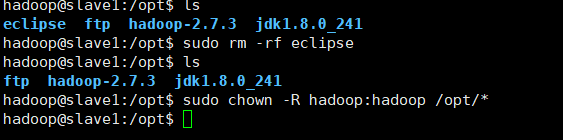
传完后ls
把eclipse文件夹删掉
sudo rm -rf eclipse
然后给文件夹提权
sudo chown -R hadoop:hadoop /opt/*
各集群节点设置环境变量
vim /home/hadoop/.profile
添加以下内容
export JAVA_HOME=/opt/jdk1.8.0_241
export HADOOP_HOME=/opt/hadoop-2.7.3
export HBASE_HOME=/opt/hbase-1.2.4
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.9
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH

执行以下命令更新配置文件
source /home/hadoop/.profile
Master节点启动Hadoop服务
Namenode格式化
hdfs namenode -format
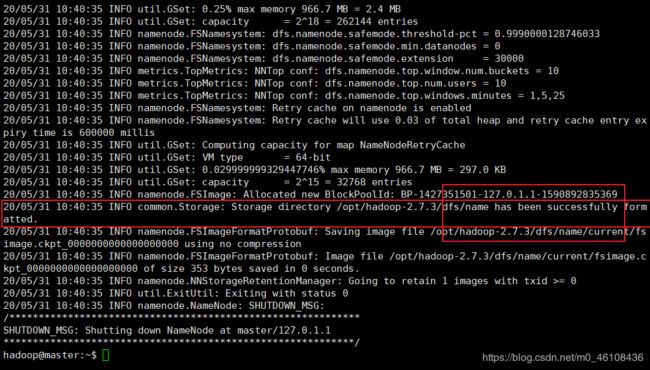
到关键的一步了
直接一键启动全部
start-all.sh
启动HistoryServer
mr-jobhistory-daemon.sh start historyserver
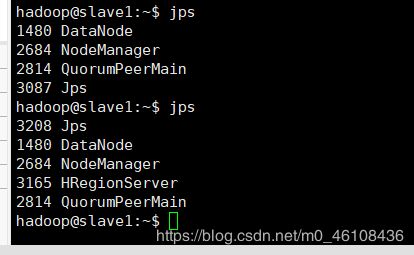
输入jps查看


算上jps的话master上一共5个进程,slave1上3个进程
用hdfs dfsadmin -report查看Live DataNode数量
如过存活数量为0那就是有问题
我百度了半天发现slave1的/etc/hosts下的ip映射没设置搞了半天
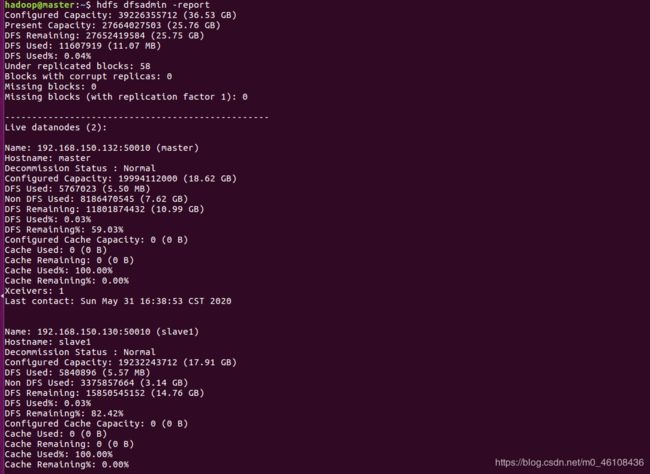
还等什么赶紧拍个快照啊tm的太难了
访问一下几个网址看看 我就不访问了
master:50070
master:50090
master:8088
master:19888
安装eclipse
之前已经在opt解压过了所以现在直接用
第一步先把hadoop-eclipse-plugin-2.6.0.jar传到eclipse下plugins目录下
提权
chown -R hadoop:hadoop /opt/eclipse /opt/hadoop* /opt/jdk*
切换到hadoop用户运行eclipse
出了点问题- -

这是因为Xserver默认情况下不允许别的用户的图形程序的图形显示在当前屏幕上. 如果需要别的用户的图形显示在当前屏幕上, 则应以当前登陆的用户, 也就是切换身份前的用户(不是hadoop用户,是root用户)执行如下命令。
解决方法


HBase、Zookeeper部署
Master节点安装软件
将Hbase和Zookeeper软件包直接传到opt下,怎么传不细讲了
切换到hadoop用户下进入opt目录

sudo tar -zxf hbase-1.2.4-bin.tar.gz
sudo tar -zxf zookeeper-3.4.9.tar.gz
解压完后删掉软件包

提权
sudo chown -R hadoop:hadoop hbase-1.2.4 zookeeper-3.4.9
Master节点设置HBase参数
(1)修改hbase-env.sh文件
cd /opt/hbase-1.2.4/conf
vim hbase-env.sh
把如下内容:
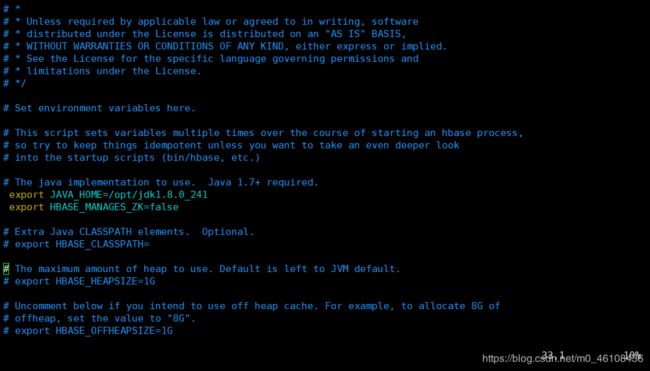
export JAVA_HOME=/usr/java/jdk1.6.0/
export HBASE_MANAGES_ZK=true
改为:
export JAVA_HOME=/opt/jdk1.8.0_241/
export HBASE_MANAGES_ZK=false
(2)修改hbase-site.xml文件
vim hbase-site.xml
在 之间添加内容如下:
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1</value>
</property>
<property>
<name>hbase.zookeeper.property.datadir</name>
<value>/opt/zookeeper-3.4.9/data/</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>20</value>
</property>
<property>
<name>hbase.regionserver.maxlogs</name>
<value>64</value>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>10485760</value>
</property>
(3)修改regionservers
vim regionservers
改成这样
Master节点设置Zookeeper参数
本来自带的文件名是叫zoo_sample.cfg 首先把名字改过来先改成zoo.cfg
这一步务必注意!必须改名,别新建文件
mv zoo_sample.cfg zoo.cfg
然后再ls一下

编辑zoo.cfg
vim zoo.cfg
改成如下这样

在dataDir指定的目录下创建myid文件,添加相应内容
如果提示权限不够就先切换到root去
mkdir /opt/zookeeper-3.4.9/data
echo 0 > /opt/zookeeper-3.4.9/data/myid
用cat看看是否写入成功
cat /opt/zookeeper-3.4.9/data/myid
![]()
拷贝zookeeper的配置文件zoo.cfg到HBase
cp /opt/zookeeper-3.4.9/conf/zoo.cfg /opt/hbase-1.2.4/conf/
Slave节点安装软件
首先切换到hadoop用户下
sudo scp -r hadoop@master:/opt/hbase-1.2.4 /opt
sudo scp -r hadoop@master:/opt/zookeeper-3.4.9 /opt
然后提权
sudo chown -R hadoop:hadoop /opt/hbase-1.2.4 /opt/zookeeper-3.4.9
写入信息
echo 1 > /opt/zookeeper-3.4.9/data/myid
同样cat看一下

Zookeeper服务
zkServer.sh start

slave1也这样做

验证Zookeeper服务
zkServer.sh status

slave1也去验证

验证HBase服务
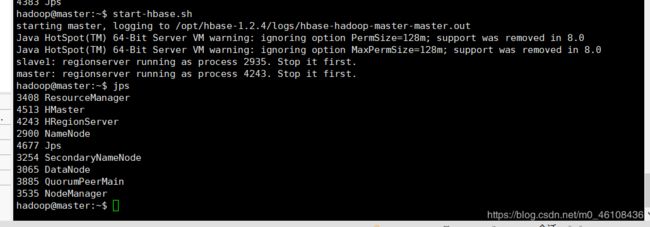
Master节点启动HBase
start-hbase.sh
少一个都算错 多启动几次试试
火狐访问http://master:16010,查看HBase Master状态

进入http://master:16030,查看RegionServer状态
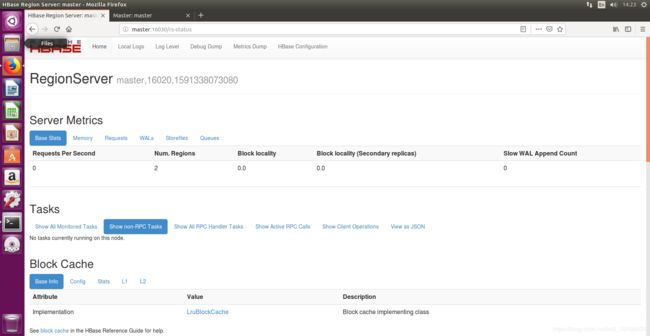
HBase Shell
表的管理
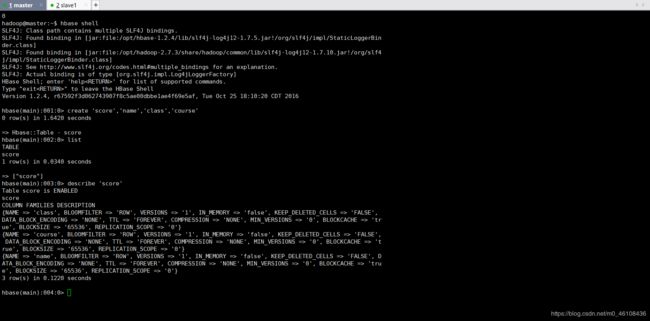
hbase shell

create 'score','name','class','course'
list
describe 'score'
数据操作
添加记录
put 'score','610213','name:','Tom'
put 'score','610213','class:class','163Cloud'
put 'score','610213','course:python','79'
put 'score','610215','name','John'
put 'score','610215','class:class','173BigData'
put 'score','610215','course:java','70'
put 'score','610215','course:java','80'
put 'score','610215','course:python','86'

读表记录
get 'score','610215'

get 'score','610215','course'

get 'score','610215','course:java'

扫描记录
scan 'score'
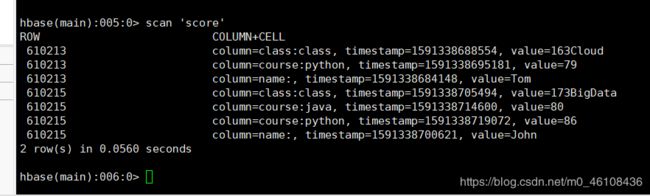
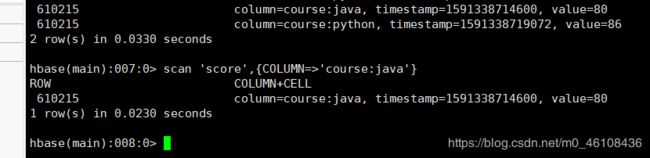
scan 'score',{COLUMNS=>'course'}

scan 'score',{COLUMN=>'course:java'}
FILTER过滤扫描记录
扫描值是John的记录
scan 'score',FILTER=>"ValueFilter(=,'binary:John')"

扫描值包含To的记录
scan 'score',FILTER=>"ValueFilter(=,'substring:To')"

扫描值包含Clou的记录
scan 'score',FILTER=>"ColumnPrefixFilter('class') AND ValueFilter(=,'substring:Cloud')"

扫描Rowkey为610开头的记录
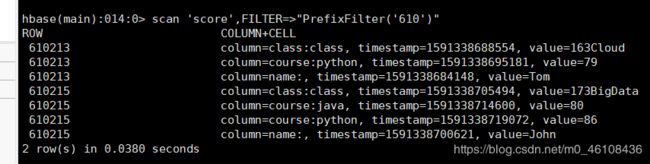
scan 'score',FILTER=>"PrefixFilter('610')"
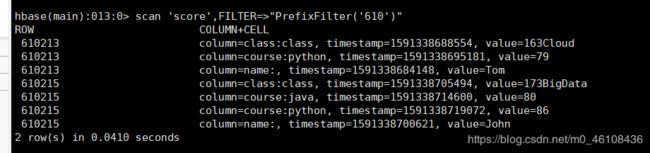
扫描Rowkey为610开头的记录
scan 'score',FILTER=>"PrefixFilter('610')"
只拿出key中的第一个column的第一个version并且只要key的记录
scan 'score',FILTER=>"FirstKeyOnlyFilter() AND KeyOnlyFilter()"

扫描从610213开始到610215结束的记录
scan 'score',{STARTROW=>'610213',STOPROW=>'610215'}

扫描列族name中含有To的记录
scan 'score',{COLUMNS=>['name'],FILTER=>"(ValueFilter(=,'substring:To'))"}

扫描列族course中成绩大等于85的记录
scan 'score',{COLUMNS=>['course'],FILTER=>"(ValueFilter(>=,'binary:85'))"}

删除记录
delete 'score','610213','course:python'
get 'score','610213'

delete 'score','610215','class:class',1486456047670
get 'score','610215'

表的删除与修改
增加列族
alter 'score',NAME=>'address'
删除列族
alter 'score',NAME=>'address',METHOD=>'delete'
删除表
disable 'score'
drop 'score'

HBase编程
关于重启后需要source重置环境变量的问题
附一篇环境变量教程
是关于重启后找不到java、jps等指令的问题解决方法