配置cuda8.0/cudnn6.0/ubunut16.04/tensorflow 环境
最后配置环境好了,还是有掉驱动的情况发生,表现为登陆的时分辨变低,图像变卡(我认为问题出在系统切换上,具体不明),这时,直接再把驱动装一遍就好,就可以继续使用
linux下截图的办法还没有找到,找到了,再对一些细节进行贴图
2018/6/6更新,截图办法已经找到使用gnome-screenshot -a
配置cuda8.0/cudnn6.0/ubunut16.04/tensorflow 环境(cdunn6.0需要对应tensorflow版本大于等于1.3)
#1.安装ubuntu(具体安装步骤等哪次重装再补)
1.首先不要勾选第3方的文件,然后进去 安装方式 选something else,接下来分区,只要有分出这4个分区就好
例如有1个t:
/home (放文件的) 逻辑分区 Ext4 700G
/ (放系统的) 主分区 Ext4 267G
/boot (启动,包括引导项)主分区 Ext4 1G
swap (交换空间,有说法大小设置为内存的2倍)逻辑分区 32G
下拉菜单选择启动引导装到哪里?一般就选默认的就行了,例如图片中默认为固态硬盘
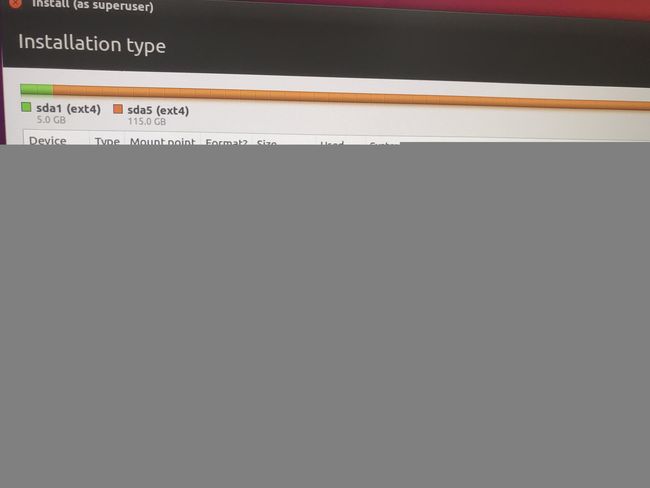
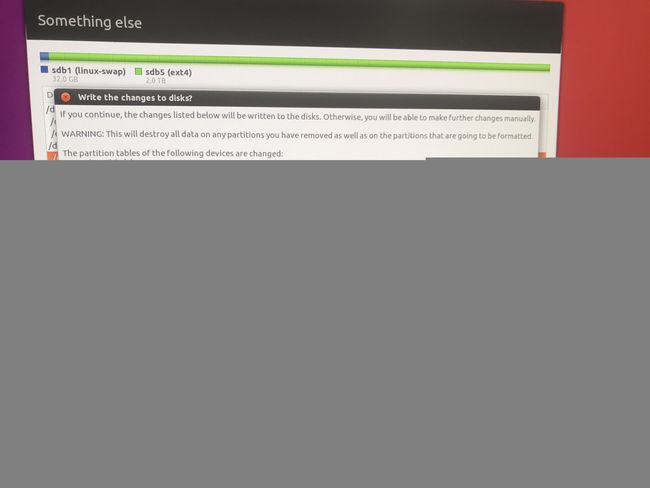
问要不要格式化,点contiune
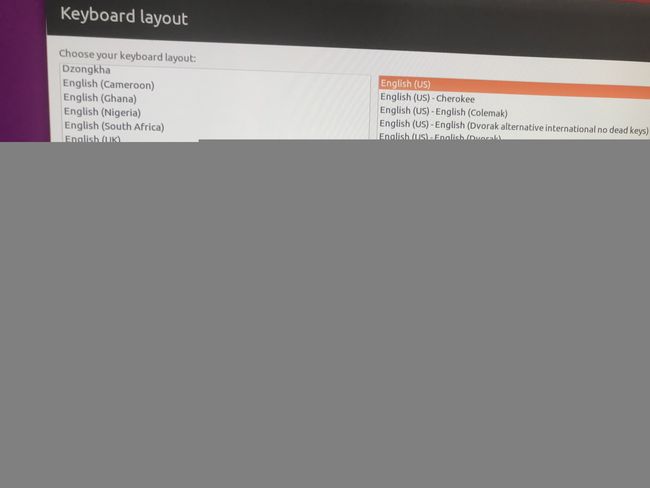
语言选默认的English(US),不然home目录下的路径在文本模式下你会看不懂,全是小星星
这里请设置个密码,不然没法logout,或者在登陆界面切纯文本模式

安装时如果太慢,大于半个小时,那么应该是在网上下东西,拔掉网线就会行

#2.完成ubuntu安装后,换apt-get的源
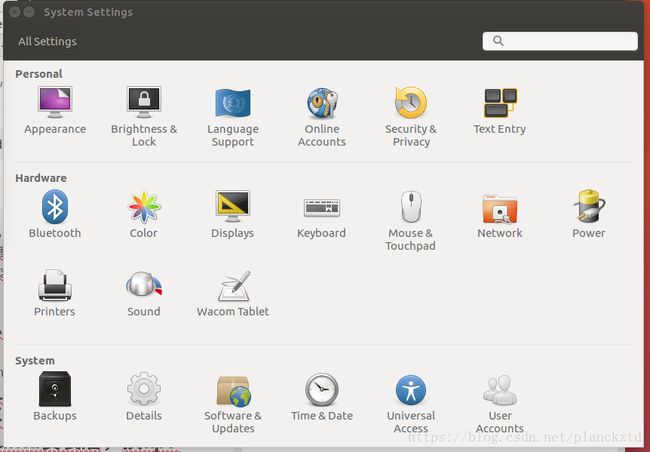
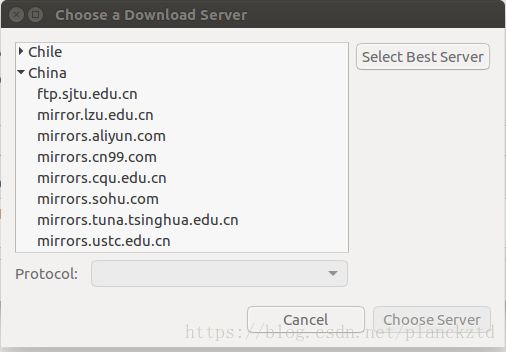
右上点击电源–>system settings–> software & update–> Download from下拉菜单选other–>找到China,选一个源,choose Server,然后一路保存,最后下东西的时候看下地址测试。

#3.更新ubuntu
sudo apt-get update
sudo apt-get upgrade
原因:有的时候gcc版本,或者什么核,不更新报错
#4.安装cuda(对于先装cuda还是先装驱动,顺序不影响)
##cuda预安装及检测,出自,参考简书https://www.jianshu.com/p/35c7fde85968
.run安装失败的…
执行
sudo /usr/local/cuda-8.0/bin/uninstall_cuda_8.0.pl
sudo /usr/bin/nvidia-uninstall
若仍安装有问题,请敲下
sudo apt-get autoremove --purge nvidia-* #把nvidia驱动清个干干净净
sudo reboot看情况重启
下面的步骤,基本不报错,就是正常的,与具体机器版本无关
1.1 Verify you have a CUDA-Capable GPU
lspci | grep -i nvidia
机器显示:
01:00.0 3D controller: NVIDIA Corporation GF117M [GeForce 610M/710M/810M/820M / GT 620M/625M/630M/720M] (rev a1)
1.2 Verify you have a Supported Version of Linux
uname -m && cat /etc/*release
机器显示:
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=14.04
...
1.3 Verify the System Has GCC Installed
gcc --version
结果显示:
gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4
...
1.4 Verify the System has the Correct Kernel Headers and Development Packages Installed
uname -r
结果显示
4.4.0-45-generic
安装对应的kernels header和开发包:
sudo apt-get install linux-headers-$(uname -r)
2.1 Disabling Nouveau 禁用系统本身的驱动,先查看
lsmod | grep nouveau
如果有内容输出,则需禁掉nouveau
sudo gedit /etc/modprobe.d/blacklist-nouveau.conf
添加如下内容:
blacklist nouveau
options nouveau modeset=0
执行
sudo update-initramfs –u
再执行,查看有没有禁用好… 这里一般还是有的,但是一般重启后就没有了,重启进了黑框的时候测试下就好
lsmod | grep nouveau
问题1:循环登录
原因:驱动装重了,有2个驱动会引起循环登录
解决:确保驱动只存在一个(包括:最开始禁用nouveau,安装cuda自带的驱动的时候选no)
问题2:如果出现循环登录后,只删除对应的驱动仍不能解决(对于新装的ubuntu,这个问题基本不会出现)
(可能会存在)原因:删驱动会有不明的影响对cuda,删cuda有不明的影响对驱动,导致反复删和装并不能解决循环登录的问题
解决:节约时间,cuda和驱动全部删掉,确保删的干干净净,重装_
安装cuda8.0
重启(不重启直接logout,我试过肯定不行),进入输入密码(所以请设密码)的界面,ctrl+alt+F1进入纯文本模式
安装前需要禁用显示sudo service lightdm stop
sudo sh xxx.run --no-opengl-libs
这里的当前驱动版本--no-opengl-libs是网上说的一个操作,不是用libs就是files,可以试试,如果不同版本的驱动不一样,改一下再试
-** 安装过程中首先长按空格,阅读文本**
-accept
-no 询问是否安装cuda自带驱动,选no
-yes 询问是否安装cuda
-回车使用默认路径/usr/local/cuda
-yes 询问是否安装cuda的symbolic
-yes 询问是否安装cuda的simples
-回车simple使用默认路径
3项中的下面两项installed就说明安装完成
#5.安装NVIDIA驱动
安装前需要禁用显示sudo service lightdm stop
sudo sh xxx.run安装驱动
具体步骤:(这里以安装NVIDIA驱动ver.390为例)




基本为,有yes选yes
#6.cuda 和NVIDIA安装完后,sudo service lightdm start,进入登录界面
。。。。。。下面是见证奇迹的时刻,如果没有循环登录,就成功了
#7.测试cuda安装好没有,最后pass就是成功了
##cuda测试,参考简书https://www.jianshu.com/p/35c7fde85968
2.3 Device Node Verification
执行
ls /dev/nvidia*
a) 若结果显示有3个类似的东西,就是成功了
/dev/nvidia0 /dev/nvidiactl /dev/nvidia-uvm
3.1)添加环境变量
①编辑bashrc文件
sudo gedit ~/.bashrc
在文件末尾加入以下两行:
export PATH=“ P A T H : / u s r / l o c a l / c u d a − 8.0 / b i n " e x p o r t L D L I B R A R Y P A T H = " PATH:/usr/local/cuda-8.0/bin" export LD_LIBRARY_PATH=" PATH:/usr/local/cuda−8.0/bin"exportLDLIBRARYPATH="LD_LIBRARY_PATH:/usr/local/cuda-8.0/lib64”
②更新配置
source ~/.bashrc
3.2.1 Verify the Driver Version
cat /proc/driver/nvidia/version
结果显示
NVRM version: NVIDIA UNIX x86_64 Kernel Module 361.77 Sun Jul 17 21:18:18 PDT 2016
GCC version: gcc version 4.8.4 (Ubuntu 4.8.4-2ubuntu1~14.04.3)
3.2.2 Verify CUDA Toolkit
nvcc -V
结果显示
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Wed_May__4_21:01:56_CDT_2016
Cuda compilation tools, release 8.0, V8.0.26
cd 进NVIDIA_CUDA-8.0_Samples目录
执行
make
这区间大概需要十几到二十分钟,请耐心等待
完成后,cd进bin目录里面的里面的里面,知道看到一堆可执行文件(菱形的图标),大概是 ~/NVIDIA_CUDA-8.0_Samples/bin/x86_64/linux/release
运行其中的一个例子
$ ./deviceQuery
结果显示,pass,j就是cuda装好了
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GT 720M"
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 2.1
Total amount of global memory: 1985 MBytes (2081226752 bytes)
( 2) Multiprocessors, ( 48) CUDA Cores/MP: 96 CUDA Cores
GPU Max Clock rate: 1250 MHz (1.25 GHz)
Memory Clock rate: 800 Mhz
Memory Bus Width: 64-bit
L2 Cache Size: 131072 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65535), 3D=(2048, 2048, 2048)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 32768
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (65535, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = GeForce GT 720M
Result = PASS
#8.安装cudnn6.0
解压包,可能会需要改后缀,改成tgz格式解压
这里的解压路径很重要,因为下面的创建软连接会用到(软连接类似于快捷方式,对原文件的改动,位置调整,会影响到链接的内容)
软连接:
sudo gedit ~/.bashrc
#在最下面加入
#下面的/your/path/to/cudnn/lib64就是解压到lib64的地址
export LD_LIBRARY_PATH=/your/path/to/cudnn/lib64:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64"
export CUDA_HOME=/usr/local/cuda
#保存后退出,在终端激活
source ~/.bashrc
复制include文件夹中的cudnn.h(请打开终端,位置处于include的目录下)
sudo cp *.h /usr/local/cuda/include/
给cudnn.h权限
sudo chmod a+r /usr/local/cuda/include/cudnn.h
#9.安装anaconda
sudo sh anacondaXXXXXX.sh
#10.完成anaconda安装,anaconda换源
conda config --add channels 'https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/'
conda config --set show_channel_urls yes
#好了,这次可以开心的下载东西了
# 如何删除添加的源呢?
# conda config --remove channels 'https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/'
# 看看当前的 cofig 是什么样的
conda config --show
#11.创建anaconda 环境
#这里的创建环境的时候,可以同时给这个环境装上不同版本的python
conda create -n 文件名 python=2.7
#12.pip 换源,下面的换源方式,会使所有的虚拟环境中的pip都换源
cd ~
mkdir .pip
cd .pip
sudo gedit pip.conf
#在里面添加
[global]
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=pypi.tuna.tsinghua.edu.cn
disable-pip-version-check = true
timeout = 6000
#13.安装tensorflow-gpu
pip install tensorflow-gpu==1.4.0
#如果版本有问题,需要卸载,使用
pip uninstall tensorflow-gpu
#14.检测tensorflow是否装好
#首先在进入环境
source activate 环境名
#如果不对,要退出,输入
source deactivate
#测试方法一:输入python,进入python环境,同时可以显示对应的python版本
python
#在python 环境下调用tensorflow测试
>>import tensorflow
#测试方法二:创建一个python的.py文件,添加以下代码,在环境中运行python test.py
# Creates a graph.
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(c))
#15.安装pycharm
直接安装就好
sudo sh pycharmXXXXXXX.run
安装完成后进入,bin目录,直接sh命令用打开(注意,打开的时候环境会有影响,在直接sh,sudo sh 和虚拟环境中打开有不同的环境)
sh pycharmXXXXXXX.sh
pycharm的使用conda环境配置的基本操作需要贴图