Python科学计算:用NumPy快速处理数据
写在前面:
大家再读别人文档的时候,一定有过以下方面的苦恼:
1、为啥我复制别人的代码总是执行报错;(内心mmp,劳资就是想学个技术,咋就这么难了???)
emmn,一定是你的计算机环境与别人不一样;(强烈建议大家回答问题,写文档时加上自己的开发环境和使用软件的版本。)
比如我现在就想学习数据分析,那么第三方库Numpy,Pandas就是必须的;可是,一般的书籍上来就推荐你用python2.x,3.x,然后你觉得不好用,就下载pythonIDE,pythonChram;可是你下载了这么多,发现还是没有第三方库Numpy,Pandas(这时候你的激情可能被消耗殆尽);
正确做法是:直接下载Anaconda--python集成环境,除了python基本功能外,还自动下载了数据分析必备的第三方库;
下载地址:https://www.anaconda.com/download/
安装视屏:https://edu.hellobi.com/course/234/lessons
- Jupyter notebook 安装管理:https://www.zhihu.com/collection/236101838
- Anaconda 安装管理:https://www.zhihu.com/collection/236101838
为什么要用 NumPy 数组结构而不是 Python 本身的列表 list?这是因为列表 list 的元素在系统内存中是分散存储的,而 NumPy 数组存储在一个均匀连续的内存块中,这样数组计算遍历所有的元素,不像列表 list 还需要对内存地址进行查找从而节省了计算资源。
另外 NumPy 中的矩阵计算可以采用多线程的方式,充分利用多核 CPU 计算资源,大大提升了计算效率。
在 NumPy 里有两个重要的对象ndarray(N-dimensional array object)解决了多维数组问题,而 ufunc(universal function object)则是解决对数组进行处理的函数。
ndarray 对象
在 NumPy 数组中,维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2;在 NumPy 中,每一个线性的数组称为一个轴(axes),其实秩就是描述轴的数量。
创建数组
import numpy as np
a = np.array([1, 2, 3])
b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b[1,1]=10
print a.shape
print b.shape
print a.dtype
print b
输出
(3L,)
(3L, 3L)
int32
[[ 1 2 3]
[ 4 10 6]
[ 7 8 9]]
创建数组前,你需要引用 NumPy 库,可以直接通过 array 函数创建数组;a是一维数组,b是二维数组;(二维数组就是在【】内嵌套【】)
可以通过函数 shape 属性获得数组的大小,
通过 dtype 获得元素的属性
注意下标是从 0 开始计的
快速构建数组
#通过数组创建一个二维的ndarray
data2 = [[1,2,3,4],[5,6,7,8]]
arr2 = np.array(data2)
print(arr2)]
输出:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
##创建全0数组
np.zeros(10)
输出
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
#创建3个1数组
np.ones(3)
输出:
array([1., 1., 1.])
#创建等差数组
np.arange(1,15,2)#不包括15
输出
array([ 1, 3, 5, 7, 9, 11, 13])
#创建正态分布随机数数组
samples = np.random.normal(2,3,size=(4,4))#均值为2,sd=3
samples
#创建随机整数数组,上限10,下限0
draws = np.random.randint(0,10,size=(3,4))
输出
array([[2, 2, 4, 5],
[7, 5, 8, 5],
[9, 0, 6, 1]])
示例构建数组
如果你想统计一个班级里面学生的姓名、年龄,以及语文、英语、数学成绩该怎么办?
import numpy as np
import pandas as pd
persontype = np.dtype({
'names':['name', 'age', 'chinese', 'math', 'english'],
'formats':['S32','i', 'i', 'i', 'f']})
peoples = np.array([("ZhangFei",32,75,100, 90),("GuanYu",24,85,96,88.5),
("ZhaoYun",28,85,92,96.5),("HuangZhong",29,65,85,100)],
dtype=persontype)
#将该列汇总起来,用于对列进行计算
chineses = peoples[:]['chinese']
maths = peoples[:]['math']
englishs = peoples[:]['english']
print ('语文成绩:',np.mean(chineses))
print ('数学成绩:',np.mean(maths))
print ('英语成绩:',np.mean(englishs))
输出
77.5
93.25
93.75
首先在 NumPy 中是用 dtype 定义的结构类型,然后在定义数组的时候,用 array 中指定了结构数组的类型 dtype=persontype;这样你就可以自由地使用自定义的 persontype 了。比如想知道每个人的语文成绩,就可以用 chineses = peoples[:][‘chinese’]
当然 NumPy 中还有一些自带的数学运算,比如计算平均值使用 np.mean。
注意当前不能使用中文字符,否则会报错!
i 代表整数,f 代表单精度浮点数,S 代表字符串,S32 代表32个字符串;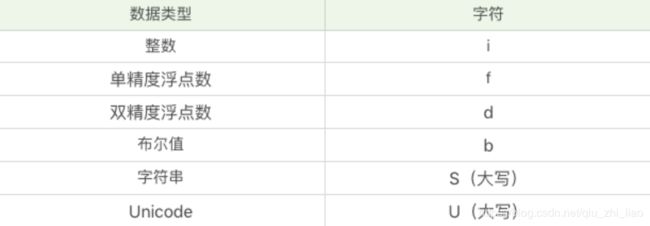
如果数据定义中使用了中文,可以用"U32".
import numpy as np
persontype = np.dtype({
'names':['name', 'age', 'chinese', 'math', 'english'],
'formats':['U32','i', 'i', 'i', 'f']})
peoples = np.array([(" 张飞 ",32,75,100, 90),(" 关羽 ",24,85,96,88.5), (" 赵云 ",28,85,92,96.5),(" 黄忠 ",29,65,85,100)], dtype=persontype)
索引与切片
numpy基本的索引和切片功能和Python列表的操作相似,由于numpy是针对大数据而言,所以针对numpy的任何操作都会作用到原始数据上(节省内存)。以下介绍基本的索引与切片。
一维数组切片
#任何操作都改变了
arr = np.arange(10)
arr[5]
# 5
arr[5:8]
#array([5, 6, 7])
arr[5:8]=12
t = arr[5:8]
t[1] = 12345
arr
#array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8, 9])
#不改变原始数组
t1 = arr[5:8].copy()
t1[2] = -222
arr
#array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])多维数组索引与切片
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr2d[0,2] #arr2d的第一个元素中的第三个元素
#3
arr2d[:2,1:]
#array([[2, 3],
# [5, 6]])ufunc 运算
它能对数组中每个元素进行函数操作。NumPy 中很多 ufunc 函数计算速度非常快,因为都是采用 C 语言实现的。
连续数组的创建
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
输出
1 3 5 7 9arange() 类似内置函数 range(),通过指定初始值、终值、步长来创建等差数列的一维数组,默认是不包括终值的。
linspace 是 linear space 的缩写,代表线性等分向量的含义.linspace() 通过指定初始值、终值、元素个数来创建等差数列的一维数组,默认是包括终值的。
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
print np.add(x1, x2)
print np.subtract(x1, x2)
print np.multiply(x1, x2)
print np.divide(x1, x2)
print np.power(x1, x2)
print np.remainder(x1, x2)
[ 2. 6. 10. 14. 18.]
[0. 0. 0. 0. 0.]
[ 1. 9. 25. 49. 81.]
[1. 1. 1. 1. 1.]
[1.00000000e+00 2.70000000e+01 3.12500000e+03 8.23543000e+05
3.87420489e+08]
[0. 0. 0. 0. 0.]
通过 NumPy 可以自由地创建等差数组,同时也可以进行加、减、乘、除、求 n 次方和取余数。在 n 次方中,x2 数组中的元素实际上是次方的次数,x1 数组的元素为基数。
在取余函数里,你既可以用 np.remainder(x1, x2),也可以用 np.mod(x1, x2)
统计函数
a = np.array([[4,3,2],[2,4,1]])
print np.sort(a)
print np.sort(a, axis=None)
print np.sort(a, axis=0)
print np.sort(a, axis=1)
[[2 3 4]
[1 2 4]]
[1 2 2 3 4 4]
[[2 3 1]
[4 4 2]]
[[2 3 4]
[1 2 4]]
如何记忆排序规则:排序不会更改数据结构---原来涨啥样,排序后仍涨啥样。将数据看作矩阵,axis=0(按照列进行排序),axis=1(按照行排序),axis=none打通格式将矩阵看作向量进行全排,axis=-1为默认,实际上与axis=1(按照行排序)
np.sort(a)默认按照axis=-1,代表就是按照数组最后一个轴来排序;
如果 axis=None,代表以扁平化的方式作为一个向量进行排序。
axis=0(按照列进行排序),所以实际上是对 [4, 2] [3, 4] [2, 1] 来进行排序,排序结果是[2, 4] [3, 4] [1, 2],对应的是每一列的排序结果。还原到矩阵中也就是 [[2 3 1], [4, 4, 2]]。
计数组 / 矩阵中的最大值函数 amax(),最小值函数 amin()
import numpy as np
import pandas as pd
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print (np.amin(a))
print (np.amin(a,0))
print (np.amin(a,1))
print (np.amax(a))
print (np.amax(a,0))
print (np.amax(a,1))
输出
1
[1 2 3]
[1 4 7]
9
[7 8 9]
[3 6 9]对于一个二维数组 a,amin(a) 指的是数组中全部元素的最小值,amin(a,0) 是延着 axis=0 轴的最小值---axis=0 轴是把元素看成了[1,4,7], [2,5,8], [3,6,9] 三个元素(按列排序,按行取数);所以最小值为 [1,2,3],amin(a,1) 是延着 axis=1 轴的最小值---axis=1 轴是把元素看成了 [1,2,3], [4,5,6], [7,8,9]三个元素;所以最小值为 [1,4,7]。同理 amax() 是计算数组中元素沿指定轴的最大值。
统计最大值与最小值之差 ptp()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.ptp(a)
print np.ptp(a,0)
print np.ptp(a,1)
8
[6 6 6]
[2 2 2]np.ptp(a) 可以统计数组中最大值与最小值的差,即 9-1=8。
同样 ptp(a,0) 统计的是沿着 axis=0 轴的最大值与最小值之差;也就是说,axis=0 是列运算;axis=1 是行运算。
统计数组的百分位数 percentile()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.percentile(a, 50)
print np.percentile(a, 50, axis=0)
print np.percentile(a, 50, axis=1)
5.0
[4. 5. 6.]
[2. 5. 8.]
同样,percentile() 代表着第 p 个百分位数,这里 p 的取值范围是 0-100如果 p=0,那么就是求最小值,如果 p=50 就是求平均值,如果 p=100 就是求最大值。同样你也可以求得在 axis=0 和 axis=1 两个轴上的 p% 的百分位数。
统计数组中的中位数 median()、平均数 mean()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
# 求中位数
print np.median(a)
print np.median(a, axis=0)
print np.median(a, axis=1)
# 求平均数
print np.mean(a)
print np.mean(a, axis=0)
print np.mean(a, axis=1)
5.0
[4. 5. 6.]
[2. 5. 8.]
5.0
[4. 5. 6.]
[2. 5. 8.]
统计数组中的加权平均值 average()
a = np.array([1,2,3,4])
wts = np.array([1,2,3,4])
print np.average(a)
print np.average(a,weights=wts)
2.5
3.0
np.average(a)=(1+2+3+4)/4=2.5;你也可以指定权重数组 wts=[1,2,3,4],这样加权平均 np.average(a,weights=wts)=(1*1+2*2+3*3+4*4)/(1+2+3+4)=3.0。
统计数组中的标准差 std()、方差 var()
a = np.array([1,2,3,4])
print np.std(a)
print np.var(a)
1.118033988749895
1.25
数组中的where 条件
xarr = np.array([1.1,1.2,1.3,1.4,1.5])
yarr = np.array([2.1,2.2,2.3,2.4,2.5])
cond = np.array([True,False,True,True,False])
np.where(cond,xarr,yarr)#当为true选择xarr,为false选择yarr
输出:array([1.1, 2.2, 1.3, 1.4, 2.5])
np.where(xarr>1.2,2,-2)
输出array([-2, -2, 2, 2, 2])
NumPy 排序
这里你可以使用 sort 函数,sort(a, axis=-1, kind=‘quicksort’, order=None),默认情况下使用的是快速排序;在 kind 里,可以指定 quicksort、mergesort、heapsort 分别表示快速排序、合并排序、堆排序。同样 axis 默认是 -1,即沿着数组的最后一个轴进行排序,也可以取不同的 axis 轴或者 axis=None 代表采用扁平化的方式作为一个向量进行排序。另外 order 字段,对于结构化的数组可以指定按照某个字段进行排序。
a = np.array([[4,3,2],[2,4,1]])
print np.sort(a)
print np.sort(a, axis=None)
print np.sort(a, axis=0)
print np.sort(a, axis=1)
[[2 3 4]
[1 2 4]]
[1 2 2 3 4 4]
[[2 3 4]
[1 2 4]]
[[2 3 1]
[4 4 2]]数组转置和轴对换
arr = np.arange(15).reshape((5,3))
arr.T
输出
array([[ 0, 3, 6, 9, 12],
[ 1, 4, 7, 10, 13],
[ 2, 5, 8, 11, 14]])
arr1 = np.arange(16).reshape((2,2,4))
arr1
arr1.transpose((1,0,2))
输出
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])对于高维数组,tranpose需要得到一个由轴编号组成的元组才能对这些轴进行转置
集合运算
arr = np.array([1,3,2,5,2,4,2,2,1,4,5,2])
np.unique(arr)#去除重复值
输出
array([1, 2, 3, 4, 5])
x = np.array([1,2,4,5])
y = np.array([3,4,5])
np.intersect1d(x,y) #取交集
#array([4, 5])
np.union1d(x,y) #取并集
#array([1, 2, 3, 4, 5])
np.setdiff1d(x,y) #在x不在y中
#array([1, 2])矩阵运算
#矩阵的乘积
x = np.array([[1,2,3],[4,5,6]])
y = np.array([[6,23],[-1,7],[8,9]])
np.dot(x,y)
输出
array([[ 28, 64],
[ 67, 181]])
#计算矩阵的逆,只有方阵才有逆
from numpy.linalg import inv,det,eig,qr,svd
t = np.array([[1,2,3],[2,3,4],[4,5,6]])
inv(t)
输出
array([[-1.20095990e+16, 1.80143985e+16, -6.00479950e+15],
[ 2.40191980e+16, -3.60287970e+16, 1.20095990e+16],
[-1.20095990e+16, 1.80143985e+16, -6.00479950e+15]])
#计算矩阵行列式
det(t)
输出
1.665334536937729e-16
#计算QR分解址
qr(t)
输出
……
#计算奇异值分解值svd
svd(t)
输出
……
#计算特征值和特征向量
eig(t)
输出
(array([ 1.08309519e+01, -8.30951895e-01, -1.24701000e-16]),
array([[ 0.34416959, 0.72770285, 0.40824829],
[ 0.49532111, 0.27580256, -0.81649658],
[ 0.79762415, -0.62799801, 0.40824829]]))
小练习
假设一个团队里有 5 名学员,成绩如下表所示。你可以用 NumPy 统计下这些人在语文、英语、数学中的平均成绩、最小成绩、最大成绩、方差、标准差。然后把这些人的总成绩排序,得出名次进行成绩输出。
import numpy as np
import pandas as pd
persontype = np.dtype({
'names':['name', 'chinese', 'math', 'english'],
'formats':['S32', 'i', 'i', 'f']})
peoples = np.array([("ZhangFei",75,100, 90),("GuanYu",85,96,88.5),
("ZhaoYun",85,92,96.5),("HuangZhong",65,85,100)],
dtype=persontype)
print(peoples)
#将该列汇总起来,用于对列进行计算
chineses = peoples[:]['chinese']
maths = peoples[:]['math']
englishs = peoples[:]['english']
print ('语文平均成绩|最小成绩|最大成绩|标准差:',np.mean(chineses),np.min(chineses),np.max(chineses),np.std(chineses))
print ('数学平均成绩|最小成绩|最大成绩|标准差:',np.mean(maths),np.min(maths),np.max(maths),np.std(maths))
print ('英语平均成绩|最小成绩|最大成绩|标准差:',np.mean(englishs),np.min(englishs),np.max(englishs),np.std(englishs))
ranking = sorted(peoples,key=lambda x:x[1]+x[2]+x[3], reverse=True)#按照降序排列
print(ranking)
输出:
[(b'ZhangFei', 75, 100, 90. ) (b'GuanYu', 85, 96, 88.5)
(b'ZhaoYun', 85, 92, 96.5) (b'HuangZhong', 65, 85, 100. )]
语文平均成绩|最小成绩|最大成绩|标准差: 77.5 65 85 8.2915619758885
数学平均成绩|最小成绩|最大成绩|标准差: 93.25 85 100 5.539629951540085
英语平均成绩|最小成绩|最大成绩|标准差: 93.75 88.5 100.0 4.6970735
[(b'ZhaoYun', 85, 92, 96.5), (b'GuanYu', 85, 96, 88.5), (b'ZhangFei', 75, 100, 90.), (b'HuangZhong', 65, 85, 100.)]对于lambda的理解
python3
C = [('e', 4, 2), ('a', 6, 1), ('c', 5, 4), ('b', 5, 3), ('d', 1, 5)]
print(sorted(C, key=lambda y: y[0]))#与x,y字母无关
print(sorted(C, key=lambda x: x[0]))
print(sorted(C, key=lambda x: x[2]))
print(sorted(C, key=lambda x: x[2]+x[1]))#将每行的第2列,第3列相加按照升序排列
输出:
[('a', 6, 1), ('b', 5, 3), ('c', 5, 4), ('d', 1, 5), ('e', 4, 2)]
[('a', 6, 1), ('b', 5, 3), ('c', 5, 4), ('d', 1, 5), ('e', 4, 2)]
[('a', 6, 1), ('e', 4, 2), ('b', 5, 3), ('c', 5, 4), ('d', 1, 5)]
[('e', 4, 2), ('d', 1, 5), ('a', 6, 1), ('b', 5, 3), ('c', 5, 4)]