如何逐步去构建一个大型网站系统
如何逐步去构建一个大型网站系统
更多干货
- 分布式实战(干货)
- spring cloud 实战(干货)
- mybatis 实战(干货)
- spring boot 实战(干货)
- React 入门实战(干货)
- 构建中小型互联网企业架构(干货)
- python 学习持续更新
- ElasticSearch 笔记
- kafka storm 实战 (干货)
一、概述
往往程序员在面试的时候,很多时候面试官会考察你对一个大型网站系统的设计思路。
首先我们要思考一个问题,什么样的网站才是大型网站,从网站的技术指标角度考虑这个问题人们很容易犯一个毛病就是认为网站的访问量是衡量的指标,懂点行的人也许会认为是网站在单位时间里的并发量的大小来作为指标
其实这种网站访问量非常大,并发数也非常高,但是它却能用最为简单的Web技术来实现:我们只要保持网站的充分的静态化,多部署几台服务器,那么就算地球上所有人都用它,网站也能正常运行。
大型网站是技术和业务的结合,一个满足某些用户需求的网站只要技术和业务二者有一方难度很大,必然会让企业投入更多的、更优秀的人力成本实现它,那么这样的网站就是所谓的大型网站了。
互联网时代,怎么构建一个大型网站是不可缺少的技能。当然,本人目前接触的网站都是读远远大于写。本文将一步步讲诉,怎么去使用lamp构建完善一个大型网站
网站架构,我个人认为最为重要的是两方面的考虑:计算和存储。有些是属于计算密集型,有些是IO密集型。所以以下都将围绕计算和存储来讲述问题。
二、最简单的搭建
假设我们自己创业了,那么我们可能需要自己去搭建一个网站。
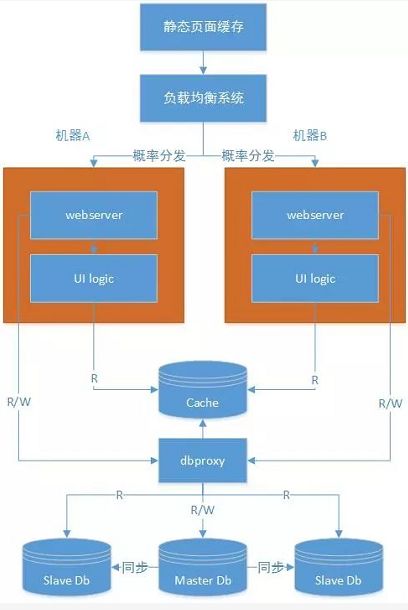
这个时候,我们需要去租借一个主机(比如阿里云的虚拟主机等)。对于网站来说,数据是最为重要的,所以需要有一个备份。但是每天pv肯定不高,所以理论上只需要一个计算机器即可。因此,我们只需要3台机器就能完整一个完整的架构。
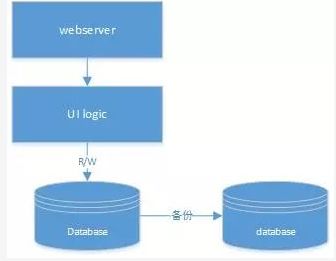
从上图可以看到计算机器上主要部署2部分内容,一部分是webserver(轻量级可以考虑niginx,lighttpd等),一个是UI逻辑处理部分,lamp架构则使用php语言来搞定这个问题。因为数据是最重要的,所以database则明显需要2台机器,一台主机,一台做冗余备份。lamp使用mysql来存储数据。
三、增加数据缓存
随着我们网站知名度变高,每天pv越来越大,导致的问题是数据库压力越来越大。很明显,绝大部分网站,**读流量都远远高于写流量。**即使我们开了mysql的query cache,它也只能在一定程度上通过减少DB机器I的操作来减少DB服务器压力。更为靠谱的是,减少对DB服务器的请求。那么这个时候就需要使用cache.
cache为非关系型kv存储,在使用过程中一般为内存操作。下面的架构改进如下。
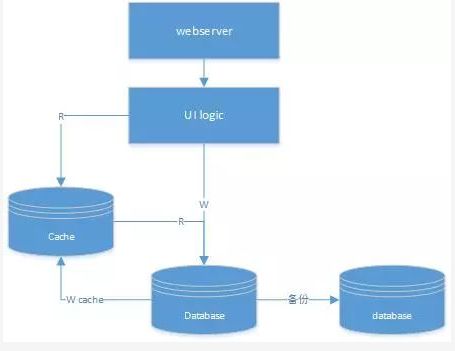
可以看出ui写数据仍然直接写入到数据库,但是读则先从cache读取,cache读取不到再从database读取。因为很有可能大部分数据都直接访问cache就可以搞定,这样就可以大大减少数据库的压力。
四、pv uv qps
pv
PV(page view),即页面浏览量
pv的解释是,一个访问者在24小时(0点到24点)内到底看了你网站几个页面。这里需要强调:同一个人浏览你网站同一个页面,不重复计算pv量,点100次也算1次。说白了,pv就是一个访问者打开了你的几个页面。
uv uv(unique visitor),指访问某个站点或点击某条新闻的不同IP地址的人数。
在同一天内,uv只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。独立IP访问者提供了一定时间内不同观众数量的统计指标,而没有反应出网站的全面活动。
QPS
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
四、增加计算机集群(计算方向)
随着整个系统pv继续上涨。单台的计算机器已经无法满足要求。这个时候就需要使用增加计算机器来解决问题。为了方便起见,可以把这个机器放入一个集群进行统一管理。
这个时候,我们可能需要考虑2个问题:负载均衡、数据同步。负载均衡系统相对难度较大,但是是必不可少的,最简单的可以通过zookkeeper等对配置文件进行统一管理。对于节点下的若干机器,可以简单通过概率来进行请求分发。数据同步也是一个难点,比如session同步、文件操作等。
需要说明的是,好的架构结果如下:N台机器能撑住的PV为X,那么TN台机器基本能撑住TX pv。换句话说,架构必须能支持横向扩展。如果机器加了一倍,但是撑住的峰值pv不能增加(接近)一倍,那个这个架构就是失败的架构,不是可扩展性的架构。
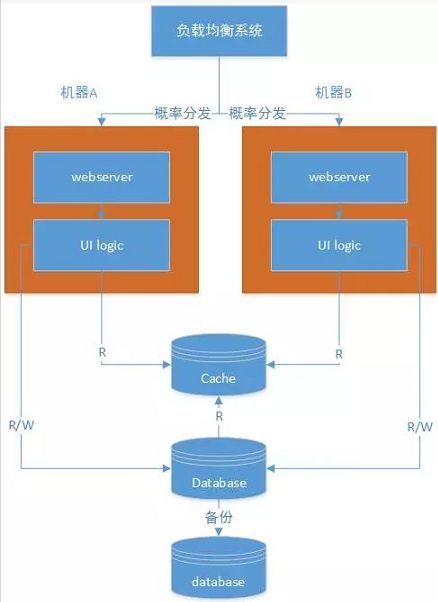
可以看出的是在负载均衡系统下可以挂很多机器。好的扩展是,加入多少倍机器,计算能力就相应提高多少倍(暂时不考虑存储的瓶颈)。
五、搭建简单的数据库集群(存储方向)
流量上升,计算能力提升的同时,也需要提升数据库的能力。这时候,我们可以采用读写分离。也就有了主从之说。主库可以写,当然也肯定能提供写,从库只能提供读,我们目前主从延时在20ms以内。目前这种工具不少,比如mysql proxy等。(下图应该是ui logic访问dbproxy,图有稍许错误,但是不影响理解)。
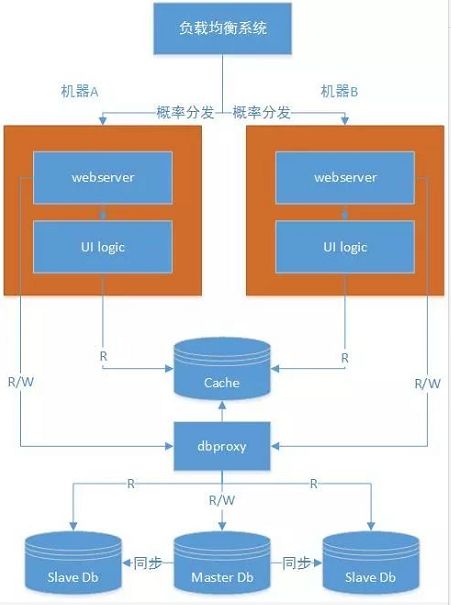
如上图,dbproxy作用主要有3个:
读写分离:读主要读从库,写只能是写主库。我们在实际设计的时候需要考虑主从延时,比如事务读必须读主库,写完若干秒内最好读主库等等。
负载均衡:他能自动根据dbproxy下面挂在的db进行负载均衡。
维持sql连接池:dbproxy维持sql连接池,里面存在和db的长连接。请求过来之后,直接从连接池取连接即可。
六、静态页面跨地域缓存
很明显,我们网站有很多静态页面,若干天才会更换一次。但是因为跨地域、跨机房的问题,外地用户可能访问较慢,所以我们可以通过cdn等技术缓存静态页面。这样就可以减少对服务器的请求,同时加快外地、不同机房用户的访问时间。
如上图所示,加入了静态页面缓存
七、跨地域跨机房设计
当我们业务进一步扩大,我们可能需要跨地域进行机器部署,目前我们主要分为华北(北京)和华东机房(杭州、南京)。跨地域部署,可以加快因为区域带来的访问过慢问题。比如广州访问北京机房数据,就不如北京访问北京机房速度快。这个时候,还是主要分为计算和存储两方面进行讲述。
计算方向
除了该机房的标示以外,各个机房的机器部署应该完全一致。
存储方向
在我看来,对于读远远大于写的系统而言,最好只有一个主库,若干个从库。所以只需要在其他机房搭建从库,让从库从主库进行数据同步即可。当然,这样的代价是主从时间比比较长。在数据链路不稳定的情况下,主从同步可能在400ms以上,所以设计需要考虑这个。
当然cache等等也需要跨地域跨机房部署。
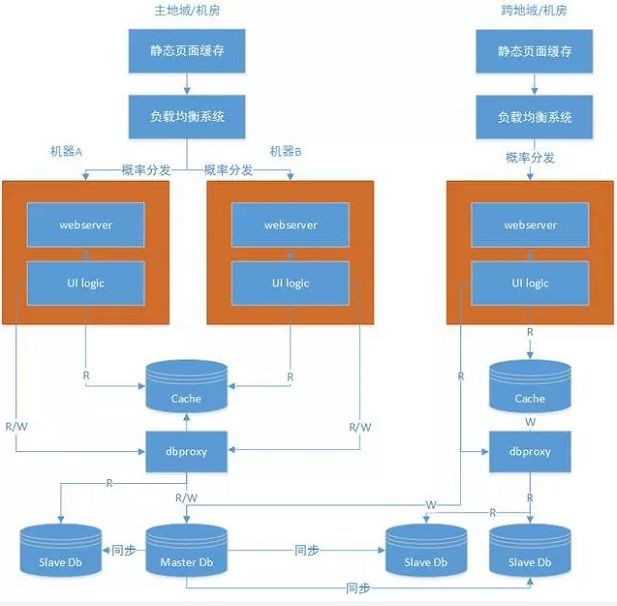
如图简要勾勒出了跨地域跨机房的一个部署方案。
通用服务的使用
随着业务拓宽,我们可能会有一些需要考虑新能的模块或者业务。
如搜索业务,我们不可能直接通过数据库的select like来实现,就需要使用C等编译型语言来搭建其他系统。所以需要我们根据业务进行架构调整来通过http等使用一些通用的高性能计算方向的服务。
同样,出于业务发展等因素的考虑,我们需要使用内存型的数据库,比如redis等,这些属于存储方向的通用服务。
这些服务,有的可以跨机房部署,各个机房无耦合,有的则相互之间有耦合,比如类似于数据库的主库从库。
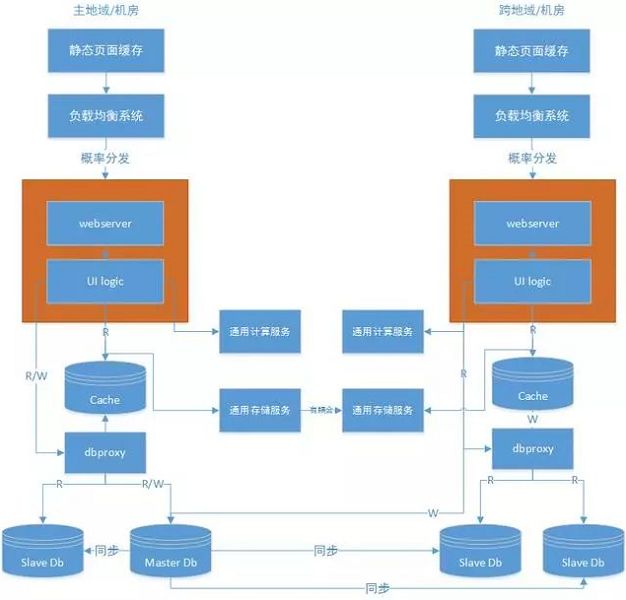
八、其它考虑
除此以外,我们还需要有其他因素进行考虑
网站数据:这个主要是比如uv/pv。这个有几种做法,第一种是借助第三方的统计攻击,比如百度统计、Google统计等。第二种是对我们现有系统的日志进行统计,同时可以进行深一步的数据挖掘。
安全性:这个需要考虑网站是不是存在sql注入,xss漏洞,csrf漏洞等。这个方面对于网站是非常关键的。一旦有黑客攻入,后果不堪设想。对于管理员后台,最好不要开通外网权限,只能通过内网访问。
seo:搜索引擎优化对于网站作用不言而喻。 后续可能会专门针对百度SEO进行一些分析。