15亿参数的NLP模型究竟有多强大?有人用它生成了一部《哈利·波特》
源 / 新智元
上周,OpenAI 发表了一个超大规模的 “通用”NLP 模型 ——GPT-2。这个模型是 OpenAI 去年发布的无监督 NLP 模型 GPT 的直接拓展,基于Transformer,拥有 15 亿参数,使用含有 800 万网页内容的数据集训练。
GPT-2 可以生成连贯的文本段落,刷新了 7 大数据集基准,并且能在未经预训练的情况下,完成阅读理解、问答、机器翻译等多项不同的语言建模任务。
但 OpenAI 声称 “有鉴于其强大的能力和可能被滥用的危险”,并没有公布 GPT-2 模型及代码,只公布了一个包含 117M 参数的样本模型及代码。
此举引起 AI 社区热议,有人批判 OpenAI 变 CloseAI,也有人赞赏 OpenAI 对 AI 安全的谨慎态度。
这个模型究竟强大到什么程度,以至于它的创造者如此担心它被恶意使用呢?
Janelle Shane 是一位喜欢训练神经网络做各种有趣事情的光学研究科学家,她曾用 AI生成过菜谱、猫咪、歌曲等等。这次,她当然没有错过用 GPT-2 创作。
她在推特上写道:
我一直渴望看看 GPT-2 会如何编写哈利 · 波特的剧本,结果超乎我想象的好。
当然,Janelle 最初用的是公开的 117M 参数的 GPT-2 模型。方法是给模型提供一句话的 “提示”,神经网络输出一段文字,效果如下:
Prompt: Harry wished that Hermione would hurry up. The icing was beginning to harden.
提示:哈利希望赫敏快点。冰开始变硬了。
Response: Even now, the cracks only hurt and were beginning to make the steel in her hair and tie in like clumps. Hermione sipped the bitter frost from her dinner and chewed on her eating soup.
回答:现在,裂缝已经让她感到疼痛,开始让她的头发变得像钢铁一样坚硬,结成一团一团的。赫敏呷了一口正餐上的霜冻,咀嚼着汤。
感觉怎么样?似乎称不上十分震撼。
但随后,Janelle Shane 得到 OpenAI 研究人员的帮助,用完整的、15 亿参数版本的GPT-2 模型做了同样的事情 —— 生成一个《哈利 · 波特》的同人电影剧本!
15亿参数的GPT-2 生成的《哈利·波特》剧本
Janelle Shane 在推特上分享了完整版GPT-2 模型生成的哈利·波特剧本,其中,只有”Open AI asked a bot" 和前 2 行对话来自人类的提示:



OpenAl 让 GPT-2 阅读了大量互联网上的《哈利 · 波特》同人小说电影剧本,然后让它自己写一个哈利 · 波特电影。
哈利:我们快到霍格沃茨了!
赫敏:到目前为止还没有出现任何攻击或灾难。
哈利:你是想出现一场战争吗,赫敏?嗯…… 这不是能和米勒娃谈的事情。她很担心。
赫敏:夏天的时候有一个名叫斯内普的巫师发生了一起事件。
[赫敏对斯内普称她 “哈利” 感到吃惊。]
哈利:嗯,一定是他。
赫敏:是另一个。
哈利:是的,伦敦那位。
哈利:我们应该去那儿的。
[哈利试图回到魔法部。]
哈利:但邓布利多说这很危险。
哈利:也许他不相信斯内普。
哈利:嗯,我相信你能想到的……
哈利:但他不在那儿时,他甚至没有注意到斯内普在那儿……
哈利:他为什么不阻止我呢?
哈利:因为我知道真相,而他不知道。
[斯内普走进他的办公室,然后看着他的信。]
赫敏:那么,你告诉他真相了吗 ?
斯内普:是的。
哈利:这会毁了他吗?你想让他看到真相。
斯内普:[转向她] 赫敏,我 —— 我 —— 我不是在要求你接受我。
哈利:[微笑]。不,这很好,没必要。
斯内普:我明白。
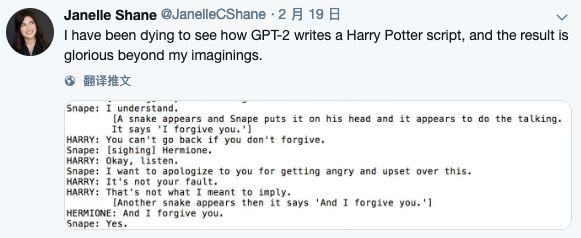
[一条蛇出现了,斯内普把它放在他的头上,它似乎在说话。它说:“我原谅你。”]
哈利:如果你不原谅,就回不去了。
斯内普:(叹气) 赫敏。
哈里:好了,听着。
斯内普:我对这件事很生气,很难过,我想为此向你道歉。
哈利:这不是你的错。
哈利:我不是这个意思。
[出现了另一条蛇,它说’我原谅你。’]
赫敏:我原谅你。
斯内普:好的。
哈利:[坐下来,从肖像洞口望出去] 我想他们会想让我成为他们的部长。
[他看着壁炉里的肖像洞,肖像被烧掉了。盒子里有一个戒指。看起来像赫敏送给哈利的戒指。]
斯内普:那不是你的。
哈利:是我的。
斯内普:不是我的。
哈利:一个朋友也问了我同样的问题,赫敏。
[斯内普伸出他的手臂,被扯下来了。哈利摘下戒指。这是一颗形状像紫水晶的蓝宝石。是赫敏送给他的戒指。]
[镜头移到肖像洞口,火光落在戒指上。面画显示斯内普伸出他受伤的手臂。]
哈利:[看着照片] 我想你该告诉我了。
[他看着壁炉里的戒指,蓝宝石又回到了盒子里。火光又灭了。]
斯内普:哈利,你永远不会知道这是怎么来的。
哈利:一切都在我的掌控之中。
[斯内普转过身来,他穿着一件睡衣,只有魔杖尖还有火苗。一条蛇坐在盒子上面。]
蛇:有两种方法可供选择。
[斯内普打开盒子,蛇进入盒子的另一边。斯内普站了起来。]
蛇:你有两种选择。
哈利:两个我都不想要。
蛇:哈利,哈利,你父亲总是告诉我,人生只有两件事情是重要的,你的父母和你的国家。
哈利:[指着自己] 你说得对,我不想要你或其他任何人。
斯内普:不,你会想要的。
[斯内普从哈利身边走过。背景中是海格的一幅画,中间是 Snively。蛇在海格的怀里。她怀里抱着一只黑猫。]
THE END
这个效果实在让人惊叹!甚至有点引人入胜,“斯内普头上的蛇” 是怎么回事?斯内普想要赫敏原谅他什么?
当然,模型并不完美,生成的剧情有时候让人迷惑,网络在人称指代关系上有时候也不明确。
但 Janelle 说:“这个结果超乎我想象的好!”
15 亿参数模型的结果跟 117M 参数的小模型的结果进行比较也很有趣。Janelle 表示,117M 版本模型生成的剧本经常偏离了格式和角色,变成用文字记录的散文或视频游戏记录。

117M参数的GPT-2生成的结果
但完整模型甚至很好地保持了格式上的统一。要知道,人类提供的提示只有”Open AI asked a bot" 和前 2 行对话。
网友评论中也纷纷表示惊叹:
“哇!如果让大卫 · 林奇 (David Lynch) 来写一部《哈利 · 波特》电影,感觉就是这样子的。而且,角色还会倒叙。”
“很惊讶它一直保持着相同的叙事风格。”
“117M 版本模型生成的剧本也给我留下了深刻的印象。它会引入其他适合的角色,等等。尽管在我经验中,它倾向于把史波克和柯克写进任何《星际迷航》故事里!”
从 "Okay, listen" 到 "meant to imply" 这里,真的是非常连贯的对话,在我看来这些对话完全可能出现在小说里。
Janelle 还提供了两个 “未选用镜头”:


在这两个失败镜头中,GPT-2 没有编写《哈利波特》的剧本,而是编写了一个由 bot 撰写的脚本,讲述编剧如何让机器人编写剧本。
零日攻击担忧
OpenAI 表示,他们对 GPT-2 的发布策略是:
由于担心大型语言模型被用于大规模地生成欺骗性、有偏见或恶意的语言,我们只发布了一个更小版本的 GPT-2 模型以及样本代码。
这里,我们有必要讨论 “规模”。OpenAI 研究人员的主张是,如果没有时间让更广泛的社区考虑好,更大规模的模型可能会造成重大损害。有意思的是,就连他们自己也不认为对这个决定有信心:
这个决定,以及我们对它的讨论,是实验性质的:虽然我们不确定这在今天是否正确的决定,但我们相信 AI 社区最终需要在某些研究领域以一种深思熟虑的方式来解决出版规范的问题。
这个模型的规模有多大呢?他们没有在博客文章中明确提到这一点,但根据论文,新模型的参数大约是之前的 GPT 模型的 10 倍。fast.ai 的 Jeremy Howard 据此推测,从AWS 租用 10 台 8 GPU 的服务器,在一个月内训练模型大约需要 5 万美元。当然也可以购买 8 张 RTX 2070 或 RTX 2080 ti 的 GPU,花 10 个月来训练,成本大约需要 2万美元。当然,还要考虑收集数据和试错所需的时间和金钱成本。
因此,在实践中,不发布模型的决定有两个结果:
(1) 其他组织要想成功复制模型,可能至少需要几个月的时间,因此我们有一些喘息的空间来讨论当它变得更广泛可用时应该怎么做。
(2) 负担不起 10 万美元左右费用的小型组织无法以演示中的规模使用这项技术。
Howard认为,第 (1) 点似乎是件好事。如果突然有人在没有任何警告的情况下使用这项技术,那么没有人能够做好准备。(理论上,人们可能已经做好了准备,因为 NLP 社区的研究人员已经警告过这样一个潜在的问题,但在实践中,人们往往不会认真对待它,直到他们真正看到问题发生。)
例如,在计算机安全社区中,如果你发现了一个缺陷,那么你的期望是帮助社区做好准备,然后才会发布完整的细节 (也许是一个漏洞)。如果这种情况没有发生,就称为 “零日攻击”(zero day attack),这会造成巨大的破坏。
另一方面,第 (2) 点就成问题了。最严重的威胁也最有可能来自拥有 10 万美元的人成本的人,例如,进行虚假宣传活动,试图改变民主选举结果。
对于这种攻击,唯一可行的防御方法是使用相同的工具来识别和反击这种虚假信息。当受到影响的更广泛的社区使用这种防御时,它的力量可能会更加强大。正如我们在维基百科或开源软件等项目中所看到的那样,一大群个人的力量一再被证明在创造方面比在破坏方面更强大。
那么,OpenAI 应该发布他们的完整预训练模型吗?Howard 表示,他也不知道。但毫无疑问,OpenAI 已经展示了一些与以前的成果有本质区别的东西(尽管没有展示出任何算法或理论上的突破)。Howard 认为这个模型会被恶意使用:它将成为传播虚假信息和大规模影响话语的有力工具,并且可能只需花费 10 万美元。
如果发布模型,这种恶意使用将更快地发生。但是,如果不发布该模型,那么可用的防御也会减少,对这个问题的理解也会更少。这两种结果都不好。
你觉得呢?
推荐阅读
人间真实:程序员的 60 个崩溃瞬间!
超强干货!TensorFlow易用代码大集合...
秘籍 | Python高效编程技巧
史上最污技术解读,让你秒懂IT术语
汇总 | 机器学习算法优缺点 & 如何选择
逃离数学焦虑、算法选择,思考做好机器学习项目的3个核心问题
15亿参数!史上最强通用NLP模型诞生:狂揽7大数据集最佳纪录
滴滴官宣裁员
