[JavaWeb-02]MySQL
文章目录
- 1、MySQL基础
- 1.1 数据库基本介绍
- 1.2 数据库的登陆
- 1.2.1 使用DOS命令方式启动
- 1.2.2 使用可视化工具--SQLyog
- 1.3 MySQL安装后的目录结构
- 1.4 数据库管理系统
- 1.5 SQL的概念
- 1.6 MySQL的语法
- 1.7 DDL(数据定义语言)
- 1.7.1 创建数据库、数据表
- 1.7.2 查看数据库、数据表
- 1.7.3 修改数据库、数据表
- 1.7.4 删除数据库、数据表
- 1.8 DML(数据操纵语言)
- 1.8.1 插入记录
- 1.8.2 蠕虫复制
- 1.8.3 更新表记录
- 1.8.4 删除表记录
- 1.9 DQL(数据查询语言)
- 1.9.1 简单查询
- 1.9.2 指定列的别名进行查询
- 1.9.3 清除重复值
- 1.9.4 查询结果参与运算
- 1.9.5 条件查询
- 1.9.6 排序
- 1.9.7 聚合函数
- 1.9.8 分组
- 1.9.9 限制
- 1.10 数据库的备份和还原
- 1.10.1 备份
- 1.10.2 还原
- 2、MySQL约束
- 2.1 主键约束
- 2.1.1 创建主键
- 2.1.2 删除主键
- 2.1.3 主键自增
- 2.2 唯一约束
- 2.3 非空约束
- 2.4 外键约束
- 2.4.1 应用场景
- 2.4.2 创建外键
- 2.4.3 删除外键
- 2.4.4 外键的级联
- 2.5 表与表之间的关系
- 2.6 数据库范式
- 3、MySQL多表&事务
- 3.1 表连接查询
- 3.1.1 内连接
- 3.1.2 外连接
- 3.2 子查询
- 3.2.1 单行单列
- 3.2.2 多行单列
- 3.2.3 多行多列
- 3.3 事务
- 3.3.1 手动提交事务
- 3.3.2 自动提交事务
- 3.3.3 事务原理
- 3.3.4 事务回滚点
- 3.3.5 事务的隔离级别
1、MySQL基础
1.1 数据库基本介绍
数据库是存储数据的仓库,本质上是一个文件系统,以文件的方式存储数据到计算机上。所有的关系型数据库都可以使用通用的 SQL 语句进行管理。
MySQL是开源免费的数据库,小型的数据库,已经被 Oracle 收购了。MySQL6.x 版本也开始收费。选择MySQL的原因是免费且功能强大。
1.2 数据库的登陆
MySQL 是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的 root 账号,使用安装时设置的密码即可登录。
1.2.1 使用DOS命令方式启动
登陆格式1:mysql -u用户名 -p密码
![[JavaWeb-02]MySQL_第1张图片](http://img.e-com-net.com/image/info8/aaff8e0a98f04f71ab859954c0b4e3d6.jpg)
登陆格式2:mysql -h地址 -u用户名 -p密码

登陆格式3:mysql --host=ip地址 --user= 用户名 --password= 密码

1.2.2 使用可视化工具–SQLyog
SQLyog是业界著名的Webyog公司出品的一款简洁高效、功能强大的图形化MySQL数据库管理工具。使用SQLyog 可以快速直观地让您从世界的任何角落通过网络来维护远端的 MySQL 数据库。
![[JavaWeb-02]MySQL_第2张图片](http://img.e-com-net.com/image/info8/d38f15c4177b4687ab7d4f857173dd70.jpg)
1.3 MySQL安装后的目录结构
| MySQL的目录结构 | 描述 |
|---|---|
| bin文件夹 | 所有mysql的可执行文件,如:mysql.exe |
| MySQLInstanceConfig.exe | 数据库的配置向导,在安装时出现的内容 |
| data文件夹 | 系统必须的数据库所在的目录 |
| my.ini 文件 | mysql 的配置文件,一般不建议去修改。 |
| c:\ProgramData\MySQL\MySQL Server 5.5\data | 我们自己创建的数据库所在的文件夹 |
1.4 数据库管理系统
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中表内的数据。
数据库管理程序(DBMS)可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。为保存应用中实体的数据,一般会在数据库创建多个表,以保存程序中实体 User 的数据。
数据库管理系统、数据库和表的关系如图所示:
![[JavaWeb-02]MySQL_第3张图片](http://img.e-com-net.com/image/info8/3f315fd812424492bf37752b20f94b0a.jpg)
一个数据库服务器包含多个数据库,一个数据库包含多张表,一张表包含多条记录。数据库在计算机上以文件夹的形式存在,表以文件的形式存在。
1.5 SQL的概念
SQL是Structured Query Language 结构化查询语言,是一种所有关系型数据库的查询规范,不同的数据库都支持。通用的数据库操作语言,可以用在不同的数据库中。不同的数据库 SQL 语句有一些区别。
SQL语句主要有以下分类:
1)Data Definition Language (DDL 数据定义语言) 如:建库,建表
2)Data Manipulation Language(DML 数据操纵语言),如:对表中的记录操作增删改
3)Data Query Language(DQL 数据查询语言),如:对表中的查询操作
4)Data Control Language(DCL 数据控制语言),如:对用户权限的设置
即,对于数据库服务器的使用,无非就是操作数据库(文件夹)、操作数据表(文件)。、
1.6 MySQL的语法
每条语句以分号结尾,如果在 SQLyog 中不是必须加的。SQL 中不区分大小写,关键字中认为大写和小写是一样的,但建议关键字用大写,方便阅读。当行注释是两个但斜杠加空格“-- ”,多行注释是“/**/”,还有mysql独有的注释“#”。
1.7 DDL(数据定义语言)
Data Definition Language (DDL 数据定义语言) 就是建立数据库(文件夹)和建立数据表(文件)的语法,详细介绍如下:
1.7.1 创建数据库、数据表
创建数据库的三种格式:
-- 直接创建数据库
-- CREATE DATABASE 数据库名;
CREATE DATABASE db1;
-- 判断是否存在,如果不存在则创建数据库
-- CREATE DATABASE IF NOT EXISTS 数据库名;
CREATE DATABASE IF NOT EXISTS db2;
-- 创建数据库并指定字符集为 gbk
-- CREATE DATABASE 数据库名 CHARACTER SET 字符集;
CREATE DATABASE db3 CHARACTER SET gbk;
创建数据表的格式:
/*
CREATE TABLE 表名 (
字段名 1 字段类型 1,
字段名 2 字段类型 2
);
*/
CREATE TABLE student (
id INT, -- 整数
name VARCHAR(20), -- 字符串
birthday DATE -- 生日,最后没有逗号
);
-- 快速创建一个表结构相同的表:CREATE TABLE 新表名 LIKE 旧表名;
CREATE TABLE s1 LIKE student;
1.7.2 查看数据库、数据表
查看数据库:
-- 查看所有的数据库
SHOW DATABASES;
-- 查看正在使用的数据库
SELECT DATABASE(); 使用的一个 mysql 中的全局函数
-- 使用/切换数据库:USE 数据库名;
USE db1;
-- 查看某个数据库的定义信息
SHOW CREATE DATABASE db3;
SHOW CREATE DATABASE db1;
查看数据表(前提是进入数据库):
-- 先进入数据库:USE 数据库名;
USE db1;
-- 查看数据库中的所有表
SHOW TABLES;
-- 查看表结构
DESC 表名;
-- 查看创建表的 SQL 语句
SHOW CREATE TABLE 表名;
1.7.3 修改数据库、数据表
修改数据库:
-- 修改数据库默认的字符集:ALTER DATABASE 数据库名 DEFAULT CHARACTER SET 字符集;
ALTER DATABASE db3 CHARACTER SET utf8;
修改数据表:
-- 添加表列 ADD:ALTER TABLE 表名 ADD 列名;
ALTER TABLE student ADD remark VARCHAR(20);
-- 修改列类型 MODIFY:ALTER TABLE 表名 MODIFY 列名 新的类型;
ALTER TABLE student MODIFY remark VARCHAR(100);
-- 修改列名 CHANGE:ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
ALTER TABLE student CHANGE remark intro VARCHAR(30);
-- 删除列:ALTER TABLE 表名 DROP 列名;
ALTER TABLE student DROP intro;
-- 修改表名:RENAME TABLE 表名 TO 新表名;
RENAME TABLE student TO student2;
-- 修改字符集:ALTER TABLE 表名 CHARACTER SET 字符集;
ALTER TABLE student2 CHARACTER SET gbk;
1.7.4 删除数据库、数据表
删除数据库:
-- DROP DATABASE 数据库名;
drop database db2;
删除数据表:
-- 直接删除表:DROP TABLE 表名;
DROP TABLE s1;
-- 判断表是否存在并删除 s1 表:DROP TABLE IF EXISTS 表名;
DROP TABLE IF EXISTS s1;
1.8 DML(数据操纵语言)
DML用于对数据表中的记录进行增删改。
1.8.1 插入记录
/*
INSERT INTO 表名 -- 表示往哪张表中添加数据
(字段名1,字段名2,...) -- 要给哪些字段设置值
VALUES
(值1,值2,...); -- 设置具体的值
*/
INSERT INTO student
(id,NAME,age,sex,address)
VALUES
(1,'学哥斌',20,'男','广东广州');
-- 插入全部字段
-- 方式一:所有的字段名都写出来
-- 格式:INSERT INTO 表名 (字段名1,字段名2,字段名3…) VALUES (值1,值2,值3);
INSERT INTO student (id,name,age,sex) VALUES (1, '孙悟空', 20, '男','水帘洞');
-- 没有添加的字段会使用 NULL
INSERT INTO student (id,name,age,sex) VALUES (1, '孙悟空', 20, '男');
-- 方式二:不写字段名(默认添加所有字段)
-- 格式:INSERT INTO 表名 VALUES (值1,值2,值3…);
INSERT INTO student VALUES (3, '孙悟饭', 18, '男', '龟仙人洞中');
注意事项:插入的数据应与字段的数据类型相同,数据的大小应在列的规定范围内,在values中列出的数据位置必须与被加入的列的排列位置相对应,字符和日期型数据应包含在单引号中,不指定列或使用 null,表示插入空值。
1.8.2 蠕虫复制
蠕虫复制即将一张已经存在的表中的数据复制到另一张表中。
-- 将表名2中的所有的列复制到表名1中
-- INSERT INTO 表名1 SELECT * FROM 表名2;
INSERT INTO student2 SELECT * FROM student;
-- INSERT INTO 表名1(列1,列2) SELECT 列1,列2 FROM student;
INSERT INTO student2 (name,age) SELECT name,age FROM student;
1.8.3 更新表记录
/*
UPDATE 需要更新的表名
SET 修改的列值
WHERE 符合条件的记录才更新
*/
-- 不带条件修改数据,将所有的性别改成女
UPDATE student SET sex = '女';
-- 带条件修改数据,将 id 号为 2 的学生性别改成男
UPDATE student SET sex='男' WHERE id=2;
-- 一次修改多个列,把 id 为 3 的学生,年龄改成 26 岁,address 改成北京
UPDATE student SET age=26, address='北京' WHERE id=3;
1.8.4 删除表记录
-- DELETE FROM 表名 [WHERE 条件表达式]
-- 带条件删除数据,删除 id 为 1 的记录
DELETE FROM student WHERE id=1;
-- 不带条件删除数据,删除表中的所有数据
DELETE FROM student;
-- 使用 TRUNCATE 删除表中所有记录(TRUNCATE 相当于删除表的结构,再创建一张表。)
TRUNCATE TABLE 表名;
1.9 DQL(数据查询语言)
查询不会对数据库中的数据进行修改.只是一种显示数据的方式。
基本格式:SELECT 列名 FROM 表名 [WHERE 条件表达式]
SELECT 命令可以读取一行或者多行记录。可以使用星号(* )来代替其他字段,SELECT 语句会返回表的所有字段数据。可以使用 WHERE 语句来包含任何条件。
SQL语句顺序分为书写顺序和执行顺序:
书写顺序:SELECT-> FROM-> WHERE-> GROUP BY -> HAVING -> ORDER BY -> LIMIT[OFFSET,]
执行顺序:FROM-> WHERE-> GROUP BY -> HAVING-> SELECT -> ORDER BY -> LIMIT
最先执行的总是FROM操作,最后执行的是LIMIT操作。其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入,只是这些虚拟的表对用户来说是透明的,但是只有最后一个虚拟的表才会被作为结果返回。如果没有在语句中指定某一个子句,那么将会跳过相应的步骤。
FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1;
WHERE: 对虚拟表VT2进行WHERE条件过滤。只有符合
GROUP BY: 根据GROUP BY子句中的列,对VT2中的记录进行分组操作,产生VT3;
HAVING: 对虚拟表VT3应用HAVING过滤,只有符合
SELECT: 执行SELECT操作,选择指定的列,插入到虚拟表VT5中;
ORDER BY: 将虚拟表VT5中的记录按照
LIMIT:取出指定行的记录,产生虚拟表VT7, 并将结果返回。
1.9.1 简单查询
-- 查询所有行和列
-- 格式:SELECT * FROM 表名;
SELECT * FROM student;
-- 查询指定的列
-- 格式:SELECT 字段名 1,字段名 2,字段名 3,... FROM 表名;
SELECT name,age FROM student;
1.9.2 指定列的别名进行查询
-- 对列指定别名
-- 格式:SELECT 字段名 1 AS 别名, 字段名 2 AS 别名... FROM 表名;
SELECT name as 姓名,age AS 年龄 FROM student;
-- 对列和表使用别名
-- 格式:SELECT 字段名 1 AS 别名, 字段名 2 AS 别名... FROM 表名 AS 表别名;
SELECT st.name AS 姓名,age AS 年龄 FROM student AS st
1.9.3 清除重复值
-- 查询指定列并且结果不出现重复数据
-- 格式:SELECT DISTINCT 字段名 FROM 表名;
SELECT DISTINCT address FROM student;
1.9.4 查询结果参与运算
-- 某列数据和固定值运算
-- 格式:SELECT 列名 1 + 固定值 FROM 表名;
SELECT math+5 FROM student;
-- 某列数据和其他列数据参与运算
-- 格式:SELECT 列名 1 + 列名 2 FROM 表名;
SELECT *,(math+english) AS 总成绩 FROM student;
1.9.5 条件查询
条件查询就是取出表中的每条数据,满足条件的记录就返回,不满足条件的记录不返回。
格式:SELECT 字段名 FROM 表名 WHERE 条件;
创建一个表来进行演示:
-- 创建 student 表
CREATE TABLE student (
id INT, -- 编号
name VARCHAR(20), -- 姓名
age INT, -- 年龄
sex VARCHAR(5), -- 性别
address VARCHAR(100), -- 地址
math INT, -- 数学
english INT -- 英语
);
-- 插入数据
INSERT INTO
student(id,NAME,age,sex,address,math,english)
VALUES
(1,'马云',55,'男','杭州',66,78),
(2,'马化腾',45,'女','深圳',98,87),
(3,'马景涛',55,'男','香港',56,77),
(4,'柳岩',20,'女','湖南',76,65),
(5,'柳青',20,'男','湖南',86,NULL),
(6,'刘德华',57,'男','香港',99,99),
(7,'马德',22,'女','香港',99,99),
(8,'德玛西亚',18,'男','南京',56,65);
-- 查询表所有行和列
SELECT * FROM student;
执行后显示如下:
![[JavaWeb-02]MySQL_第4张图片](http://img.e-com-net.com/image/info8/4fe6dfdfdfb9446880ff607a0fb60189.png)
使用比较运算符对这个表进行条件查询:
| 比较运算符 | 说明 |
|---|---|
| > 、< 、<= 、>= 、= 、<> | <>在 SQL 中表示不等于,在 mysql 中也可以使用!=,没有==运算符 |
| BETWEEN…AND | 在一个范围之内,如:between 100 and 200相当于条件在 100 到 200 之间,包头又包尾 |
| IN( 集合) | 集合表示多个值,使用逗号分隔 |
| LIKE ’ 张%’ | 模糊查询,%匹配任意多个字符,_匹配一个字符 |
| IS NULL | 查询某一列为 NULL 的值,注:不能写=NULL |
查询math分数大于80分的学生:SELECT * FROM student WHERE math>80;

查询 english 分数小于或等于 80 分的学生:SELECT * FROM student WHERE english <=80;

查询 age 等于 20 岁的学生:SELECT * FROM student where age = 20;

查询 age 不等于 20 岁的学生,注:不等于有两种写法
写法一:SELECT * FROM student WHERE age <> 20;
写法二:SELECT * FROM student WHERE age != 20;
![[JavaWeb-02]MySQL_第5张图片](http://img.e-com-net.com/image/info8/e38d61eff4034a2a92aa068a5019a727.png)
查询 english 成绩大于等于 75,且小于等于 90 的学生:SELECT * FROM student WHERE english between 75 and 90;

查询姓马的学生:SELECT * FROM student WHERE name LIKE '马%';

查询姓马,且姓名有两个字的学生:SELECT * FROM student WHERE name LIKE '马_';

使用逻辑运算符对这个表进行条件查询:
| 逻辑运算符 | 说明 |
|---|---|
| and 或 && | 与,SQL 中建议使用前者,后者并不通用。 |
| or 或 || | 或 |
| not 或 ! | 非 |
查询 age 大于 35 且性别为男的学生:SELECT * FROM student WHERE age>35 AND sex='男';

查询 age 大于 35 或性别为男的学生:SELECT * FROM student WHERE age>35 OR sex='男';
![[JavaWeb-02]MySQL_第6张图片](http://img.e-com-net.com/image/info8/800298c8d0e5466da5683d674d6a3afc.png)
查询 id 是 1 或 3 或 5 的学生:SELECT * FROMstudent WHERE id=1 OR id=3 OR id=5;
![[JavaWeb-02]MySQL_第7张图片](http://img.e-com-net.com/image/info8/bb55dca1cc3843749c4feb5efdc94224.png)
IN关键字:里面的每个数据都会作为一次条件,只要满足条件的就会显示。
查询 id 是 1 或 3 或 5 的学生:SELECT * FROM student WHERE id IN (1,3,5);

1.9.6 排序
-- DESC:降序 ASC:升序
-- 单列排序:只按某一个字段进行排序,单列排序。
SELECT * FROM student ORDER BY age DESC;
-- 组合排序:同时对多个字段进行排序,如果第 1 个字段相等,则按第 2 个字段排序,依次类推。
SELECT * FROM student ORDER BY age DESC, math ASC;
1.9.7 聚合函数
聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值 NULL。
| 聚合函数 | 作用 |
|---|---|
| MAX(列名) | 求这一列的最大值 |
| MIN(列名) | 求这一列的最小值 |
| AVG(列名) | 求这一列的平均值 |
| COUNT(列名) | 统计这一列有多少条记录 |
| SUM(列名) | 求这一列的总和 |
-- SELECT 聚合函数(列名) FROM 表名;
SELECT COUNT(id) AS 总人数 FROM student;
SELECT COUNT(*) AS 总人数 FROM student;
-- 可以利用 IFNULL()函数,如果记录为 NULL,给个默认值,这样统计的数据就不会遗漏
SELECT COUNT(IFNULL(id,0)) FROM student;
1.9.8 分组
分组查询是指使用 GROUP BY 语句对查询信息进行分组,相同数据作为一组。
格式:SELECT 字段 1, 字段 2... FROM 表名 GROUP BY 分组字段 [HAVING 条件];
下面根据SQL执行顺序来理解分组查询的流程:
-- 按性别进行分组,求男生和女生数学的平均分
SELECT sex, AVG(math) FROM student GROUP BY sex;
顺序是:FROM -> GROUP BY -> SELECT。首先FROM语句生成student虚拟表,然后GROUP BY以student虚拟表作为输入,生成两张sex唯一的虚拟表,然后SELECT以这两张虚拟表作为输入,生成sex和AVG(math)为字段的虚拟表并返回。
![[JavaWeb-02]MySQL_第8张图片](http://img.e-com-net.com/image/info8/364de09fa7b0479d8c1197042ea4dfbb.jpg)
1.9.9 限制
LIMIT 是限制的意思,所以 LIMIT 的作用就是限制查询记录的条数。
格式:LIMIT offset,length;
-- 查询学生表中数据,从第 3 条开始显示,显示 6 条。
SELECT * FROM student LIMIT 2,6;
1.10 数据库的备份和还原
1.10.1 备份
在DOS下,未登录的时候,执行语句:mysqldump -u 用户名 -p 密码 数据库 > 文件路径
-- 备份 day21 数据库中的数据到 d:\day21.sql 文件中
mysqldump -uroot -proot day21 > d:/day21.sql
1.10.2 还原
还原 day21 数据库中的数据,注意:还原的时候需要先登录 MySQL,并选中对应的数据库。
USE day21;
source d:/day21.sql;
2、MySQL约束
约束的作用:对表中的数据进行限制,保证数据的正确性、有效性和完整性。一个表如果添加了约束,不正确的数据将无法插入到表中。约束在创建表的时候添加比较合适。
| 约束名 | 约束关键字 |
|---|---|
| 主键 | PRIMARY KEY |
| 唯一 | UNIQUE |
| 非空 | NOT NULL |
| 外键 | FOREIGN KEY |
| 检查 | CHECK (MySQL不支持) |
2.1 主键约束
主键用来唯一标识数据库中的每一条记录。通常不用业务字段作为主键,单独给每张表设计一个 id 的字段,把 id 作为主键。主键是给数据库和程序使用的,不是给最终的客户使用的。所以主键有没有含义没有关系,只要不重复,非空就行。
主键的特点是:非空、唯一。
2.1.1 创建主键
-- 在创建表的时候给字段添加主键
-- 格式:字段名 字段类型 PRIMARY KEY
-- 创建表学生表 st5, 包含字段(id, name, age)将 id 做为主键
CREATE TABLE st5 (
id INT PRIMARY KEY, -- id 为主键
name VARCHAR(20),
age INT
)
DESC st5;

2.1.2 删除主键
-- 删除 st5 表的主键
ALTER TABLE st5 DROP PRIMARY KEY;
-- 在已有表中添加主键
-- ALTER TABLE 表名 ADD PRIMARY KEY(字段名);
ALTER TABLE st5 ADD PRIMARY KEY(id);
2.1.3 主键自增
主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段的值。格式:AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
/*
CREATE TABLE 表名(
列名 INT PRIMARY KEY AUTO_INCREMENT
) AUTO_INCREMENT= 起始值;
*/
-- 指定起始值为 1000
create table st4 (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
) AUTO_INCREMENT = 1000;
-- 如果想创建表后修改起始值
ALTER TABLE st4 AUTO_INCREMENT = 2000;
DELETE删除所有的记录之后,自增长没有影响。TRUNCATE删除以后,自增长又重新开始。
2.2 唯一约束
唯一约束表示数据表中某一列不能出现重复的值。
格式:字段名 字段类型 UNIQUE
-- 创建学生表 st7, 包含字段(id, name),name 这一列设置唯一约束,不能出现同名的学生
CREATE TABLE st7 (
id INT,
name VARCHAR(20) UNIQUE
)
2.3 非空约束
非空约束表示数据表的某一列不能为 null。
格式:字段名 字段类型 NOT NULL
-- 创建表学生表 st8, 包含字段(id,name,gender)其中 name 不能为 NULL
CREATE TABLE st8 (
id INT,
name VARCHAR(20) NOT NULL,
gender CHAR(1)
)
或者可以通过设置默认值来防止出现NULL:字段名 字段类型 DEFAULT
-- 创建一个学生表 st9,包含字段(id,name,address), 地址默认值是广州
CREATE TABLE st9 (
id INT,
name VARCHAR(20),
address VARCHAR(20) DEFAULT '广州'
)
如果一个字段设置了非空与唯一约束,该字段与主键的区别:主键数在一个表中,只能有一个。不能出现多个主键。主键可以单列,也可以是多列。自增长只能用在主键上。
2.4 外键约束
2.4.1 应用场景
外键约束用于多表中,解决数据冗余的问题。外键是在从表中与主表主键对应的那一列。主表是用来约束别人的表,从表是被别人约束的表。
对于下面的表,存在数据冗余,因为研发部和广州是一一对应,销售部和深圳也是一一对应,没必要每插入一条记录时,部门和地点都要重复写。
![[JavaWeb-02]MySQL_第9张图片](http://img.e-com-net.com/image/info8/ec9b8fecab044d4ba365382ae1c9939e.jpg)
解决方法是拆分成两个表,一个部门表作为主表,员工表作为从表。这样,每插入新的员工表记录时,只需要协商部门表的id即可。
![[JavaWeb-02]MySQL_第10张图片](http://img.e-com-net.com/image/info8/c9f01b6b2d554efaa90e1385ba7b3f8e.jpg)
拆分成两个表还要在程序上关联,即让部门表的主键id和员工表的dep_id关联上,否则增删改没有系统限制。
![[JavaWeb-02]MySQL_第11张图片](http://img.e-com-net.com/image/info8/6b4edf2c59214beebf8ab75fffabd522.jpg)
2.4.2 创建外键
-- 新建表时增加外键
-- 格式:[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
-- 创建从表 employee 并添加外键约束 emp_depid_fk
-- 多方,从表
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
age INT ,
dep_id INT , -- 外键对应主表的主键
CONSTRAINT emp_depid_fk FOREIGN KEY (dep_id) REFERENCES department(id) -- 创建外键约束
)
-- 已有表增加外键
-- 格式:ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主键字段名);
-- 在 employee 表情存在的情况下添加外键
ALTER TABLE employee ADD CONSTRAINT emp_depid_fk FOREIGN KEY (dep_id) REFERENCES department(id);
2.4.3 删除外键
-- ALTER TABLE 从表 DROP FOREIGN KEY 外键名称;
-- 删除 employee 表的 emp_depid_fk 外键
ALTER TABLE employee DROP FOREIGN KEY emp_depid_fk;
2.4.4 外键的级联
在修改和删除主表的主键时,同时更新或删除副表的外键值,称为级联操作。
| 级联语法 | 描述 |
|---|---|
| ON UPDATE CASCADE | 级联更新,创建表的时候创建级联。更新主表中的主键,从表中的外键列也自动同步更新 |
| ON DELETE CASCADE | 级联删除 |
-- 创建 employee 表,添加级联更新和级联删除
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
age INT,
dep_id INT, -- 外键对应主表的主键
-- 创建外键约束
CONSTRAINT emp_depid_fk
FOREIGN KEY (dep_id)
REFERENCES department(id)
ON UPDATE CASCADE
ON DELETE CASCADE
)
2.5 表与表之间的关系
| 关系 | 描述 |
|---|---|
| 一对一 | 如:姓名和身份证,使用相对较少 |
| 一对多 | 如:部门和员工,使用最广泛。使用外键建立关系 |
| 多对多 | 如:学生和课程,建立第三张表作为中间表,使用外键建立关系 |
2.6 数据库范式
| 范式 | 特点 |
|---|---|
| 第一范式 | 原子性,每一列都不可再拆分。 |
| 第二范式 | 不产生局部依赖,表中每一列都完全依赖于主键。 |
| 第三范式 | 不产生传递,表中每一列都直接依赖于主键。 |
3、MySQL多表&事务
3.1 表连接查询
多表查询用于对多个表的数据访问,因为查询结果在多张不同的表中,每张表取 1 列或多列。多表查询分为内连接和外连接。
![[JavaWeb-02]MySQL_第12张图片](http://img.e-com-net.com/image/info8/d5630a6234d5475a90bde24af2ad3fd9.jpg)
多表选择时会出现笛卡尔积现象,比如A表有3条记录,B表有5条记录,然后对AB表直接查询会出现3×5=15条的记录。
![[JavaWeb-02]MySQL_第13张图片](http://img.e-com-net.com/image/info8/e81d1b459dd740b29847bdfbf992f652.jpg)
一般我们进行多个表查询时,这些表直接往往是有关联的,比如上图的员工表的dept_id就是对应部门表的id,我们查询往往是要dept_id=id的结果。也就是说,当查询多个表时,是先生成了一个笛卡尔积表,然后我们从这个笛卡尔积表中进行过滤。
3.1.1 内连接
内连接就是用左边表的记录去匹配右边表的记录,如果符合条件则显示。内连接还分为隐式和显示。假设有两张表dept和emp:
![[JavaWeb-02]MySQL_第14张图片](http://img.e-com-net.com/image/info8/8810820d59954d3bbcc53c5e97eabe38.jpg)
执行FROM dept,emp时生成笛卡尔积表,如下:
![[JavaWeb-02]MySQL_第15张图片](http://img.e-com-net.com/image/info8/df0459e1614f4dd1b40dcb2286d1ff5e.jpg)
1.隐式内连接:看不到JOIN关键字,条件使用WHERE指定。
格式:SELECT 字段名 FROM 左表, 右表 WHERE 条件
执行语句:SELECT * FROM emp,dept WHERE emp.'dept_id' = dept.'id';输出如下:
![[JavaWeb-02]MySQL_第16张图片](http://img.e-com-net.com/image/info8/79ce2ff3ec5e4861aa78ef4170e39573.jpg)
分析:左表是emp,右表是dept,先生成量表的笛卡尔积表,然后选择符合emp.‘dept_id’ = dept.'id’条件的记录,显示符合条件是所有记录。
2.显示内连接:使用 INNER JOIN ... ON 语句, 可以省略 INNER
格式:SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件
例如,查询唐僧的信息,显示唐僧的id、姓名、性别、工资和所在部门名称。发现这些字段分属两个表,所以要进行多表查询。
执行语句:SELECT e.'id' 编号,e.'name' 姓名,e.'gender' 性别,e.'salary' 工资,d.'name' 部门名字 FROM emp e INNER JOIN dept d ON e.'dept_id' = d.'id' WHERE e.'name'='唐僧';输出如下:
![]()
总结使用内连接的查询步骤:
- 确定查询那些表;
- 确定表连接的条件;
- 确定查询的条件;
- 确定查询的字段。
3.1.2 外连接
(左右)外连接就是在内连接的基础上保证数据(左右)表的全部显示。
在部门表中增加一个销售部:INSERT INTO dept (name) VALUES ('销售部');
![[JavaWeb-02]MySQL_第17张图片](http://img.e-com-net.com/image/info8/5499925ac15140308258819f587c214b.jpg)
使用内连接:SELECT * FROM dept d INNER JOIN emp e on d.'id' = e.'dept_id';
使用左外连接:SELECT * FROM dept d LEFT JOIN emp e ON d.‘id’ = e.‘dept_id’;
![[JavaWeb-02]MySQL_第18张图片](http://img.e-com-net.com/image/info8/78a8f2e6aacc4393a5a1264944b2aa25.jpg)
在员工表中增加一个员工:INSERT INTO emp VALUES (null, '沙僧','男',6666,'2013-12-05',null);
![[JavaWeb-02]MySQL_第19张图片](http://img.e-com-net.com/image/info8/0af5838bc2ba4ae59822081d5ae91768.jpg)
使用内连接:SELECT * FROM dept INNER JOIN emp ON dept.‘id’ = emp.‘dept_id’;
使用右外连接:SELECT * FROM dept RIGHT JOIN emp ON dept.'id' = emp.'dept_id';
![[JavaWeb-02]MySQL_第20张图片](http://img.e-com-net.com/image/info8/5517b1318f064e39b75e240fe7d7019c.jpg)
3.2 子查询
子查询就是一个查询的结果做为另一个查询的条件,有查询的嵌套,内部的查询称为子查询。子查询要使用括号。子查询的结果分为三种情况:单行单列、多行单列、多行多列。
3.2.1 单行单列
子查询结果只要是单行单列,肯定在 WHERE 后面作为条件,父查询使用:比较运算符,如:> 、<、<>、=等。
-- 查询最高工资是多少
SELECT MAX(salary) FROM emp;
-- 根据最高工资到员工表查询到对应的员工信息
SELECT * FROM emp WHERE salary = (SELECT MAX(salary) FROM emp);
-- 查询平均工资是多少
SELECT AVG(salary) FROM emp;
-- 到员工表查询小于平均的员工信息
SELECT * FROM emp WHERE salary < (SELECT MAX(salary) FROM emp);
3.2.2 多行单列
子查询结果是单例多行,结果集类似于一个数组,父查询使用 IN 运算符。
-- 查询工资大于 5000 的员工,来自于哪些部门的名字
-- 先查询大于 5000 的员工所在的部门 id
SELECT dept_id FROM emp WHERE salary > 5000;
-- 再查询在这些部门 id 中部门的名字 Subquery returns more than 1 row
SELECT name FROM dept WHERE id = (SELECT dept_id FROM emp WHERE salary > 5000);
-- 使用 IN 运算符
SELECT name FROM dept WHERE id in (SELECT dept_id FROM emp WHERE salary > 5000);
-- 查询开发部与财务部所有的员工信息
-- 先查询开发部与财务部的 id
SELECT id FROM dept WHERE name in('开发部','财务部');
-- 再查询在这些部门 id 中有哪些员工
SELECT * FROM emp WHERE dept_id in (SELECT id FROM dept WHERE name in('开发部','财务部'));
3.2.3 多行多列
子查询结果只要是多列,肯定在 FROM 后面作为表。
-- 查询出 2011 年以后入职的员工信息,包括部门名称
-- 在员工表中查询 2011-1-1 以后入职的员工
SELECT * FROM emp WHERE join_date >='2011-1-1';
-- 查询所有的部门信息,与上面的虚拟表中的信息组合,找出所有部门 id 等于的 dept_id
SELECT * FROM dept d, (SELECT * FROM emp WHERE join_date >='2011-1-1') e WHERE d.`id`= e.dept_id;
也可以使用表连接:
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id` WHERE join_date >='2011-1-1';
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id` AND join_date >='2011-1-1';
3.3 事务
事务执行是一个整体,所有的 SQL 语句都必须执行成功。如果其中有 1 条 SQL 语句出现异常,则所有的SQL 语句都要回滚,整个业务执行失败。MySQL有两种方式进行事务操作:手动和自动。
| 功能 | SQL语句 |
|---|---|
| 开启事务 | START TRANSACTION; |
| 提交事务 | COMMIT; |
| 回滚事务 | ROLLBACK; |
3.3.1 手动提交事务
成功的情况:开启事务 -> 执行多条 SQL 语句 -> 成功提交事务;
失败的情况:开启事务 -> 执行多条 SQL 语句 -> 事务的回滚。
![[JavaWeb-02]MySQL_第21张图片](http://img.e-com-net.com/image/info8/4f97088c27324b059f0c970719e8be22.jpg)
案例演示1:模拟张三给李四转 500 元钱(成功) 目前数据库数据如下:
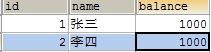
使用 DOS 控制台进入 MySQL,执行 SQL 语句:开启事务;张三账号-500;李四账号+500。使用 SQLYog 查看数据库:发现数据并没有改变。在控制台执行 commit 提交事务。使用 SQLYog 查看数据库:发现数据改变。
![[JavaWeb-02]MySQL_第22张图片](http://img.e-com-net.com/image/info8/9fa15d0890044fbf98868e376953ab24.jpg)
注意,上图查询表时显示执行成功了,但是这时候没有提交,所以使用SQLyog查看时数据没有改变。
案例演示2:模拟张三给李四转 500 元钱(失败) 目前数据库数据如下:

在控制台执行以下 SQL 语句:1.开启事务, 2.张三账号-500。使用 SQLYog 查看数据库:发现数据并没有改变。在控制台执行 rollback 回滚事务。使用 SQLYog 查看数据库:发现数据没有改变。
![[JavaWeb-02]MySQL_第23张图片](http://img.e-com-net.com/image/info8/e49799824afb41e9a7d9df611e402284.jpg)
总结: 如果事务中 SQL 语句没有问题,commit 提交事务,会对数据库数据的数据进行改变。 如果事务中 SQL语句有问题,rollback 回滚事务,会回退到开启事务时的状态。
3.3.2 自动提交事务
MySQL 默认每一条 DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,语句执行完毕自动提交事务,MySQL 默认开始自动提交事务。

可以通过取消自动提交事务,使得每一次执行SQL语句都要commit才能生效。
![[JavaWeb-02]MySQL_第24张图片](http://img.e-com-net.com/image/info8/cc99480d30234e3e97072c7eb2a47da3.jpg)
执行更新语句,使用 SQLYog 查看数据库,发现数据并没有改变,在控制台执行 commit 提交任务,数据更改才生效。
![[JavaWeb-02]MySQL_第25张图片](http://img.e-com-net.com/image/info8/f79a7f2315964bf3ab6c9485428de871.jpg)
3.3.3 事务原理
事务开启之后, 所有的操作都会临时保存到事务日志中, 事务日志只有在得到 commit 命令才会同步到数据表中,其他任何情况都会清空事务日志(rollback,断开连接)。
![[JavaWeb-02]MySQL_第26张图片](http://img.e-com-net.com/image/info8/96f743dbb1214bed8b8214fdcd3a3d09.jpg)
事务的步骤:1)客户端连接数据库服务器,创建连接时创建此用户临时日志文件;2)开启事务以后,所有的操作都会先写入到临时日志文件中;3)所有的查询操作从表中查询,但会经过日志文件加工后才返回;4)如果事务提交则将日志文件中的数据写到表中,否则清空日志文件。
3.3.4 事务回滚点
| 操作 | SQL语句 |
|---|---|
| 设置回滚点 | SAVEPOINT 名字 |
| 回到回滚点 | ROLLBACK TO 名字 |
设置回滚点可以让我们在失败的时候回到回滚点,而不是回到事务开启的时候。
3.3.5 事务的隔离级别
事务的四大特性ACID:
| 特性 | 描述 |
|---|---|
| 原子性(Atomicity) | 每个事务都是一个整体,不可再拆分,事务中的语句要么执行成功,要么都失败 |
| 一致性(Consistency) | 事务在执行前数据库的状态和执行后的状态保持一致。 |
| 隔离性(Isolation) | 事务与事务之间不应该相互影响,执行时保持隔离的状态。 |
| 持久性(Durability) | 一旦事务执行成功,对数据库的修改是持久的,就算关机也保存下来。 |
事务在操作时的理想状态: 所有的事务之间保持隔离,互不影响。因为并发操作,多个用户同时访问同一个数据。可能引发并发访问的问题:
| 问题 | 含义 |
|---|---|
| 脏读 | 一个事务读取到了另一个事务中尚未提交的数据。 |
| 不可重复读 | 一个事务中两次读取的数据内容不一致,这是事务update时引发的问题。 |
| 幻读 | 一个事务中两次读取的数据的数量不一致,这是INSERT或DELETE时引发的问题。 |
根据这三个问题,引出MySQL数据库的四种隔离级别:
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle和SQL Server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
隔离级别越高,性能越差,安全性越高。
| 功能 | SQL语句 |
|---|---|
| 查询隔离级别 | SELECT @@tx_isolation |
| 设置隔离级别 | SET GLOBAL TRANSACTION ISOLATION LEVEL 级别字符串 |