Windows下 配置Hadoop3.0.0
文章参考:符智生:10分钟搞定Windows环境下hadoop安装和配置
1.下载Hadoop
挂载VPN,登陆Apache公共软件档案馆
http://archive.apache.org/dist/
由于该页面仅提供当前最新的软件版本,所以若需要旧版本软件,需要点击右上

之后Hadoop/common就可找到Hadoop3.0.0
http://archive.apache.org/dist/hadoop/common/
下载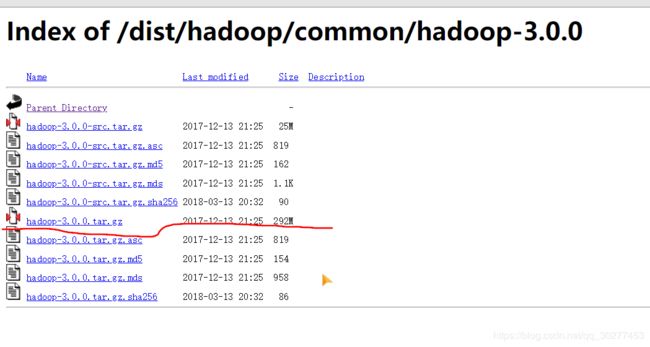
2.解压并配置
部分解压软件需要采用使用管理员运行的方式才可正常解压(Bandizip)
下载https://github.com/4ttty/winutils winutils包,使用对应版本的bin文件夹替换Hadoop文件夹内的bin文件夹
2.1 配置Hadoop环境变量
配置Java环境变量
新建变量名:JAVA_HOME
输入路径:D:\Softwares\jdk1.8.0_012 (这里是以我的jdk地址为例,请根据自己的jdk地址来设置)
在path中最前面加上:%JAVA_HOME%\bin;
配置Hadoop环境变量
新建变量名:HADOOP_HOME
输入路径:D:\hadoop
在path中最前面加上:%HADOOP_HOME%\bin;
2.2 在Hadoop中配置Java变量
在Hadoop文件夹下,\etc\hadoop找到hadoop-env.cmd
右键用一个文本编辑器打开
找到 set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8
将C:\PROGRA~1\Java\jdk1.7.0_67 改为 D:\Softwares\jdk1.8(在环境变量设置中JAVA_HOME的值)
(如果路径中有“Program Files”,则将Program Files改为 PROGRA~1
以上操作完成,在命令提示符界面输入 Hadoop version,就会显示Hadoop版本信息,否则重新配置
2.3 核心配置
在etc/hadoop/找到并复制粘贴以下内容,配置以下几个文件
core-site.xml
fs.defaultFS
hdfs://localhost:9000
mapred-site.xml
mapreduce.framework.name
yarn
hdfs-site.xml 请注意需要建立data 文件夹和两个子文件夹,本例子是建立在 HADOOP_HOME的目录里
dfs.replication
1
dfs.namenode.name.dir
/D:/hadoop/namenode 该部分根据自己的namenode文件夹位置配置
dfs.datanode.data.dir
/D:/hadoop/datanode 该部分根据自己的datanode文件夹位置配置
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
3.启动服务
创建三个文件夹
D:/hadoop/tmp
D:/hadoop/namenode
D:/hadoop/datanode
格式化 HDFS
以管理员身份打开命令提示符
输入hdfs namenode -format执行到如下图所示
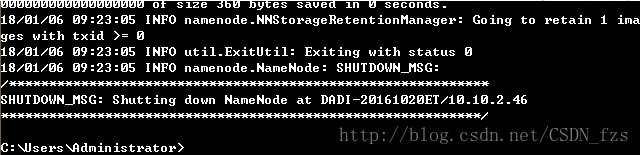
格式化之后,namenode文件里会自动生成一个current文件,则格式化成功。
然后转到Hadoop-2.7.3\sbin文件下
输入start-all.cmd,启动hadoop服务
本步一定要仔细,保证不报错才可正常
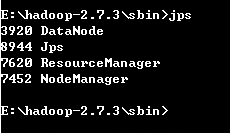
输入JPS – 可以查看运行的所有服务 (前提是java路径设置正确)