MYSQL实战四十五讲总结笔记_05、索引_下
前言:整理归纳,个人温习之用,请支持正版极客时间
1、问题引入
在下面这个表 T 中,如果我执行 select * from T where k between 3 and 5,需要执行几次树的搜索操作,会扫描多少行?
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
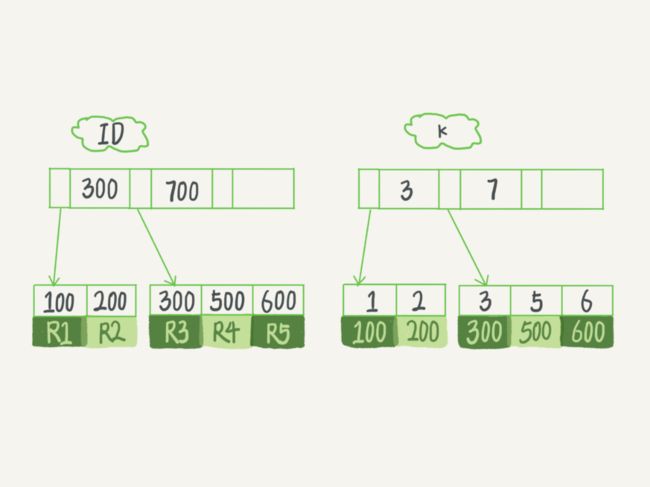
执行流程:
-
在 k 索引树上找到 k=3 的记录,取得 ID = 300;
-
再到 ID 索引树查到 ID=300 对应的 R3;
-
在 k 索引树取下一个值 k=5,取得 ID=500;
-
再回到 ID 索引树查到 ID=500 对应的 R4;
-
在 k 索引树取下一个值 k=6,不满足条件,循环结束。
这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)
2、覆盖索引
*如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引
*由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
*在引擎内部使用覆盖索引在索引 k 上其实读了三个记录,R3~R5(对应的索引 k 上的记录项),但是对于 MySQL 的 Server 层来说,它就是找引擎拿到了两条记录,因此 MySQL 认为扫描行数是 2。
*问题:在一个市民信息表上,是否有必要将身份证号和名字建立联合索引?
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB
如果现在有一个高频请求,要根据市民的身份证号查询他的姓名,这个联合索引就有意义了。它可以在这个高频请求上用到覆盖索引,不再需要回表查整行记录,减少语句的执行时间。
*最左前缀原则:B+ 树这种索引结构,可以利用索引的“最左前缀”,来定位记录。
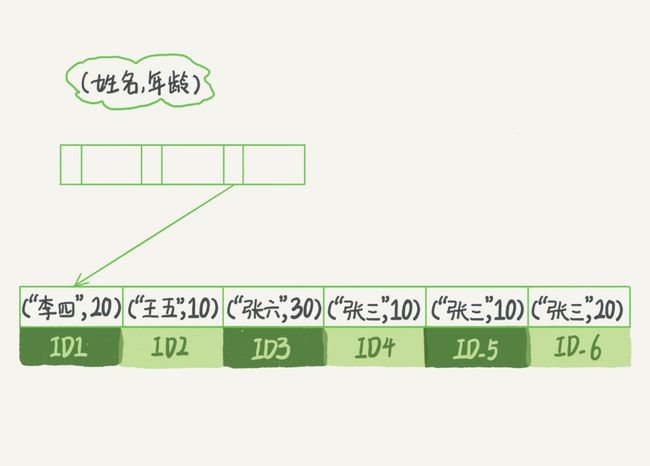
如果你要查的是所有名字第一个字是“张”的人,你的 SQL 语句的条件是"where name like ‘张 %’"。这时,你也能够用上这个索引,查找到第一个符合条件的记录是 ID3,然后向后遍历,直到不满足条件为止。
不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
*问题:在建立联合索引的时候,如何安排索引内的字段顺序?
因为支持最左前缀,所以当已经有了 (a,b) 这个联合索引后,一般就不需要单独在 a 上建立索引了。第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
*如果既有联合查询,又有基于 a、b 各自的查询呢?查询条件里面只有 b 的语句,是无法使用 (a,b) 这个联合索引的,这时候需要同时维护 (a,b)、(b) 这两个索引。第二原则是空间。比如上面这个市民表的情况,name 字段是比 age 字段大的 ,那我就建议你创建一个(name,age) 的联合索引和一个 (age) 的单字段索引。
3、索引下推
*以市民表的联合索引(name, age)为例:检索出表中“名字第一个字是张,而且年龄是 10 岁的所有男孩”
mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
根据前缀索引规则,这个语句在搜索索引树的时候,只能用 “张”,找到第一个满足条件的记录 ID3。然后判断其他条件是否满足。
在 MySQL 5.6 之前,只能从 ID3 开始一个个回表。到主键索引上找出数据行,再对比字段值。
而 MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。


左图 中,这个过程 InnoDB 并不会去看 age 的值,只是按顺序把“name 第一个字是’张’”的记录一条条取出来回表。需要回表 4 次。
右图中,InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等于 10 的记录,直接判断并跳过。只需要回表 2 次。
4、总结
*问题:主键索引也是可以使用多个字段的。有这么一个表,表结构定义类似这样的:
CREATE TABLE `geek` (
`a` int(11) NOT NULL,
`b` int(11) NOT NULL,
`c` int(11) NOT NULL,
`d` int(11) NOT NULL,
PRIMARY KEY (`a`,`b`),
KEY `c` (`c`),
KEY `ca` (`c`,`a`),
KEY `cb` (`c`,`b`)
) ENGINE=InnoDB;
由于历史原因,这个表需要 a、b 做联合主键;既然主键包含了 a、b 这两个字段,那意味着单独在字段 c 上创建一个索引,就已经包含了三个字段了呀,为什么要创建“ca”“cb”这两个索引?因为他们的业务里面有这样的两种语句?对不对?
select * from geek where c=N order by a limit 1;
select * from geek where c=N order by b limit 1;
答:表记录

主键 a,b 的聚簇索引组织顺序相当于 order by a,b ,也就是先按 a 排序,再按 b 排序,c 无序。
索引 ca 的组织是先按 c 排序,再按 a 排序,同时记录主键,这个跟索引 c 的数据是一模一样的。

索引 cb 的组织是先按 c 排序,在按 b 排序,同时记录主键。所以,结论是 ca 可以去掉,cb 需要保留。

*建立的每个索引都要维护一个数据段,新插入一行值,每个索引段都会维护这行值。索引越多,“维护成本”越大
*树高其实取决于叶子树(数据行数)和“N叉树”的N。 而N是由页大小和索引大小决定的。
*查询数据的时候,执行器调用引擎到表里的数据段/索引段取数据 ,数据是按照段->区->页维度去取,取完后先放到数据缓冲池中,再通过二分法查询叶结点的有序链表数组找到行数据返回给用户 。 当数据量大的时候,会存在不同的区,取范围值的时候会到不同的区取页的数据返回用户。