重学计算机组成原理(五)- "旋转跳跃"的指令实现
CPU执行的也不只是一条指令,一般一个程序包含很多条指令
因为有if…else、for这样的条件和循环存在,这些指令也不会一路平直执行下去。
一个计算机程序是怎么被分解成一条条指令来执行的呢
1 CPU如何执行指令
CPU里差不多几百亿个晶体管
实际上,一条条计算机指令执行起来非常复杂
好在CPU在软件层面已经为我们做好了封装
对于程序员来说,我们只要知道,写好的代码变成了指令之后,是一条一条顺序执行
不管几百亿的晶体管的背后是怎么通过电路运转起来的
逻辑上,我们可以认为,CPU其实就是由一堆寄存器组成的
而寄存器就是CPU内部,由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单电路。
触发器和锁存器,其实就是两种不同原理的数字电路组成的逻辑门
如果想要深入学习的话,可以学习数字电路的相关课程
N个触发器或者锁存器,就可以组成一个N位(Bit)的寄存器,能够保存N位的数据
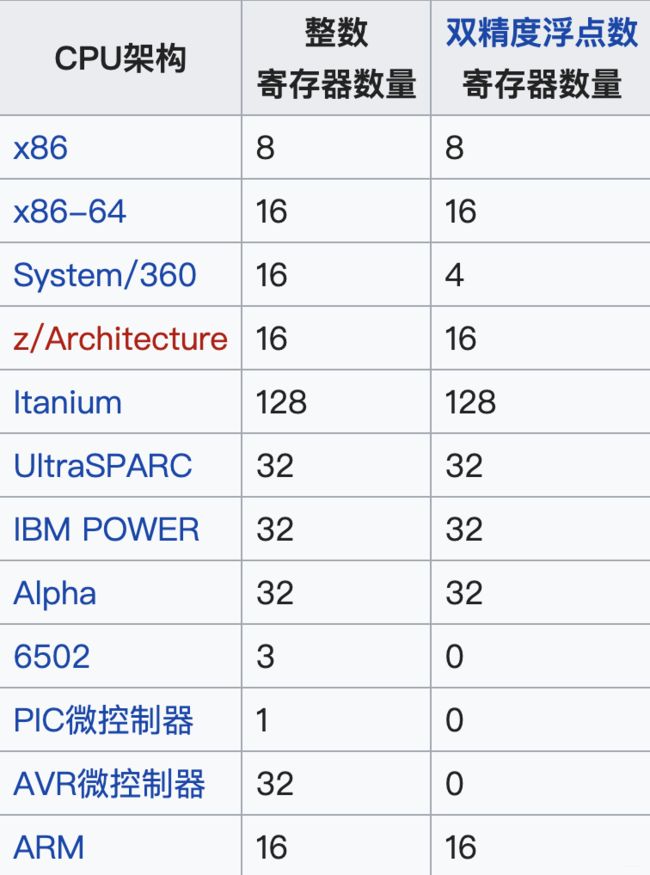
比方说,我们用的64位Intel服务器,寄存器就是64位的
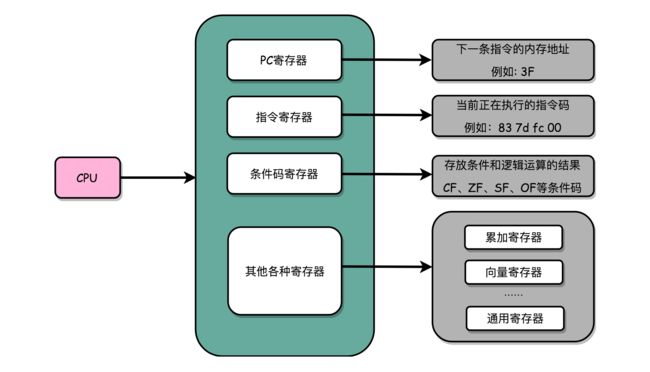
CPU里有很多种不同功能的
1.1 寄存器
寄存器(Register),是中央处理器内的其中组成部分。寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和地址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器。在中央处理器的算术及逻辑部件中,包含的寄存器有累加器。
在计算机体系结构里,处理器中的寄存器是少量且速度快的计算机存储器,借由提供快速共同地访问数值来加速计算机程序的运行:典型地说就是在已知时间点所作的之计算中间的数值。
寄存器是存储器层次结构中的最顶端,也是系统操作数据的最快速途径。寄存器通常都是以他们可以保存的比特数量来估量,举例来说,一个8位寄存器或32位寄存器。寄存器现在都以寄存器数组的方式来实现,但是他们也可能使用单独的触发器、高速的核心存储器、薄膜存储器以及在数种机器上的其他方式来实现出来。
这个名词通常都用来意指由一个指令之输出或输入可以直接索引到的寄存器组群。更适当的是称他们为“架构寄存器”。例如,x86指令集定义八个32位寄存器的集合,但一个实现x86指令集的CPU可以包含比八个更多的寄存器。
1.1.1 PC寄存器(Program Counter Register)
亦称指令地址寄存器(Instruction Address Register)
存放下一条需要执行的计算机指令的内存地址
1.1.2 指令寄存器(Instruction Register)
存放当前正在执行的指令
1.1.3 条件码寄存器(Status Register)
用里面的一个一个标记位(Flag),存放CPU进行算术或者逻辑计算的结果
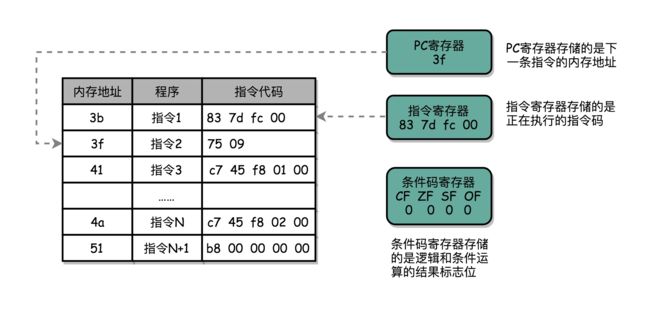
CPU里面还有更多用来存储数据和内存地址的寄存器
这样的寄存器通常一类里面不止一个
通常根据存放的数据内容来给它们取名字,比如
- 常量寄存器
用来持有只读的数值(例如0、1、圆周率等等)。由于“其中的值不可更改”这一特殊性质,这些寄存器未必会有实体的硬件电路相对应,例如将从零常数寄存器读的操作实现为接通目标寄存器的下拉电阻。
一般而言,即使真正在硬件中放置常数寄存器也未必会是出于体系结构理论上的考虑,而很可能是由硬件描述语言为了简化操作而自动生成的电路 - 整数寄存器
用来存储整数数字(参考以下的浮点寄存器)。在某些简单(或旧)的CPU,特别的数据寄存器是累加器,作为数学计算之用。 - 浮点数寄存器(FPRs)
用来存储浮点数字。 - 向量寄存器
用来存储由向量处理器运行SIMD指令所得到的数据。 - 地址寄存器
持有存储器地址,以及用来访问存储器。在某些简单/旧的CPU里,特别的地址寄存器是索引寄存器(可能出现一个或多个)。
有些寄存器既可以存放数据,又能存放地址,我们就叫它通用寄存器(GPRs)。
程序执行的时候,CPU会
- 根据PC寄存器里的地址
- 从内存里面把需要执行的指令读取到指令寄存器里面执行
- 然后根据指令长度自增
- 开始顺序读取下一条指令
可以看到,一个程序的一条条指令,在内存里是连续保存的,也会一条条顺序加载
而有些特殊指令,比如上一讲我们讲到J类指令,也就是跳转指令,会修改PC寄存器里面的地址值
这样,下一条要执行的指令就不是从内存里面顺序加载的了
事实上,这些跳转指令的存在,也是我们可以在写程序的时候,使用
- if…else条件语句
- while/for循环语句
的原因
2 从if/else看程序的执行和跳转
我们现在就来看一个包含if…else的简单程序。
- test.c
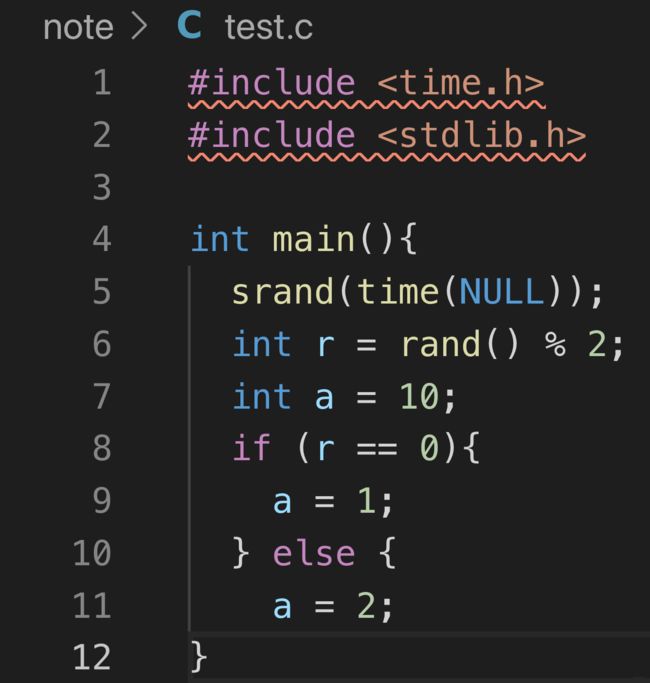
用rand生成了一个随机数r(0/1)
- 当r是0,我们把之前定义的变量a设成1
- 不然就设成2
我们把这个程序编译成汇编代码。你可以忽略前后无关的代码,只关注于这里的if…else条件判断语句
- 对应的汇编代码是这样的
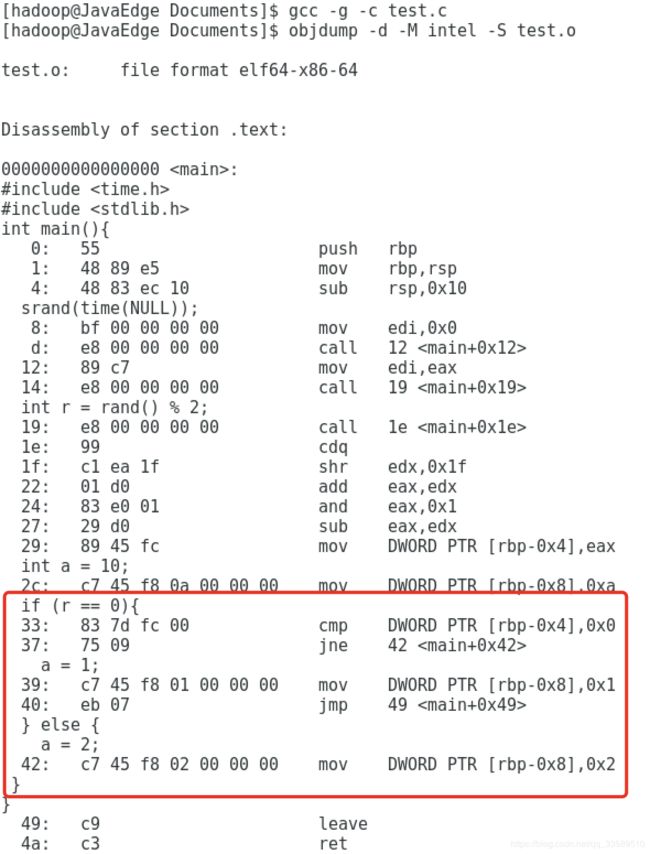
对于r == 0的条件判断,被编译成了cmp和jne两条指令。
- cmp指令比较了前后两个操作数的值
DWORD PTR 代表操作的数据类型是32位的整数
[rbp-0x4]则是一个寄存器的地址
第一个操作数就是从寄存器里拿到的变量r的值
第二个操作数0x0就是我们设定的常量0的16进制表示
cmp指令的比较结果,会存入到条件码寄存器
状态寄存器又名条件码寄存器,它是计算机系统的核心部件——运算器的一部分
状态寄存器用来存放两类信息:
一类是体现当前指令执行结果的各种状态信息(条件码),如有无进位(CF位)、有无溢出(OF位)、结果正负(SF位)、结果是否为零(ZF位)、奇偶标志位(P位)等
另一类是存放控制信息(PSW:程序状态字寄存器),如允许中断(IF位)、跟踪标志(TF位)等
有些机器中将PSW称为标志寄存器FR(Flag Register)。
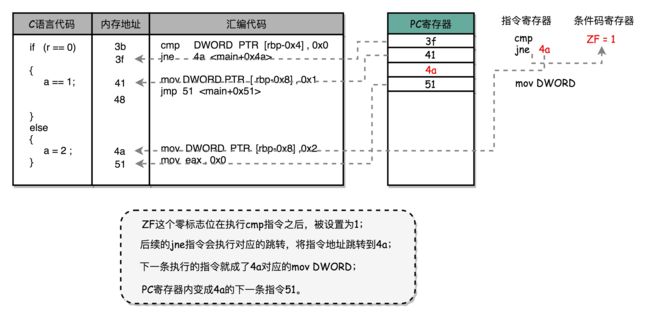
如果比较结果 True,即 r == 0,就把零标志条件码(对应的条件码是ZF,Zero Flag)设置为1
条件码是CPU根据运算结果由硬件设置的位,体现当前指令执行结果的各种状态信息
例如:算术运算产生的正、负、零或溢出等的结果。条件码可被测试,作为分支运算的依据,此外,有些条件码可被设置,例如对于最高位进位标志C,可用指令对它置位和复位。
Intel的CPU下还有
- 进位标志(CF,Carry Flag)
最近的操作使最高位产生了进位。可以用来检查无符号操作数据的溢出。 - 符号标志(SF,Sign Flag)
最近的操作得到的结果为负数。 - 溢出标志(OF,Overflow Flag)
最近的操作导致一个补码溢出–正溢出或负溢出
用在不同的判断条件下。
cmp指令执行完成之后,PC寄存器会自增,开始执行下一条jne的指令
跟着的jne指令(jump if not equal),它会查看对应的零标志位
如果为0,会跳转到后面跟着的操作数4a的位置
4a,对应汇编代码的行号,也就是else条件里的第一条指令
当跳转发生,PC寄存器不再是自增变成下一条指令的地址,而被直接设置4a这个地址
这个时候,CPU再把4a地址里的指令加载到指令寄存器执行。
跳转到执行地址为4a的指令,实际是一条mov指令
第一个操作数和前面的cmp指令一样,是另一个32位整型的寄存器地址,以及对应的2的16进制值0x2
mov指令把2设置到对应的寄存器里去,相当于一个赋值操作
然后,PC寄存器里的值继续自增,执行下一条mov指令。
这条mov指令的第一个操作数eax,代表累加寄存器
在中央处理器中,累加器 (accumulator) 是一种寄存器,用来储存计算产生的中间结果。如果没有像累加器这样的寄存器,那么在每次计算 (加法,乘法,移位等等) 后就必须要把结果写回到 内存,也许马上就得读回来。然而存取主存的速度是比从算术逻辑单元到有直接路径的累加器存取更慢。
第二个操作数0x0则是16进制的0的表示。这条指令其实没有实际的作用,它的作用是一个占位符
if条件如果满足,在赋值的mov指令执行完成之后,有一个jmp的无条件跳转指令
跳转的地址就是这一行的地址51
我们的main函数没有设定返回值,而mov eax, 0x0 其实就是给main函数生成了一个默认的为0的返回值到累加器里面
if条件里面的内容执行完成之后也会跳转到这里,和else里的内容结束之后的位置是一样的。
上一讲我们讲打孔卡的时候说到,读取打孔卡的机器会顺序地一段一段地读取指令,然后执行。
执行完一条指令,它会自动地顺序读取下一条指令
如果执行的当前指令带有跳转的地址,比如往后跳10个指令,那么机器会自动将卡片带往后移动10个指令的位置,再来执行指令
同样的,机器也能向前移动,去读取之前已经执行过的指令
这也就是我们的while/for循环实现的原理。
如何通过if…else和goto来实现循环?

我们再看一段简单的利用for循环的程序。我们循环自增变量i三次,三次之后,i>=3,就会跳出循环。整个程序,对应的Intel汇编代码就是这样的:
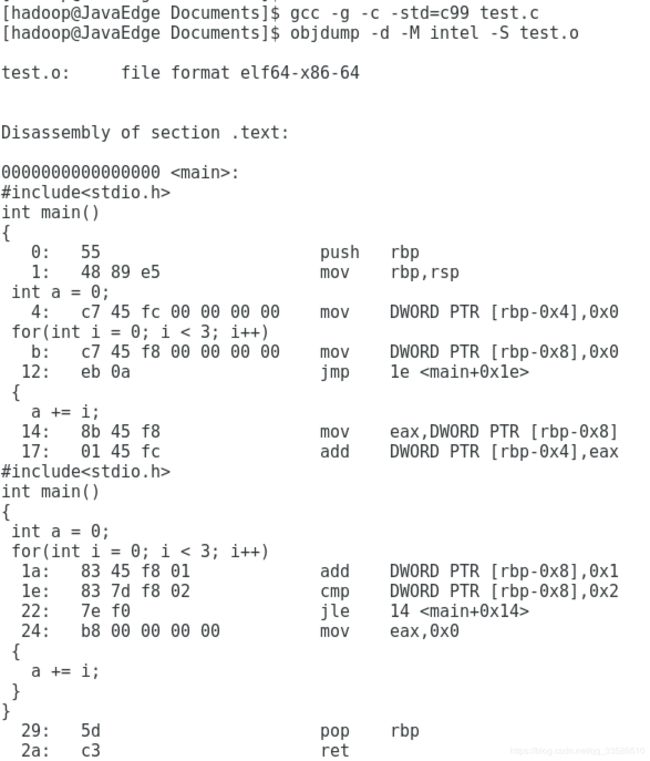
可以看到,对应的循环也是用1e这个地址上的cmp比较指令
和紧接着的jle条件跳转指令来实现的
主要的差别在于,这里的jle跳转的地址,在这条指令之前的地址14,而非if…else编译出来的跳转指令之后
往前跳转使得条件满足的时候,PC寄存器会把指令地址设置到之前执行过的指令位置,重新执行之前执行过的指令,直到条件不满足,顺序往下执行jle之后的指令,整个循环才结束。

如果你看一长条打孔卡的话,就会看到卡片往后移动一段,执行了之后,又反向移动,去重新执行前面的指令。
jle和jmp指令,有点像程序语言里面的goto命令,直接指定了一个特定条件下的跳转位置
虽然我们在用高级语言开发程序的时候反对使用goto,但是实际在机器指令层面,无论是if…else…也好,还是for/while也好,都是用和goto相同的跳转到特定指令位置的方式来实现的。
3 总结
学习了程序里的多条指令,究竟是怎么样一条一条被执行的
除了简单地通过PC寄存器自增的方式顺序执行外
条件码寄存器会记录下当前执行指令的条件判断状态
然后通过跳转指令读取对应的条件码
修改PC寄存器内的下一条指令的地址
最终实现if…else以及for/while这样的程序控制流程。
虽然我们可以用高级语言,可以用不同的语法,比如 if…else 这样的条件分支,或者 while/for 这样的循环方式,来实现不用的程序运行流程
但是回归到计算机可以识别的机器指令级别,其实都只是一个简单的地址跳转而已,也就是一个类似于goto的语句。
想要在硬件层面实现这个goto语句,除了本身需要用来保存下一条指令地址,以及当前正要执行指令的PC寄存器、指令寄存器外
我们只需要再增加一个条件码寄存器,来保留条件判断的状态。这样简简单单的三个寄存器,就可以实现条件判断和循环重复执行代码的功能。
4 推荐阅读
- 《深入理解计算机系统》的第3章
详细讲解了C语言和Intel CPU的汇编语言以及指令的对应关系,以及Intel CPU的各种寄存器和指令集。
Intel指令集相对于之前的MIPS指令集要复杂一些
- 所有的指令是变长的
从1个字节到15个字节不等 - 即使是汇编代码,还有很多针对操作数据的长度不同有不同的后缀
参考
- 状态寄存器
- 寄存器
- 条件码
- 累加器
- 深入浅出计算机组成原理