大数据开发笔记
大数据开发笔记
- 0 Brief
- 1 Java
- 2 SQL
- 3 大数据组件底层原理
- EMR - 阿里云大数据平台/工业场景下的大数据工具
- HDFS - 分布式文件系统
- MapReduce - 分布式数据处理引擎
- HBase - 分布式数据库/NoSQL数据库
- Hive - 数据仓库软件/NOSQL数据库
- Kudu - 大数据存储引擎(列数据储存结构)
- KUDU常用指令
- 常见错误
- Flume - 数据采集
- Kafka - 消息系统
- Spark - 大数据计算引擎
- Flink - 大数据计算引擎
- Livy - 基于Apache Spark的REST服务
- Impala - SQL查询引擎
- 常用命令
- Parquet
- Phoenix - HBase sql引擎
- Sqoop
- Canal
- Knox
- Flume、ElasticSearch、Kibana
- Yarn、Pig、Storm、Zookeeper
- 数仓设计思想/原则
- Other
- SCALA笔记
0 Brief
- 整体流程
定义Event时间模型作为数据结构 -> 采集、清洗、存储至分布式文件集群 -> 分布式计算供给各个业务线运营
- 数据结构
灵机数据模型:“事件模型(Event 模型)”,用来描述用户在产品上的各种行为,这也是灵机数据中心所有的接口和功能设计的核心依据。
PV 模型无法满足一些更加细节的、更加精细化的分析。例如,我们想分析哪类产品销量最好,访问网站的用户的年龄和性别构成,每个渠道过来的用户的转化率、留存和重复购买率分别如何,新老用户的客单价、流水、补贴比例分别是多少等等。这些问题,都是以 PV 为核心的传统统计分析没办法解答的问题。
因此,灵机数据中心采用事件模型作为基本的数据模型。事件模型可以给我们更多的信息,让我们知道用户用我们的产品具体做了什么事情。事件模型给予我们更全面且更具体的视野,指导我们做出更好的决策。
(所谓的精细化运营就是将各个信息都保存起来,然后从不同维度去做统计,根据统计指标(量化结果)得出事件结论?)
Event 的五要素
一个 Event 就是描述了:一个用户在某个时间点、某个地方,以某种方式完成了某个具体的事情。一个完整的 Event,包含如下的几个关键因素:Who、When、Where、How、What。
- 数据开发:(单条业务线) 埋点 + 上传存储 + ETL清洗 + 运营指标计算 + 接口开发; 实时?离线
Hadoop业务的整体开发流程:

Hadoop
Hadoop的核心为HDFS与MapReduce,HDFS分布式文件系统在Hadop中是用来存储数据的;MapReduce为Hadoop处理数据的核心
Hadoop是一个开源框架来存储和处理大型数据在分布式环境中。它包含两个模块,一个是MapReduce,另外一个是Hadoop分布式文件系统(HDFS)。
- MapReduce:它是一种并行编程模型在大型集群普通硬件可用于处理大型结构化,半结构化和非结构化数据。
- HDFS:Hadoop分布式文件系统是Hadoop的框架的一部分,用于存储和处理数据集。它提供了一个容错文件系统在普通硬件上运行。
Hadoop生态系统包含了用于协助Hadoop的不同的子项目(工具)模块,如Sqoop, Pig 和 Hive。
- Sqoop: 它是用来在HDFS和RDBMS之间来回导入和导出数据。
- Pig: 它是用于开发MapReduce操作的脚本程序语言的平台。
- Hive: 它是用来开发SQL类型脚本用于做MapReduce操作的平台。
注:有多种方法来执行MapReduce作业:
- 传统的方法是使用Java MapReduce程序结构化,半结构化和非结构化数据。
- 针对MapReduce的脚本的方式,使用Pig来处理结构化和半结构化数据。
- Hive查询语言(HiveQL或HQL)采用Hive为MapReduce的处理结构化数据。
摘自Spark入门基础教程
目前按照大数据处理类型来分大致可以分为:批量数据处理、交互式数据查询、实时数据流处理,这三种数据处理方式对应的业务场景也都不一样;
关注大数据处理的应该都知道Hadoop,而Hadoop的核心为HDFS与MapReduce,HDFS分布式文件系统在Hadop中是用来存储数据的;MapReduce为Hadoop处理数据的核心,接触过函数式编程的都知道函数式语言中也存在着Map、Reduce函数其实这两者的思想是一致的;也正是因为Hadoop数据处理核心为MapReduce奠定了它注定不是适用场景广泛的大数据框架;
可以这么说Hadoop适用于Map、Reduce存在的任何场景,具体场景比如:WordCount、排序、PageRank、用户行为分析、数据统计等,而这些场景都算是批量数据处理,而Hadoop并不适用于交互式数据查询、实时数据流处理;
这时候就出现了各种数据处理模型下的专用框架如:Storm、Impala、GraphLab等;
1、Storm:针对实时数据流处理的分布式框架;
2、Impala:适用于交互式大数据查询的分布式框架;
3、GraphLab:基于图模型的机器学习框架;
1、MapReduce简单模型
这时候如果一个团队或一个公司中同时都有设计到大数据批量处理、交互式查询、实时数据流处理这三个场景;这时候就会有一些问题:
1、学习成本很高,每个框架都是不同的实现语言、不同的团队开发的;
2、各个场景组合起来代价必然会很大;
3、各个框架中共享的中间数据共享与移动成本高;
就在这时候UC Berkeley AMP推出了全新的大数据处理框架:Spark提供了全面、统一适用与不同场景的大数据处理需求(批量数据处理、交互式数据查询、实时数据流处理、机器学习);Spark不仅性能远胜于Hadoop而却还兼容Hadoop生态系统,Spark可以运行在Hadoop HDFS之上提供争强 功能,可以说Spark替代了Hadoop MapReduce,但Spark依然兼容Hadoop中的YARN与Apache Mesos组件,现有Hadoop用户可以很容易就迁移到Spark;
Spark中最核心的概念为RDD(Resilient Distributed DataSets)中文为:弹性分布式数据集,RDD为对分布式内存对象的 抽象它表示一个被分区不可变且能并行操作的数据集;RDD为可序列化的、可缓存到内存对RDD进行操作过后还可以存到内存中,下次操作直接把内存中RDD作为输入,避免了Hadoop MapReduce的大IO操作;

1 Java
常用语法
WEB开发:springboot
.java文件编译过程和执行过程分析以及计算机简单认识:系统的讲解了计算机的组成和java文件编译,jvm解释的过程
2 SQL
常用SQL语法
增删改查、内连外连等
3 大数据组件底层原理
了解基本原理和使用方法即可
EMR - 阿里云大数据平台/工业场景下的大数据工具
E-MapReduce介绍
E-MapReduce的用途

通过E-MapReduce,您可以从繁琐的集群构建相关的采购、准备和运维等工作中解放出来,只关心自己应用程序的处理逻辑(8-10步骤)即可。
E-MapReduce还提供了灵活的搭配组合方式,您可以根据自己的业务特点选择不同的集群服务。例如,如果您的需求是对数据进行日常统计和简单的批量运算,则可以只选择在E-MapReduce中运行Hadoop服务;如果您有流式计算和实时计算的需求,则可以在Hadoop服务基础上再加入Spark服务。
E-MapReduce的组成
E-MapReduce最核心也是用户直接面对的组件是集群。E-MapReduce集群是由一个或多个阿里云ECS实例组成的Hadoop和Spark集群。以 Hadoop为例,每个ECS Instance上通常都运行了一些daemon进程(例如,NameNode、DataNode、ResouceManager 和 NodeManager),这些 daemon 进程共同组成了Hadoop集群。其中运行NameNode和ResourceManager的节点称为Master节点,而运行DataNode和NodeManager的节点称为Slave节点。
包含一个Master节点和三个Slave节点的E-MapReduce集群

E-MapReduce集群是基于Hadoop的生态环境搭建的,可以与阿里云的对象存储服务(OSS)进行无缝数据交换。此外,E-MapReduce集群也可以与云数据库(RDS)等云服务无缝对接,方便您将数据在多个系统之间进行共享和传输,以满足不同业务类型的访问需要。
- Hadoop集群
- Kafka集群
- Zookeeper集群
- Druid集群
HDFS - 分布式文件系统
与普通文件系统(Win、Linux、Mac)的不同就是,hdfs是分布式文件系统。
good - HBase和HDFS的关系
hdfs简单操作
MapReduce - 分布式数据处理引擎
https://yq.aliyun.com/articles/340381
MapReduce是Google开发的C++编程工具,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(化简)”,和他们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
Map(映射)/Reduce(简化)
https://www.liaoxuefeng.com/wiki/897692888725344/989703124920288
| 操作名称 | 目的 | 输入:输出 | 并行 |
|---|---|---|---|
| Map | 映射 | 1:1 | 可以高度并行 |
| Reduce | 定义一个化简函数,通过让列表中的元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素 | 2:1 | 依旧可以并行,虽不如Map函数那么并行 |
分布和可靠性
MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个节点会周期性的把完成的工作和状态的更新报告回来。如果一个节点保持沉默超过一个预设的时间间隔,主节点(类同Google File System中的主服务器)记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。每个操作使用命名文件的原子操作以确保不会发生并行线程间的冲突;当文件被改名的时候,系统可能会把他们复制到任务名以外的另一个名字上去。(避免副作用)。
化简操作工作方式很类似,但是由于化简操作在并行能力较差,主节点会尽量把化简操作调度在一个节点上,或者离需要操作的数据尽可能进的节点上了;这个特性可以满足Google的需求,因为他们有足够的带宽,他们的内部网络没有那么多的机器。
用途
在Google,MapReduce用在非常广泛的应用程序中,包括“分布grep,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类,机器学习,基于统计的机器翻译…”值得注意的是,MapReduce实现以后,它被用来重新生成Google的整个索引,并取代老的ad hoc程序去更新索引。
MapReduce会生成大量的临时文件,为了提高效率,它利用Google文件系统来管理和访问这些文件。
HBase - 分布式数据库/NoSQL数据库
HBase - 分布式数据库/NoSQL数据库
Hive - 数据仓库软件/NOSQL数据库
Hive - 数据仓库软件/NOSQL数据库
Kudu - 大数据存储引擎(列数据储存结构)
Apache Kudu是一个为了Hadoop系统环境而打造的列存储管理器.
KUDU 的定位是 「Fast Analytics on Fast Data」,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
在Kudu出现之前,Hadoop生态环境中的储存主要依赖HDFS和HBase,追求高吞吐批处理的用例中使用HDFS,追求低延时随机读取用例下用HBase,而Kudu正好能兼顾这两者。
数据高效处理的秘诀——Kudu实战
Kudu异常总结
Kudu的主要优点:
- 快速处理OLAP(Online Analytical Processing)任务
- 集成MapReduce、Spark和其他Hadoop环境组件
- 与Impala高度集成,使得这成为一种高效访问交互HDFS的方法
- 强大而灵活的统一性模型
- 在执行同时连续随机访问时表现优异
- 通过Cloudera Manager可以轻松管理控制
- 高可用性,tablet server和master利用Raft Consensus算法保证节点的可用
- 结构数据模型
kudu使用时的优势:
1)一个table由多个tablet组成,对分区查看、扩容和数据高可用支持非常好
2)支持update和upsert操作。
3)与imapla集成或spark集成后(dataframe)可通过标准的sql操作,使用起来很方便
4)可与spark系统集成
kudu使用时的劣势:
1)只有主键可以设置range分区,且只能由一个主键,也就是一个表只能有一个字段range分区,且该字段必须是主键。
2)如果是pyspark连接kudu,则不能对kudu进行额外的操作;而scala的spark可以调用kudu本身的库,支持kudu的各种语法。
3)kudu的shell客户端不提供表schema查看。如果你不通过imapla连接kudu,且想要查看表的元数据信息,需要用spark加载数据为dataframe,通过查看dataframe的schema查看表的元数据信息。
4)kudu的shell客户端不提供表内容查看。如果你想要表的据信息,要么自己写脚本,要么通过spark、imapla查看。
5)如果使用range 分区需要手动添加分区。假设id为分区字段,需要手动设置第一个分区为1-30.第二个分区为30-60等等
6)时间格式是utc类型,需要将时间戳转化为utc类型,注意8个小时时差
常见的应用场景:
- 刚刚到达的数据就马上要被终端用户使用访问到
- 同时支持在大量历史数据中做访问查询和某些特定实体中需要非常快响应的颗粒查询
- 基于历史数据使用预测模型来做实时的决定和刷新
- 要求几乎实时的流输入处理
kudu的产生背景和应用场景
1.在 kudu 之前,大数据主要以两种方式存储:
第一种是静态数据:以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。
这类存储的局限性是数据无法进行随机的读写和批量的更新操作。
第二种是动态数据:以 HBase作为存储引擎,适用于大数据随机读写场景。这类存储的局限性是批量读取吞吐量远不如 HDFS、不适用于批量数据分析的场景。
2.从上面分析可知,这两种数据在存储方式上完全不同,进而导致使用场景完全不同,但在真实的场景中,边界可能没有那么清晰,面对既需要随机读写,又需要批量分析的大数据场景,该如何选择呢?
3.这个场景中,单种存储引擎无法满足业务需求,我们需要通过多种大数据组件组合来满足这一需求,一个常见的方案是:
数据实时写入 HBase,实时的数据更新也在 HBase 完成,为了应对 OLAP 需求,我们定时(通常是 T+1 或者 T+H)将 HBase的 数据写成静态的文件(Parquet)
导入到 OLAP 引擎(HDFS)。这一架构能满足既需要随机读写,又可以支持 OLAP 分析的场景。
但他有如下缺点:
第一:架构复杂。从架构上看,数据在 HBase、消息队列Kafka、HDFS 间流转,涉及环节太多,运维成本很高。
并且每个环节需要保证高可用、维护多个副本、存储空间浪费。最后数据在多个系统上,对数据安全策略、监控等都提出了挑战。
第二:时效性低。数据从 HBase 导出成静态文件是周期性的,一般这个周期是一天(或一小时),在时效性上不是很高。
第三:难以应对后续的更新。真实场景中,总会有数据是延迟到达的。如果这些数据之前已经从 HBase 导出到 HDFS,
新到的变更数据就难以处理了,一个方案是把新变更的数据和原有数据进行对比,把不同的数据重新进行更新操作,这时候代价就很大了。
假如说,我们想要sql实时对大量数据进行分析该怎么办?或者是我想让数据存储能够支持Upsert(更新插入操作),又该怎么办?所以这就是kudu的优势。
KUDU 的定位是 Fast Analytics on Fast Data,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
4.KUDU在 HDFS 和 HBase 这两个中平衡了随机读写和批量分析的性能,既支持了SQL实时查询,也支持了数据更新插入操作。
完美的和impala集成,统一了hdfs数据源和kudu数据源,从而使得开发人员能够高效的进行数据分析。
KUDU常用指令
KUDU&Impala基本操作
kudu表分区
所谓列存储、行存储数据模式,在底层的存储、DDL等操作上各有不同,不过API级别都提供差不多的功能:增删改查,不同数据库对不同操作的性能各有不同而已
**impala kudu 操作sql语句:**
// 所有数据库
show databases;
// 表结构描述
DESCRIBE kudu_test_table;
// 查询
SELECT current_database();
select * from kudu_test_table limit 10;
// 插入(xu指定主键)
insert into kudu_test_table values ("[email protected]","123456","no","65246241","1000");
insert into kudu_test_table () values ("[email protected]","123456","no","65246241","1000");
// 更新(需指定主键)
UPDATE kudu_test_table set linghit_id = "654321" where $mail= "[email protected]";
UPDATE kudu_test_table set linghit_id = "7654321" where linghit_id= "654321";
// 删除行(需指定主键)
delete from linghit_bigdata_userinfo where user_center_id="[email protected]" and log_time=1584633600 and product_id="5648";
// 追加列,新增字段/列名
alter table kudu_test_table add columns(salary string,time_stamp string);
// 删除
DROP TABLE kudu_test_table;
// 新增分区
与mysql类似的,kudu中range分区的表也是支持增加分区的,增加分区的语句为:
alter table new_table add range partition 30<=values<40
EXAMPLE: KUDU修改分区,查看分区为什么只能在外部表上操作,外部表内部表的映射可以共享表结构吗
ALTER TABLE linghit_bigdata_dwd.linghit_bigdata_userinfo_external ADD RANGE PARTITION unix_timestamp("2020-04-13") <= VALUES < unix_timestamp(date_add("2020-04-13", 3));
// 删除分区
alter table new_table DROP RANGE PARTITION 30<=values<40
// 查看分区
1. show partitions tablename(外部表);
2. alter table new_table add range partition 30<=values<40; // 再增加一次试试反馈
// 从Impala中创建KUDU中XX表的外部表
CREATE EXTERNAL TABLE kudu_test_table
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'emr-header-1:7051,emr-header-2:7051,emr-worker-1:7051',
'kudu.table_name' = 'java_example-1580975328237'
);
-- impala创建外部关联表
CREATE EXTERNAL TABLE linghit_bigdata_userinfo_external
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = '172.16.110.88:7051,172.16.110.87:7051,172.16.110.83:7051',
'kudu.table_name' = 'linghit_bigdata_userinfo'
);
// 从impala创建内部表
CREATE TABLE kudu_test_table_4
(
id STRING,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = '172.16.110.88:7051,172.16.110.87:7051,172.16.110.83:7051',
);
- Kudu 分区
kudu的分区方式
kudu-impala分区表(hash和range分区)
impala建Kudu表语句中的PARTITION BY的作用
----------------------------------------
基本常用操作:
--描述表
DESCRIBE tabel_name;
--查看分区情况
SHOW PARTITIONS table_name;
--查看当前使用数据库
SELECT current_database();
--查看建表语句
SHOW CREATE TABLE table_name
-------------------------------------------
1.建表
(1)hash分区
--主键两个字段,分区字段未指定 hash分区
create table kudu_first_table(
id int,
name string,
age int,
gender string,
primary key(id,name)
) partition by hash partitions 4
stored as kudu;
--主键两个字段,分区字段指定,hash分区
create table specify_partition_column(
id int,
name string,
age int,
gender string,
primary key(id,name)
) partition by hash(id) partitions 3
stored as kudu;
--主键两个字段,分区字段指定一个字段,hash分区
create table specify_partition_one_column(
id int,
name string,
age int,
gender string,
primary key(id)
) partition by hash(id) partitions 3
stored as kudu;
**区别:未指定分区字段时,其分区字段默认是主键,若主键有两个列则分区字段为两个,指定分区字段时,需要分区列是主键的子集;否则会报错「 Only key columns can be used in PARTITION BY」
**不指定分区:表依然会创建,但是只有一个分区,会提示「Unpartitioned Kudu tables are inefficient for large data sizes.」
(2)range分区:主要针对时间进行range分区
CREATE TABLE cust_behavior (
_id BIGINT PRIMARY KEY,
salary STRING,
edu_level INT,
usergender STRING,
`group` STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
sku STRING,
rating INT,
fulfilled_date BIGINT
)
PARTITION BY RANGE (_id)
(
PARTITION VALUES < 1439560049342,
PARTITION 1439560049342 <= VALUES < 1439566253755,
PARTITION 1439566253755 <= VALUES < 1439572458168,
PARTITION 1439572458168 <= VALUES < 1439578662581,
PARTITION 1439578662581 <= VALUES < 1439584866994,
PARTITION 1439584866994 <= VALUES < 1439591071407,
PARTITION 1439591071407 <= VALUES
)
STORED AS KUDU;
**优势:可以根据数据的具体情况建立分区,比如:建立2017年之前的分区,2017-2018,2018-2019,2019-2020,2020-2021,。。。
**劣势:如果使用单级range分区的话,容易产生数据热点问题(可混合hash分区使用)、
在range分区中,如果有不止一个字段作为分区字段的话也可以,语法暂时不清楚
如果插入一条主键的值不落在任何range区间时会插入失败,并报错
(3)混合分区
create table tw_details4(
user_id string,
event_date string,
event string,
properties string,
customer_id int,
project_id int,
primary key(event_date,event,user_id)
) partition by hash(user_id) partitions 3, range(event_date)(
partition values < '2017-01-01',
partition '2017-01-01' <= values < '2018-01-01',
partition '2018-01-01' <= values < '2019-01-01',
partition '2019-01-01' <= values < '2020-01-01',
partition '2020-01-01' <= values < '2021-01-01'
) stored as kudu;
**优势:可以根据时间进行检索,来减少需要scan的tablet,插入的时候不会只有一个tabletserver产生热点
(4)CTAS方式创建表
CREATE TABLE kudu_ti_event_fact_copy
primary key(user_id,event_date)
partition by hash(user_id) partitions 3
stored as kudu
as select user_id,event_date,properties
from auto3.ti_event_fact;
2.创建数据库
impala创建数据库与hive一样,create database db_name,但是这个数据库只是一个impala端的namespace,kudu官网中没有提到数据库的概念,猜测可能是没有这个概念
impala中创建表的时候比如在test数据库中创建table_test对应在kudu中为 test:table_test
3.插入数据
(1)insert into table1 values(v1,v2,v3)
(2)insert into table1 select v1,v2,v3 from table2;
**(3)upsert into table1 values(v1,v2,v3) --根据主键判定,若已经存在则更新,若不存在则插入
4.更改column
(1)update语法
UPDATE kudu_first_table set age = 32 where id= 2;
UPDATE kudu_first_table set age = 31 where gender= 'female';
其中where条件后面的column不是主键也可以但是更改的范围会扩大
**主键中不支持更改,只能删除后重新添加
(2)upsert语法
upsert into table1 values(v1,v2,v3)
**需要更新所有字段
5.更改表
(1)修改表名,修改的只是表在impala中的映射名
alter table kudu_ti_event_fact_copy rename to kudu_ti_event_fact_copy_rename;
(2)修改kudu存储的表名,但是不会改变在impala端的映射表名,也就是在impala中依然访问更改之前的表名
ALTER TABLE kudu_ti_event_fact_copy_rename
SET TBLPROPERTIES('kudu.table_name' = 'kudu_ti_event_fact_copy');
(3)修改列属性
-- --**不支持---
(4)添加列
alter table kudu_ti_event_fact_copy_rename add columns(method string,time_stamp string);
(5)删除列
ALTER table kudu_ti_event_fact_copy_rename drop column method;
(6)删除分区
ALTER TABLE range_partition_table DROP RANGE PARTITION VALUES < '2017-01-01';
(7)添加分区
alter table range_partition_table add range partition values < '2017-01-01';
- Kudu 链接方式
- Kudu Sink Connector:封装好不会报错,但操作(增删改)失败的一些可能原因是:1.kudu表建表的服务器位置和你用代码连接的位置不一样,导致看到的表信息不一样 2. 操作必须带有主键,主键的数据类型必须与建表指定的一致 3. kudu建表时如果存在分区,需要看清楚主键的上下限,在上下限中间取值,避免操作的时候出现主键错误 4. 使用Impala建表和java api建表表名会不一样,impala建表表名会显示impala:
常见错误
-
kudu 插入报错之主键不存在:
Row error for primary key=“9”, tablet=null, server=xx, status=Not found: key not found
这个报错的意思是说没有主键为9的数据,因为你使用的是update模式去更新数据,更新数据,那么数据必须先存在。 -
kudu 插入报错之分区不存在:
Row error for primary key=“156307740800000040\x00\x00\xDE\x93\xC8\x00X01”, tablet=null, server=null, status=Not found: ([0x00000003DE88AF00, 0x00000003DE99D280))
相应的kudu分区不存在
KUDU容易出错的三个地方:
- tables忘记加上kudu表名(使用flink kudu sink connector的时候)
- kudu字段的数据类型不匹配
- kudu分区不存在
- 更新、删除数据行需要指定所有的主键,更新的话对应主键的数据必须存在
kudu常见错误整理
Flume - 数据采集
数据采集层
Flume 1.9.0 User Guide
Flume入门
Flume学习之路 (一)Flume的基础介绍
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
/apache-flume-1.8.0-bin/conf/flume.conf
http source
flume的过滤器: KongKim-Flume.git 通过ip解析了城市之类的信息
- file channel
- memory channel2
hdfs Sinks
kafka sink2
修改完 flume.conf 不用重启,自己就轮训了
Kafka - 消息系统
Apache Kafka教程 - W3Cschool
Kafka命令行消费、生产Demo
Flink从kafka中读数据存入Mysql Sink:里面含kafka生产者Java代码,maven没有导入kafka包,但是kafka producer可以导入org.apache.kafka.clients.producer.KafkaProducer;说明flink-connector-kafka包起作用了
Flink消费Kafka数据时指定offset的五种方式
kafka中文简介
Kafka在Linux环境下搭建过程
Kafka查看topic、consumer group状态命令
RabbitMQ消息队列 简介以及使用场景
在大数据中,使用了大量的数据。 关于数据,我们有两个主要挑战。第一个挑战是如何收集大量的数据,第二个挑战是分析收集的数据。 为了克服这些挑战,您必须需要一个消息系统。
Kafka专为分布式高吞吐量系统而设计。 Kafka往往工作得很好,作为一个更传统的消息代理的替代品。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
什么是消息系统?
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
消息系统(生产者 - 消费者):
- 点对点消息系统 :在点对点系统中,消息被保留在队列中。 一个或多个消费者可以消耗队列中的消息,但是特定消息只能由最多一个消费者消费。 一旦消费者读取队列中的消息,它就从该队列中消失。该系统的典型示例是订单处理系统,其中每个订单将由一个订单处理器处理,但多个订单处理器也可以同时工作。
- 发布 - 订阅消息系统:消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。 在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。
好处
以下是Kafka的几个好处 -
- 可靠性 - Kafka是分布式,分区,复制和容错的。
- 可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
- 耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
- 性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。
Kafka非常快,并保证零停机和零数据丢失。
用例
Kafka可以在许多用例中使用。 其中一些列出如下 -
- 指标 - Kafka通常用于操作监控数据。 这涉及聚合来自分布式应用程序的统计信息,以产生操作数据的集中馈送。
- 日志聚合解决方案 - Kafka可用于跨组织从多个服务收集日志,并使它们以标准格式提供给多个服务器。
- 流处理 - 流行的框架(如Storm和Spark Streaming)从主题中读取数据,对其进行处理,并将处理后的数据写入新主题,供用户和应用程序使用。 Kafka的强耐久性在流处理的上下文中也非常有用。
需要Kafka
Kafka是一个统一的平台,用于处理所有实时数据Feed。 Kafka支持低延迟消息传递,并在出现机器故障时提供对容错的保证。 它具有处理大量不同消费者的能力。 Kafka非常快,执行2百万写/秒。 Kafka将所有数据保存到磁盘,这实质上意味着所有写入都会进入操作系统(RAM)的页面缓存。 这使得将数据从页面缓存传输到网络套接字非常有效。
基础知识
消费者:(Consumer):从消息队列中请求消息的客户端应用程序
生产者:(Producer) :向broker发布消息的应用程序
AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题
-分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列
每一个分区都可以有多个副本,以防止数据的丢失
某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader来更新
消费者可以分组,比如有两个消费者组A和B,共同消费一个topic:order_info,A和B所消费的消息不会重复,比如 order_info 中有100个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49号,B组就消费50-99号.
同一个消费组的多个消费者相当于一个消费者去消费数据,提高了消费的效率。topic的分区,给消费顺序带来了一些麻烦,通过了解到kafka的底层原理后,在遇到问题时,就可能解释并解决。
消费者在具体消费某个topic中的消息时,可以指定起始偏移量
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手
作者:骑着大象去上班
链接:https://www.jianshu.com/p/bfbb8a5e2f63
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Spark - 大数据计算引擎
Spark 是一个同时支持批处理和流计算的分布式计算系统。Spark 的所有计算均构建于 RDD 之上,RDD 通过算子连接形成 DAG 的执行计划,RDD 的确定性及不可变性是 Spark 实现故障恢复的基础。Spark Streaming 的 D-Stream 本质上也是将输入数据分成一个个 micro-batch 的 RDD。
基于内存的大数据计算框架,比依赖于HDFS读取存储的MR要快、方便的多,更具备实时性
Spark既有官方语言scala,也有java和python版本的api。
Spark入门基础教程
Spark 教程
在linux上安装spark详细步骤
《Spark官方文档》Spark操作指南
Spark on yarn模式
SparkOnYarn专题四–cluster模式和client模式资源分配的详解
Spark中yarn模式两种提交任务方式
spark中dag的介绍
Spark基础 DAG
spark与hbase交互错误:org.apache.htrace
关于怎么解决java.lang.NoClassDefFoundError错误
Spark SQL教程
Spark SQL
SparkConf 配置的用法
Idea 里面创建Mavenproject 利用sparkSQL操作Hive
SparkSQL操作Hive Table - enableHiveSupport():.enableHiveSupport().getOrCreate();
Java接入Spark之创建RDD的两种方式和操作RDD
spark-sql createOrReplaceTempView 和createGlobalTempView区别
SparkSQLDemo初尝--SparkSession链接数据库
spark sql——5. spark sql操作mysql表
cdh5.13 spark连接hive数据源
spark动态资源(executor)分配
HDFS MR是批处理,Spark streaming和Flink是流处理。我理解是批处理是全量,流处理是无界数据分区进行处理,微批处理是分batch对流数据进行处理

流处理和批处理框架的异同:讲述了流处理,微批处理的原理、区别;消息传输保障三种模式(at most once,at least once和exactly once)的原理
Spark 其他
Spark认识&环境搭建&运行第一个Spark程序
《Spark官方文档》Spark操作指南
-
部署PySpark
http://blog.csdn.net/hjxinkkl/article/details/57083549?winzoom=1
http://blog.csdn.net/yiyouxian/article/details/51020334 -
pyspark部署中相关错误
http://makaidong.com/aiyuxi/348_1857825.html
http://blog.csdn.net/pipisorry/article/details/52916307
https://www.cnblogs.com/hark0623/p/4170172.html
https://stackoverflow.com/questions/19620642/failed-to-locate-the-winutils-binary-in-the-hadoop-binary-path
改了两个地方:
1.os.environ[‘JAVA_HOME’] = “D:\Java\jdk1.8.0_131” 在代码中加入这句
2.修改 D:\hadoop-2.7.4\libexec\hadoop-config.sh 162行
增加 export JAVA_HOME = “D:\Java\jdk1.8.0_131”
3.之后出现的错误
Py4JNetworkError An error occurred while trying to connect to the Java server (127.0.0.1:51499)
不影响使用
pyspark的使用和操作(基础整理)
IDEA安装Scala,版本对应
详见有道云笔记-MAC IDEA SPARK(SCALA)环境配置
Flink - 大数据计算引擎
统一批处理流处理——Flink批流一体实现原理
Flink,Storm,SparkStreaming性能对比
Flink与storm,spark的区别, 优势, 劣势.
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
大数据发展阶段:第一阶段-第四阶段
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
分布式流处理是对无边界数据集进行连续不断的处理、聚合和分析。它跟MapReduce一样是一种通用计算,但我们期望延迟在毫秒或者秒级别。这类系统一般采用有向无环图(DAG)。
一个通俗易懂的概念: Apache Flink 是近年来越来越流行的一款开源大数据计算引擎,它同时支持了批处理和流处理.
这是对Flink最简单的认识, 也最容易引起疑惑, 它和storm和spark的区别在哪里? storm是基于流计算的, 但是也可以模拟批处理, spark streaming也可以进行微批处理, 虽说在性能延迟上处于亚秒级别, 但也不足以说明Flink崛起如此迅速(毕竟从spark迁移到Flink是要成本的).
网上最热的两个原因:
- Flink灵活的窗口
- Exactly once语义保证
这两个原因可以大大的解放程序员, 加快编程效率, 把本来需要程序员花大力气手动完成的工作交给框
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
1.什么是 Window
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(Time Window, 例如: 每30秒钟), 也可以是数据驱动的(Count Window, 例如: 每一百个元素). 一种经典的窗口分类可以分成: 翻滚窗口(Tumbling Window, 无重叠), 滚动窗口(Sliding Window, 有重叠), 和会话窗口(Session Window,活动间隙).
我们举个具体的场景来形象地理解不同窗口的概念. 假设, 淘宝网会记录每个用户每次购买的商品个数, 我们要做的是统计不同窗口中用户购买商品的总数. 下图给出了几种经典的窗口切分概述图:
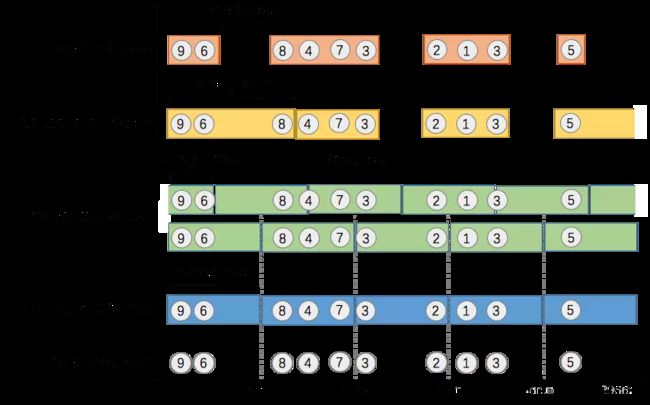
大数据起源自批处理, spark最初的定位就是改进hadoop, 更快速的进行批处理. storm擅长的则是进行无状态的流计算(在无状态的流计算领域, 它的延迟是最小的), 而Flink则是storm的下一代解决方案(当然Flink的设计之初并不是改进storm), 能够进行高吞吐,低延迟(毫秒级)的有状态流计算.


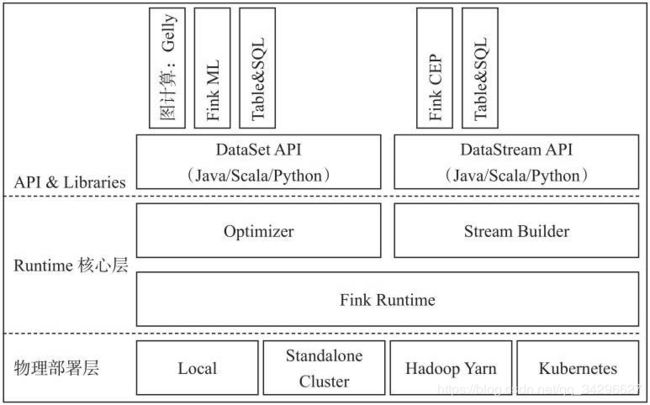
Flink基本架构图



Livy - 基于Apache Spark的REST服务
Livy:基于Apache Spark的REST服务
Spark之livy的安装使用
EMR-3.20+, 自带 livy 0.6.0
livy支持两种两种任务提交方案:
1、交互式:说白了,就是把原本在spark-shell里面执行的语句,通过http请求发送到livy服务端,然后livy在服务端开启spark-shell执行你传过来的语句;
2、批处理式:说白了,帮你做spark-submit的工作,同样通过http请求吧参数发到livy服务端。
使用REST接口调用Spark——Apache Livy使用笔记
Impala - SQL查询引擎
impala教程
Impala和Hive的关系:写的很好
Impala Shell 简单命令
Impala Shell常用命令行选项与常用命令
什么是Impala?
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
为什么选择Impala?
Impala通过使用标准组件(如HDFS,HBase,Metastore,YARN和Sentry)将传统分析数据库的SQL支持和多用户性能与Apache Hadoop的可扩展性和灵活性相结合。
- 使用Impala,与其他SQL引擎(如Hive)相比,用户可以使用SQL查询以更快的方式与HDFS或HBase进行通信。
- Impala可以读取Hadoop使用的几乎所有文件格式,如Parquet,Avro,RCFile。
与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。
因此,它减少了使用MapReduce的延迟,这使Impala比Apache Hive快。Hive底层采用MR进行SQL操作。
Impala的优点
-
使用impala,您可以使用传统的SQL知识以极快的速度处理存储在HDFS中的数据。
-
由于在数据驻留(在Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。
-
使用Impala,您可以访问存储在HDFS,HBase和Amazon s3中的数据,而无需了解Java(MapReduce作业)。您可以使用SQL查询的基本概念访问它们。
-
为了在业务工具中写入查询,数据必须经历复杂的提取 - 变换负载(ETL)周期。但是,使用Impala,此过程缩短了。加载和重组的耗时阶段通过新技术克服,如探索性数据分析和数据发现,使过程更快。
-
Impala正在率先使用Parquet文件格式,这是一种针对数据仓库场景中典型的大规模查询进行优化的柱状存储布局。
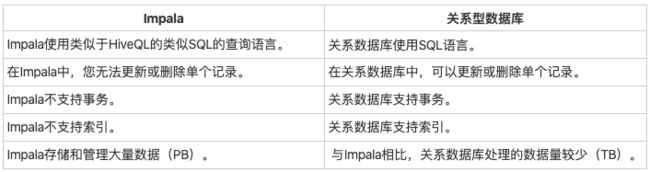
Impala和关系数据库
Impala,Hbase和Hive
Cloudera Impala使用与Hive相同的查询语言,元数据和用户界面,但在某些方面它与Hive和HBase不同。 下表介绍了HBase,Hive和Impala之间的比较分析。

在Impala中,您无法更新或删除单个记录。Impala不支持事务。Impala不支持索引。Impala存储和管理大量数据(PB)。
Impala的缺点
- Impala不提供任何对序列化和反序列化的支持。
- Impala只能读取文本文件,而不能读取自定义二进制文件。
- 每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
使用
除了Impala shell之外,您还可以使用Hue浏览器与Impala进行通信。
Impala架构
impala与其存储引擎解耦。 它有三个主要组件,即Impala daemon(Impalad),Impala Statestore和Impala元数据或metastore。
https://www.w3cschool.cn/impala/impala_architecture.html
Impala视图
视图仅仅是存储在数据库中具有关联名称的Impala查询语言的语句。 它是以预定义的SQL查询形式的表的组合。
视图可以包含表的所有行或选定的行。 可以从一个或多个表创建视图。 视图允许用户 -
- 以用户或用户类发现自然或直观的方式结构化数据。
- 限制对数据的访问,以便用户可以看到和(有时)完全修改他们需要的内容,而不再更改。
- 汇总可用于生成报告的各种表中的数据。
视图也可以理解成一张表,只是一张绘制了表格线和表头的表。

常用命令
https://www.jianshu.com/p/b19971ddaf85
SELECT VERSION();
# 偏移量(offset) & 限制(limit)
# OFFSET 需要使用order by 条件语句配合。limit:查询数量 offset:偏移量-根据order排序后的数据定位
select * from table_test order by create_time limit 2 offset 1
使用curl快速重启impala
https://www.cnblogs.com/sdhzdtwhm/p/10253861.html
Parquet
数据格式
为什么我们选择parquet
Parquet介绍及简单使用
parquet常用操作
good - 深入分析 Parquet 列式存储格式
Phoenix - HBase sql引擎
Sqoop
Apache Sqoop(TM)是一种用于在Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据的工具。
一个组织中有价值的数据都存储在关系型数据库系统等结构化存储器中。Sqoop允许用户将数据从结构化存储器抽取到Hadoop中,用于进一步的处理。抽取出的数据可以被MapReduce程序使用,也可以被其他类似亍Hive的工具使用。一旦生成最终的分析结果,Sqoop便可以将这些结果导回数据存储器,供其他客户端使用。
关系型数据库 < – > Hadoop
全量、增量导入导出
sqoop 导入导出数据命令参数详解
Sqoop 常用命令及参数
Sqoop 复制mysql表结构建表、从mysql导入数据到hive
Sqoop 导入及导出表数据案例
sqoop导入数据到hive查询全部为null 、 sqoop导入数据到hive数据增多
target-dir导入到哪一个HDFS目录
注意:指定的hdfs的目录不能存在,因为sqoop会将这个目录作为MapReduce的输出目录。
我认为仅仅只是作为mapreduce中间计算过程的临时文件夹,执行完会自行删除中间结果。hive表的位置取决于–hive-table参数
sqoop执行的时候会检测对应的hive表,如果没有就创建
CREATE TABLE IF NOT EXISTS linghit_bigdata_ods.u_visitor
# Sqoop example
jdbcurl="jdbc:mysql://$host:3306/$db_name?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false" tinyInt1isBit禁止自动转换&useUnicode/characterEncoding 编码参数,解决中文乱码问题
sqoop import --connect "$jdbcurl" \
--username $username \
--password $password \
--columns "user_id,account,email,phone,password,status,create_at,update_at" \
--query "select * from u_visitor where create_at>='$day_init 00:00:00' and \$CONDITIONS" \ 尽量不要用*,写出具体字段,因为mysql端可能会不通知你的情况下增加字段
--hive-table db.table_name \
--hive-drop-import-delims \
--split-by 'user_id' \
--target-dir "/user/hive/warehouse/tmp/dataceter_u_account" \
--delete-target-dir \
--hive-partition-key row_date \ 分区表,分区字段
--hive-partition-value $day_init \
--hive-overwrite \
--null-string '\\N' \ string类型的字段,当Value是NULL,替换成指定的字符\N
--null-non-string '\\N' \ 非string类型的字段,当Value是NULL,替换成指定的字符\N
--fields-terminated-by "\t" \ hive表中字段分隔符
--num-mappers 1 \
--hive-import
// LIMIT
–query “select id,lid,teacher_uid,user_id,server_id,server_name,amount,created_at,order_id from yi_live_server_pay where $CONDITIONS LIMIT 100”
–null-string ‘@@@’
–null-non-string ‘###’
备注:
–null-string含义是 string类型的字段,当Value是NULL,替换成指定的字符,该例子中为@@@
–null-non-string 含义是非string类型的字段,当Value是NULL,替换成指定字符,该例子中为###
-
sqoop导入数据到hive查询全部为null
从postgresql或者mysql来的数据的分隔符则应该为:’\0001’,需要在sqoop指令中进行指定–fields-terminated-by “\0001” -
sqoop导入数据到hive数据增多
导入的数据默认的列分隔符是’\001’,默认的行分隔符是’\n’。
这样问题就来了,如果导入的数据中有’\n’,hive会认为一行已经结束,后面的数据被分割成下一行。这种情况下,导入之后hive中数据的行数就比原先数据库中的多,而且会出现数据不一致的情况。
简单的解决办法就是加上参数 –hive-drop-import-delims 来把导入数据中包含的hive默认的分隔符去掉。 -
我们用sqoop,并且采用query的时候,我们最好使用双引号,而且如果有where语句,必须加上“\CONDITIONS”,注意有“\”进行转义。
--query "select * from u_product_relation where DATE_FORMAT(created_at,'%Y-%m-%d')='$day_init' and \$CONDITIONS" \
–connect 链接对应的数据库
–query 去数据库查需要的数据出来
如果没有数据迁移到hive,可以先复制–query 中的mysql语句到mysql命令行试试是否有错
https://blog.csdn.net/IKnowNothinglee/article/details/90640912
-
Error converting column: 2 to INT
无所谓,仅仅只是在impala中解析hive表会出现这个警告,在hive中查询则是正常的
It doesn’t matter, just not parse in impala,the data is existed in hive table;
Impala Can Not Parse “null” Values in Numeric Fields, Raises “Error converting column: TO INT (Data is: null)” on the BDA Instead (Doc ID 2154903.1)
Ref
but I find that the null values in the HDFS file are replaced by ‘N’ instead of ‘\N’ :
Which results to unrecognized NULL values mostly for the STRING type (because for the INT type the ‘N’ is considered like NULL…).
Ref -
Sqoop创建的hive表部分字段的数据格式和mysql对不上
遇到这种情况,我们可以采用自己先来建对应的hive表,再用sqoop来迁移。
如果mysql数据不大,只是用来测试的话,也可以先让sqoop默认去建造hive表,然后用show create table tablename来查看建表语句
// 查看hive建表语句
show create table linghit_bigdata_ods.u_account;
为了预防这种情况,我们在sqoop迁移完数据之后,最好和mysql的数据比较一下,作为检验
-
sqoop tinyint变成了null
只能将那个字段的数据格式进行转化,
https://www.cnblogs.com/guozhen/p/9836459.html
https://blog.csdn.net/weixin_38750084/article/details/82873171 -
查询语句中出现sql关键字
–columns指令出现了默认关键字的话,不需要转义,它只对应hive表中对应的字段
–query就要加上反引号,并且反引号需要用’'进行转义
–columns “id,name,describe,sort,created_at,updated_at,deleted_at”
–query “select id,name,`describe`,`sort`,created_at,updated_at,deleted_at from groups WHERE $CONDITIONS” \ -
出现hive表中只有一个字段有值,其他字段都为NULL
- 检查下hive表字段和mysql字段是否数量一致
- 试试–fields-terminated-by “\0001”
sqoop允许强转的的数据格式
- ERROR tool.ImportTool: Import failed: java.io.IOException: Generating splits for a textual index column allowed only in case of “-Dorg.apache.sqoop.splitter.allow_text_splitter=true” property passed as a parameter
中间如果注释掉一行,就会报这个错
--target-dir "/user/hive/warehouse/tmp/" \
# --delete-target-dir \
--hive-partition-key row_date \
--hive-partition-value $day_init \
Ref
-
tinyint(1) 数据格式自动变成Boolean 数据格式
sqoop从mysql导入数据到hive时tinyint(1)格式自动变成Boolean解决方案
在jdbc的连接后面加上:tinyInt1isBit=false
–connect jdbc:mysql://192.168.9.80:3306/kgc_behivour_log?tinyInt1isBit=false -
Hive数据类型
Hive之数据类型
sqoop入门教程
sqoop client java api将mysql的数据导到hdfs
Sqoop之java API导入导出数据
Sqoop Java客户端API与外部应用交互
Canal
基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql
将mysql的数据与中间件的数据进行同步,Mysql -> Kafka
阿里开源Canal–①简介
开源数据同步神器–canal
canal配置分为两部分:
① canal.properties (系统根配置文件)
② instance.properties (instance级别的配置文件,每个instance一份),每个数据库对应1个instance,如果需要同步多个数据库,只需要在conf下创建多个destination目录,创建多个instance.properties,并在每个instance.properties中配置需要的数据库即可。
canal instance添加或修改properties配置文件,canal会自动扫描
但是canal.property不会,需要手动重启
sh bin/startup.sh
sh bin/restart.sh
tailf logs/canal/canal.log
canal重启文件不会丢失,接着之前mysql的binlog继续往下走
canal重启不会丢失数据的讨论
https://github.com/alibaba/canal/issues/1078
https://github.com/alibaba/canal/issues/237
canal配置文件
数据同步canal服务端介绍
canal的配置详解
Canal配置文件详解
Knox
使用Apache Knox配置保护Spark/Hadoop
我们主要用Knox来保护Spark UI、HDFS UI、Yarn UI,以及thrift server。当然,Knox也不只是服务于Hadoop、Spark,对于Web化的应用,基本上都可以使用Knox做保护,例如用Knox做Tomcat代理
Hadoop生态圈-Knox网关的应用案例
Flume、ElasticSearch、Kibana
最全Flume、ElasticSearch、Kibana实现日志实时展示
实时日志收集-查询-分析系统(Flume+ElasticSearch+Kibana)
Elasticsearch 权威指南(中文版)
Yarn、Pig、Storm、Zookeeper
广证、仲奇没有让我看的技术点
Kibana:Kibana是从flume sink到的kafka端获取数据
kibana ELK
YARN
Yarn资源调度工作原理
w3cschool的批处理入门:w3cschool的批处理入门教程,与shell编程是一样的概念,与大数据里的批处理不是一个概念
数仓设计思想/原则
数仓组成
ods、dwd、dws、ads
Other
yarn、npm比较
yarn详细入门教程
YAML教程