Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning 论文赏析
Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning 论文赏析
- 前言
- Introduction
- Motivation(动机)
- Related Work
- Overview
- Model Architecture
- Spatial Reasoning Network
- Temporal Stack Learning Network
- 数据预处理
- 时间堆叠网络
- Classification
- Experiments
前言
前段时间拜读了司晨阳老师在ECCV2018上发表的文章《Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning》,感觉收获良多。现特意将个人的一些理解、感想整理下来,供大家参考。有不足之处还请大家多多包涵指正,感谢~
论文题目:Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning
论文链接:https://arxiv.org/abs/1805.02335v1
Introduction
Motivation(动机)
通读文章Introduction和Related Work部分可以将文章的动机总结为以下四点:
- 人体在完成某一动作时,身体各部位之间是相互协调完成的(例如走路时除了腿在迈动,胳膊也在摆动);
- 人体骨架数据是不规则的,CNN无法直接对原始骨架数据进行操作,因此在处理骨架数据时,一般的做法是将骨架数据编码成规则的图像,然后输入到CNN中进行卷积操作。但是这样做的缺点就是Conv操作受到感受野的限制,只能建模相邻关节点的空间特征,无法建模跨度较大节点间的关系;
- RNN和LSTM在建模动态时序特征方面有优势,但是无法提取高语义的空间特征;
- 由于RNN和LSTM的当前节点信息只与前一节点相关,导致其只能够建模短时间的动态信息,无法存储长时序列。
当前在动作识别方面,最好的方法还是双流网络,即将视频的静态空间特征和动态时序特征分别用两个神经网络进行建模。前3个动机可以看作是在建模空间特征方面进行的分析,最后第4个动机则是在建模动态时序特征方面进行分析。针对以上motivations,本文做了以下4点contributions(文章中罗列):
- 针对空间特征提出了空间推理网络(Spatial Reasoning Network),将人体骨架结构分成K部分,利用残差图网络建模各部分之间的空间关系;
- 针对长时建模提出了时间堆叠学习网络(Temporal Stack Learning Network),将完整的视频序列分成M个clips,每一个clip用LSTM进行建模,将clip间的LSTM进行skip connect。通过堆叠clip来实现更长时序的建模;
- 提出了clip-based incremental loss来训练模型;
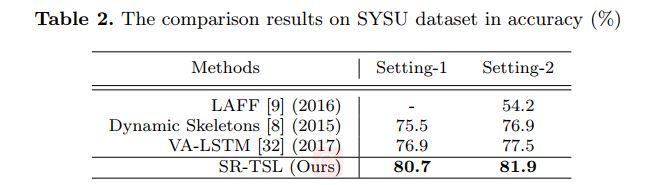
- 本文提出的SR-TSL在SYSU 3D和NTU RGB+D数据集上都取得了SOTA。
第1个contribution针对前3个motivations;2,3个contributions对应于第4个motivation。通读整篇文章可以发现,本文的侧重点在于使用multiple skip-clip LSTMs进行长时建模方面。
Related Work
文章中的相关工作包括两个模块。首先介绍了基于3D人体骨架数据的相关工作。从早期的手工特征设计到目前最流行的深度神经网络提取特征,本文的侧重点在于LSTM,故介绍的RNN、LSTM的相关工作较多;第二个模块介绍了关于图神经网络的发展及相关工作。
Overview
此部分内容就是介绍本文用到的基本方法的操作:图神经网络的计算和RNN、LSTM。
在这里,我将本文的整体框架拿到本部分进行介绍。本文模型的整体框架如如下图所示:
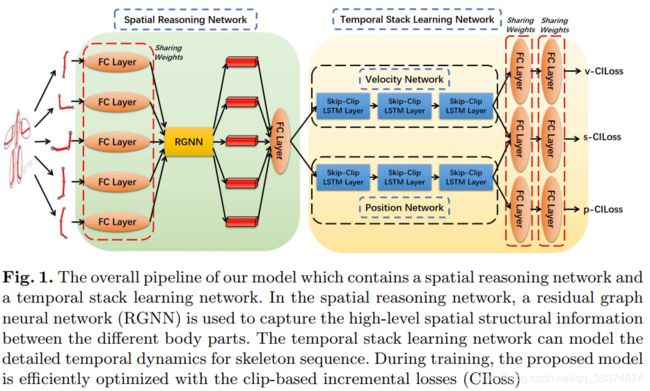
如图1所示,首先将人体骨架分成K部分(这里就按图1,K=5来讲),然后将每个部分通过权值共享的全连接层学习每个part内部的空间特征并将输出维度统一。 第二步,全连接层的输出作为残差图网络(Residual Graph Neural Network)的输入,学习每个part之间的空间特征,其中图神经网络有几个节点就有几个输出。输出后的特征经全连接层聚合之后输入到LSTM中。本文采用双流LSTM,分别用来学习动态时序特征和空间特征。最后通过两个全连接层进行分类。
Model Architecture
重点来了!本章节重点介绍了本文所提出的方法 SR-TSL。SR-TSL包括两个模块,故本章节先后介绍了空间推理网络(Spatial Reasoning Network)和时间堆叠学习网络(Temporal Stack Learning Network)。
Spatial Reasoning Network
空间推理网络采用的是残差图神经网络(Residual Graph Neural Network, RGNN)。骨架数据在输入到RGNN前,先经过预处理,分成K个part。如图2(a)所示:
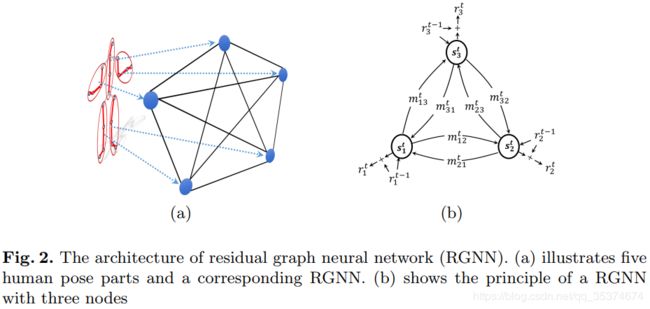
RGNN的每个节点单独作为一个计算单元,有K个body parts就对应其K个节点。在输入RGNN前,首先每个part经过全连接层处理。一方面是通过全连接层建模每个part内部各关节之间的关系,另一方面通过全连接层处理后的特征维度都相同,容易输入到RGNN进行下一步的处理。图2(a)所示为无向图,故图中每个节点之间都是相互影响的。 RGNN主要包括三部分的信息,分别为节点自身状态信息(s),边的信息(m)以及残差信息(r),如图2(b)所示。下面将具体介绍RGNN的计算过程。
边信息(Received Message mkt)
边的信息表示节点间的互相影响。本文中received message通过以下方式进行更新:

公式(4)中的 Ω v k Ω_{v_k} Ωvk表示与节点k相连的所有邻居节点。因此,公式(4)求建模的是节点k的所有邻居的关系,但是不包含k节点。也就是说,received messages建模的是与第k个部位连接的其他身体部位之间的空间关系。
节点的状态信息(Information of Node Hidden State)
更新完边的信息之后,需要更新每个节点自身的状态信息。信息更新函数如公式(5)所示:

其中 s k t − 1 s^{t-1}_k skt−1表示第t-1时刻,节点k的状态信息; m k t m^t_k mkt表示第t时刻,节点k接收到的边的信息; r k t − 1 r^{t-1}_k rkt−1表示t-1时刻,节点k的残差信息。 f l s t m f_{lstm} flstm表示的是LSTM计算单元,即RGNN的每个节点是一个LSTM。
残差信息(Residual)
残差信息 r k t r^t_k rkt的更新方式如下所示:

在这里,残差信息r被初始化为每一部分的结构特征,即 r k 0 = e k r^0_k=e_k rk0=ek。加入残差的目的是为了将节点自身的信息融合到特征中,即建模所有部位间的空间关系。另外,通过LSTM计算单元建模part内部的特征关系可以学习到part内部的时间特征。
空间特征
RGNN有K个节点,每个节点都是建模的身体部位间的空间关系。因此,最终需要的空间特征是将K个节点的输出进行综合。如下所示:

以上就是空间推理网络的建模方式,通过RGNN不但可以建模空间特征,而且通过每个LSTM计算单元可以提取部分时间特征。下面介绍时间堆叠网络如何建模长时间的动态特征。
Temporal Stack Learning Network
数据预处理
本文建模时间特征是基于clips,即将完整的视频分成 M M M个clips。假设完整的视频序列有 N N N帧,按照 d d d帧的间隔分成 M M M个clips,即每个clip包括 d d d帧。如下所示:
![]()
其中,
![]()
代表的是经过空间推理网络后输出的空间特征。首先,要通过空间特征计算出运动特征,及相邻帧之间的差值,用 V V V表示:
![]()
时间堆叠网络
文章中通过3层的LSTM进行时间建模。如下图所示:
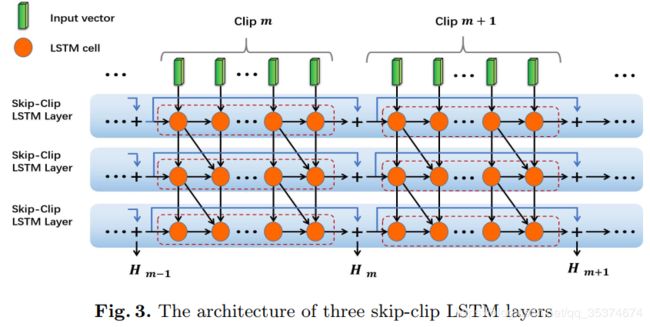
其中视频序列的clip数量与LSTM的数量是相同的,即图3中绿色块的组数。文章设计的巧妙之处在于以clip为单位进行了LSTM的skip connect。这样可以将过去的长时序列融合到当前的clip,从而实现长时动态信息的建模。至于为什么采用3层的LSTM,我猜想可能是跟clips的数量有关,因为在实验中作者将视频分成了3个clip(看到过相关论文也有类似的堆叠LSTM的层数,是跟视频分的片段数量有关);另外,通过堆叠LSTM层数,可以更加灵活的建模时序特征。

Classification
文章的时间堆叠网络采用的是双流网络的思想,通过两个LSTM分支分别建模空间、时间特征。作者采用了三个loss function来训练整个模型,分别是空间loss( L p L_p Lp),时间loss( L v L_v Lv)以及空间-时间loss( L s L_s Ls),采用的都是信息熵的形式,如下所示:

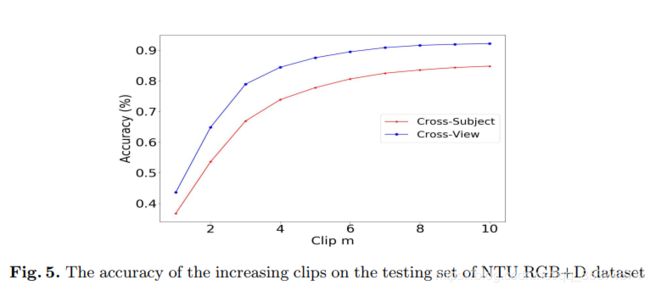
因为在建模时间特征时,依赖于视频的clips的数量,作者指出在一定范围内,clip的长度越长包含的时间特征就越多,对识别任务越有利。在后面的实验中,作者也去讨论验证了clips的数量和长度对实验结果的影响。
本文的主要思想就是这样的,新颖的地方在于将整个骨架分为几部分分别建模,并通过图网络来建模各part之间的空间关系。但是我认为这样做还是有一定的局限性的,就是分割人体之后,难免会丢失一些全局特征,那么丢失的这些特征究竟对识别任务有多大的影响是难以判定的。另外的新颖的地方就是在后边建模时间特征的时候,是以clip为单位进行skip connect的,这样即可建模更长时间的特征关系。
Experiments
文章在NTU RGB+D数据集和SYSU 3D数据集上进行了测试。
先后验证了本文方法的有效性;不同结构对方法的影响以及三个参数( M , T , d M, T, d M,T,d)的影响。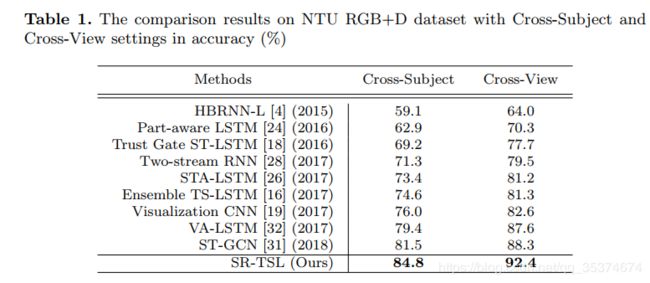

本文仅供大家参考,如有理解不到位的地方欢迎大家批评指正~