BLOG - 个人博文系统开发总结 三:批量博文导入功能
自上一篇博文以来,网站在很多地方有了改进:
- 修改了网站的主要字体为
Segoe UI Semibold - 博主个人主页博文列表每一项在右侧显示博文中的图片(选取博文中的首张图片,如果有的话)
- 将博文统计信息用单独的页面展示,普通用户也能查看(非博主)
- 添加博主个人设置页面,博主可修改用户名,个人简介,主页布局等
- 完成了博文批量导入功能
GitHub:DuanJiaNing/BlogSystem
部分新功能截图
主页列表项添加图片和博文统计数据查看入口

博文统计数据页面
博主个人设置 # 基础设置
博主个人设置 # 账号 # 批量导入博文
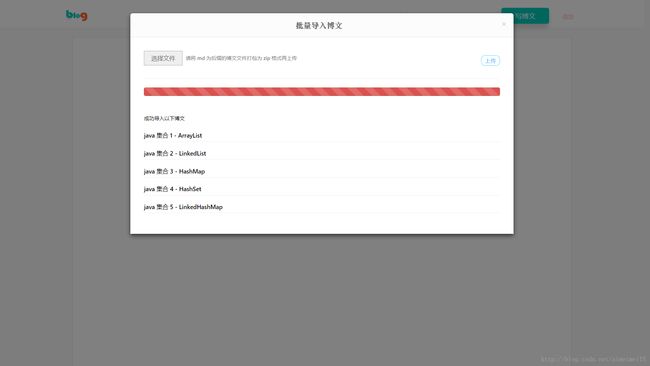
批量博文导入功能
好了,总结过后,进入本篇博文的主题,解析 批量博文导入 功能。
流程是这样的
- 上传将后缀为
.md的博文文件打包的.zip压缩文件 - 将
.zip存至临时文件夹 - 读取
.zip并遍历其中的.md文件 - 将
.md解析并调用新增博文服务新增博文 - 删除临时文件
- 返回成功新增博文的标题
前端.zip文件上传代码
前端界面使用了 bootstrap 的进度条组件,进度条组件通过修改 css 中的 width 属性来修改当前进度(百分比),如 width = 80%时进度条百分比如下:
我设计了在 0% - 60% 的时间段内表示文件上传,当 ajax 请求返回时(这意味着后端处理已经结束),此时进度条快速从 60% 走到 100%(模拟解析过程耗时),表示解析完成,之后将批量导入的博文标题显示出来。
难点在于进度条的 0% - 60 % 这一过程,进度条在走时,文件上传和后端处理正在进行,但两者没有前后关系,即有可能进度条到 60% 但后端处理没有结束,这种情况进度条会停止 60% 处,没有影响,但如果后端处理结束返回但进度条没走到 60% 处,此时就需要提醒进度条直接跳到 60%,另一种情况是,后端处理返回,但处理出错,此时需要提醒进度条回到 0%,并显示错误信息。
简化代码如下:
...
$('#processStatus').html('正在上传...');
var stopSuc = false; // 用于后端处理提前返回时进行提醒
var stopFail = false; // 用于后端处理出错时进行提醒
//进度条从 0% -> 60%,countDown 方法会每过 20 毫秒将值(从60开始)减一,并调用回调方法
countDown(60, 20, function (count) {
if (stopFail) {
// 将进度设为 0%
$('#progressbar').css('width', '0%');
return true; // 返回 true 后倒计时会立即停止
}
if (stopSuc) {
// 将进度设为 60%
$('#progressbar').css('width', '60%');
return true;
}
// 正常倒计时(递增进度)
$('#progressbar').css('width', (60 - count) + '%');
});
// zip 文件
var data = new FormData();
data.append('zipFile', $('#zipFile').prop('files')[0]);
$.ajax({
url: '/blogger/' + bloggerId + '/blog/patch',
type: 'POST',
data: data,
cache: false,
processData: false,
contentType: false,
success: function (result) {
if (result.code === 0) { // 后端处理成功回调
stopSuc = true;
// 60% -> 100% 处理时间
$('#processStatus').html('正在解析...');
countDown(40, 20, function (count) {
if (count === 0) { // 倒计时结束(进度 100%)
$('#progressbar').css('width', '100%');
// 将后端处理返回的成功导入的博文标题显示出来
handleImportSucc(result.data);
return true;
} else {
$('#progressbar').css('width', (100 - count) + '%');
}
});
} else { // 后端处理失败回调
stopFail = true;
$('#processStatus').html('');
// 有可能进度条已经走到 60%
$('#progressbar').css('width', '0%');
// 显示后端处理出错信息
error(result.msg, 'blogImportErrorMsg', true, 3000);
}
}
});
...
后端文件接收和处理代码
Controller层方法
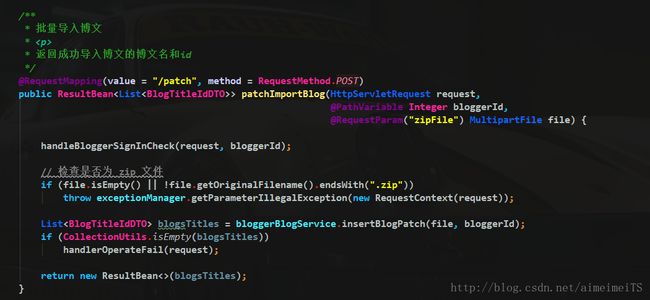
Service 层方法
@Override
public List insertBlogPatch(MultipartFile file, int bloggerId) {
// 保存到临时文件
StringBuilder b = new StringBuilder();
// 从 bloggerProperties.getPatchImportBlogTempPath() 中获得临时文件夹路径
File dir = new File(bloggerProperties.getPatchImportBlogTempPath());
if (!dir.exists() || dir.isFile()) {
if (!dir.mkdirs())
return null;
}
// 构建临时文件全路径
String fullPath = b.append(dir.getAbsolutePath())
.append(File.separator)
.append("temp-")
.append(bloggerId)
.append("-")
.append(System.currentTimeMillis())
.append("-")
.append(file.getOriginalFilename())
.toString();
// 保存临时文件
FileUtils.saveFileTo(file, fullPath);
// 用于将读取到的 md 格式文件解析为 html 格式
final Parser parser = Parser.builder().build();
final HtmlRenderer renderer = HtmlRenderer.builder().build();
// 解析博文
List result = new ArrayList<>();
ZipFile zipFile = null;
try {
zipFile = new ZipFile(fullPath);
Enumeration entries = zipFile.entries();
// 变量 zip 中的 md 文件
while (entries.hasMoreElements()) {
ZipEntry entry = entries.nextElement();
BufferedInputStream stream = new BufferedInputStream(zipFile.getInputStream(entry));
InputStreamReader reader = new InputStreamReader(stream, Charset.forName("UTF-8"));
// 解析 md 文件,存入数据库,并返回博文标题和记录在数据库中的id
BlogTitleIdDTO node = analysisAndInsertMdFile(parser, renderer, entry, reader, bloggerId);
if (node != null)
result.add(node);
}
} catch (IOException e) {
throw new InternalIOException(e);
} finally {
if (zipFile != null) try {
zipFile.close();
// 删除临时文件
File tempFile = new File(fullPath);
if (tempFile.exists() && tempFile.isFile())
tempFile.delete();
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
return result;
}
Parser 和 HtmlRenderer 是 flexmark 框架中的类,flexmark 可以将 markdown 转为 Html。
参考文章:Java 实现 markdown转Html
maven:com.vladsch.flexmark
md 文件解析和新增博文
// 解析 md 文件读取字符流,新增记录到数据库
private BlogTitleIdDTO analysisAndInsertMdFile(Parser parser, HtmlRenderer renderer, ZipEntry entry, InputStreamReader reader, int bloggerId) throws IOException {
if (!entry.getName().endsWith(".md")) return null;
// 文件名作为标题
String title = entry.getName().replace(".md", "");
StringBuilder b = new StringBuilder((int) entry.getSize());
int len = 0;
char[] buff = new char[1024];
while ((len = reader.read(buff)) > 0) {
b.append(buff, 0, len);
}
// reader.close();
// zip 文件关闭由 insertBlogPatch 方法 finally 块中的 zipFile.close() 统一关闭。
// 博文内容
String mdContent = b.toString();
// 对应的 html 内容
Document document = parser.parse(mdContent);
String htmlContent = renderer.render(document);
// 摘要
String firReg = htmlContent.replaceAll("<.*?>", ""); // 避免 subString 使有遗留的 html 标签,这样前端显示时可能会出错
String tmpStr = firReg.length() > 500 ? firReg.substring(0, 500) : firReg;
String aftReg = tmpStr.replaceAll("\\n", "");
String summary = aftReg.length() > 200 ? aftReg.substring(0, 200) : aftReg;
// 调用博文新增方法:插入数据到数据库,创建 Lucene 索引 ...
int id = insertBlog(bloggerId, null, null, PUBLIC, title, htmlContent, mdContent, summary, null, false);
if (id < 0) return null;
BlogTitleIdDTO node = new BlogTitleIdDTO();
node.setTitle(title);
node.setId(id);
return node;
}
思路通过注释能够很好的说明,也就不再使用过多语言描述。
Controller 层代码源文件:BloggerBlogController.java
Service 层代码源文件:BloggerBlogServiceImpl.java