zookeeper深入了解体系结构
1.zookeeper的体系结构图如下所示:(图来自百度)
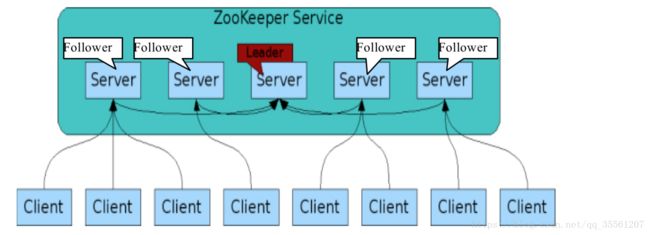 客户端可以连接到每个server,每个server的数据是完全相同的,每个follwer和leader都有连接(如图所示),接受leader的数据更新操作(并将leader数据更新的数据同步到follower中去),至此来实现数据同步和一致性。
客户端可以连接到每个server,每个server的数据是完全相同的,每个follwer和leader都有连接(如图所示),接受leader的数据更新操作(并将leader数据更新的数据同步到follower中去),至此来实现数据同步和一致性。
Server记录事务日志和快照(虚拟机中名词,可理解为将当前计算机所在状态)到持久存储的过程,过半数的server可用,则整体服务就可以使用,leader只有一个,宕机之后,就会重新选择出一个leader。
zookeeper的基本特性如下所示:
(1)强一致性:client无论是连接到哪个server,展示给他的都是同一个视图,这是zookeeper最重要的功能,此处请参考(一致性算法,zookeeper使用的是其中一种一致性算法)
(2)可靠性:具有简单的,健壮,良好的性能,如果消息Message被一台服务器接收,那么就会被所有的服务器进行接收(每个服务器都和leader做了数据同步,,而zookeeper是使用一致性来保持数据的一致性,以及维护视图的特性,由此来进行理解。)(3)实时性;zookeeper在保证客户端在一个时间间隔范围里面内获得服务器的更新信息。或者服务器失效的信息,考虑到网络的问题,导致数据的实时性问题,如因为TCP以及udpt通信,导致丢包的情况,因此将数据的这种网络问题导致的数据无法进行实时更新问题也考虑进去的话,在服务端获取最新数据之前,应该进行的操作是Sync进行实现。
(4)等待无关(wait-free),慢的或者失效的client不能干预快速的client的请求,使得每个client都能有效地等待。(快的进行数据传递过程中,一旦服务器进行了接受,那么client数据往服务器请求数据的过程中)数据将会进行视图同步到客户端进行相关的情况。
(5)原子性:这里可是同时通过事务中的原子性来理解,是一种线程安全,以及数据安全性的一个确定。
数据要么更新失败,要么更新成功,没有中间状态,对于数据库比较了解的人,应该明白,也就是不会去产生脏数据,也就是垃圾性数据,进行相关的脏数据。
(6)顺序性:包括全局的数据以及偏序的数据两种,可以理解为函数中的(全局变量和局部变量)。
Zookeeper的数据模型图如下所示:
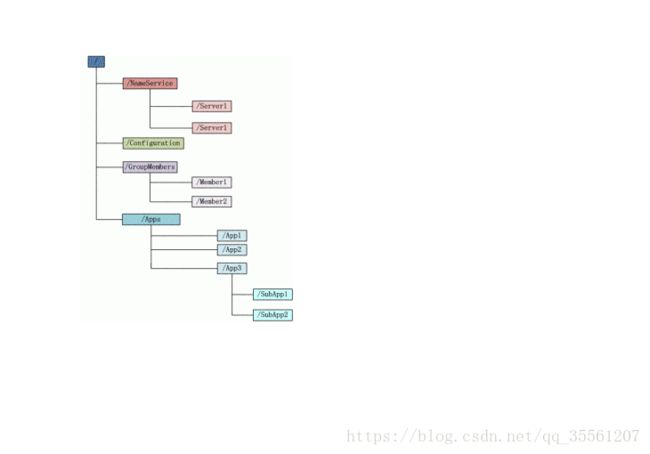
zookeeper的数据模型基于树型结构的命名空间,与文件系统类似,如图:
数据存储模型的几个特点是:
1.该数据模型是分布式的,数据节点被称为znode,客户端可以连接到每个Server,每个server的数据是完全一致的,这里也就是体现到了数据的一致性的问题。
server的数据之间数据也是一致的,不仅仅是client从服务器端获取的数据是一致性的。
2.Znode的时效性问题,Znode既可以是临时节点也可以是持久性的节点,一旦znode的客户端和服务器端失去联系,也就是znode维护的client和sever失去联系,那么znode也就是立即删除,此时数据出现断开,同时也可以这样理解,也就是,client不再向server端进行数据交互和进行相关的通信,zookeeper的客户端和服务端通信时采取长连接(
长连接,指在一个连接上可以连续发送多个数据包,在连接保持期间,如果没有数据包发送,需要双方发链路检测包。
)的方式,这样做的目的是提高server和client之间进行交互的速率,减少因为网络的问题导致的数据无法进行数据的同步问题,每个client和sever进行交互的时候,使用心跳机制来保持连接(这里和hadoop的原理是类似的,扩展,心跳是一种定时进行数据状态,数据是否存在的一个定时遍历,详细可以通过时间片轮转算法来进行理解这个过程,和nginx来定时的去访问底下的服务器机制是十分类似的,大数据概念里面叫做心跳,)同时这个状态也可以称为session(事务的连接,存在原子性的特性),
如果znode是一个临时的节点(临时server和client进行连接的一个znode)那么当session失效的时候,那么znode也就删除了,失去原先的效果了。
Znode核心特性可以实现的功能有集中管理,集群管理,分布式锁。