Web of science以及中国知网学术论文爬取教程(附代码)
我是目录
- Web of Science
- 中国知网
最近又做了爬取知网以及web of science的工作,因此记录在这里。(话说这几天简直是要类吐血,之前看的论文累得全忘光光了,还得捡一下)
本期教程以关键词摘要的爬取为例。
Web of Science
首先爬这个你得需要有WOS的账号,不然就可以放弃了,试试去爬开源的学术资源,比如Aminer,谷歌学术啥的吧。因为疫情在家,使用必须输入学校的账号才可以登录,因此在爬取的时候Keep alive并且保存Cookie很重要。当然,爬数据的时候也不能漫无目的地爬,因此需要整一个检索的公式。我就以高级检索为例子了。
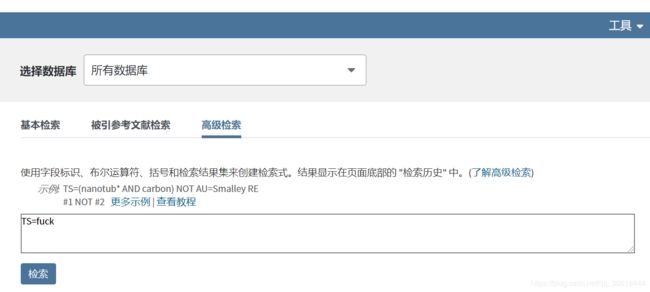
然后点击检索,发现居然还有几百条返回结果????fxxk这个词真的适合学术论文吗?点击那个362的< a>标签:


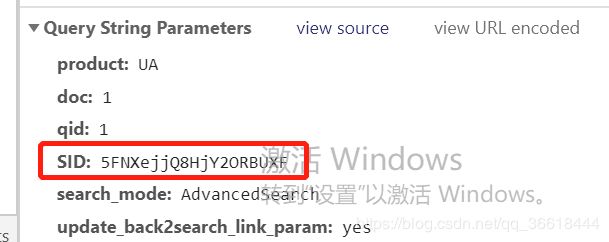
由于WOS是不通过更改状态栏的URL进行的js请求,因此还需要解析网络情求,在浏览器里右键->检查就可以了(我用的是Google),这样request Header里的东西就是你需要在爬虫里填充的了:

然后再往下翻翻,能看到一堆请求参数(激活windows请忽略哈)。其中最重要的是SID参数,这个东西在cookies里也可以见到,可能是Search ID的缩写?俺也不太清楚。
好接下来就是紧张刺激的爬虫编写阶段了。其中几个变量需要额外注意:params,这个就是上个图中params的字典。Header,实际操作中发现Reference并没有啥用,就注释掉了,注意Cookies改成当前的。然后page是返回结果的分页数,每页默认10条论文数据。然后就可以使用bs4解析获取到的页面了。当然,有时候WOS会封禁你的IP,导致大量的数据爬去失败,所以尽量做一个能接着上次爬的程序:
def get_papers(pages, Ts, wf):
docs = range(1,11)
for page in [pages]:
for doc in docs:
try:
params = {'product': 'UA',
'search_mode': 'AdvancedSearch',
'qid': '1',
'SID': '6BEGcONYvx9UwsFqcjJ',
'page': page,
'doc': doc+10*page}
headers = {'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
# 'Referer': 'https://s.jlu.edu.cn/http/77726476706e69737468656265737421f1e7518f69276d52710e82a297422f30a0c6fa320a29ae/summary.do?product=UA&doc=1&qid=1&SID=5DBpNAh2XO1RiRuktE5&search_mode=AdvancedSearch&update_back2search_link_param=yes',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'remember_token=cGomHwzZHlXaNRRaojffCTmArGaQSybzZmZmgbwMRHwdDFZcsgQLPPfyvXWGGoWX; wengine__ticket=b96dc49f3eda90d9; refresh=0'}
url = 'https://s.jlu.edu.cn/http/77726476706e69737468656265737421f1e7518f69276d52710e82a297422f30a0c6fa320a29ae/full_record.do'
htm1 = requests.get(url, headers=headers, params=params, verify=False)
soup = BeautifulSoup(htm1.text, 'html.parser')
title = soup.find('div', attrs={'class':'title'}).text
if title not in Ts: # 已经爬取过的文章跳过
abstract = soup.find('div', text='摘要').find_next().text
keywords = soup.find('div', text='关键词').find_next().text
journal = soup.find('span', attrs={'class':'hitHilite'}).text
print(page, doc, title, sep=' ')
wf.write("" .join([title, abstract, keywords, journal]).replace('\n','')+'\n')
except:
traceback.print_exc()
time.sleep(3)
continue
get_paper是获取论文标题摘要和关键词的数据,并要写入txt文件。为了防止因为网络原因中断,所以除了pages参数外,还有Ts(所有已经爬取的论文数),wf需要写入的文件,在写的时候判断是否已经爬过这个数据了,如果爬过就跳过。
然后接下来得读取Ts呀,很简单的读取方法:
def check_titles(): # 判断当前爬取的论文是否已经存在,存在则跳过
Ts = []
files = os.listdir('Results')
for file in files:
with open('Results/'+file, 'r', encoding='utf-8') as rf:
Ts.extend([line.strip().split('' )[0] for line in rf.readlines()])
print('已经爬取:', len(Ts))
return Ts
然后为了加速,做了一个简单的多线程,但是线程太多就会被封IP,大家自己调一调哦,封了IP等一会就好了(6个没啥问题吧)。其中,每个线程调用一个不同的get_papers方法,爬取不同page的数据。
if __name__ == '__main__':
id = 7
# genarate_command(id)
Ts = check_titles()
threads = [] # 存放多线程
all_pages = int(2933/10) + 1
wf = open('Results/{}.txt'.format('journal'+str(id+1)), 'a', encoding='utf-8')
for i in range(100, all_pages):
threads.append(threading.Thread(target=get_papers, args=(i,Ts,wf)))
num = 0
while num <= len(threads):
if threading.activeCount() <= 6: # 最大线程数小于6
threads[num].start()
num += 1
else:
time.sleep(10) # 否则我休眠一百秒去执行线程
当然,实在是经常被封IP还可以用下一个策略:Selenium。这个就是实打实的浏览器访问,因此不会被封,但是十分之慢…因此就不介绍了
中国知网
我贼喜欢中国知网,因为数据太好爬了。但是大家爬数据要秉着学术研究的目的,别做别的,爬虫学得好,牢饭吃到饱。
这次我以期刊为范围,进行期刊的爬取。比如“管理世界”,知网中的期刊对应了不同的缩写,比如管理世界就是“GLSJ”,而且显示地出现在URL里了,也不用我额外去解析:http://navi.cnki.net/KNavi/JournalDetail?pcode=CJFD&pykm=GLSJ
然后我在期刊内检索关键词“创新创业”:

然后还是找到response对应的请求头,咱一个一个解析参数:

| 参数 | 含义 |
|---|---|
| pcode | 我也不是很清楚啊哈哈 |
| baseId | 期刊名字 |
| where | 检索字段,应该表示主题 |
| searchText | 检索框内输入的关键词 |
| orderby | RT,看起来是根据相关性的排序 |
| ordertype | DESC,熟悉MySQL的同学应该都知道,倒序排序嘛,ASC正序 |
| pageIndex | 0,检索返回结果的第一页 |
| pageSize | 50,每页50条记录 |
其中,%28SU%25%27%7B0%7D%27%29应该是被编码的检索字段,随便找个在线解码器看看,这个SU应该是知网中表示主题的代码;%E5%88%9B%E6%96%B0%E5%88%9B%E4%B8%9A解码就是对应创新创业这个检索词了。

然后,再看看request URL:

这样完全就可以根据参数自己编写请求头了。接下来还是直接看代码。首先,我要抓取检索结果中的所有论文的URL,因为知网的检索结果论文每个都有固定的id,不像是WOS返回的连接是动态生成的…把每个结果paper的link存起来:
header={'Connection':'Keep-Alive',
'Accept':'text/html,*/*',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
# 'Referer':'http://navi.cnki.net/KNavi/JournalDetail?pcode=CJFD&pykm=GLSJ',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
# 'Cookie': 'Ecp_ClientId=2200210174601303834; RsPerPage=20; cnkiUserKey=814a1a67-effa-b5af-9db6-3b38894d2622; Ecp_IpLoginFail=200602125.223.253.2; ASP.NET_SessionId=qudz13gpalld1xpiq2antz3w; SID_kns=123105; SID_klogin=125143; SID_crrs=125132; KNS_SortType=; _pk_ref=%5B%22%22%2C%22%22%2C1591103026%2C%22https%3A%2F%2Fwww.cnki.net%2F%22%5D; _pk_ses=*; SID_krsnew=125134; SID_kns_new=kns123117'
}
params = {
'pcode': 'CJFD',
'baseId': 'GLSJ', # 需要根据期刊修改
'where': '%28SU%25%27%7B0%7D%27%29', # 不要修改
'searchText': '创业研究', # 根据检索关键词修改
'condition':'',
'orderby': 'RT',
'ordertype': 'DESC',
'scope':'',
'pageIndex': 0, # 在遍历的时候修改,0表示第一页
'pageSize': 50 #
}
def get_search_page_link():
with open('./links.txt', 'a', encoding='utf-8') as wf:
for journal in journal_code:
print(journal)
for keyword in keywords:
print(keyword)
params['baseId'] = journal
params['searchText'] = keyword
path = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleDataXsltByInternalSearch'
print(path)
htm1 = requests.get(path, headers=header, params=params)
soup = BeautifulSoup(htm1.text, 'html.parser')
links = soup.find_all('td', attrs={'class':'name'})
for link in links:
href = link.find('a')
if href:
href = href['href']
wf.write(href.strip()+'\n')
wf.flush()
print(href.strip())
time.sleep(0.5)
time.sleep(2)
get_search_page_link()
可以看看paper的href:Common/RedirectPage?sfield=FN&dbCode=CJFD&fileName=GLSJ202005008&tableName=CJFDAUTO&url=
其中,GLSJ202005008就是论文的id咯。然后我们把这个id替换到具体的检索论文的URL中:
https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&fileName=GLSJ202005008
就可以跳转到论文的详细信息页了。get_papers用于获取论文的具体信息,注意写入文件的时候需要flush,不然数据就在缓冲区中并没有真正写入。
def get_papers():
file = open('./papers.txt', 'a', encoding='utf-8')
with open('./links.txt', 'r', encoding='utf-8') as rf:
for line in rf.readlines():
name = re.findall('&fileName=.+?&', line.strip())[0]
url = 'https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD'+name[:-1]
print(url)
htm1 = requests.get(url)
soup = BeautifulSoup(htm1.text, 'html.parser')
title = soup.find('title').text.strip()
abstract = soup.find('span', attrs={'id':'ChDivSummary'})
if abstract is None:
abstract = ''
else:
abstract = abstract.text.strip()
keyword = soup.find('label', attrs={'id':'catalog_KEYWORD'})
ks = []
if keyword is not None:
keyword = keyword.parent.find_all('a')
for word in keyword:
ks.append(word.text.strip())
ks = ''.join(ks)
else:
ks = "" # 没有关键词
print(title, url)
file.write('' .join([title,abstract,ks])+'\n')
file.flush()
time.sleep(0.5)
file.close()
get_papers()
看看结果:
