第 9 讲:谈谈 Vector、ArrayList、LinkedList 的区别
共同点:
Hashtable、HashMap、TreeMap 都是最常见的一些 Map 实现,是以键值对的形式存储和操作数据的容器类型。
Hashtable:
- 元素特性
早期 Java 类库提供的一个哈希表实现,本身是同步的,不支持 null 键和值,无序,由于同步导致的性能开销,所以已经很少被推荐使用。
- 初始化与增长方式
HashTable在不指定容量的情况下的默认容量为11,且不要求底层数组的容量一定要为2的整数次幂。
扩容时:Hashtable 将容量变为原来的 2 倍加 1
HashMap:
- 元素特性
应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值(只能有一个 key为 null 的键值对,但是允许有多个值为 null 的键值对),无序。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选。比如,实现一个用户 ID 和用户信息对应的运行时存储结构。
如果需要同步
1、可以用 Collections 的 synchronizedMap 方法;
2、使用 ConcurrentHashMap 类,相较于 HashTable 锁住的是对象整体, ConcurrentHashMap 基于 lock 实现锁分段技术。首先将 Map 存放的数据分成一段一段的存储方式,然后给每一段数据分配一把锁,当一个线程占用锁访问其中一个段的数据时,其他段的数据也能被其他线程访问。ConcurrentHashMap 不仅保证了多线程运行环境下的数据访问安全性,而且性能上有长足的提升。
- 初始化与增长方式
HashMap 默认容量为 16,且要求容量一定为 2 的整数次幂
扩容时:HashMap 扩容将容量变为原来的 2 倍
- 一段话HashMap
HashMap 基于哈希思想,实现对数据的读写。当我们将键值对传递给 put() 方法时,它调用键对象的 hashCode() 方法来计算hashcode,然后找到 bucket 位置来储存值对象。当获取对象时,通过键对象的 equals() 方法找到正确的键值对,然后返回值对象。HashMap 使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的 hashcode 相同时,它们会储存在同一个 bucket 位置的链表中,可通过键对象的 equals() 方法用来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),链表就会被改造为树形结构。
TreeMap:
基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
TreeMap 是利用红黑树来实现的(树中的每个节点的值,都会大于或等于它的左子树种的所有节点的值,并且小于或等于它的右子树中的所有节点的值),实现了 SortMap 接口,能够对保存的记录根据键进行排序。所以一般需要排序的情况下是选择 TreeMap 来进行,默认为升序排序方式(深度优先搜索),可自定义实现 Comparator 接口实现排序方式。
知识扩展:
Map 整体结构
- 首先,我们先对 Map 相关类型有个整体了解,Map 虽然通常被包括在 Java 集合框架里,但是其本身并不是狭义上的集合类型(Collection),具体你可以参考下面这个简单类图。

- Hashtable 比较特别,作为类似 Vector、Stack 的早期集合相关类型,它是扩展了 Dictionary 类的,类结构上与 HashMap 之类明显不同。
- HashMap 等其他 Map 实现则是都扩展了 AbstractMap,里面包含了通用方法抽象。不同 Map 的用途,从类图结构就能体现出来,设计目的已经体现在不同接口上。
- 大部分使用 Map 的场景,通常就是放入、访问或者删除,而对顺序没有特别要求,HashMap 在这种情况下基本是最好的选择。HashMap 的性能表现非常依赖于哈希码的有效性,请务必掌握 hashCode 和 equals 的一些基本约定:
1、equals 相等,hashCode 一定要相等。
2、重写了 hashCode 也要重写 equals。
3、hashCode 需要保持一致性,状态改变返回的哈希值仍然要一致。
4、equals 的对称、反射、传递等特性。
HashMap 源码分析
- HashMap 内部实现基本点分析。
它可以看作是数组(Node
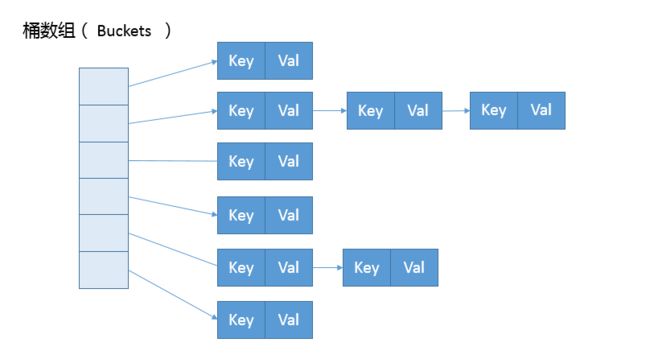
从非拷贝构造函数的实现来看,这个表格(数组)似乎并没有在最初就初始化好,仅仅设置了一些初始值而已。
public HashMap(int initialCapacity, float loadFactor){
// ...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
- 容量(capacity)和负载系数(load factor)。
1、容量和负载系数决定了可用的桶的数量,空桶太多会浪费空间,如果使用的太满则会严重影响操作的性能。极端情况下,假设只有一个桶,那么它就退化成了链表,完全不能提供所谓常数时间存的性能。
2、如果能够知道 HashMap 要存取的键值对数量,可以考虑预先设置合适的容量大小。具体数值我们可以根据扩容发生的条件来做简单预估,它需要符合计算条件:负载因子 * 容量 > 元素数量,
3、所以,预先设置的容量需要满足,大于“预估元素数量 / 负载因子”,同时它是 2 的幂数。
- 树化 。
HashMap 的树化本质上是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。