此文章是记录自己对于网站爬取的部分知识总结。
对于比较小的需求,直接使用request即可。大的需求使用scrapy较合适。
scrapy的工作流程:
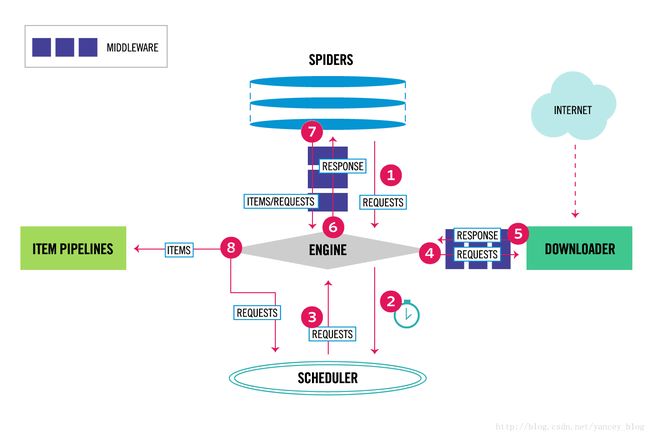
组件
ENGINE
是scrapy的核心,负责调动数据的流向,可以理解为控制中心,根据不同的动作触发不同的事件响应。
SCHEDULER(调度器)
调度器哦负责处理引擎发过来的request,后面引擎需要再提供给引擎。
DOWNLOADER(下载器)
拿着接收到的url,根据指定的规则 获取页面数据,可以看到根据箭头方向,其将下载到的数据提供给了引擎,引擎再返回给spider。
SPIDERS
spider是需要用户自己手动编写的,每个spider负责处理一些特定的网站(一般处理一个网站)。
ITEM PIPELINE
item类似与Java 中的javabean 给要爬取的数据编写一些能够方便存储的数据类型,比如,我们要爬去的数据中有 标题之类的 就可以定义一个title 进行保存,数据库中最好保持一致。另外使用Django的表单更方便。处理,清洗数据。
pipeline则是item和数据库之间打交道的管道,在这里一般是将数据存入数据库操作,或者编写twisted之类的异步操作。
其他的一些组件暂不作介绍。
首先看文件组织图:

第一步:
安装Scrapy 1.5.0 安装教程自行搜索。
打开命令行:
$ scrapy startproject ArticleSpider
$ cd ArticleSpider
$ scrapy genspider -t crawl lagou www.lagou.com # 这里使用crawl模板 也可以去掉 -t crawl 推荐使用
之后使用pycharm 打开项目,spider目录下就有了lagou文件,这里是我们编写针对网站爬取规则的主要地方。
# -*- coding: utf-8 -*-
from scrapy.linkextractorsimport LinkExtractor
from scrapy.spidersimport CrawlSpider, Rule
from itemsimport LagouJobItem,LagouJobItemLoader
from utils.commonimport *
from datetimeimport datetime
class LagouSpider(CrawlSpider):
name ='lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/']
rules = ()
# 定义爬取允许链接 allow允许使用正则表达式 即我们要爬取那些网站
# 针对工作页面 回调函数 parse_job
Rule(LinkExtractor(allow=(r'zhaopin/.*',)), follow=True),
Rule(LinkExtractor(allow=(r'gongsi/j\d+.html',)), follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_job', follow=True),
def parse_job(self, response):
# 这里主要是编写一些 抓取数据的规则
item_loader = LagouJobItemLoader(item=LagouJobItem(), response=response)
item_loader.add_css('title', '.job-name::attr(title)')
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id", get_md5(response.url))
item_loader.add_css('salary', '.salary::text')
job_item = item_loader.load_item()
return job_item # 数据返回给item pipelin进行处理
item使用自定义的LagouJobItem() 位于item文件下。
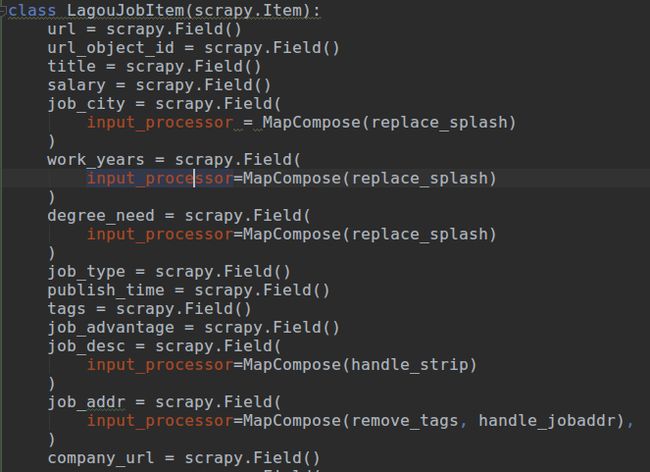
input_processor = MapCompose(replace_splash)的意思是 input_processor表示输入数据预处理 MapCompose() 调用方法进行处理输入数据,输入方法名即可 可以输入多个方法。
LagouJobItemLoader继承自ItemLoader
由于在编写的规则提取数据基本为数组 需要的数据也基本上都是第一个 即取数组第一位
所以可以这样写:
class LagouJobItemLoader(ItemLoader):
default_output_processor = TakeFirst()# 针对item_loader默认取第一个
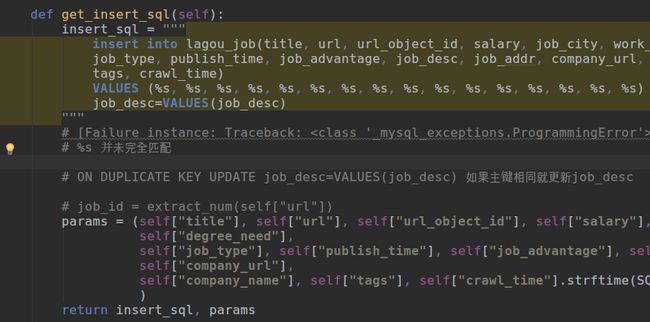
LagouJobItem下编写 函数 用以写数据库插入语句。
然后数据return insert_sql, params



上面 写法基本是固定的 可以自行改动 最后面的插入语句 便可以自动启用twisted。
使用异步操作是因为 用时候爬虫爬取到数据插入数据库速度过快,导致拥塞,所以可以使用异步方式解决拥塞问题。
middleware.py 暂未用到 之前在这里写过动态更换ip,暂时可以不用,通过IP代理并不见得速度更快,只是能够很好的隐藏自己的IP不至于爬取速率过快而被禁掉。
字数有限,后面补充githup地址。