Python正则表达式入门详解(字符串前有个r,在第六章标题下)文末福利视频讲解
正则表达式(有疑问请留言,及时回复)
一:首先了解什么是正则表达式,当我们注册邮箱时,会提示输入手机号,当我们输入如下所示的内容后,会提示输入正确的手机号
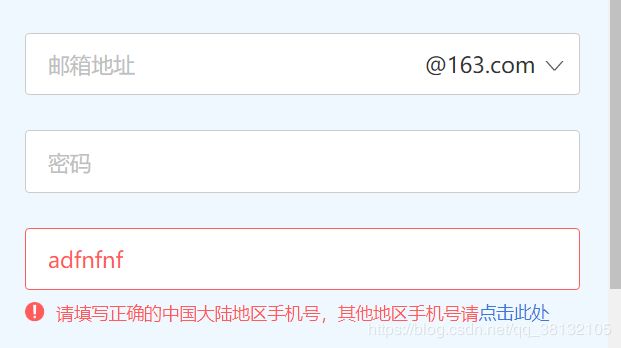
那么,如何知道输入的内容(字符串)不是正确的手机号呢?服务器有一个校验手机号的规则,如手机号必须11位数字,不能包含字母的规则,如何把这个规则描述出来,即让计算机能读懂这个规则,这种描述的语法就是正则表达式。正则表达式就是描述了一个规则的表达式。
例如,linux中的命令 ls *.txt 是列出当前目录下的所有的以 .txt 结尾的文件,这个星号描述的就是一种规则:任意文件名,只要是以 .txt 结尾的文件都要列出。
二:正则表达式又称正规表示式等,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换哪些匹配某个模式的文本。
一:re模块
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块:re
二:re模块的使用过程
re.match 是用来进行正则匹配检查的方法,若字符串匹配正则表达式,则match方法返回匹配对象(Match Object),否则返回None。
匹配对象Match Object具有group方法,用来返回字符串的匹配部分。
# 导入re模块
import re
# 使用match方法进行匹配操作
# 应用到手机号的情景上,括号内的参数“正则表达式”就是服务器对于手机号的规则
# 参数“要匹配的字符串”就是输入框中你输入的内容
result = re.match(正则表达式, 要匹配的字符串)
# 如果要匹配的字符串满足正则表达式,则match方法返回匹配对象(Match Object),赋给对象变量result,由对象变量 result 调用group方法
result.group()
三:练习使用re模块
import re
# pattern是模式,规则的意思,定义正则表达式规则
# 定义规则是一个普通的字符串
pattern = "itcast"
# 定义一个要匹配规则的字符串
s = "itheima"
# 调用match方法,用变量result接收
result = re.match(pattern, s)
print(result)
# 因为不匹配,所以输出None
import re
pattern = "itcast"
s = "itcast"
result = re.match(pattern, s)
# result.group()返回符合规则的字符串
print(result.group())
# 输出 itcast
import re
result = re.match("itcast", "itcastitheima")
# result.group() 返回符合规则的字符串,但 itcastitheima 后边有多处的字母,我们也称这样的情况为符合规则的,只不过输出的是 itcast
print(result.group())
# 输出 itcast
re模块的match方法也可以通过下方的代码来实现
"itcastitheima".startswith("itcast")
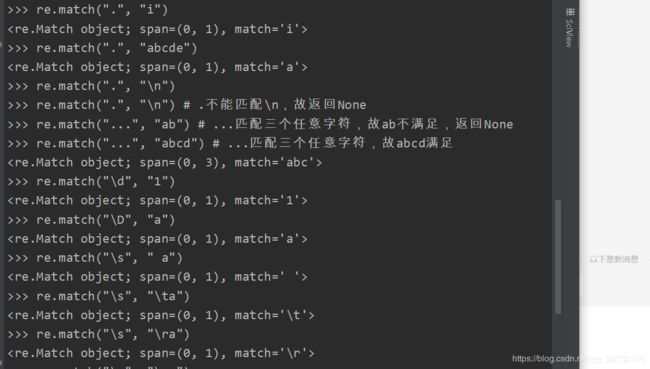
四:表示字符
| 字符 | 功能 |
|---|---|
| . | 匹配任意一个字符(除了\n) |
| [] | 匹配[]中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字(若是匹配中文,用\D) |
| \s | 匹配空白,即空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、… |
| \W | 匹配非单词字符 |
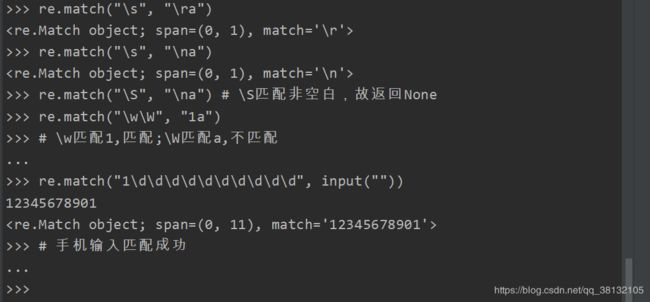

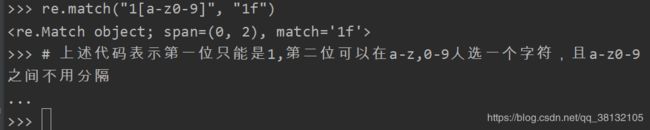

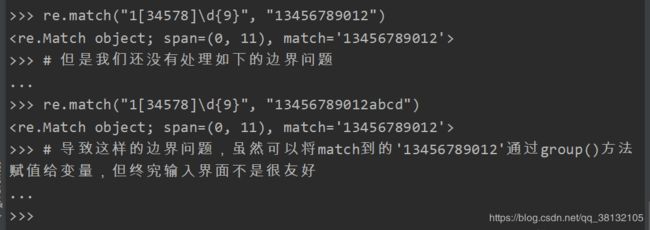
注意:手机号的 re.match(“1[34578]\d\d\d\d\d\d\d\d\d”, “13456789012”)
中的\d重复了九次,那么有没有一种可以表示数量的字符呢。
五:表示数量
| 字符 | 功能 |
|---|---|
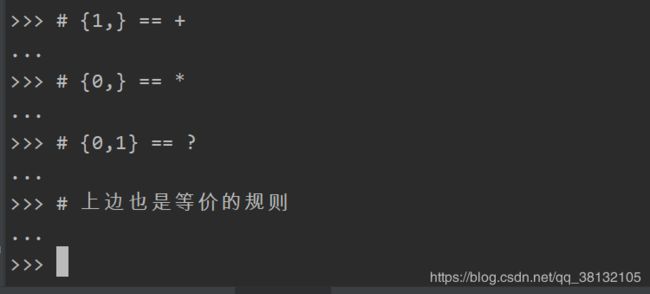
| * | 匹配前一个字符出现0次或者无限次(指的是无穷多个数字,不是11111…出现即重复1无限次) |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,} | 匹配前一个字符至少出现m次 |
| m,n} | 匹配前一个字符出现从m到n次 |
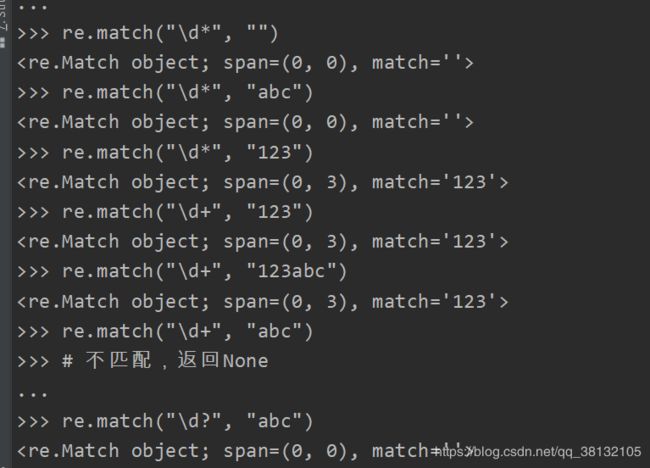
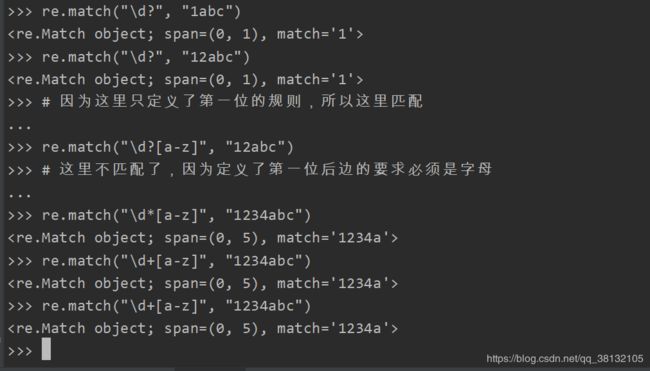
可以用{m}的方式来规定具体重复的次数:
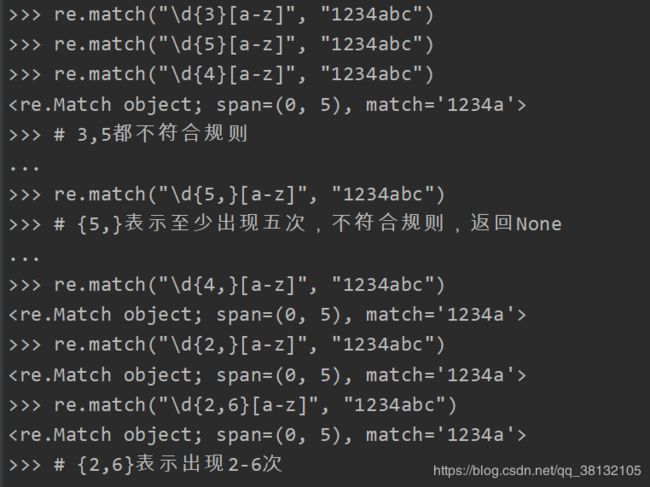
到现在为止,我们已经简化了输入手机号的规则:
六:原始字符串(以后所有的正则表达式的规则都使用 r)
当字符串中包含转义字符时,要匹配规则的转义字符就要加倍:可以使用原始字符串的 r
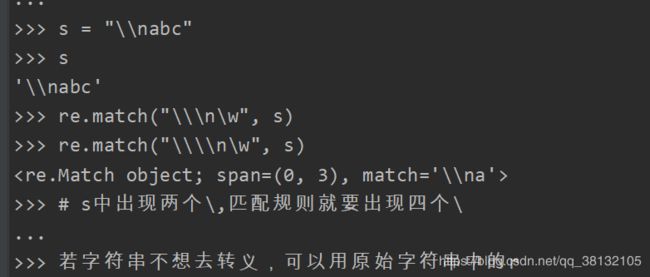
加上 r,原样输出字符串:

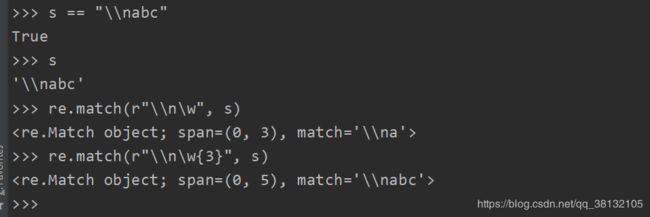
注意:r 只是使\n、\t等转义字符失去作用,并不会将 \w、\d等表示字符失去作用
七:表示边界
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头(在match方法中体现不出来,因为match本身就是从左向右匹配) |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
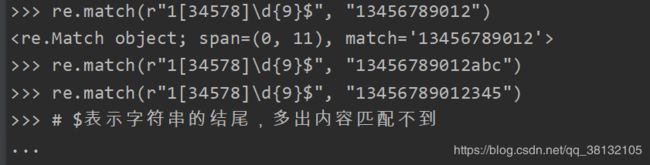
注意:^和$在linux中有类似的应用,在vi编辑文件时,不进入编辑模式,只是让光标跳到尾部或者首部,首部用^,尾部用$
一般我们在用正则表达式规则时,要用^开头和$结尾。

介绍\b:
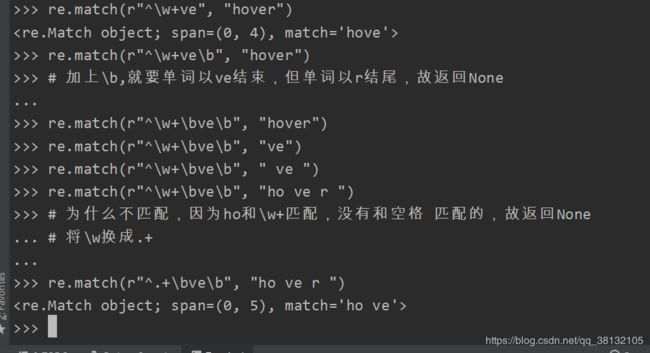
介绍\B:

八:匹配分组
| 字符 | 功能 |
|---|---|
| 匹配左右任意一个表达式 | |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| ?P |
给分组起别名,用在分组()中,不单独为?P |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
示例一:匹配出0-100之间的数字
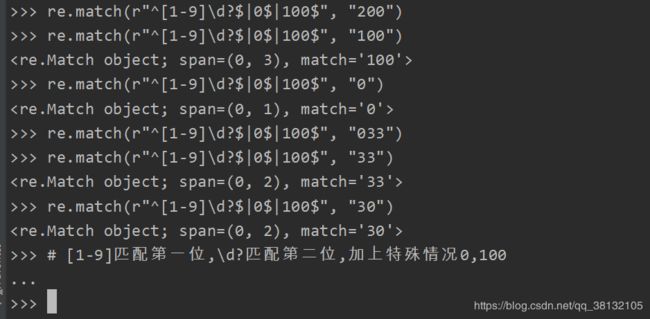
改进一下:

二:从字符串中提取特定的部分,比如从路径/book/med/inner中提取//之间的字符串是什么。或者在网页从服务器端传送给客户端的过程中,客户端的socket.recv("
匹配分组
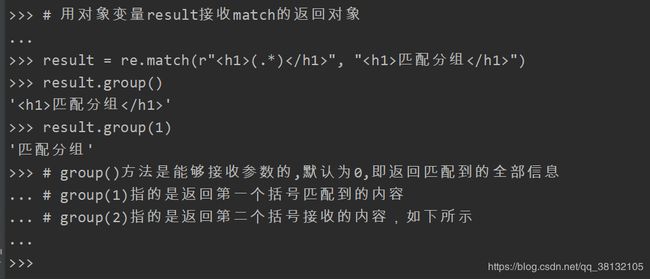
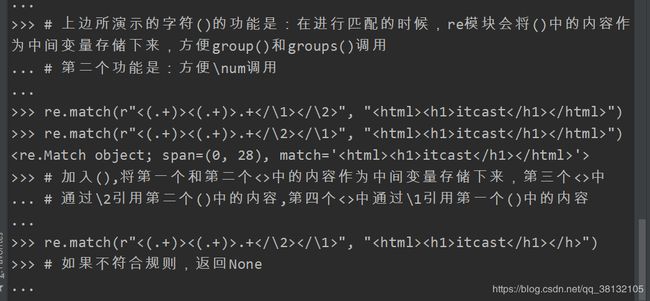
其他字符"),接收了一个字符串,字符串中包含一级标题"匹配分组"的样式信息,但我们有时(比如做爬虫的时候),就是想要爬取一级标题里所包括的内容是什么,一个网页里可能有多个标题,定义一级标题的方法就是不会变,会变得是标题内容,所以我们要用正则表达式,将中的标题内容接收下来。(ab)的作用:字符()的功能是:在进行匹配的时候,re模块会将()中的内容作
为中间变量存储下来,方便group()和groups()调用
第二个功能是:方便\num调用(后边会讲到)

group()的参数:
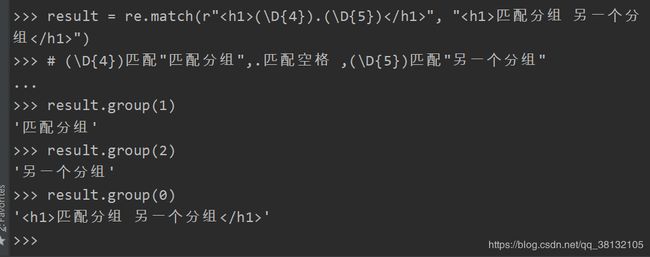
还有一个groups()方法,groups方法返回一个元组,元组的内容是:所有的()都展示出来。
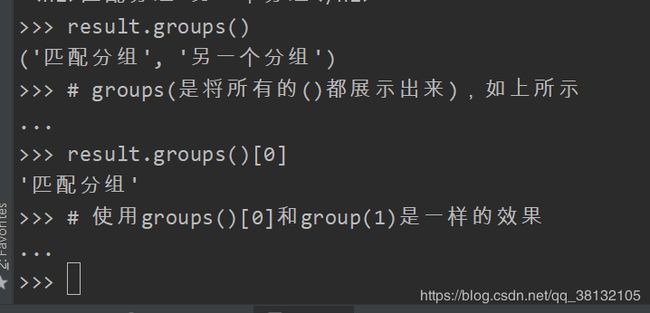
上面的group()和groups()的功能是将匹配到的内容提取出来。下边介绍一种情况:只需要匹配即可,不需要提取出匹配到的内容。
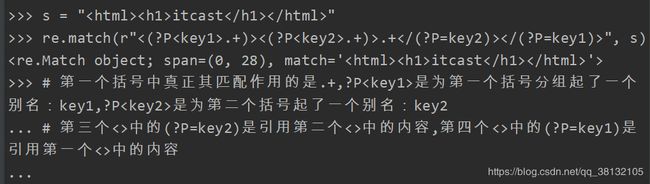
如:s = “
itcast
”现在规则如下:首先四个<>括起来的内容,而且第一个<>中的内容和第四个相同(除去/的内容),第二个和第三个<>的内容相同才符合规则,则match()内的规则如何定义:
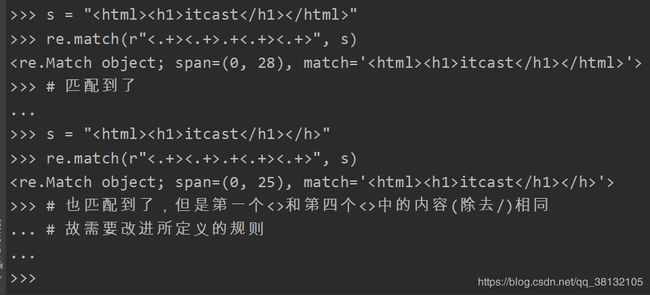
下面就用到了匹配分组中的字符(ab)和\num:
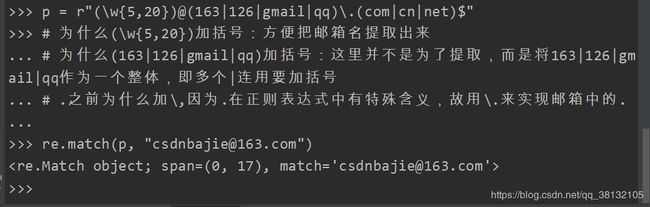
示例二:定义一个邮箱格式的规则
?P
如果我们使用到的字符()太多,我们不可能记住哪一个\num对应哪一个(),这时我们需要用到?P
九:re模块的高级用法
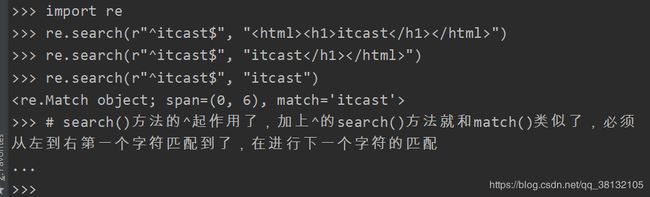
search
re模块的search()方法,search(正则表达式, 要匹配的参数)
与match()方法不同,match()默认从左向右匹配,第一个字符满足规则,接着匹配下一个字符。但seach()方法只要要匹配的参数中,有满足正则表达式的字符或字符串就行。如下图search()的用法:

的字符串,就停止匹配。
findall
返回所有匹配到的结果:(对比search只返回第一个匹配到的结果)

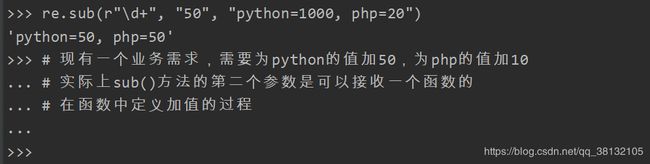
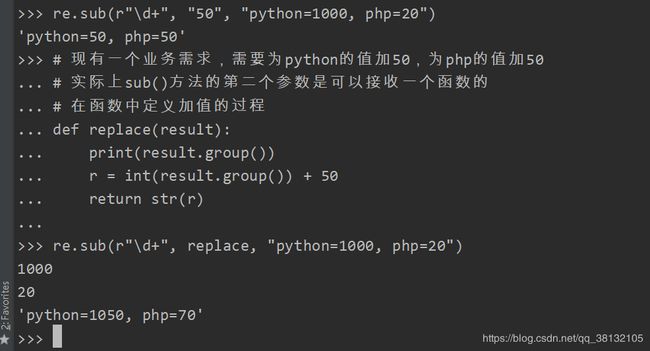
sub
将匹配到的数据进行批量替换
re.sub(匹配规则, 替换的内容, 进行匹配的字符串)

补一个知识点:python中""" “”“的三对”"可以当作多行注释,另一个作用是原样保留字符串的完整格式,详见视频12_re的高级用法38:20处。
sub()方法例题:



split
split()方法根据匹配及进行切割字符串,并返回一个列表

注意上方代码()有无输出的区别。
十:贪婪模式
python里的数量词默认是贪婪的:
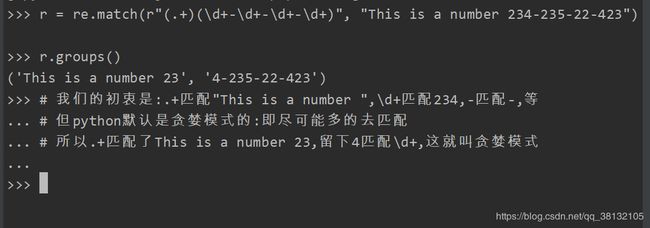
关闭贪婪模式:用非贪婪操作符?, 这个操作符可以用在 . + ? 的后面,要求正则匹配的越少越好。
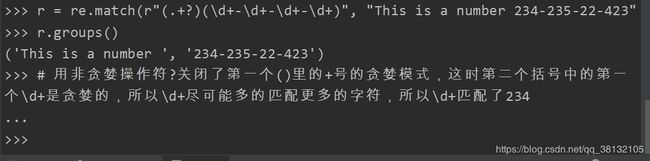

提取出图片的链接:
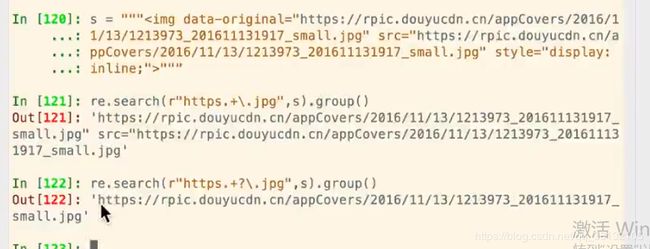
不用?又会进入贪婪模式。
例题:提取网址http://www.interoem.com/messageinfo.asp?id=35中的http://www/interoem.com
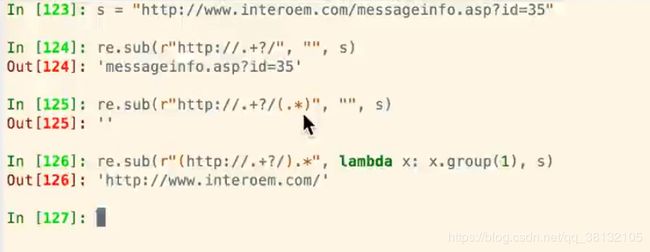
lambda表达式中的x是整个匹配规则的字符串,在这里就是http://www.interoem.com/messageinfo.asp?id=35整个字符串。
结尾:正则表达式到此结束,文末福利:视频讲解:https://www.bilibili.com/video/av42206116?
itcast-itheima