重启exploer.exe,以加载新的注册表信息先杀掉,再启动。重启exploer.exe,以加载新的注册表信息先杀掉,再启动。usingSystem.Diagnostics;process[]processes=process.getprocesses();//获取所有进程信息for(inti=0;i
【Java学习】从0到1掌握行为抽象与Lambda表达式:分区的深度解析与实战指南
墨瑾轩
一起学学Java【二】java学习开发语言
关注墨瑾轩,带你探索编程的奥秘!超萌技术攻略,轻松晋级编程高手技术宝库已备好,就等你来挖掘订阅墨瑾轩,智趣学习不孤单即刻启航,编程之旅更有趣从0到1掌握行为抽象与Lambda表达式:分区的深度解析与实战指南!引言在现代编程中,行为抽象和Lambda表达式是提高代码可读性和灵活性的重要工具。特别是在Java8引入的流(Stream)API和分区功能,更是让处理集合数据变得简单而优雅。今天,我们就一起
Python pywinauto PC端自动化测试核心代码封装类
《代码爱好者》
ChatGPTpython自动化测试框架pythonwindows
PythonpywinautoPC端自动化测试核心代码封装类以下是一个基于pywinauto的自动化测试核心代码封装类的完整代码实例,其中包含多个函数实例并加上中文注释方案1importpywinautoimporttimeclassPywinautoWrapper:def__init__(self,app_path):"""初始化函数,传入应用程序的路径"""self.app_path=app_
请简述vue2和vue3的区别
youhebuke225
vue面试题vue.js前端javascript
Vue2和Vue3作为Vue.js框架的两个主要版本,在多个方面存在显著的差异。以下是它们之间主要区别的详细概述:生命周期函数钩子:Vue2:包含了一系列的生命周期钩子函数,如beforeCreate、created、beforeMount等,这些函数在组件的不同生命周期阶段被调用。Vue3:对生命周期函数进行了调整,setup成为了新的入口点,代替了beforeCreate和created。同时
app架构
yx1166
IOS
一个好的app架构,能够经得起时间的检验,能让开发者愉快并非常自豪,拓展性非常好。架构是什么?一个app的架构,包含外在和内在2个方面。外在,指的是项目的目录。内在,指的是支撑app的基础运行库。具体包括但不限于:网络请求框架、日志输出框架、图片处理框架、地图、推送等基础必备的库。有了这些库,这个框架不一定是高效的,还要看框架的使用和搭建的成果,框架改动的次数。怎样设计一个好架构?架构,只有适合自
设计模式-桥接模式 C++
星星典典
设计模式c++桥接模式
一、简介1、什么是桥接模式桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。需要注意的是,这里面说的抽象化和实现化并不是指抽象基类和具体派生类的关系。即桥接模式的目的并不是把抽象基类和具体派生类进行分离。而是指把问题的具体特质分离出来,以关联的关系加入对象的实例化过程。可以结合下面的桥接
Pywinauto 快速学习指南
口_天_光健
microsoftpythonwindows自动化
Pywinauto技术指南一、基础概念(一)控件(Widgets)在Windows应用程序中,控件是用户界面的基本组成部分,如按钮、文本框、下拉列表等。Pywinauto提供了方法来识别和操作这些控件。(二)应用程序(Applications)代表正在运行的Windows应用程序。可以使用Pywinauto启动、连接和操作应用程序。(三)窗口(Windows)应用程序中的窗口是用户与之交互的界面。
咱们继续学Java——高级篇 第二百五十五篇:之Java进阶之本地方法:Windows注册表访问代码的终极解读
一杯年华@编程空间
咱们继续学java高级篇mavenjava-eespringbootspringcloudhibernatetomcat
咱们继续学Java——高级篇第二百五十五篇:之Java进阶之本地方法:Windows注册表访问代码的终极解读在Java学习的道路上,我们不断追求代码理解的深度,每一次对复杂代码的终极解读都是成长的重要里程碑。我写这篇博客的目的,就是希望与大家一同深入剖析Java本地方法中访问Windows注册表的剩余关键代码,助力大家在Java与其他语言交互编程领域掌握最核心的技能。今天,我们将详细解读Win32
java语言中“导包”的解释
喵果森森
java编程学习日志javajvmservlet
在java编程过程中,常常使用一种功能,叫“导包”。关键字为import例如importjava.util.Scanner;importjava.util.Random;什么是导包?导包即导入包,通过import关键字将他人完善的代码导入自己的代码中。“他人完善的代码”是被封装成类和包的形式,导入包,并不会将他人的代码插入自己的代码里,只需将其对象实例化后使用即可。什么人写的代码都可以导入吗?Ja
Hibernate不是过时了么?SpringDataJpa又是什么?和Mybatis有什么区别?
芝士汉堡 ིྀིྀ
mybatishibernatespring
一、前言ps:大三下学期,拿到了一份实习。进入公司后发现用到的技术栈有SpringDataJpa\Hibernate,但对于持久层框架我只接触了Mybatis\Mybatis-Plus,所以就来学习一下SpringDataJpa。1.回顾MyBatis来自官方文档的介绍:MyBatis是一款优秀的持久层框架,它支持定制化SQL、存储过程以及高级映射。MyBatis避免了几乎所有的JDBC代码和手动
深度学习|表示学习|卷积神经网络|由参数共享引出的特征图|08
漂亮_大男孩
表示学习深度学习学习cnn
如是我闻:FeatureMap(特征图)的概念与ParameterSharing(参数共享)密切相关。换句话说,参数共享是生成FeatureMap的基础。FeatureMap是卷积操作的核心产物,而卷积操作的高效性正是由参数共享带来的。下面我们详细看一下FeatureMap和ParameterSharing之间的关系:1.什么是FeatureMap?定义:FeatureMap是卷积操作生成的输出结
23种设计模式-桥接(Bridge)设计模式
萨达大
软考中级-软件设计师设计模式javaC++桥接模式结构型设计模式软考软件设计师
文章目录一.什么是桥接设计模式?二.桥接模式的特点三.桥接模式的结构四.桥接模式的优缺点五.桥接模式的C++实现六.桥接模式的Java实现七.代码解析八.总结类图:桥接设计模式类图一.什么是桥接设计模式? 桥接模式(BridgePattern)是一种结构型设计模式,用于将抽象部分与实现部分分离,使它们可以独立地变化。通过桥接模式,抽象层和实现层之间的耦合度被降低,从而使系统具有更好的灵活性和可扩展
【数据结构】最有效的实现栈和队列的方式(C&C++语言版)
大名顶顶
数据结构数据结构c语言c++程序员计算机编程软件开发
在这个技术飞速发展的时代,掌握基础的数据结构知识是每个程序员必不可少的技能。本文将深入探讨栈和队列这两种线性数据结构,带你了解它们在实际编程中的应用以及如何用C/C++代码实现这些结构的核心操作。我们不仅讲解了栈的后进先出(LIFO)和队列的先进先出(FIFO)原理,还通过实例展示了如何将这两种数据结构结合起来,提升编程效率和解决实际问题的能力⚙️。不论你是编程新手还是经验丰富的开发者,本文都将
vue3表格数据分2个表格序号连续展示
我爱加班、、
前端开发遇到的问题前端功能实现以及问题解决vue项目实际开发中的bugelementui前端javascript
一、el-table表格在弹窗里面分两个表格展示。假设我们有一个数组tableData,我们希望在第一个表格中展示前半部分的数据,第二个表格中展示后半部分的数据。打开弹窗取消确定exportdefault{data(){return{dialogVisible:false,tableData:[{date:'2024-01-01',name:'张三',address:'上海市浦东新区',},{da
vue3实际开发bug解决
我爱加班、、
前端开发遇到的问题vue项目实际开发中的bugbug前端javascript
index.vue:119Uncaught(inpromise)TypeError:Cannotcreateproperty'value'onstring'我是标题'问题分析:问题出在componentName的解构和赋值操作上。你尝试将一个字符串赋值给ref的.value属性,这导致了错误。ref是Vue3中用于响应式引用的工具,它返回一个对象,该对象的.value属性用于存储实际的值。解决:不
实际开发中的有趣bug:“undefined“ is not valid JSON SyntaxError: “undefined“ is not valid JSON。
我爱加班、、
vue项目实际开发中的bugvuexbugjson前端javascriptvue.jsecmascriptajax
bug解读:指出在尝试解析或序列化JSON数据时遇到了问题。JSON(JavaScriptObjectNotation)是一种轻量级的数据交换格式,它要求数据必须是有效的JSON格式。在JavaScript中,undefined是一个特殊的值,表示变量没有被赋值,它不是一个有效的JSON值。场景:在后台项目,用户登录后,通过用户的菜单权限渲染侧边栏菜单,做了持久化存储。当登出后,在登录页刷新页面,
PySide6与PyQt5的区别
大乔乔布斯
pyqtpythonqt
虽然PySide6和PyQt5的功能和API十分相似,但由于它们分别是基于不同版本的Qt和由不同的团队维护,是两个不同的Python绑定库,分别用于与Qt库进行交互,可能会在一些细节上表现出差异,一些关键区别:1.维护和授权PySide6:由TheQtCompany官方维护。使用LGPL授权,这意味着你可以在开源和闭源项目中免费使用它(遵守LGPL条款)。版本号与Qt本身一致,PySide6对应于
shell 批量导表到数据库
大乔乔布斯
数据库unixlinux
需求:1,一堆表格,csv文件,2,特定分割符,3,表头有特殊utf16进制字符,文件可能是16进制或者utf8的格式,统一utf84,读取第一行作为表头处理一些空的字符,还有特殊字符,BOM(ByteOrderMark)5,转化linux路径为MYSQL可识别路径,先转换下中文到英文,否则mysql不能load6,循环导入到数据库中。可以每个表在数据库工具中,像Navicat里导入,1by1,也
Java 和 JavaScript 的区别
大乔乔布斯
javajavascript开发语言
尽管名字相似,JavaScript的名字中带有“Java”,确实让很多人误以为它与Java有紧密联系。但实际上,它们是完全不同的语言,只是在JavaScript的发展历史中与Java有一定的关联。1.JavaScript的诞生背景时间点:1995年,网景公司(Netscape)开发了一种轻量级的脚本语言,用于增强网页的交互性。开发者:JavaScript的发明者是布兰登·艾奇(BrendanEic
MySQL 拆分字符串函数Split
大乔乔布斯
mysql数据库
MYSQL目前没有Hive或者Java。python这列直接split的函数,需要自己定义一个,复制代码,一键使用CREATEDEFINER=`root`@`localhost`FUNCTION`func_split_str`(xVARCHAR(255),--字符串delimVARCHAR(12),--分隔符posINT--按分隔浮拆分后的第几个结果,从1开始数)RETURNSvarchar(25
JVM基础:什么是STW?
我心向阳iu
#JVMJava面试知识点精讲jvmjava面试
今天笔试题,出了个STW,咱是见也没见过,漏了怯了无语,仔细回忆了下,知道Stop-The-World这个词,不知道SWT,无语文章目录STW:Stop-The-WorldSTW概念进入SWT时机STW停顿的原因STW示例代码STW:Stop-The-WorldSTW概念STW(Stop-The-World):是在垃圾回收算法执行过程当中,将JVM内存冻结、应用程序停顿的⼀种状态。一旦Stop-t
TypeError: ‘str‘ object is not callable的几种情况及解决办法
兔兔爱学习兔兔爱学习
pandaspython机器学习深度学习人工智能
TypeError:‘str’objectisnotcallable的几种情况及解决办法第一个可能,定义了一个str的变量,这个和Python自带函数str的命名冲突了,所以发生这个错误。确实,这是一个情况。这种情况的解决办法就是:严格遵守命名规范,避免命名冲突。第二个可能,是字符串后面加了括号调用的缘故。这一般是由于不了解,对某个对象的细节不清楚,错把属性看成了函数。
Vue3 - Element Plus 下拉菜单 el-dropdown 阻止冒泡传递到上层触发事件,解决 dropdown 下拉菜单组件被容器元素包裹时点击事件触发,会连带触发外层包裹容器的点击事件
王二红
+Vue3elementplusel-dropdownvue3把command加上.stop下拉菜单组件如何点击不冒泡stop事件修饰符阻止点击冒泡click.stop无法使用
前言平常只需要给@click事件加入即可,但现在使用stop修饰符无法支持和识别语法。本文实现了在vue3+elementplus项目开发中,解决el-dropdown下拉菜单组件时点击事件冒泡问题(激活触发外层嵌套元素的点击事件,从而同时触发),使用.stop修饰符又没有地方可以加入的问题。本文提供完美解决方案,保证100%解决。如下图所示,常见于这种需求页面,点击“···”图标时就会引发点击事
appium自动化测试app在线升级软件时候使用dontStopAppOnReset参数让软件不关闭,卸载在安装新包
weixin_42811974
appium
使用dontStopAppOnReset参数:这个参数的作用是在Appium会话结束时,不会关闭应用。这样,即使Appium会话被关闭,应用也会保持在运行状态,然后软件就可以自己来安装新的应用包。defrestart_app(self)->WebDriver:ifself._driverisNone:caps={}caps["platformName"]="android"caps["device
sql统计相同项个数并按名次显示
朱辉辉33
javaoracle
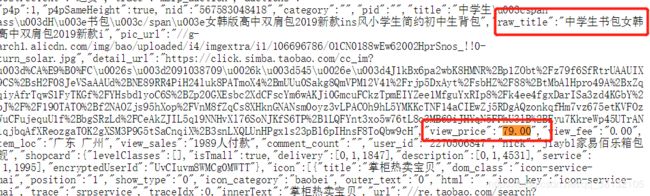
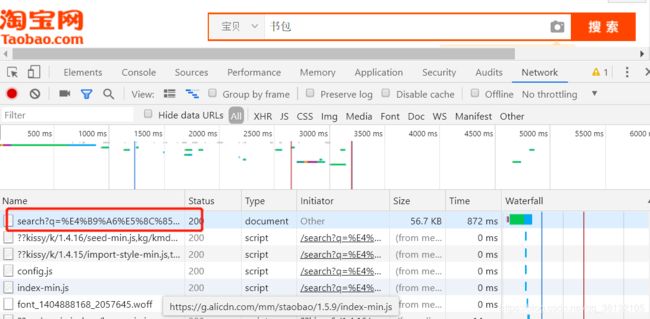
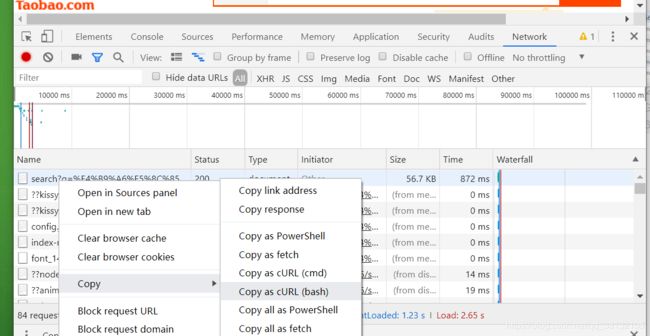
现在有如下这样一个表:
A表
ID Name time
------------------------------
0001 aaa 2006-11-18
0002 ccc 2006-11-18
0003 eee 2006-11-18
0004 aaa 2006-11-18
0005 eee 2006-11-18
0004 aaa 2006-11-18
0002 ccc 20
Android+Jquery Mobile学习系列-目录
白糖_
JQuery Mobile
最近在研究学习基于Android的移动应用开发,准备给家里人做一个应用程序用用。向公司手机移动团队咨询了下,觉得使用Android的WebView上手最快,因为WebView等于是一个内置浏览器,可以基于html页面开发,不用去学习Android自带的七七八八的控件。然后加上Jquery mobile的样式渲染和事件等,就能非常方便的做动态应用了。
从现在起,往后一段时间,我打算
如何给线程池命名
daysinsun
线程池
在系统运行后,在线程快照里总是看到线程池的名字为pool-xx,这样导致很不好定位,怎么给线程池一个有意义的名字呢。参照ThreadPoolExecutor类的ThreadFactory,自己实现ThreadFactory接口,重写newThread方法即可。参考代码如下:
public class Named
IE 中"HTML Parsing Error:Unable to modify the parent container element before the
周凡杨
html解析errorreadyState
错误: IE 中"HTML Parsing Error:Unable to modify the parent container element before the child element is closed"
现象: 同事之间几个IE 测试情况下,有的报这个错,有的不报。经查询资料后,可归纳以下原因。
java上传
g21121
java
我们在做web项目中通常会遇到上传文件的情况,用struts等框架的会直接用的自带的标签和组件,今天说的是利用servlet来完成上传。
我们这里利用到commons-fileupload组件,相关jar包可以取apache官网下载:http://commons.apache.org/
下面是servlet的代码:
//定义一个磁盘文件工厂
DiskFileItemFactory fact
SpringMVC配置学习
510888780
springmvc
spring MVC配置详解
现在主流的Web MVC框架除了Struts这个主力 外,其次就是Spring MVC了,因此这也是作为一名程序员需要掌握的主流框架,框架选择多了,应对多变的需求和业务时,可实行的方案自然就多了。不过要想灵活运用Spring MVC来应对大多数的Web开发,就必须要掌握它的配置及原理。
一、Spring MVC环境搭建:(Spring 2.5.6 + Hi
spring mvc-jfreeChart 柱图(1)
布衣凌宇
jfreechart
第一步:下载jfreeChart包,注意是jfreeChart文件lib目录下的,jcommon-1.0.23.jar和jfreechart-1.0.19.jar两个包即可;
第二步:配置web.xml;
web.xml代码如下
<servlet>
<servlet-name>jfreechart</servlet-nam
我的spring学习笔记13-容器扩展点之PropertyPlaceholderConfigurer
aijuans
Spring3
PropertyPlaceholderConfigurer是个bean工厂后置处理器的实现,也就是BeanFactoryPostProcessor接口的一个实现。关于BeanFactoryPostProcessor和BeanPostProcessor类似。我会在其他地方介绍。PropertyPlaceholderConfigurer可以将上下文(配置文件)中的属性值放在另一个单独的标准java P
java 线程池使用 Runnable&Callable&Future
antlove
javathreadRunnablecallablefuture
1. 创建线程池
ExecutorService executorService = Executors.newCachedThreadPool();
2. 执行一次线程,调用Runnable接口实现
Future<?> future = executorService.submit(new DefaultRunnable());
System.out.prin
XML语法元素结构的总结
百合不是茶
xml树结构
1.XML介绍1969年 gml (主要目的是要在不同的机器进行通信的数据规范)1985年 sgml standard generralized markup language1993年 html(www网)1998年 xml extensible markup language
改变eclipse编码格式
bijian1013
eclipse编码格式
1.改变整个工作空间的编码格式
改变整个工作空间的编码格式,这样以后新建的文件也是新设置的编码格式。
Eclipse->window->preferences->General->workspace-
javascript中return的设计缺陷
bijian1013
JavaScriptAngularJS
代码1:
<script>
var gisService = (function(window)
{
return
{
name:function ()
{
alert(1);
}
};
})(this);
gisService.name();
&l
【持久化框架MyBatis3八】Spring集成MyBatis3
bit1129
Mybatis3
pom.xml配置
Maven的pom中主要包括:
MyBatis
MyBatis-Spring
Spring
MySQL-Connector-Java
Druid
applicationContext.xml配置
<?xml version="1.0" encoding="UTF-8"?>
&
java web项目启动时自动加载自定义properties文件
bitray
javaWeb监听器相对路径
创建一个类
public class ContextInitListener implements ServletContextListener
使得该类成为一个监听器。用于监听整个容器生命周期的,主要是初始化和销毁的。
类创建后要在web.xml配置文件中增加一个简单的监听器配置,即刚才我们定义的类。
<listener>
<des
用nginx区分文件大小做出不同响应
ronin47
昨晚和前21v的同事聊天,说到我离职后一些技术上的更新。其中有个给某大客户(游戏下载类)的特殊需求设计,因为文件大小差距很大——估计是大版本和补丁的区别——又走的是同一个域名,而squid在响应比较大的文件时,尤其是初次下载的时候,性能比较差,所以拆成两组服务器,squid服务于较小的文件,通过pull方式从peer层获取,nginx服务于较大的文件,通过push方式由peer层分发同步。外部发布
java-67-扑克牌的顺子.从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的.2-10为数字本身,A为1,J为11,Q为12,K为13,而大
bylijinnan
java
package com.ljn.base;
import java.util.Arrays;
import java.util.Random;
public class ContinuousPoker {
/**
* Q67 扑克牌的顺子 从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的。
* 2-10为数字本身,A为1,J为1
翟鸿燊老师语录
ccii
翟鸿燊
一、国学应用智慧TAT之亮剑精神A
1. 角色就是人格
就像你一回家的时候,你一进屋里面,你已经是儿子,是姑娘啦,给老爸老妈倒怀水吧,你还觉得你是老总呢?还拿派呢?就像今天一样,你们往这儿一坐,你们之间是什么,同学,是朋友。
还有下属最忌讳的就是领导向他询问情况的时候,什么我不知道,我不清楚,该你知道的你凭什么不知道
[光速与宇宙]进行光速飞行的一些问题
comsci
问题
在人类整体进入宇宙时代,即将开展深空宇宙探索之前,我有几个猜想想告诉大家
仅仅是猜想。。。未经官方证实
1:要在宇宙中进行光速飞行,必须首先获得宇宙中的航行通行证,而这个航行通行证并不是我们平常认为的那种带钢印的证书,是什么呢? 下面我来告诉
oracle undo解析
cwqcwqmax9
oracle
oracle undo解析2012-09-24 09:02:01 我来说两句 作者:虫师收藏 我要投稿
Undo是干嘛用的? &nb
java中各种集合的详细介绍
dashuaifu
java集合
一,java中各种集合的关系图 Collection 接口的接口 对象的集合 ├ List 子接口 &n
卸载windows服务的方法
dcj3sjt126com
windowsservice
卸载Windows服务的方法
在Windows中,有一类程序称为服务,在操作系统内核加载完成后就开始加载。这里程序往往运行在操作系统的底层,因此资源占用比较大、执行效率比较高,比较有代表性的就是杀毒软件。但是一旦因为特殊原因不能正确卸载这些程序了,其加载在Windows内的服务就不容易删除了。即便是删除注册表中的相 应项目,虽然不启动了,但是系统中仍然存在此项服务,只是没有加载而已。如果安装其他
Warning: The Copy Bundle Resources build phase contains this target's Info.plist
dcj3sjt126com
iosxcode
http://developer.apple.com/iphone/library/qa/qa2009/qa1649.html
Excerpt:
You are getting this warning because you probably added your Info.plist file to your Copy Bundle
2014之C++学习笔记(一)
Etwo
C++EtwoEtwoiterator迭代器
已经有很长一段时间没有写博客了,可能大家已经淡忘了Etwo这个人的存在,这一年多以来,本人从事了AS的相关开发工作,但最近一段时间,AS在天朝的没落,相信有很多码农也都清楚,现在的页游基本上达到饱和,手机上的游戏基本被unity3D与cocos占据,AS基本没有容身之处。so。。。最近我并不打算直接转型
js跨越获取数据问题记录
haifengwuch
jsonpjsonAjax
js的跨越问题,普通的ajax无法获取服务器返回的值。
第一种解决方案,通过getson,后台配合方式,实现。
Java后台代码:
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
String ca
蓝色jQuery导航条
ini
JavaScripthtmljqueryWebhtml5
效果体验:http://keleyi.com/keleyi/phtml/jqtexiao/39.htmHTML文件代码:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>jQuery鼠标悬停上下滑动导航条 - 柯乐义<
linux部署jdk,tomcat,mysql
kerryg
jdktomcatlinuxmysql
1、安装java环境jdk:
一般系统都会默认自带的JDK,但是不太好用,都会卸载了,然后重新安装。
1.1)、卸载:
(rpm -qa :查询已经安装哪些软件包;
rmp -q 软件包:查询指定包是否已
DOMContentLoaded VS onload VS onreadystatechange
mutongwu
jqueryjs
1. DOMContentLoaded 在页面html、script、style加载完毕即可触发,无需等待所有资源(image/iframe)加载完毕。(IE9+)
2. onload是最早支持的事件,要求所有资源加载完毕触发。
3. onreadystatechange 开始在IE引入,后来其它浏览器也有一定的实现。涉及以下 document , applet, embed, fra
sql批量插入数据
qifeifei
批量插入
hi,
自己在做工程的时候,遇到批量插入数据的数据修复场景。我的思路是在插入前准备一个临时表,临时表的整理就看当时的选择条件了,临时表就是要插入的数据集,最后再批量插入到数据库中。
WITH tempT AS (
SELECT
item_id AS combo_id,
item_id,
now() AS create_date
FROM
a
log4j打印日志文件 如何实现相对路径到 项目工程下
thinkfreer
Weblog4j应用服务器日志
最近为了实现统计一个网站的访问量,记录用户的登录信息,以方便站长实时了解自己网站的访问情况,选择了Apache 的log4j,但是在选择相对路径那块 卡主了,X度了好多方法(其实大多都是一样的内用,还一个字都不差的),都没有能解决问题,无奈搞了2天终于解决了,与大家分享一下
需求:
用户登录该网站时,把用户的登录名,ip,时间。统计到一个txt文档里,以方便其他系统调用此txt。项目名
linux下mysql-5.6.23.tar.gz安装与配置
笑我痴狂
mysqllinuxunix
1.卸载系统默认的mysql
[root@localhost ~]# rpm -qa | grep mysql
mysql-libs-5.1.66-2.el6_3.x86_64
mysql-devel-5.1.66-2.el6_3.x86_64
mysql-5.1.66-2.el6_3.x86_64
[root@localhost ~]# rpm -e mysql-libs-5.1