R-CNN(Region-based Convolutional Neural Network)论文解读
R-CNN论文解读
- 一、预备知识
- (一)目标检测
- (二)IoU
- (三)mAP
- 二、使用R-CNN进行目标检测
- (一)系统构成
- (二)算法流程
- 1、算法流程图
- 2、算法分析
- (三)模型详解
- 1、候选区提取
- 2、候选区缩放
- (1)各向异性缩放
- (2)各向同性缩放
- 3、候选区特征提取
- (四)候选区分类
- (五)去除冗余候选区域
- (六)位置精修
- (七)创新点
- 论文链接:R-CNN
一、预备知识
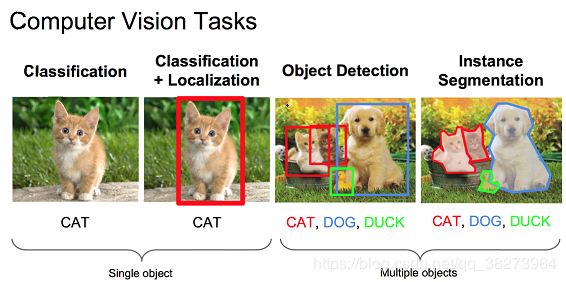
(一)目标检测
目标检测是指:
给定一个图像,找到其中的目标,找到它们的位置,并且对目标进行分类。目标检测模型通常是在一组固定的类上进行训练的,所以模型只能定位和分类图像中的那些类。此外,目标的位置通常是边界矩阵的形式。所以,目标检测需要涉及图像中目标的位置信息和对目标进行分类。
- 图像分类 VS 图像定位 VS 目标检测 VS 实例分割
(二)IoU
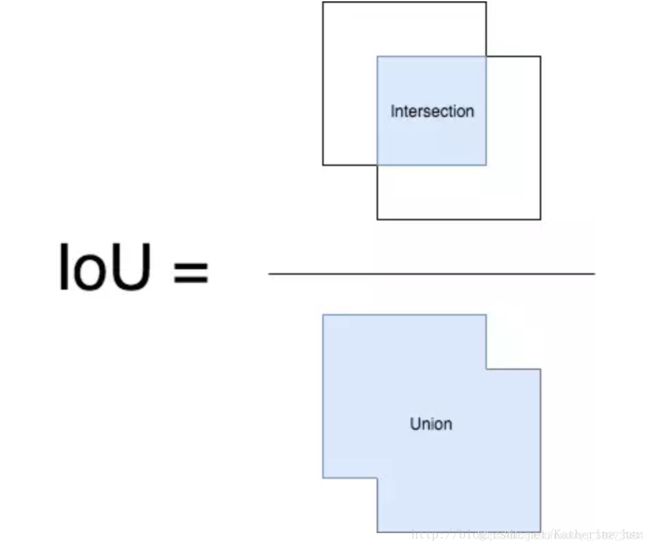
IoU 的全称为交并比(Intersection over Union),IoU 计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值。
- Ground Truth
- 预测结果(Bounding Boxes)
- IoU计算

(三)mAP
mAP(Mean Average Precision)均值平均精度对于评估模型定位性能、目标监测模型性能和分割模型性能都是有用的。
- 选择mAP的原因
目标检测问题中的模型的分类和定位都需要进行评估,每个图像都可能具有不同类别的不同目标,因此,在图像分类问题中所使用的标准度量不能直接应用于目标检测问题。
mAP计算过程
1、 导入数据集
对于数据集中的每一张图片,我们都有其相应的Ground Truth数据,即已知每张图片的真实信息。
2、计算当前图片中每个检测框的IoU
根据提前设定的阈值,若IoU>阈值,则认为这是一个真实的检测(True Detection);反之,则是一次错误的检测(False Detection)。找到类C的真实检测,整理得到:
- 该图中类C的正确检测次数(A)
依据的是IoU与阈值的大小之比 - 图片中类C的实际个数(B)
依据的是Ground Truth
3、计算当前图片中类C精度
P r e c e s i o n C = N ( T r u e D e t e c t i o n s ) C N ( T o t a l O b j e c t s ) C = A B Precesion_{C} = \frac{N(TrueDetections)_{C}}{N(TotalObjects)_{C}} = \frac{A}{B} PrecesionC=N(TotalObjects)CN(TrueDetections)C=BA
即给定一张图像,该图像中类别C的精度=图像正确预测的数量除以在图像中这一类的总的目标数量。
例:现在有一个给定的类,验证集中有100个图像,并且假设每张图像都包含100个类(基于ground truth),所以到这一步之后我们可以得到这张图片中100个类的精度值。
4、重复步骤2、3
直至,我们可以得到:
- 数据集中每张图片的类C的精度;
- 含有类C的图片的总数。
5、计算类C的平均精度
A v e r a g e P r e c i s i o n C = ∑ P r e c i s i o n C N ( T o t a l I m a g e s ) C AveragePrecision_{C} = \frac{\sum{Precision}_{C}}{N(TotalImages)_{C}} AveragePrecisionC=N(TotalImages)C∑PrecisionC
即一个C类的平均精度=在验证集上所有的图像对于类C的精度值的和除以有类C这个目标的所有图像的数量。
5、重复步骤2、3、4,直至将所有类别的平均精度计算出来。
例:整个集合中有100个类,到这一步之后我们就有100个类的平均精度值。
6、计算mAP
取所有类的平均精度值的平均值,即mAP(均值平均精度)
M e a n A v e r a g e P r e c i s i o n = ∑ A v e r a g e P r e c i s i o n C N ( C l a s s e s ) MeanAveragePrecision = \frac{\sum{AveragePrecision}_{C}}{N(Classes)} MeanAveragePrecision=N(Classes)∑AveragePrecisionC
即mAP=所有类别的平均精度之和除以类别总数 。
至此,我们就获得了能够评估模型性能的指标mAP。
二、使用R-CNN进行目标检测
(一)系统构成
原文:
Our object detection system consists of three modules. The first generates category-independent region proposals. These proposals define the set of candidate detections available to our detector. The second module is a large
convolutional neural network that extracts a fixed-length feature vector from each region. The third module is a set of classspecific linear SVMs.
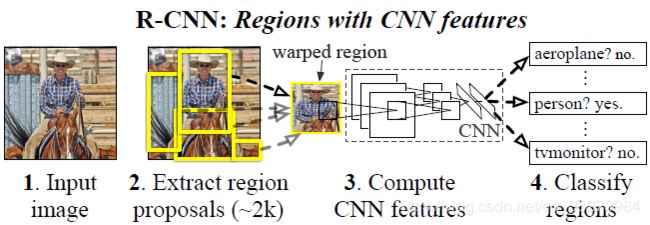
基于R-CNN的目标检测系统的构造分为以下三个部分:
- 提取候选区域;
- CNN,从候选区域中提取出固定长度的特征向量;
- 一系列SVM,分类。
(二)算法流程
1、算法流程图
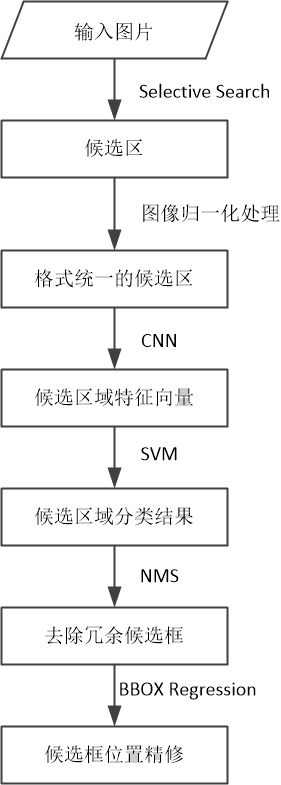
2、算法分析
- 候选区域提取
输入一张多目标图像,采用Selective Search算法提取约2000个候选区域。
候选区域均为矩形,但大小不一,而CNN的输入图像大小是固定的(假设为227x227),所以,在将图片输入到CNN中之前,需要对候选区进行归一化处理,将大小设置为227x227。 - 图像归一化处理
边界像素填充:论文中padding=16效果最佳;
图像变形:将图片缩放为227x227,论文中采用的是暴力拉伸方法,即不管图片的长宽比例,管它是否扭曲,进行缩放就是。 - 特征提取
将归一化处理后得到的2000张维度为227x227的候选区域输入到CNN(论文中选用的CNN模型有两种:AlexNet和VGG16)中,获得一个维度为2000x4096的图像特征矩阵。 - 分类
论文中使用的SVM均为二分类器,分类时将2000×4096维的特征矩阵与20个SVM组成的权值矩阵4096×20相乘【20种分类,SVM是二分类器,则有20个SVM】,获得2000×20维矩阵表示每个候选区域是某个物体类别的得分。 - 去除冗余候选框
分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制(NMS)剔除重叠候选区域,得到该列即该类中得分最高的一些候选区域。 - 位置精修
分别用20个BBOX Regression对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的Bounding Box。
(三)模型详解
1、候选区提取
在本论文中,候选区提取采用的算法为Selective Search
原文:While R-CNN is agnostic to the particular region proposal method, we use selective search to enable a controlled comparison with prior detection work.
一般可用的算法有:
- objectnes;
- selective search;
- category-independent object proposals;
- constrained parametric min-cuts(CPMC);
- multi-scale combinatorial grouping;
- Ciresan et al.
Selective Search方法
Selective Search方法基本思路如下:
- 使用一种过分割手段,将图像分割成小区域;
- 查看现有小区域,合并可能性最高的两个区域,重复直到整张图像合并成一个区域位置;
- 输出所有曾经存在过的区域,所谓候选区域。
合并规则
优先合并以下四种区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域 。 - 合并后,总面积在其BBOX中所占比例大的
保证合并后形状规则。
2、候选区缩放
由于下一步需要将候选区图片输入CNN模型中,但CNN模型对输入图像的尺寸是有要求的,在本文中为227*227 RGB。而通过selective search得到的候选区虽均为矩阵,但大小不一。
因此,在图片输入CNN模型之前,需要做一个图像缩放工作。在本文中,作者采用的是最简单的缩放方式,无视候选区域的大小和形状,统一变换到 227*227 的尺寸。
PS:在对 Region 进行缩放之前,首先对这些区域进行膨胀处理,在其 box 周围附加了p个像素,也就是人为添加了边框,在这里 p=16(因为效果最佳)。
原文:Of the many possible transformations of our arbitrary-shaped regions, we opt for the simplest. Regardless of the size or aspect ratio of the candidate region, we warp all pixels in a tight bounding box around it to the required size. Prior to warping, we dilate the tight bounding box so that at the warped size there are exactly p pixels of warped image context around the original box (we use p = 16).
原文:
缩放效果展示:



(1)各向异性缩放
不管图片长宽比例,不管是否扭曲,只管缩放到CNN要求的比例,见上图D列中的图片。
特点:
- 操作简单;
- 会造成图像扭曲和变形。
(2)各向同性缩放
考虑到图片扭曲会对分类精度有影响,提出各向同性缩放
- 先扩充后裁剪
直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充。见上图B列中的图片。 - 先裁剪后扩充
先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),见上图C列中的图片。
3、候选区特征提取
论文实验中使用的卷积神经网络来实现图像特征提取,使用的模型有:
- AlexNet;
- VGG16模型。
1、使用两个模型得出的结果对比如下:

2、两个模型构造如下:
- VGG16

- AlexNet

VGG16模型的特点是选择比较小的卷积核、选择较小的步长,它的精度更高高,但计算量是AlexNet的7倍。
论文主要对AlexNet模型的使用进行了讲解,我们接下来介绍R-CNN模型中具体使用的AlexNext的构造。
3、R-CNN模型中的AlexNet
Alexnet特征提取部分包含了5个卷积层、2个全连接层,输入图像维度为227*227*3,输出的特征向量维度为4096,各层的具体构造参考上一部分的AlexNet模型。
原文:We extract a 4096-dimensional feature vector from each region proposal using the Caffe implementation of the CNN described by Krizhevsky et al. Features are computed by forward propagating a mean-subtracted 227*227 RGB image through five convolutional layers and two fully connected layers.
4、AlexNet模型训练
(1)有监督预训练
- 数据集:ImageNet ILSVRC 2012,共1千万张图片,分为1000个类;
- 训练目的:训练AlexNet识别物体类型的能力。
(2)参数微调
- 数据库:PASCAL VOC 2007,共一万张图片,分为20个类;
- 训练目的:训练AlexNet解决特定问题的能力
- 详细说明:
采用 selective search 搜索出来的候选框 (PASCAL VOC 数据库中的图片) 继续对上面预训练的AlexNet模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景) (20 + 1bg = 21),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个正样本、96个负样本。

为什么要进行微调?
文中设计了没有进行微调的对比实验,分别就AlexNet CNN网络的pool5、fc6、fc7层进行特征提取,输入SVM进行训练,这相当于把AlexNet CNN网络当做万精油使用,类似HOG、SIFT等做特征提取一样,不针对特征任务。实验结果发现f6层提取的特征比f7层的mAP还高,pool5层提取的特征与f6、f7层相比mAP差不多;
在PASCAL VOC 2007数据集上采取了微调后fc6、fc7层特征较pool5层特征用于SVM训练提升mAP十分明显;
由此作者得出结论:不针对特定任务进行微调,而将CNN当成特征提取器,pool5层得到的特征是基础特征,类似于HOG、SIFT,类似于只学习到了人脸共性特征;从fc6和fc7等全连接层中所学习到的特征是针对特征任务特定样本的特征,类似于学习到了分类性别分类年龄的个性特征。
(四)候选区分类
采用的是SVM算法,SVM训练过程如下:
假设我们要检测车辆。我们知道只有当bounding box把整量车都包含在内,那才叫正样本;如果bounding box 没有包含到车辆,那么我们就可以把它当做负样本。但问题是当我们的检测窗口只有部分包含物体,那该怎么定义正负样本呢?作者测试了IOU阈值各种方案数值0,0.1,0.2,0.3,0.4,0.5。最后通过训练发现,如果选择IOU阈值为0.3效果最好(选择为0精度下降了4个百分点,选择0.5精度下降了5个百分点),即当重叠度小于0.3的时候,我们就把它标注为负样本。一旦CNN fc7层特征被提取出来,那么我们将为每个物体类训练一个SVM分类器。当我们用CNN提取2000个候选框,可以得到2000x4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与SVM权值矩阵4096*N点乘(N为分类类别数目,因为我们训练的N个SVM,每个SVM包含了4096个权值w),就可以得到结果了。
SVM模型训练
- 由于SVM是二分类器,需要为每个类别训练单独的SVM;
- SVM训练时输入正负样本在AlexNet CNN网络计算下的4096维特征,输出为该类的得分,训练的是SVM权重向量;
- 由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本。

(五)去除冗余候选区域
采用非极大值抑制法(NMS)
先前说道,selective research会产生2k个region proposals。经过SVM打分后,一个物体可能就有多个框。如下图:

但是我们需要一个物体只有一个最优框(相对同一物体的所有的框,即SVMs打分后得到的矩阵的一个列向量中挑选最优的)。于是使用NMS来抑制冗余的框,得到如下图的结果:
具体实现步骤如下:
① 对2000×20维矩阵中每列按从大到小进行排序;
② 从每列最大的得分候选框开始,分别与该列后面的得分候选框进行IoU计算,若IoU>阈值,则剔除得分较小的候选框,否则认为图像中存在多个同一类物体;
③ 从每列次大的得分候选框开始,重复步骤②;
④ 重复步骤③直到遍历完该列所有候选框;
⑤ 遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制。
举例:
某个物体最终得到了A,B,C,D,E,F六个框,按照SVM打分从高到低刚好也是A,B,C,D,E,F。挑选出得分最高的A,然后遍历剩下的(候选集),依次计算相对于A的IOU,如果IOU>阈值,则抛弃对应的框(例如:IOU(A,B)>阈值,则抛弃B),否则放回候选集。遍历完后,如果候选集还有元素且元素个数大于1,继续挑选出候选集中得分最高的(例如上一轮只抛弃了B,候选集中是C,D,E,F,那么现在得分最高的的是C),然后遍历候选集,再依次计算(同上),知道候选集中没有元素,或者只剩一个元素。那么留下的就是最优的框。
(六)位置精修
首先要明确目标检测不仅是要对目标进行识别,还要完成定位任务,所以最终获得的bounding-box也决定了目标检测的精度。
这里先解释一下什么叫定位精度:定位精度可以用算法得出的物体检测框与实际标注的物体边界框的IoU值来近似表示。
如下图所示,绿色框为实际标准的卡宴车辆框,即Ground Truth;黄色框为selective search算法得出的候选框,即Region Proposal。即使黄色框中物体被分类器识别为卡宴车辆,但是由于绿色框和黄色框IoU值并不大,所以最后的目标检测精度并不高。采用回归器是为了对候选框进行校正,使得校正后的Region Proposal与selective search更接近, 以提高最终的检测精度。论文中采用bounding-box回归使mAP提高了3~4%。

如何设置回归器?
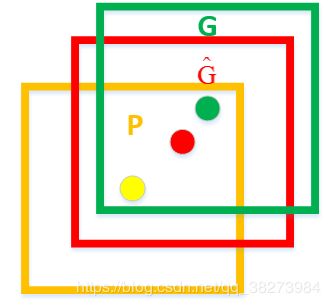
上图中,各个框的含义如下:
- 黄色框 P P P:Region Proposal;
- 绿色框 G G G:Ground Truth;
- 红色框 G ^ {\hat{G}} G^:Region Proposal进行回归后的预测窗口。
目的:
现在的目标是找到 P P P到 G ^ {\hat{G}} G^的线性变换【当Region Proposal与Ground Truth的IoU>0.6时可以认为是线性变换】,使得 G ^ {\hat{G}} G^与 G G G越相近,这就相当于一个简单的可以用最小二乘法解决的线性回归问题。
训练样本:

(七)创新点
1、经典的目标检测算法使用滑动窗法依次判断所有可能的区域。本文则(采用Selective Search方法)预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上(采用CNN)提取特征,进行判断。
2、经典的目标检测算法在区域中提取人工设定的特征。本文则采用深度网络进行特征提取。
参考:
- R-CNN算法解析
- 目标检测之 IoU
- 目标检测模型中的性能评估——MAP(Mean Average Precision)
- R-CNN论文详解
- 图像目标检测一——RCNN
- R-CNN学习总结